
Google 和 CMU 的研究员使用 3 亿张图片,在图像识别算法的几个指标上取得了长足改进,而往常的训练一般只使用一百万张图片。
很多开发者在训练物体检测算法时会使用包含一百万张图片的 ImageNet 数据集。这个数据集从 2011 年起就没有新图片加入了。然而,在该数据集上训练的神经网络中的参数数量与日俱增,训练模型的 GPU 算力也在增加。卡内基梅隆大学(CMU)中 Google 的研究人员和科学家提出:如果增加训练数据量会如何?
于是,Google 建立了一个内部数据集,含有3 亿张图片,标记为18291 个类别。图片标注的来源包括原始网络信号,网页之间的联系,以及用户的反馈。因为不是由人标注的,所以含有20% 的噪音。
结论是:增大数据量果然有益。虽然图片标记含有噪音,算法的准确率还是提高了3 个百分点。很明显,数据量的增加克服了标记的噪音。研究人员发现算法的表现和数据量呈对数关系上升,如图所示。论文作者认为,现有的模型是基于一百万张图片建立的:如果对模型进行调整,准确率还有上升空间。
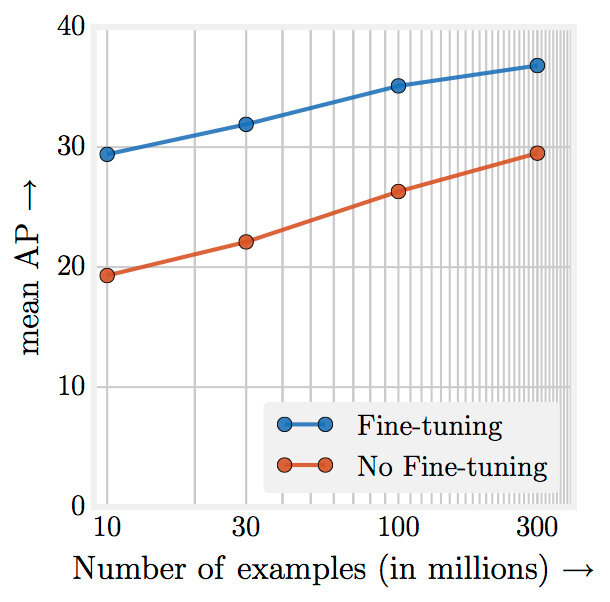
研究人员在微软的 COCO 对象检测基准测试上进行了测试,结果喜人:平均正确率 (AP) 从 34.3 上升到 37.4。Google 和 CMU 在 ICCV 会议上发布了算法和评测,并发布了论文《重新审视深度学习时代数据的非理性效果》,可在arxiv 自由获取。
查看英文原文: Researchers Improve State of the Art in Image Recognition Using Data Set With 300 Million Images
感谢冬雨对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论