

关键要点
持续可靠地运行 Spark 应用程序是一项具有挑战性的任务,而且需要一个良好的性能监控系统。
-在设计性能监控系统时有三个目标——收集服务器和应用程序指标、在时序数据库中存储指标,并提供用于数据可视化的仪表盘。
Uber JVM Profiler 被用于监控 Spark 应用程序,用到的其他技术还有 InfluxDB(用于存储时序数据)和 Grafana(数据可视化工具)。
性能监控系统可帮助 DevOps 团队有效地监控系统,用以满足应用程序的合规性和 SLA。
很多行业都在使用 Apache Spark 构建大数据处理应用程序。Spark 为此类应用程序提供了隐式数据并行性和容错性。这类应用程序可以是基于流式处理、批处理、SQL 数据集处理或机器学习。Spark 通过快速的内存数据处理引擎在集群中运行这些应用程序,并在数据管道中转换和处理大量数据。持续可靠地运行这些应用程序是一项具有挑战性的任务,需要一个良好的性能监控系统。随着 Spark 被各行各业广泛采用,性能监控、度量分析和调优 Spark 应用程序的问题越来越受到关注。Uber 最近开源了他们的 JVM Profiler。在本文中,我们将讨论如何扩展 Uber JVM Profiler,并将其与 InfluxDB 和 Grafana 一起用于监控和报告 Spark 应用程序的性能指标。
Spark 应用程序性能监控系统
要最大限度地利用可用资源并尽早发现可能存在的问题,需要一个性能监测系统。监控系统需要为运行中的系统提供综合性的状态报告,并在组件发生故障时发送警报。当我们需要在 Spark 集群中运行大规模分布式系统以及 Hadoop 生态系统的不同组件时,对细粒度性能监视系统的需求就变得不可或缺。Spark 应用程序在共享资源上执行数据的分布式处理,这使得 DevOps 团队的工作变得非常复杂。DevOps 团队必须有效地管理可用资源,并密切监控系统的不同组件,以避免出现宕机。性能监控系统提供的完整堆栈可见性有助于 DevOps 团队了解系统行为,并对生产问题做出快速反应。这确保了 Spark 应用程序的可靠性、可伸缩性和性能。
针对这种复杂系统的理想性能监控系统必须具备以下特性:
监控系统应提供有关集群内每个组件的细粒度可见性。我们应该能够获得有关 CPU、内存、存储、本地文件和 HDFS 的磁盘 I/O、堆栈跟踪等详细指标。这些指标有助于快速诊断发生故障的实例。
监控系统应该为在 Spark 上运行的应用程序提供代码级别度量(例如执行时间、方法的参数等)。这将有助于识别运行较慢的方法、磁盘热点等。
监控系统应存储每一秒的指标,并允许我们通过浏览不同时间段的数据来分析指标。我们应该能够对这些数据进行二级和二级解剖。我们应该能够控制数据保留期,并在需要时轻松访问和分析过去的数据。这有助于分析当前趋势并预测未来趋势。
监控系统应该要提供有效的方法,用于从连续收集的大量指标中提取有意义信息。包括使用 SQL 或 API 查询数据、过滤数据、聚合值和应用自定义分析。这有助于轻松转换和更快地分析数据。
监控系统应该能够方便地访问从度量数据分析中推导出的信息,可以使用不同的形式(如图表等)在仪表盘中显示数据,可以基于主机、时间或作业对数据进行分类,用户应该能够进一步深入分析不同的数据点,能够为用户定义的阈值配置警报和通知。这有助于 DevOps 团队和组织的其他利益相关者在必要时快速获得所需的信息。
在本文中,我们将使用开源工具和技术开发一个性能监控系统。Spark 应用程序性能监控系统的设计有三个目标:
收集系统(驱动程序和执行程序)和应用程序代码的性能指标;
将这些指标存储在持久存储中以进行时序分析(批量和实时);
以图表的形式生成度量指标报告。
Apache Spark 为指标提供了一个 web-ui 和 REST API。Spark 还提供各种接收器,包括控制台、JMX、Servlet、Graphite 等。还有一些其他可用的开源性能监控工具,如 dr-elephant、sparklint、prometheus 等。这些工具提供的指标主要是服务器级别的指标,其中有一些也提供应用程序的信息。
Uber JVM Profiler 同时收集服务器级别和应用程序的度量指标。它可以从驱动程序、执行程序或任已 JVM 中收集所有指标(cpu、内存、缓冲池等)。它可以在不修改现有代码的情况下对其进行增强,因此可以收集有关方法、参数和执行时间的指标。为了存储用于时序分析的度量指标,我们将使用 InfluxDB,它是一个功能强大的时序数据库。我们将扩展 Uber JVM Profiler,并为 InfluxDB 添加一个新的 Reporter,这样就可以通过 HTTP API 保存度量数据。在图形化的仪表盘方面,我们将使用 Grafana,它将从 InfluxDB 查询指标数据。
以下是用于 Spark 应用性能监控系统的工具和技术的详细信息。
Uber JVM Profiler
Uber JVM Profiler 是一个分布式的分析器,它从集群的不同节点收集性能指标和资源利用率指标。它作为 Java 代理与应用程序一起运行,并收集不同的度量指标。它将这些指标发布给指定的 Reporter,以进行进一步的分析和报告。Uber JVM Profiler 是为分析 Spark 应用程序而开发的,但它也可以用于分析任何基于 JVM 的应用程序。Uber JVM Profiler 有三个主要组件:
Profiler:Uber JVM Profiler 内置了以下的 Profiler:
CpuAndMemory Profiler——收集缓冲池(直接和映射)、垃圾回收(计数和时间)、堆内存(已提交和已使用)、非堆内存(已提交和已使用)、CPU(加载和时间)、内存池详细信息(EdenSpace、SurvivorSpace、TenuredGen、CodeCache、CompressedClassSpace、Metaspace)、vmHWM 和 vmRSS 指标。
IO Profiler——收集 CPU 统计信息(idle、nice、system、user、iowait)和磁盘 IO 的读/写字节。
Stacktrace Profiler——收集线程名称、线程状态和堆栈跟踪指标。
ProcessInfo Profiler——收集代理版本、JVM 类路径、JVM 输入参数和 xmxBytes 指标。
MethodDuration Profiler——收集方法执行时间的指标,其中包括类名、方法名和进程名。
MethodArgument Profiler——收集方法参数的指标,其中包括类名、方法名和进程名。
Transformer:这个 Class File Transformer 用于增强 Java 方法的字节码。
Reporter:可用的 Reporter 包括:
KafkaOutputReporter——将性能指标发送到 Kafka 主题。
FileOutputReporter——将指标写入文件中。
ConsoleOutputReporter——将指标发送到控制台。
RedisOutputReporter——将指标存储到 Redis 数据库。
有关 JVM Profiler 的更多详细信息,请参阅 Uber 的博文。
InfluxDB 和 Grafana
InfluxDB:InfluxDB 是一个开源的时序数据库,用于存储和查询大量带时间戳的数据。这些数据可以是物联网传感器数据、实时分析数据、应用程序指标数据或 DevOps 监控数据。它通过让旧数据过期和删除旧数据进行自动数据生命周期管理。它通过类似 SQL 的查询语言、HTTP API 和客户端库提供写入和查询功能。请从这里获得更多信息。
Grafana:Grafana 是一个开源的度量指标仪表盘和图形编辑器。Grafana 还支持警报和通知。它支持很多数据源,如 Graphite、InfluxDB、OpenTSDB、Prometheus、Elasticsearch 和 CloudWatch。很多仪表盘和插件(包括开源的和商业的)都可以在 Grafana 的网站上找到。有关 Grafana 的更多详细信息,请访问该网站。
系统架构
Spark 应用程序运行在集群网络上,集群网络可能包含几个节点到数千个节点。为了从这个分布式系统收集指标,并将指标发送到其他系统进行进一步分析,我们需要一个具备松散耦合和容错能力的架构。将指标发布到 Kafka 主题是最佳解决方案之一。Uber JVM Profiler 附带了“KafkaOutputReporter”,可用于实现这个目的。另一个解决方案是使用 InfluxDB。InfluxDB 提供了 HTTP API,可用于查询和写入数据库。这个 API 支持 Basic 和 JWT 令牌身份验证,并支持 HTTPS 访问。本文中的“InfluxDBOutputReporter”将通过调用 Write HTTP Endpoint 来存储由不同的 Profiler 收集到的指标。Grafana 为 InfluxDB 提供了丰富的数据源插件。Grafana 使用 Query HTTP Endpoint 从 InfluxDB 获取指标数据,并以图形和表格的形式在仪表盘上显示数据。这些图形和表格以固定的时间间隔自动刷新,时间间隔可以在 Grafana 中设置。
使用 Uber JVM Profiler、InfluxDB 和 Grafana 的 Spark 应用性能监控系统的架构图如下图 1 所示。
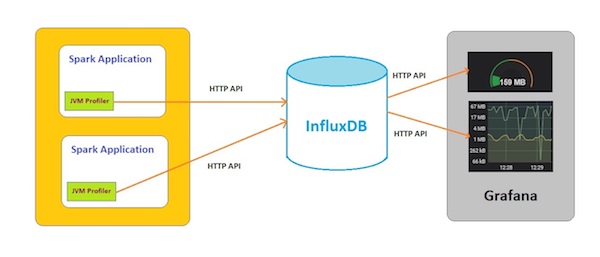
图 1. 性能监控系统架构图
技术和工具
下面的表格列出了性能监控系统使用的技术和工具。
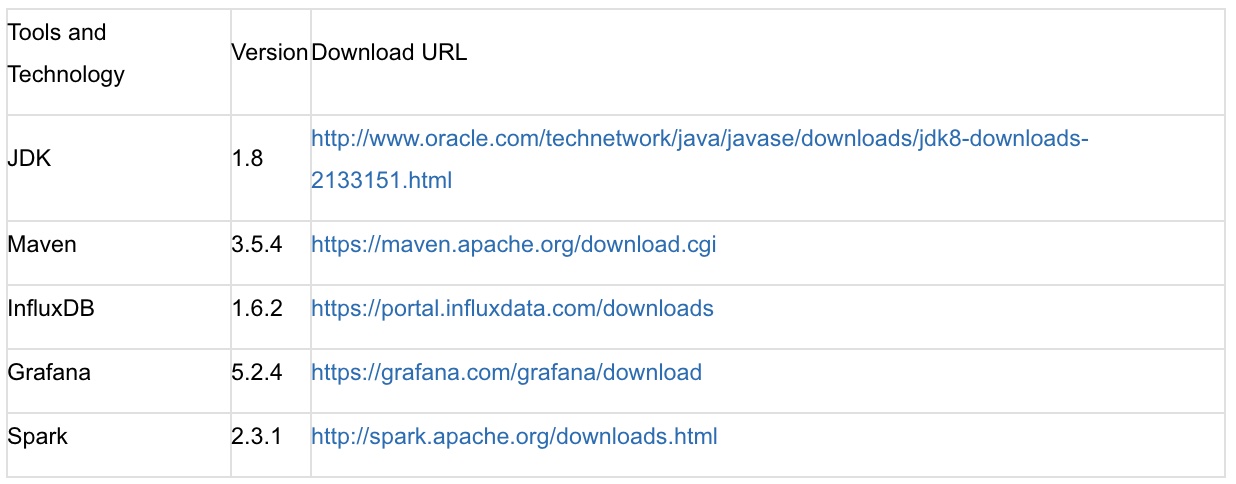
请参阅相关文档以了解如何安装和配置这些工具。
设计与实现
以下部分介绍了 Spark 应用程序性能监控系统的设计和实现细节。Uber JVM Profiler 从驱动程序和执行程序收集指标,这些指标包含了一些详细信息,如角色、processUuid 和主机。这些信息对于识别不同系统和分析这些系统的指标来说非常有用。在 InfluxDB 中,我们可以使用这些信息来查询不同执行程序的性能指标。我们可以将 processUuid 加入到 InfluxDB 标签中,以此来提高查询性能。首先,我们将在 InfluxDB 中创建“metrics”数据库,然后在 JVM Profiler 代码库中添加“InfluxDBOutputReporter”,最后配置 Grafana 仪表盘。
在 InfluxDB 中创建 metrics 数据库
启动 InfluxDB 服务器,默认情况下端口为 8086。在 Ubuntu 系统中打开一个终端并执行“Influxd”命令。
/user/bin$ sudo influxd
在服务器启动后,在另一个终端启动“influx”。然后执行命令创建“metrics”数据库。
/user/bin$ sudo influx
CREATE DATABASE metrics
实现 InfluxDBOutputReporter
我们将在 JVM-Profile 代码库中实现“InfluxDBOutputReporter”。请参阅 GitHub 上的“Influxdb_reporter”分支的 InfluxDBOutputReporter.java 文件,以了解本节所讨论的实现细节。
我们通过 Influxdb-java 库与 InfluxDB 数据库服务器发生交互。它通过 HTTP API 读写 InfluxDB 数据库。更新 pom.xml 文件,添加 Influxdb-java 依赖项。
在 InfluxDBOutputReporter 类中定义 InfluxDB 数据库服务器的主机、端口和数据库属性。这些属性的默认值分别为“127.0.0.1”、“8086”和“metrics”。使用 Influxdb-java 库提供的 API 连接 InfluxDB。
InfluxDBOutputReporter 类需要实现 com.uber.profiling.Reporter 接口。我们需要覆盖 public void report(String profilerName,Map<String,Object> metrics)方法和 public void close()方法。“profilerName”将是“metrics”数据库中的度量名称。
由于 InfluxDB 使用行协议来存储键值对,我们需要处理由 Profiler 发送的 Map<String,Object>度量数据,并将它们转换为可以存储在 InfluxDB 中的格式。我们可以使用指标中的“name”属性的值(如果可用)作为字段名称。如果“name”属性不可用,可以使用计数器的值。InfluxDB 支持在查询字段中使用正则表达式,因此查询这些字段不成问题。
使用 Influxdb-java 库提供的 API 创建 Point 和 Batchpoint,并将 Batchpoints 写入 InfuxDB 数据库。
要从 yaml 文件中读取数据库连接信息,必须使用 com.uber.profiling.YamlConfigProvider 和 com.uber.profiling.Argument 类。在 Argument 类中添加 InfluxDBOutputReporter 类的引用,并调用 setProperties 方法传入 yaml 文件中定义的属性。GitHub 的 resources/Influxdb.yaml 是一个 yaml 示例文件。
在 Grafana 中添加数据源和仪表盘
本节将介绍在 Grafana 中添加度量数据图表所需的步骤。
启动 Grafana 服务器。在 Ubuntu 上,我们可以执行以下命令。默认端口号为 3000。
sudo service grafana-server start
在浏览器中打开 http://localhost:3000/,并为 InfluxDB 创建数据源。将 Name 设置为“InfluxDBDataSource”,Type 设置为“InfluxDB”,InfluxDB 的默认 URL 为“http://localhost:8086”,数据库名称为“metrics”。
单击“Graph”创建一个新的仪表盘,单击“Edit”添加查询。以下是一个查询示例。
Grafana 提供了一些选项,用于定义可在查询中传递的模板变量。这对在仪表盘上显示来自多个执行程序的数据来说非常有用。例如,我们可以为“executorProcessUuid”和“timeInterval”创建变量,并在查询中使用它们,如下所示。
GitHub 提供了一个 JSON 示例文件 Spark-Metrics-Dashboar。可以在 Grafana 服务器上导入这个文件。在浏览器中打开 http://localhost:3000/dashboard/import,然后单击“Upload .json File”。
构建和部署
本节将介绍构建和部署性能监控系统的步骤。可以从 GitHub 上的“Influxdb_reporter”分支克隆应用程序代码。
使用以下命令构建带有“InfluxDBOutputReporter”的 JVM Profiler。
mvn clean package
将 maven 创建的 JVM Profiler-0.0.9.jar 文件复制到某个目录(例如/opt/profiler)。我们也可以将 Influxdb.yaml 放在这个目录中。
我们将使用 Apache Spark 附带的 JavaNetworkWordCount 应用程序进行 profiling,源代码位于/spark-2.3.1-bin-hadoop2.7/examples/src/main/java/org/apache/spark/examples/streaming 中。
要运行 JavaNetworkWordCount,我们需要使用以下命令运行 Netcat 服务器。
nc -lk 9999
转到/spark-2.3.1-bin-hadoop2.7/sbin 目录,并使用以下命令启动 Master。
./start-master.sh
我们可以从日志文件中获取 Master 的 URL。将此 URL 传给命令来启动 Worker。
./start-slave.sh -c 2 spark://192.168.1.6:7077
转到/spark-2.3.1-bin-hadoop2.7/bin 目录并执行以下命令。这个命令将执行 JavaNetworkWordCount 应用程序,并启动 JVM Profiler。有关参数的详细信息,请查看 Uber JVM Profiler 的 GitHub README 页面。
或者,我们可以使用 yaml 文件来运行应用程序。在命令中传递“configProvider”和“configFile”参数,如下所示。
转到“influx”终端并执行以下命令。
use metrics
show measurements
我们将获取到“metrics”数据库中的“Measurements”名称,如下所示。
CpuAndMemory
IO
ProcessInfo
Stacktrace
使用以下命令从 CpuAndMemory 度量中获取单个记录。
select * from CpuAndMemory limit 1
以下是示例仪表盘。
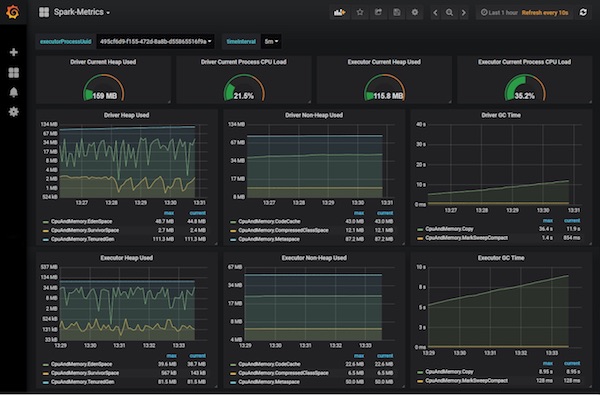
图 2. 用于 Spark 指标的 Grafana 仪表盘示例
优点和缺点
我们在本文中讨论的性能监控系统使用 Uber JVM Profiler 收集系统和应用程序的指标,并将它们存储在 InfluxDB 时序数据库中。时序数据库提供数据保留策略、连续查询、灵活的时间聚合以及数百万条记录的实时处理和批处理。这些时序数据有助于我们分析过去系统发生的变化、系统当前的行为方式以及预测未来系统将如何变化。我们可以通过关联指标来识别故障模式。我们使用 Grafana 创建了一个仪表盘,帮助我们轻松访问不同类型的指标。DevOps 团队可以使用这些图形和图表来关联不同的指标,以了解系统行为,并识别数据中的热点。这有助于保持合规性并实现应用程序的 SLA。总的来说,该性能监控系统有助于实现系统的持续监控。
这个性能监控系统受限于基于代理的 Profiler。基于代理的 Profiler 会消耗一定量的计算资源。有时可能需要进行故障排除和打补丁,这对于大型分布式系统来说可能很困难。在生产系统上安装代理之前,你可能需要先做一些调研工作。我们还必须考虑性能监控系统的安全性、可扩展性和可用性。通过正确设计和调整应用程序和系统,可以解决大多数问题。如果不允许在生产系统上安装代理,可以考虑使用无代理系统,但它也有自己的局限性,例如更少的细粒度指标和网络负载开销。
总结
对于复杂的 Spark 应用程序来说,识别、调试、解决生产环境的问题并非易事,我们需要一个有效的性能监控系统来帮助我们解决这些问题。Uber JVM Profiler 是一个很好的开源工具,我们可以扩展它,添加用于发布度量指标的 Reporter。不同 Profiler 收集的 Spark 应用程序性能指标可以存储在 InfluxDB 中。我们在本文中讨论的“InfluxDBOutputReporter”通过 HTTP API 将 Spark 驱动程序和执行程序的度量指标写入 InfluxDB。Grafana 为 InfluxDB 提供了一个插件,可以通过 HTTP API 查询指标。我们可以为这些指标创建包含图表的仪表盘,并以固定的时间间隔自动刷新。此处提供了“InfluxDBOutputReporter”的代码,此处提供了 Spark-InfluxDB-Grafana.json 文件。
参考
Uber JVM Profiler——https://eng.uber.com/jvm-profiler/
InfluxDB——https://docs.influxdata.com/influxdb/v1.6/
Grafana——http://docs.grafana.org/
关于作者
Amit Baghel 是一名软件架构师,在围绕 Java 生态系统的企业应用程序和产品的设计和开发方面拥有超过 17 年的经验。他目前重点关注物联网、云计算、大数据解决方案、微服务、DevOps 以及持续集成和交付。你可以通过电子邮件 baghel_amit@yahoo.com 联系 Baghel。
查看英文原文:https://www.infoq.com/articles/spark-application-monitoring-influxdb-grafana
相关推荐:

12 月 7 日北京 ArchSummit 全球架构师峰会上,来自 Uber 的讲师徐宏亮和付静将分享具有 Uber 特色的技术话题,“Uber 搭建基于 Kafka 的跨数据中心拷贝平台”、“Uber 外卖平台国际化架构演化之路”相关经验与实践。详情点击 https://bj2018.archsummit.com/schedule

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 2 条评论