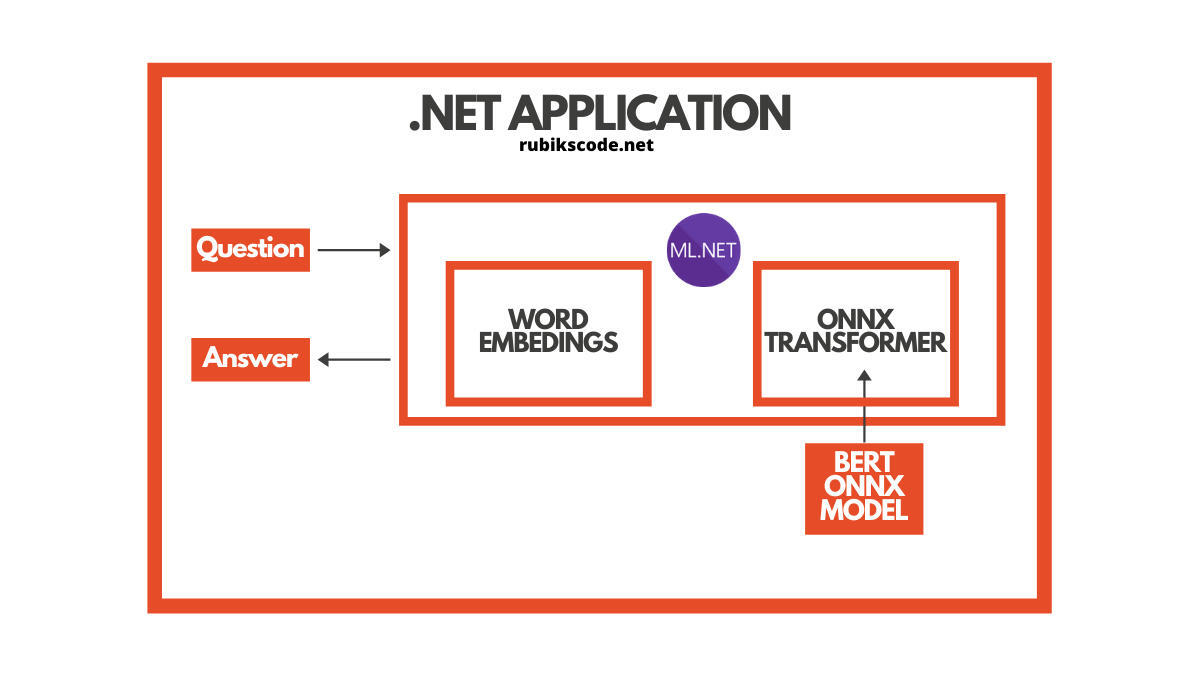
迄今为止,在我们的 ML.NET 之旅中,我们主要关注计算机视觉问题,例如图像分类和目标检测。在本文中,我们将转向自然语言处理,并探索一些我们可以用机器学习来解决的问题。
自然语言处理(Natural language processing,NLP)是人工智能的一个子领域,其主要目的是帮助程序理解和处理自然语言数据。这一过程的输出是一个计算机程序,它可以“理解”语言。
如果你担心人工智能会夺走你的饭碗,那么一定要成为它的创造者,并与不断上升的人工智能产业保持紧密联系。
追溯到 2018 年,谷歌发表了一篇论文,其中有一个深度神经网络叫做 Bidirectional Encoder Representations from Transformers 或 BERT。因为它的简单性,它成为目前最流行的一种自然语言处理算法。使用这种算法,任何人都能在短短的几个小时内训练自己最先进的问答系统(或其他各种模型)。在本文中,我们将使用 BERT 来创建一个问答系统。
BERT 是基于 Transformer 架构的神经网络。正因为如此,在本文中,我们将首先探索这个架构,然后再进一步了解 BERT:
前提
理解 Transformer 架构
BERT 直觉
ONNX 模型
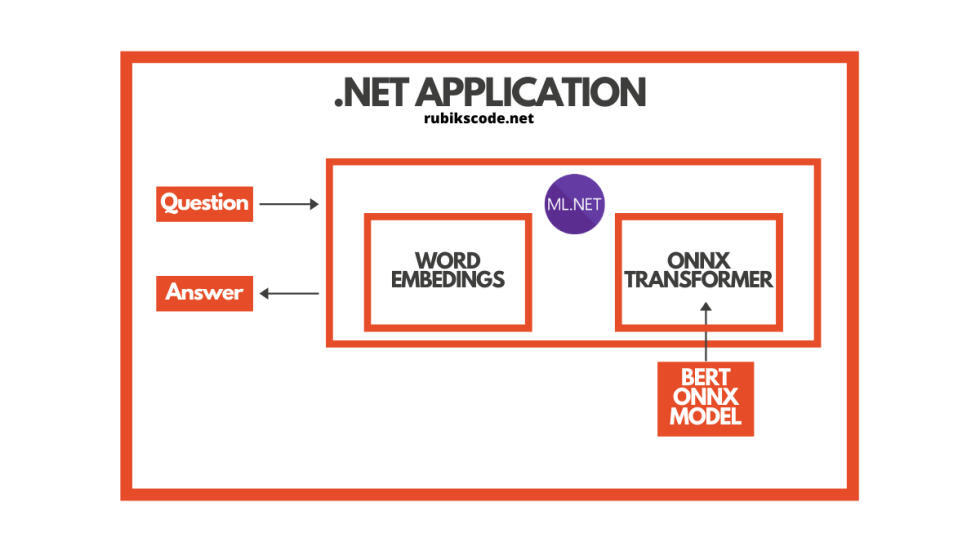
用 ML.NET 实现
1. 前提
本文的实现用 C# 语言完成,我们使用最新的 .NET 5。因此要确保你已安装此 SDK。若你正在使用 Visual Studio,则随附 16.8.3 版本。此外,确保你已安装下列软件包:
$ dotnet add package Microsoft.ML$ dotnet add package Microsoft.ML.OnnxRuntime$ dotnet add package Microsoft.ML.OnnxTransformer
复制代码
你可以在 Package Manager Console 中执行相同操作:
Install-Package Microsoft.MLInstall-Package Microsoft.ML.OnnxRuntimeInstall-Package Microsoft.ML.OnnxTransformer
复制代码
你可以使用 Visual Studio 的 Manage NuGetPackage 选项来执行类似操作:
假如你想了解使用 ML.NET 进行机器学习的基本知识,请看这篇文章:《使用 ML.NET 进行机器学习:简介》(Machine Learning with ML.NET – Introduction)。
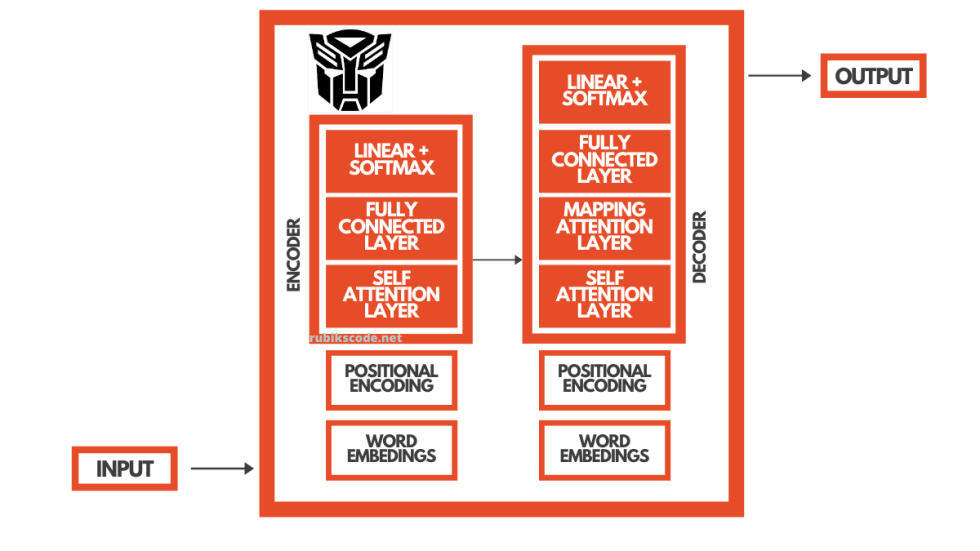
2. 理解 Transformer 架构
语言是顺序数据。从根本上说,你可以把它看成是一个词流,每个词的含义都取决于它前面的词和后面的词。因此,计算机理解语言非常困难,因为要想理解一个词,你需要一个上下文。
此外,有时候作为输出,还需要提供数据序列(词)。把英语翻译成塞尔维亚语就是一个好例子。我们将词序列作为算法的输入,同时对输出也需要提供一个序列。
本例中,一种算法要求我们理解英语,并理解如何将英语单词映射到塞尔维亚语单词(实质上,这意味着对塞尔维亚语也有某种程度的理解)。在过去的几年里,已经有很多深度学习的架构用于这种目的,例如递归神经网络(Recurrent Neural Network,RNN)和长短期记忆网络(LSTM)。但是,Transformer 架构的使用改变了一切。
由于 RNN 和 LSTM 难以训练,且已出现梯度消失(和爆炸),因此不能完全满足需求。Transformer 的目的就是解决这些问题,带来更好的性能和更好的语言理解。它们于 2017 年推出,并被发表在一篇名为《注意力就是你所需要的一切》(Attention is all you need)的传奇性论文上。
简而言之,他们使用编码器 - 解码器结构和自注意力层来更好地理解语言。如果我们回到翻译的例子,编码器负责理解英语,解码器负责理解塞尔维亚语,并将英语映射到塞尔维亚语。
在训练过程中,使用过程编码器从英语语言中提取词嵌入。计算机并不理解单词,它们理解的是数字和矩阵(一组数字)。这就是为什么我们要将词转换成向量空间,也就是说,我们为语言中的每个词分配某些向量(将它们映射到某些潜在的向量空间)。这些就是词嵌入。有许多可用的词嵌入,如 Word2Vec。
但是,该词在句子中的位置也是影响上下文的重要因素,所以才会有位置编码。编码器就是这样获取关于单词和它的上下文信息的。编码器的自注意力层确定了词之间的关系,并为我们提供了句子中每一个词相互关系的信息。编码器就是这样理解英语的。接着,数据进入深度神经网络,再进入解码器的映射 - 注意力层。
不过,在此之前,解码器已获取有关塞尔维亚语的同样信息。用同样的方法学习如何理解塞尔维亚语,使用词嵌入、位置编码和自注意力。解码器的映射 - 注意力层既有英语也有塞尔维亚语的信息,它只是学习如何从一种语言转换到另一种语言的词。如需有关 Transformer 的更多信息,请参阅这篇文章《Transformer 架构介绍》(Introduction to Transformers Architecture)。
3. BERT 直觉
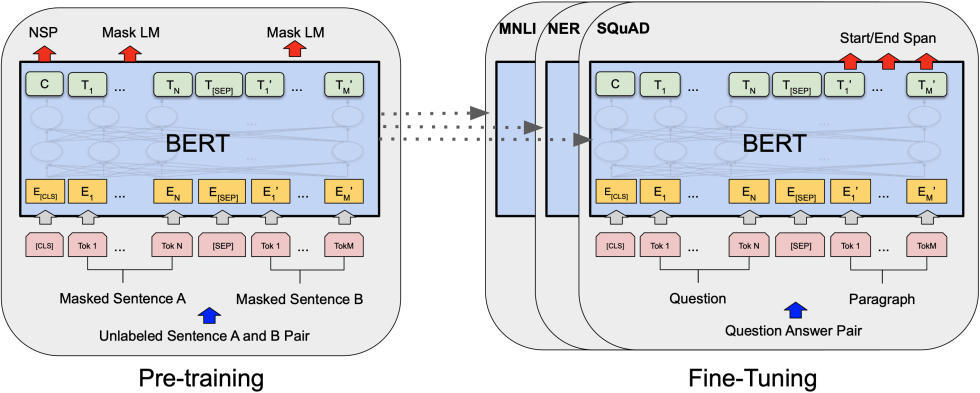
BERT 使用这种 Transformer 架构来理解语言。更为确切的是,它使用了编码器。这个架构有两大里程碑。首先,它实现了双向性。也就是说,每个句子都是双向学习的,并且更好地学习上下文,包括之前的上下文和将来的上下文。BERT 是首个采用纯文本语料(维基百科)进行训练的深度双向、无监督的语言表示。这也是最早应用于自然语言处理的一种预训练模型。在计算机视觉中,我们了解了迁移学习。但是,在 BERT 出现之前,这一概念就没有在自然语言处理领域得到重视。
这有很大的意义,因为你可以在大量的数据上训练模型,并且一旦模型理解了语言,你就可以根据更具体的任务对它进行微调。因此,BERT 的训练分为两个阶段:预训练和微调。
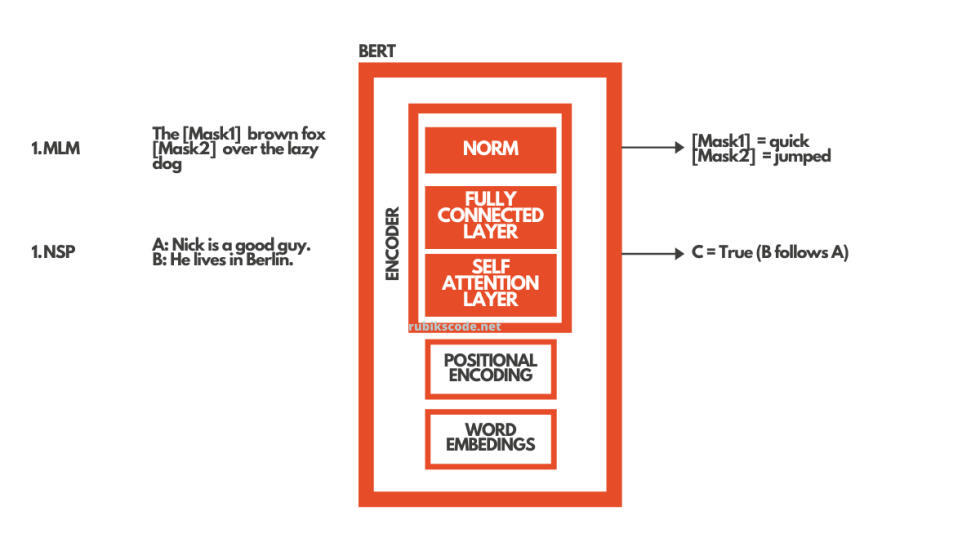
BERT 预训练采用两种方法实现双向性:
掩码语言建模使用掩码输入。这意味着句子中的一些词被掩码,BERT 的工作就是填补这些空白。下一句预测是给出两个句子作为输入,并期望 BERT 预测是一个句子接着另一个句子。在现实中,这两种方法都是同时发生的。
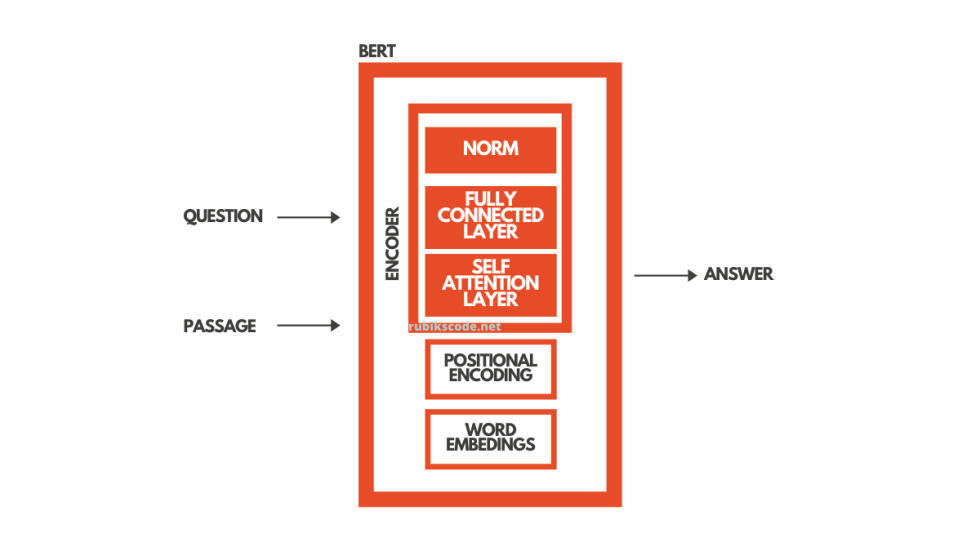
在微调阶段,我们为特定的任务训练 BERT。这就是说,如果我们想要创建一个问答系统的解决方案,我们只需要训练 BERT 的额外层。这正是我们在本教程中所做的。所有我们需要做的就是将网络的输出层替换为为我们特定目的设计的新层集。我们有文本段(或上下文)和问题作为输入,而作为输出,我们想要问题的答案。
举例来说,我们的系统,应该使用两个句子。为了提供答案“Jim”,可以使用“Jim is walking through the woods.”(段落或上下文)和“What is his name?” (问题)。
4. ONNX 模型
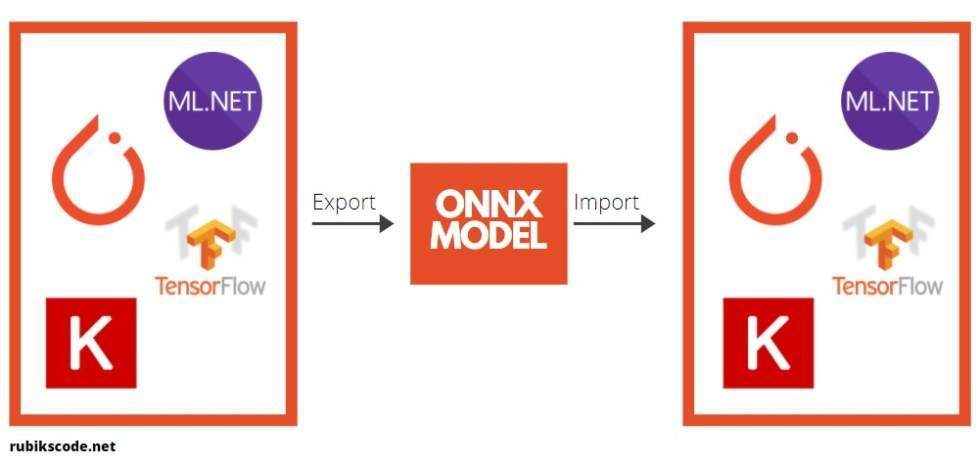
在进一步探讨利用 ML.NET 实现对象检测应用之前,我们还需要介绍一个理论上的内容。那就是开放神经网络交换( Open Neural Network Exchange,ONNX)文件格式。这种文件格式是人工智能模型的一种开源格式,它支持框架之间的互操作性。
你可以用机器学习的框架(比如 PyTorch)来训练模型,保存模型,并将其转换为 ONNX 格式。那么你就可以将 ONNX 模型用于另一个框架,比如 ML.NET。这正是我们在本教程中所做的内容。你可以在 ONNX 网站上找到详细信息。
在本教程中,我们使用了预训练 BERT 模型,在这里可以找到该模型,即 BERT SQUAD。简而言之就是,我们将这个模型导入到 ML.NET 中,并在应用中运行它。
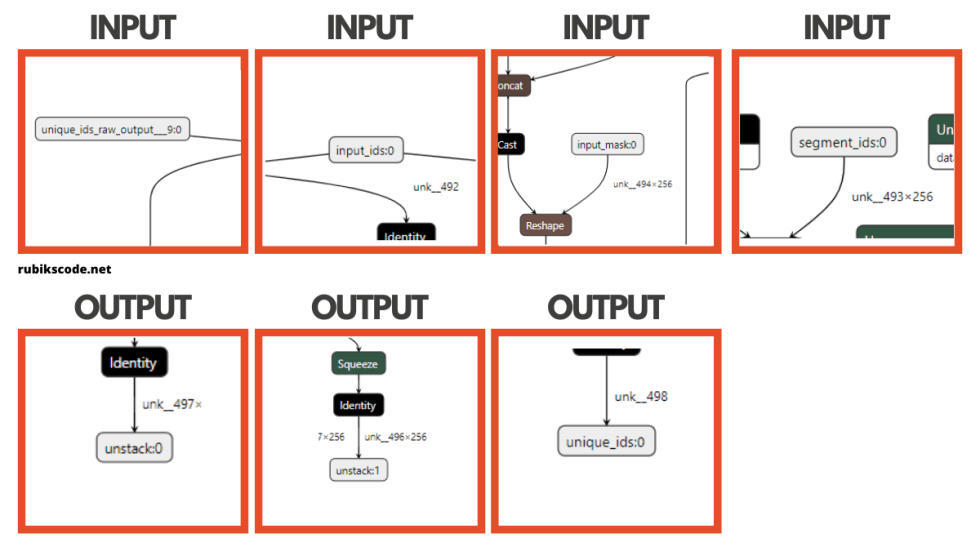
在 ONNX 模型中,有一件非常有趣且有用的事情,那就是我们可以使用一系列工具来对模型进行可视化表示。这在像本教程一样使用预训练模型的情况下很有用。
我们常常需要知道输入层和输出层的名字,而这个工具在这方面很有优势。所以,下载 BERT 模型之后,我们就可以使用这些工具中的一种来加载它,并进行可视化表示。我们在这个指南中使用 Netron,这里只有一部分输出:
我知道,这太疯狂了,BERT 是个大模型。你可能会想,我怎么能用这个,为什么我需要它?但是,为了使用 ONNX 模型,我们通常需要知道模型的输入和输出层的名称。BERT 看起来是下面这样的:
5. 用 ML.NET 实现
在我们下载模型的 BERT-Squad 仓库中,你会注意到关于依赖性的有趣部分。更为确切的说,你将注意到依赖于 tokenization.py。这意味着我们需要自己进行标记化处理。词标记化是将大量的文本样本分割成词的一个过程。在自然语言处理中,每一个词都需要捕捉,并进行进一步分析。做这件事的方法有很多。
实际上,我们进行词编码,并为此使用 Word-Piece Tokenization,正如这篇论文所描述的那样。该版本由 tokenzaton.py 移植。为实现这一复杂的解决方案,我们构建了这样的解决方案:
在 Assets 文件夹中,你可以找到下载的 .onnx 模型和包含词汇的文件夹,我们要在这些词汇上训练我们的模型。Machine Learning 文件夹包含我们在这个应用程序中所需要的代码。Trainer 和 Predictor 类就在这里,就像为数据建模的类一样。在单独的文件夹中,我们可以找到用于加载文件的 helper 类和用于 Softmax 的 Enumerable 类型的 extension 类以及字符串的拆分。
这个解决方案的灵感来源于 Gjeran Vlot 的实现,你可以在这里找到。
5.1 数据模型
你可能注意到,在 DataModel 文件夹中,我们为 BERT 的输入和预测提供了两个类。BertInput 类是用来表示输入的。它们的名称和大小与模型中的层类似:
using Microsoft.ML.Data;
namespace BertMlNet.MachineLearning.DataModel{ public class BertInput { [VectorType(1)] [ColumnName("unique_ids_raw_output___9:0")] public long[] UniqueIds { get; set; }
[VectorType(1, 256)] [ColumnName("segment_ids:0")] public long[] SegmentIds { get; set; }
[VectorType(1, 256)] [ColumnName("input_mask:0")] public long[] InputMask { get; set; }
[VectorType(1, 256)] [ColumnName("input_ids:0")] public long[] InputIds { get; set; }}}
复制代码
Bertpredictions 类使用 BERT 输出层:
using Microsoft.ML.Data;
namespace BertMlNet.MachineLearning.DataModel{ public class BertPredictions { [VectorType(1, 256)] [ColumnName("unstack:1")] public float[] EndLogits { get; set; }
[VectorType(1, 256)] [ColumnName("unstack:0")] public float[] StartLogits { get; set; }
[VectorType(1)] [ColumnName("unique_ids:0")] public long[] UniqueIds { get; set; } }}
复制代码
5.2 训练器
Trainer(训练器)类非常简单,它只有一个方法 BuildAndTrain,使用预训练模型的路径。
using BertMlNet.MachineLearning.DataModel;using Microsoft.ML;using System.Collections.Generic;
namespace BertMlNet.MachineLearning{ public class Trainer { private readonly MLContext _mlContext;
public Trainer() { _mlContext = new MLContext(11); }
public ITransformer BuidAndTrain(string bertModelPath, bool useGpu) { var pipeline = _mlContext.Transforms .ApplyOnnxModel(modelFile: bertModelPath, outputColumnNames: new[] { "unstack:1", "unstack:0", "unique_ids:0" }, inputColumnNames: new[] {"unique_ids_raw_output___9:0", "segment_ids:0", "input_mask:0", "input_ids:0" }, gpuDeviceId: useGpu ? 0 : (int?)null);
return pipeline.Fit(_mlContext.Data.LoadFromEnumerable(new List<BertInput>())); }}
复制代码
在上述方法中,我们建立了管道。在这里,我们应用 ONNX 模型并将数据模型与 BERT ONNX 模型的各个层连接起来。请注意,我们有一个标志,可以用来在 CPU 或 GPU 上训练这个模型。最后,我们将该模型与空白数据进行拟合。这么做的目的是加载数据模式,即加载模型。
5.3 预测器
Predictor(预测器)类甚至更加简单。它接收一个经过训练和加载的模型,并创建一个预测引擎。然后它使用这个预测引擎为新图像创建预测。
using BertMlNet.MachineLearning.DataModel;using Microsoft.ML;
namespace BertMlNet.MachineLearning{ public class Predictor { private MLContext _mLContext; private PredictionEngine<BertInput, BertPredictions> _predictionEngine; public Predictor(ITransformer trainedModel) { _mLContext = new MLContext(); _predictionEngine = _mLContext.Model .CreatePredictionEngine<BertInput, BertPredictions>(trainedModel); }
public BertPredictions Predict(BertInput encodedInput) { return _predictionEngine.Predict(encodedInput); }}}
复制代码
5.4 助手和扩展
有一个 helper(助手)类和两个 extension(扩展)类。helper 类 FileReader 有一个读取文本文件的方法。我们稍后用它来从文件中加载词汇表。它非常简单:
using System.Collections.Generic;using System.IO;
namespace BertMlNet.Helpers{ public static class FileReader { public static List<string> ReadFile(string filename) { var result = new List<string>(); using (var reader = new StreamReader(filename)) { string line;
while ((line = reader.ReadLine()) != null) { if (!string.IsNullOrWhiteSpace(line)) { result.Add(line); } } }
return result; }}}
复制代码
有两个 extension 类。一个用于对元素集合进行 Softmax 操作,另一个用于分割字符串并一次处理一个结果。
using System;using System.Collections.Generic;using System.Linq;
namespace BertMlNet.Extensions{ public static class SoftmaxEnumerableExtension { public static IEnumerable<(T Item, float Probability)> Softmax<T>( this IEnumerable<T> collection, Func<T, float> scoreSelector) { var maxScore = collection.Max(scoreSelector); var sum = collection.Sum(r => Math.Exp(scoreSelector(r) - maxScore));
return collection.Select(r => (r, (float)(Math.Exp(scoreSelector(r) - maxScore) / sum))); }}}
复制代码
using System.Collections.Generic;
namespace BertMlNet.Extensions{ static class StringExtension { public static IEnumerable<string> SplitAndKeep( this string inputString, params char[] delimiters) { int start = 0, index;
while ((index = inputString.IndexOfAny(delimiters, start)) != -1) { if (index - start > 0) yield return inputString.Substring(start, index - start);
yield return inputString.Substring(index, 1);
start = index + 1; }
if (start < inputString.Length) { yield return inputString.Substring(start); } }}}
复制代码
5.5 词法分析器
到目前为止,我们已经探索过解决方案的简单部分。接下来,我们来看一看如何实现标记化,从而了解更复杂和重要的部分。先定义一个默认的 BERT 标记列表。举例来说,两个句子都应该使用 [SEP] 标记来区分。[CLS] 标记总是出现在文本的开头,并特定于分类任务。
namespace BertMlNet.Tokenizers{ public class Tokens { public const string Padding = ""; public const string Unknown = "[UNK]"; public const string Classification = "[CLS]"; public const string Separation = "[SEP]"; public const string Mask = "[MASK]"; }}
复制代码
在 Tokenizer(词法分析器)类中完成标记化的过程。有两个公共方法:Tokenize 和 Untokenize。第一个方法首先将接收的的文本分割成若干句子,然后对于每个句子,每个词都被转换为嵌入。需要注意的是,一个词可能会出现用多个标记表示的情况。
举例来说,单词“embeddings”表示为标记数组:['em', '##bed', '##ding', '##s']。这个词已经被分割成更小的子词和字符,其中一些子词前面有两个 # 号,这只是我们的词法分析器的方式,表示这个子词或字符是一个大词的一部分,前面是另一个子词。
因此,例如,'##bed' 标记与 'bed' 标记是分开的。标记方法所做的另一件事是返回词汇索引和分割索引。这两个都是 BERT 输入。如果想知道更多的原因,请查阅这篇文章《BERT 词嵌入教程》(BERT Word Embeddings Tutorial)。
using BertMlNet.Extensions;using System;using System.Collections.Generic;using System.Linq;
namespace BertMlNet.Tokenizers{ public class Tokenizer { private readonly List<string> _vocabulary;
public Tokenizer(List<string> vocabulary) { _vocabulary = vocabulary; }
public List<(string Token, int VocabularyIndex, long SegmentIndex)> Tokenize(params string[] texts) { IEnumerable<string> tokens = new string[] { Tokens.Classification };
foreach (var text in texts) { tokens = tokens.Concat(TokenizeSentence(text)); tokens = tokens.Concat(new string[] { Tokens.Separation }); }
var tokenAndIndex = tokens .SelectMany(TokenizeSubwords) .ToList();
var segmentIndexes = SegmentIndex(tokenAndIndex);
return tokenAndIndex.Zip(segmentIndexes, (tokenindex, segmentindex) => (tokenindex.Token, tokenindex.VocabularyIndex, segmentindex)).ToList(); }
public List<string> Untokenize(List<string> tokens) { var currentToken = string.Empty; var untokens = new List<string>(); tokens.Reverse();
tokens.ForEach(token => { if (token.StartsWith("##")) { currentToken = token.Replace("##", "") + currentToken; } else { currentToken = token + currentToken; untokens.Add(currentToken); currentToken = string.Empty; } });
untokens.Reverse();
return untokens; }
public IEnumerable<long> SegmentIndex(List<(string token, int index)> tokens) { var segmentIndex = 0; var segmentIndexes = new List<long>();
foreach (var (token, index) in tokens) { segmentIndexes.Add(segmentIndex);
if (token == Tokens.Separation) { segmentIndex++; } }
return segmentIndexes; }
private IEnumerable<(string Token, int VocabularyIndex)> TokenizeSubwords(string word) { if (_vocabulary.Contains(word)) { return new (string, int)[] { (word, _vocabulary.IndexOf(word)) }; }
var tokens = new List<(string, int)>(); var remaining = word;
while (!string.IsNullOrEmpty(remaining) && remaining.Length > 2) { var prefix = _vocabulary.Where(remaining.StartsWith) .OrderByDescending(o => o.Count()) .FirstOrDefault();
if (prefix == null) { tokens.Add((Tokens.Unknown, _vocabulary.IndexOf(Tokens.Unknown)));
return tokens; }
remaining = remaining.Replace(prefix, "##");
tokens.Add((prefix, _vocabulary.IndexOf(prefix))); }
if (!string.IsNullOrWhiteSpace(word) && !tokens.Any()) { tokens.Add((Tokens.Unknown, _vocabulary.IndexOf(Tokens.Unknown))); }
return tokens; }
private IEnumerable<string> TokenizeSentence(string text) { // remove spaces and split the , . : ; etc.. return text.Split(new string[] { " ", " ", "\r\n" }, StringSplitOptions.None) .SelectMany(o => o.SplitAndKeep(".,;:\\/?!#$%()=+-*\"'–_`<>&^@{}[]|~'".ToArray())) .Select(o => o.ToLower()); }}}
复制代码
另一个公共方法是 Untokenize。这个方法被用于逆转这一过程。从根本上说,BERT 的输出会产生大量的嵌入信息。这个方法的目的是把这些信息转化成有意义的句子。
该类具有使该过程成为现实的多种方法。
5.6 BERT
Bert 类将所有这些东西放在一起。在构造函数中,我们读取词汇文件并实例化 Train、Tokenizer 和 Predictor 对象。这里只有一个公共方法:Predict。这个方法接收上下文和问题。作为输出,将检索出具有概率的答案:
using BertMlNet.Extensions;using BertMlNet.Helpers;using BertMlNet.MachineLearning;using BertMlNet.MachineLearning.DataModel;using BertMlNet.Tokenizers;using System.Collections.Generic;using System.Linq;
namespace BertMlNet{ public class Bert { private List<string> _vocabulary;
private readonly Tokenizer _tokenizer; private Predictor _predictor;
public Bert(string vocabularyFilePath, string bertModelPath) { _vocabulary = FileReader.ReadFile(vocabularyFilePath); _tokenizer = new Tokenizer(_vocabulary);
var trainer = new Trainer(); var trainedModel = trainer.BuidAndTrain(bertModelPath, false); _predictor = new Predictor(trainedModel); }
public (List<string> tokens, float probability) Predict(string context, string question) { var tokens = _tokenizer.Tokenize(question, context); var input = BuildInput(tokens);
var predictions = _predictor.Predict(input);
var contextStart = tokens.FindIndex(o => o.Token == Tokens.Separation);
var (startIndex, endIndex, probability) = GetBestPrediction(predictions, contextStart, 20, 30);
var predictedTokens = input.InputIds .Skip(startIndex) .Take(endIndex + 1 - startIndex) .Select(o => _vocabulary[(int)o]) .ToList();
var connectedTokens = _tokenizer.Untokenize(predictedTokens);
return (connectedTokens, probability); }
private BertInput BuildInput(List<(string Token, int Index, long SegmentIndex)> tokens) { var padding = Enumerable.Repeat(0L, 256 - tokens.Count).ToList();
var tokenIndexes = tokens.Select(token => (long)token.Index).Concat(padding).ToArray(); var segmentIndexes = tokens.Select(token => token.SegmentIndex).Concat(padding).ToArray(); var inputMask = tokens.Select(o => 1L).Concat(padding).ToArray();
return new BertInput() { InputIds = tokenIndexes, SegmentIds = segmentIndexes, InputMask = inputMask, UniqueIds = new long[] { 0 } }; }
private (int StartIndex, int EndIndex, float Probability) GetBestPrediction(BertPredictions result, int minIndex, int topN, int maxLength) { var bestStartLogits = result.StartLogits .Select((logit, index) => (Logit: logit, Index: index)) .OrderByDescending(o => o.Logit) .Take(topN);
var bestEndLogits = result.EndLogits .Select((logit, index) => (Logit: logit, Index: index)) .OrderByDescending(o => o.Logit) .Take(topN);
var bestResultsWithScore = bestStartLogits .SelectMany(startLogit => bestEndLogits .Select(endLogit => ( StartLogit: startLogit.Index, EndLogit: endLogit.Index, Score: startLogit.Logit + endLogit.Logit ) ) ) .Where(entry => !(entry.EndLogit < entry.StartLogit || entry.EndLogit - entry.StartLogit > maxLength || entry.StartLogit == 0 && entry.EndLogit == 0 || entry.StartLogit < minIndex)) .Take(topN);
var (item, probability) = bestResultsWithScore .Softmax(o => o.Score) .OrderByDescending(o => o.Probability) .FirstOrDefault();
return (StartIndex: item.StartLogit, EndIndex: item.EndLogit, probability); }}}
复制代码
Predict 方法会执行一些步骤。让我们来详细讨论一下。
public (List<string> tokens, float probability) Predict(string context, string question) { var tokens = _tokenizer.Tokenize(question, context); var input = BuildInput(tokens);
var predictions = _predictor.Predict(input);
var contextStart = tokens.FindIndex(o => o.Token == Tokens.Separation);
var (startIndex, endIndex, probability) = GetBestPrediction(predictions, contextStart, 20, 30);
var predictedTokens = input.InputIds .Skip(startIndex) .Take(endIndex + 1 - startIndex) .Select(o => _vocabulary[(int)o]) .ToList();
var connectedTokens = _tokenizer.Untokenize(predictedTokens);
return (connectedTokens, probability); }
复制代码
首先,该方法对问题和传递的上下文(基于 BERT 应该给出答案的段落)进行标记化。基于这些信息,我们建立了BertInput。这是在 BertInput 方法中完成的。基本上,所有标记化的信息都被填充了,因此可以将其作为 BERT 的输入,并用于初始化 BertInput 对象。
然后我们从 Predictor 获得模型的预测结果。这些信息会得到额外的处理,并且根据上下文找到最佳预测。也就是说,BERT 从上下文中选出最有可能是答案的词,然后我们选出最好的词。最后,这些词都是未标记的。
5.7 程序
Program(程序)是利用了我们在 Bert 类中实现的内容。首先,让我们定义启动设置:
{ "profiles": { "BERT.Console": { "commandName": "Project", "commandLineArgs": "\"Jim is walking through the woods.\" \"What is his name?\"" } }}
复制代码
我们定义了两个命令行参数:“Jim is walking throught the woods.”和“What is his name?”。正如我们已经提到的,第一个参数是上下文,第二个参数是问题。Main 方法是最小的。
using System;using System.Text.Json;
namespace BertMlNet{ class Program { static void Main(string[] args) { var model = new Bert("..\\BertMlNet\\Assets\\Vocabulary\\vocab.txt", "..\\BertMlNet\\Assets\\Model\\bertsquad-10.onnx");
var (tokens, probability) = model.Predict(args[0], args[1]);
Console.WriteLine(JsonSerializer.Serialize(new { Probability = probability, Tokens = tokens })); } }
复制代码
在技术上,我们用词汇表文件的路径和模型的路径创建 Bert 对象。然后我们用命令行参数调用 Predict 方法。我们得到的输出是这样的:
{"Probability":0.9111285,"Tokens":["jim"]}
复制代码
我们可以看到,BERT 有 91% 的把握认为问题的答案是“Jim”,而且是正确的。
结语
通过这篇文章,我们了解了 BERT 的工作原理。更具体地说,我们有机会探索 Transformer 架构的工作原理,并了解 BERT 如何利用该架构来理解语言。最后,我们学习了 ONNX 模型格式,以及如何将它用于 ML.NET。
作者介绍:
Nikola M. Zivkovic 是 Rubik's Code 的首席人工智能官,也是《Deep Learning for Programmers》(尚无中译本)一书的作者。热爱知识分享,是一位经验丰富的演讲者,也是塞尔维亚诺维萨德大学的客座讲师。
原文链接:
https://rubikscode.net/2021/04/19/machine-learning-with-ml-net-nlp-with-bert/














评论