
来自 LinkedIn 性能工程团队的的工程师 Toon Sripatanaskul 和 Zhengyu Cai 在官方网站上披露了他们是如何通过 Inception 处理内部系统的日志,从而实现服务监控的。
早在 2012 年初,LinkedIn 的性能工程团队就尝试构建一种工具,它可以对发生代码变更后的服务进行有效性验证。日志消息,特别是异常日志,可以很准确地反应服务的运行状况。对于新部署的服务,通过检查是否有新的异常日志出现就可以知道服务的健康状况。那个时候,他们使用脚本把日志文件拷贝到其它机器上,然后通过正则表达式生成最终的日志报告。这种方式在刚开始的时候运作良好,但 LinkedIn 发展迅速,脚本工具不具备伸缩性,无法跟上公司的发展速度。
2012 年底,他们构建了一个日志消息处理系统,叫作 Inception(Linked In Ex _ception_ 的合体)。他们把各个数据中心产生的日志消息聚集到 Kafka 上,然后 Inception 通过 Kafka 客户端处理这些消息,并把它们存放到如下几个数据库表中:
- 唯一性异常(What):异常日志消息的堆栈信息被抽取出来,并通过散列生成 MD5 串,这个串就是这个消息的签名。这样,他们就可以通过比较这个散列值快速地识别出新的异常,同时可以对异常进行去重。在计算散列值时,消息里的动态数据会被过滤掉,比如时间戳和代码行数。这个表保存的是日志消息和它的散列值。
- 实例(Where):这个表保存的是发生异常的服务实例,包括主机名、服务名和代码版本号。
- 时间序列(When):他们以分钟时间为单位,并检查在一分钟内某种异常发生的次数。这个表同时还引用了上述两个表的数据。
把以上三个表的数据连接起来,他们就有足够的信息来生成日志报表,包括唯一性日志消息以及它们的发生次数和发生地点。
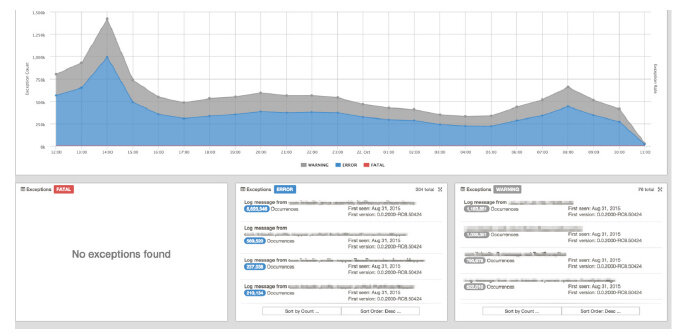
几年来,为了适应 LinkedIn 迅速的发展,Inception 的架构也在不断演进。在经历了几次伸缩性问题之后,他们决定使用在 Inception 里使用 Apache Samza 来处理日志。Samza 不仅处理速度快,而且高度可伸缩。Inception 现在每秒可以处理 110 万条日志消息。除此以外,Inception 还支持多种数据源。
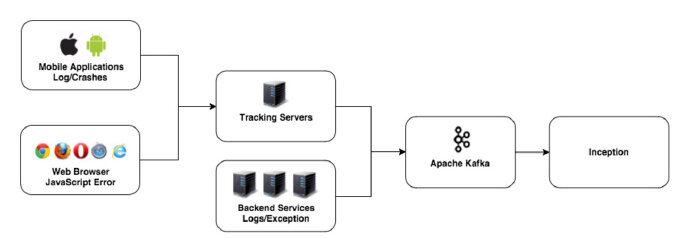
- 服务端异常: Inception 现在支持 Java、Python、Scala 和 C++ 的服务端异常。
- JavaScript 异常:他们使用一种数据管道从用户的浏览器端收集 JavaScript 异常,这些客户端异常通过 REST API 发送到专门的服务器上,并被转成 Kafka 事件。
- 移动设备异常:移动设备异常跟服务端异常一样,也包含了堆栈信息。不过收集这些信息会比较困难一些,目前他们还在不断解决这方面的问题。
- 测试框架异常: Inception 集成了 Selenium 框架,对于每一个测试用例,他们都会有一个唯一的标识,它们会被传播到下游的后端服务上。Inception 因此可以知道下游服务是否运行正常。
- JIRA 集成:当 Inception 检测到异常时,他们的另外一个系统就会创建一个 JIRA ticket。他们通过这种方式报告缺陷,不过这种方式会创建过多的 ticket,从而造成干扰,他们正在完善这个方案。
说到这里,不得不提一下,在日志分析技术领域,ELK(Elasticsearch、Logstash、Kibana)是另外一个值得一说的日志分析技术栈。ELK 可以保存完整的日志信息,包括时间戳、实际发生次数和具体的堆栈信息。不过 ELK 会占用大量的存储空间。对于 LinkedIn 来说,为了得到一个粗略的报表,可能因此需要耗费 50T 的存储空间,而 Inception 只需要 30G 的空间,并且处理速度更快。这么说来,Inception 似乎在这方面更胜一筹。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论