
InfoQ 此前翻译分享了“Google Play 的应用发现”系列文章中的“了解主题”和“使用相关App 的个性化建议”,本文是该系列的第三部分,主要介绍了Google Play 如何借助机器学习技术来打击规模化的垃圾信息和恶意评论。
在应用发现系列文章的第一部分和第二部分中,我们讨论了通过使用机器学习来对App 的相关主题有一个更深入的理解,以及一个深度学习框架来提供个性化推荐服务。本问将讨论借助机器学习技术,来打击Google Play Store 应用中的垃圾信息和恶意行为,从而为10 多亿Android 用户提供一个安全可信任的应用平台。
随着应用逐渐成为人们工作和生活中越来越重要的一部分,我们认识到有至关重要的两点必须得到保证:1) Google Play 找到的App 是安全的, 2) 展现给用户的App 信息是可靠且公正的。我们的目录中已有超过1 百万的App,并且新推出App 的数量每日都在明显增加,所以需要开发可扩展的方法来精准快速地识别劣质App。为解决该问题我们双管齐下,使用多种机器学习技术来帮助打击规模化的垃圾信息和恶意行为。
识别并阻止劣质App 进入Google Play 平台
正如 Google Play 开发者政策中所述,我们不允许上架恶意的、攻击性的或者非法 App。虽然有这样的政策,但依然会有少数破坏分子试图发布欺骗用户的应用。从大量应用目录中发现违反政策的应用并不是件简单的事情,尤其是每天还有数万新应用提交。这就是在评估是否违反政策,以及一个 App 对它的潜在用户可能构成的潜在风险方面,我们拥抱机器学习技术的原因。
我们使用了多种技术,比如基于大型概率网络的词嵌入 (word embedding) 文本分析、使用 Google Brain 的图像理解以及 APK 二进制文件的静态和动态分析。这些独特的技术主要目的是探测具体的违规行为(比如,受限内容、隐私和安全、知识产权、用户欺诈),相比于人工审核这种方式会更加系统化和可靠。被算法标识出的 App,要么退回给开发者要求修复检测到的问题,要么“暂存”到我们可以证明它是安全的,或清除潜在的违规行为。因为这种 App 审核流程结合了专家分析和算法,所以开发者可以在 App 提交后的数小时里就采取必要措施(比如继续迭代或发布)。

图示攻击性内容样本的词嵌入中违反政策的 App(红点)和符合政策的 App(绿点),通过 t-SNE( t-Distributed Stochastic Neighbor Embedding )算法绘制。
阻止操纵应用评分和排名
一个 App 其自身可能是合法合规的,但一些不良分子可能企图通过刷榜来操纵该应用的评分和排名。为了给用户提供一个 App 可感知质量的准确反映,我们在努力消除这些不良企图。然而,在我们制定政策做出努力的同时,操纵行为背后的不良分子也在尝试调整和改变他们的行为策略以绕过我们的政策,从而导致了一个对抗性问题摆在我们面前。
这种情况下,除了使用传统的有监督学习方法(正如我们在本系列的第一部分或第二部分里所介绍的,这是个更加“固定”的问题),还需要开发一个可重复的流程,让我们跟破坏分子一样(至少不亚于他们)敏捷。我们通过使用一种混合策略实现了这一点,该策略使用无监督学习技术生成训练数据,这些数据被依次输入到一个传统有监督学习技术构建的模型。
利用发生在Google Play 平台上的交互、事务和行为数据,我们应用异常检测技术来识别被刷榜党盯上的App。比如,一个可疑App 的所有交互数据可能源自某一个数据中心,而一个有机交互的正常应用其交互数据一般会符合一个正常的来源分布。
接着我们使用这些App 来分离出那些密谋或精心策划来操纵评分和排名的App,还有那些轮流用于训练数据来构建识别相似App 模型的。使用有监督学习技术构建的这个模型,接下来用于扩展覆盖度以及消除Google Play Apps 平台上的刷榜行为。
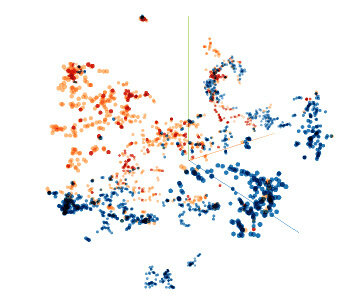
图示一个通过已知恶意行为App(红色)训练过的模型,如何扩大覆盖度来检测类似的恶意行为App(橙色),同时忽略掉系统用户(蓝色)。
通过支持快速发布同时不对用户安全妥协,我们力争使Google Play 成为开发者和用户的最佳平台。上文提到的机器学习的潜力帮助我们取得了双赢,而且我们会继续在这些技术上做出创新,以确保我们的用户远离垃圾信息和恶意行为。
感谢刘志勇对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论