
 本文最初发表在 IEEE 软件 杂志上,由InfoQ & IEEE__ 计算机学会共同为您呈现。
本文最初发表在 IEEE 软件 杂志上,由InfoQ & IEEE__ 计算机学会共同为您呈现。
预测建模社区(predictive modeling community)将数据挖掘应用到来自软件项目的工件上。这项工作一直以来都非常成功,我们知道如何为软件的影响和不足构建预测模型,还能为学习“开发人员”的编程模式这样的任务构建预测模型(参见本文的扩展版本 了解详情)。
那就是说,为了对业内从业人员真正产生影响,我们需要改变预测建模社区的关注点。对数据而言,我们花在算法挖掘上的时间太多了,可实际上战场已经转移到我称之为景观挖掘(landscape mining)的东西上去了。为了给业内从业人员以支持,我们正准备转向我称之为决策挖掘,继而是讨论挖掘的东西上去。
本文对图 1 中所示的四种挖掘器做了比较和对比:
- 算法挖掘器探索的是数据挖掘算法参数的调整。
- 景观挖掘器揭示了决策空间的形状。
- 决策挖掘器对如何最有效地改变一个项目发表意见。
- 讨论挖掘器帮社区针对不同的决策辩论取舍。
算法和景观挖掘是更侧重于研究的活动,要探索挖掘器的内部细节。而决策和讨论挖掘更侧重于从业人员,因为他们关注的是社区如何使用结论。
算法挖掘
尽管很少有人指出,但预测建模最初的前提是预测应该能够指导软件管理,换句话说,曾几何时,预测的目的是为了决策。
可悲的是,最初的目标看起来已经被遗忘了。这一领域中有太多的研究人员被困在一个怪圈中,发表那种只用很少时间探索数据,却把大把的时间用在数据算法上的论文。这些论文大多数都把重点放在探索算法的配置项上,而不是如何反映底层的数据。最近有论文指出这种算法挖掘收获甚微,因为通过这种方式得到的“提升”充其量也只能算是边缘化的。比如说,对于工作量估算和缺陷预测而言,比较简单的数据挖掘器跟更精巧的比起来,能达到同样,甚至更好的效果。1,2
景观挖掘
算法挖掘是“跃了再看”,研究员把算法扔到数据上,然后看结果是什么。第二种方式是“先看再跃”,挖掘数据找出可能的推理空间,然后再跟学习器一起飞跃。这就是数据的“景观”。
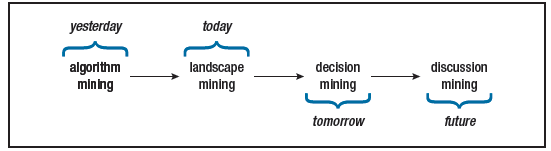
图 1. 从左到右的四种挖掘代表着从过去到将来
考虑下 W1 案例推理 (CBR) 系统,也被称为“达不溜(Dub-ya)”或“决策者”。 3 CBR 通过侦测最近的相似案例做出结论。为了把 W1 做成景观挖掘器(我们会称之为 W2),我们可以把训练数据聚类到一棵集群树中,其中的子节点包含的是父节点的子集群。然后用一个特性选择器遍历数据,拒绝那些其值无法区分出集群的特性。说得具体一点,就是我们检查整个集群中所有属性值的熵,把熵最高的那些删掉。最后我们可以用叶集群的中位数代替叶集群。这样特性的结果空间和样本非常小:几十个特性只剩下几个,几百个样本最终是每个集群中只有一个。
因为推断现在被限定到集群的子树上了(现在叶节点中只有一个代表性样本),所以我们可以迅速构建出很多针对特定情境的局部模型。
W2 有两个重要特点。首先,它是景观挖掘器,映射出数据的不同区域,让我们可以在其中构建不同的模型。其次,尽管这些想法合在一起很独特,但 W2 的每一部分都是预测建模社区熟知的工具。那就是说,让预测建模社区可以重新调整工具,对准一个有趣的新目标。
决策挖掘
最近在 ICSE 2012 上有一个关于软件分析的演讲,行业从业人员回顾了数据挖掘技术的状态。4 演讲嘉宾指出:“预测一切都好,但决策制定怎么样呢?” 数据挖掘之所以有用,是因为它侧重于对具体问题的调查,但数据挖掘器处于更高层的决策流程的子过程中。
为了把 W2 转成决策挖掘器(我们称之为 W3),我们添加了对照组学习。分类能给出数据的不同区域,而对照组学习能给出这些区域的不同之处。对照组要比分类规则小得多,特别是当它们是作为某些决策树过程的后续处理结果而生成的时。在决策树上层学习的对照组倾向于消除大部分的可能性,只选很少的类别,它们用较少的额外限制达成这一效果。
W3 所用的集群跟 W2 找到的一样,但它会在其上应用嫉妒原则。每个集群找到它最渴望找到的最近相邻集群,比如对于工作量估算而言,项目的相邻集群是构建起来更廉价的集群。然后 W3 会在相邻集群上应用一个对照组学习,以便在那个集群中找出达成那些更优结果的最佳实践。最近在 IEEE 软件工程期刊的一篇论文里,我指出这种基于嫉妒的“局部学习”比泛泛地从所有数据中学习得到的模型更好。5
W3 给我们的经验跟 W2 一样:重构我们现有的工具能够得到新型的、创新的预测建模方式。
讨论挖掘
毕加索曾经说过“计算机很傻;它们只能告诉你答案。”讨论挖掘器不傻;它们知道,尽管预测和决策很重要,但得出那些结论的过程中产生的问题和线索也很重要。在我看来,讨论挖掘是预测建模社区即将面临的巨大挑战。在这个到处充斥着数字的新世纪,这样的讨论工具将成为必需品。没有它们,人类将无法浏览和利用不断增长的、可以随时获取的数字化信息。
从某种意义上来说,讨论挖掘跟 Web 的关系非常紧密:
- Web 是用来做信息传输和访问的,主要目的是新信息的快速分享。
- 如果 Web 是讨论挖掘器,它很可能可以即时查询每个 web 页面,找到其它观念相似(或相左)的页面,找到之间的对照组,然后是赞同或驳斥的页面,然后运行查询,以便帮读者评估对照组中每个条目的合理性。
需要注意的是,目前大多数预测建模研究都算不上是讨论挖掘器,因为通常来说,大多数文献还在创建模型的方法中挣扎,我们就等着将来看模型的更新换代吧。
级别
是什么
任务
用途
做
预测, 决定
回归、分类、近邻推理
1
说
汇总, 规划, 描述
实例分区, 特征选择, 对照集
2
反应
权衡, 封装, 诊断, 监测
聚类, 多目标优化, 异常检测
3
分享
隐私保护、数据压缩、新旧规则整合、
找出竞争模型之间的变化量并进行辩论
对照组学习, 迁移学习
4
规模
迅速完成上述全部任务
?
表一 讨论挖掘器的内部
有一个关于讨论挖掘器的开放性问题很有意思,就是应该如何评估它们。在讨论挖掘中,模型的目标是找到它自身的缺陷,并用更好的东西替代,这让我想起了苏珊·桑塔格说过的话:“只有能够毁灭问题的答案才是好答案。”换句话说,我们不应该用准确性、回顾或精确程度评估这样的模型,而是应该用它们所造成的受众参与程度来评估。不,我也不知道该怎么做,但发现有这样清晰和重要的问题等着我们去解决,就会觉得很兴奋。
从工程原理的角度来看,表一给出了讨论挖掘器的内部构造。注意,预测建模社区已经掌握了要组合成这种或其它新的挖掘器的各个部分。
我们必须继续前进,并且我们能做到。算法挖掘已经足够好了:现在该去做别的了。行业从业人员真的不关心算法的内部细节,也不在乎数据如何分区。他们更关心用什么工具帮他们推动社区针对各种可能的决策展开辩论。
参考资料
1 K. Dejaeger et al., “Data Mining Techniques for Software Effort Estimation: A Comparative Study,” IEEE Trans. Software Eng., vol. 28, no. 2, pp. 375-397.
2 T. Hall et al., "A Systematic Review of Fault Prediction Performance in Software Engineering,"IEEE Trans. Software Eng., vol. 38, no. 6, pp. 1276-1304.
3 A. Brady and T. Menzies, “Case-Based Reasoning vs. Parametric Models for Software Quality Optimization,” Proc. 6th Int’l Conf. Predictive Models in Software Eng. (PROMISE 10), ACM, 2010;
4 T. Menzies and T. Zimmermann, “Goldfish Bowl Panel: Software Development Analytics,” Proc. 2012 Int’l Conf. Software Eng. (ICSE 2012), IEEE, 2012, pp. 1032-1033.
5 T. Menzies et al., " Local vs. Global Lessons for Defect Prediction and Effort Estimation ,"IEEE Trans. Software Eng., preprint, published online Dec. 2012;
关于作者
 Tim Menzies是西弗吉尼亚大学计算机科学与电气工程学院计算机科学系的全职教授。他的邮箱是 tim@menzies.us。
Tim Menzies是西弗吉尼亚大学计算机科学与电气工程学院计算机科学系的全职教授。他的邮箱是 tim@menzies.us。
本文最初发表在 IEEE__ 软件 杂志上。 IEEE 软件的使命是构建领先的和面向未来的软件从业人员社区。这份杂志致力于提供可靠、使用、前沿的软件开发信息,让工程师和管理人员能够紧跟快速变化的技术。
原文英文链接: Beyond Data Mining

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论