
Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据。它能在亚秒内查询巨大的 Hive 表。本文将详细介绍 Apache Kylin 1.5 中的 Fast-Cubing 算法。
Fast Cubing,也称快速数据立方算法, 是一个新的 Cube 算法。我们知道,Cube 的思想是用空间换时间, 通过预先的计算,把索引及结果存储起来,以换取查询时候的高性能 。在 Kylin v1.5 以前,Kylin 中的 Cube 只有一种算法:layered cubing,也称逐层算法:它是逐层由底向上,把所有组合算完的过程。
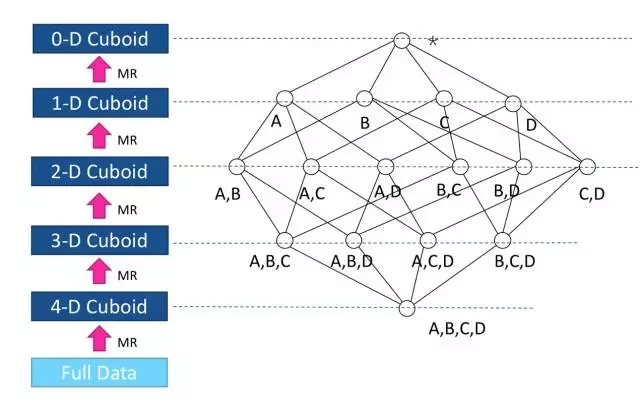
图 1 逐层的 Cube 计算
图 1 是一个四维 Cube,有维度 A、B、C、D;它会需要五轮的 Map-Reduce 来完成:第一轮 MR 的输入是源数据, 这一步会对维度列的值进行编码,并计算 ABCD 组合的结果。接下来的 MR 以上一轮的输出为输入,向上聚合计算三个维度的组合: ABC, BCD, ABD, 和 ACD;依此类推,直到算出所有的维度组合。
这个算法的优势是每一轮 MR 以上一轮的输出为结果,这样可以减少重复结算;当计算到后半程的时候,随着数据的减小,计算会越来越快 。
逐层 Cube 算法的主要优点是简单:Cube 聚合的过程就是把要聚合掉的维度从 key 中减掉组成新的 key 交给 Map-Reduce,由 Map-Reduce 框架对新 key 做排序和再聚合,计算结果写到 HDFS。这个算法很好地利用了 Map-Reduce 框架。得益于 Hadoop/Map-Reduce 的成熟,此算法的稳定性已经非常高。
经过不断的实践,开发团队也发现了此算法的局限:我们知道,当数据量大的时候,Hadoop 主要利用外存(也就是磁盘)做排序,数据在 Mapper 和 Reducer 之间还需要洗牌(shuffle)。在计算 Cube 的时候,集群的 IO 使用率往往很高 ; 在运行一些大的任务时,瓶颈会出现在网络传输和磁盘读写上,而 CPU 和内存的使用率比较低。
此外, 因为需要递交 N+1 次 Map-Reduce 任务;每次递交任务,都需要检查集群是否有可用的节点能否满足资源要求,如果没有还需等待其它任务释放资源;反复的任务递交,给 Hadoop 集群带来额外的调度开销。特别是当集群比较繁忙的时候,等待的时间常常会非常可观,这些都导致 了 Cube 构建的时间比较长 。
带着这个问题开发团队做了不断分析和尝试,结合了若干研究者的论文,于是有了开发新算法的设想。新算法的核心思想是清晰简单的,就是最大化利用 Mapper 端的 CPU 和内存,对分配的数据块,将需要的组合全都做计算后再输出给 Reducer; 由 Reducer 再做一次合并(merge),从而计算出完整数据的所有组合。如此,经过一轮 Map-Reduce 就完成了以前需要 N 轮的 Cube 计算。图 2 是此算法的概览。
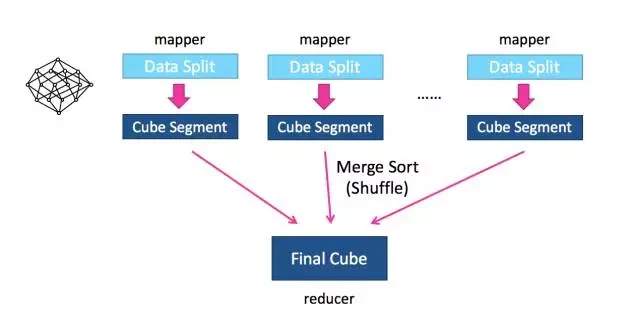
图 2 Fast Cubing
在 Mapper 内部, 也可以有一些优化,图 3 是一个典型的四维 Cube 的生成树;第一步会计算 Base Cuboid(所有维度都有的组合),再基于它计算减少一个维度的组合。基于 parent 节点计算 child 节点,可以重用之前的计算结果;当计算 child 节点时,需要 parent 节点的值尽可能留在内存中; 如果 child 节点还有 child,那么递归向下,所以它是一个深度优先遍历。当有一个节点没有 child,或者它的所有 child 都已经计算完,这时候它就可以被输出,占用的内存就可以释放。
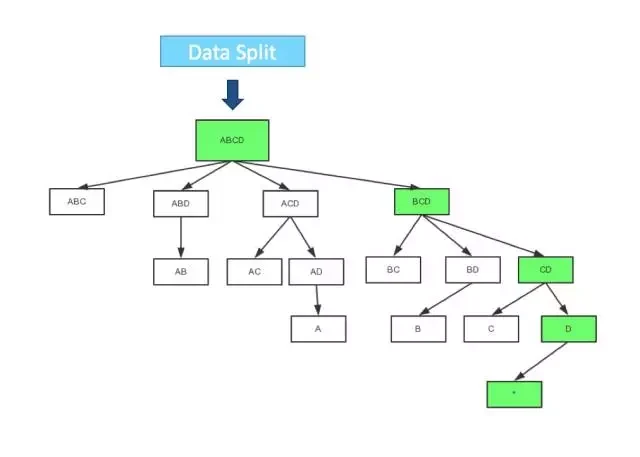
图 3 Mapper 端的 Cube 生成树遍历
如果内存够的话,可以多线程并行向下聚合。如此可以最大限度地把计算发生在 Mapper 这一端,一方面减少 shuffle 的数据量,另一方面减少 Reducer 端的计算量。
Fast Cubing 的优点:
- 总的 IO 量比以前大大减少。
- 此算法可以脱离 Map-Reduce 而对数据做 Cube 计算,故可以很容易地在其它场景或框架下执行,例如 Streaming 和 Spark。
Fast Cubing 的缺点:
- 代码比以前复杂了很多: 由于要做多层的聚合,并且引入多线程机制,同时还要估算 JVM 可用内存,当内存不足时需要将数据暂存到磁盘,所有这些都增加复杂度。
- 对 Hadoop 资源要求较高,用户应尽可能在 Mapper 上多分配内存;如果内存很小,该算法需要频繁借助磁盘,性能优势就会较弱。在极端情况下(如数据量很大同时维度很多),任务可能会由于超时等原因失败;
要让 Fast-Cubing 算法获得更高的效率,用户需要了解更多一些“内情”。
首先,在 v1.5 里,Kylin 在对 Fast-Cubing 请求资源时候,默认是为 Mapper 任务请求 3Gb 的内存,给 JVM2.7Gb。如果 Hadoop 节点可用内存较多的话,用户可以让 Kylin 获得更多内存:在 conf/kylin_job_conf_inmem.xml 文件,由参数“mapreduce.map.memory.mb”和“mapreduce.map.java.opts”设定 。
其次,需要在并发性和 Mapper 端聚合之间找到一个平衡。在 v1.5.2 里,Kylin 默认是给每个 Mapper 分配 32 兆的数据;这样可以获得较高的并发性。但如果 Hadoop 集群规模较小,或可用资源较少,过多的 Mapper 会造成任务排队。这时,将数据块切得更大,如 64 兆,效果会更好。数据块是由 Kylin 创建 Hive 平表时生成的, 在 kylin_hive_conf.xml 由参数 dfs.block.size 决定的。从 v1.5.3 开始,分配策略又有改进,给每个 mapper 会分配一样的行数,从而避免数据块不均匀时的木桶效应:由 conf/kylin.properteis 里的“kylin.job.mapreduce.mapper.input.rows”配置,默认是 100 万,用户可以示自己集群的规模设置更小值获得更高并发,或更大值减少请求的 Mapper 数。
通常推荐 Fast-Cubing 算法,但不是所有情况下都如此。
举例说明,如果每个 Mapper 之间的 key 交叉重合度较低,fast cubing 更适合;因为 Mapper 端将这块数据最终要计算的结果都达到了,Reducer 只需少量的聚合。另一个极端是,每个 Mapper 计算出的 key 跟其它 Mapper 算出的 key 深度重合,这意味着在 reducer 端仍需将各个 Mapper 的数据抓取来再次聚合计算;如果 key 的数量巨大,该过程 IO 开销依然显著。对于这种情况,Layered-Cubing 更适合。
用户该如何选择算法呢? 无需担心,Kylin 会自动选择合适的算法。
Kylin 在计算 Cube 之前对数据进行采样,在“fact distinct”步,利用 HyperLogLog 模拟去重,估算每种组合有多少不同的 key,从而计算出每个 Mapper 输出的数据大小,以及所有 Mapper 之间数据的重合率,据此来决定采用哪种算法更优。在对上百个 Cube 任务的时间做统计分析后,Kylin 选择了 8 做为默认的算法选择阀值 (参数 kylin.cube.algorithm.auto.threshold):如果各个 Mapper 的小 Cube 的行数之和,大于 reduce 后的 Cube 行数的 8 倍,采用 Layered Cubing, 反之采用 Fast Cubing。如果用户在使用过程中,更倾向于使用 Fast Cubing,可以适当调大此参数值,反之调小。
作者介绍
史少锋,Kyligence 技术合伙人兼资深架构师,Apache Kylin 核心开发者和项目管理委员会成员(PMC),专注于大数据分析和云计算技术。曾任 eBay 全球分析基础架构部大数据高级工程师,IBM 云计算部门软件架构师;曾是 IBM 公有云 Bluemix DevOps 团队核心成员,负责平台的规划、开发和运营。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论