

为了维护良好的社区氛围,帮助知友们在轻松愉悦的环境中分享彼此的知识、经验和见解,我们在算法、产品和规则上进行了很多尝试。昨天
@知乎小管家 也在自己的专栏中进行了整体地介绍了算法最新的进展: 瓦力解锁新技能:实时识别处理多种违规行为。其实,知一声也邀请了几位小伙伴来从技术的角度分享算法识别背后的原理。
近期,我们发现社区内出现了垃圾广告的导流内容,影响用户体验,破坏认真、专业和友善的社区氛围。为了解决这种情况,我们进行了大量努力和探索。最开始在识别导流信息上采用的是干扰转换+正则匹配+匹配项回溯的方式进行异常导流信息的识别与控制,取得了很好的效果。
但是我们发现,随着我们处理这些内容的同时,他们正在逐步增加导流信息的各种变体,常见的有以下几种方式:第一种变体是导流前缀的变化,如 QQ 导流前缀变化成企鹅,「腾顺」等等;第二变体是不使用前缀,如退款 123377281;第三种变体是导流中随机插入非特殊字符,如 319xxxx053xxxx7178。我们对这些变体进行了收集整理和分析。
通过对典型导流样本的分析,我们发现尽管导流信息变体在不断演化,但是它们所在的上下文变化并不明显。因此,我们尝试通过序列标注的方式来识别导流内容,提高算法的识别准确度。
模型
常用的序列标注算法,有 HMM、CRF、RNN、BILSTM-CRF 等。BILSTM-CRF 在多个自然语言序列标注问题(NER、POS)上都表现优秀,同时,通过实验,我们也发现 BILSTM-CRF 表现优于其他模型。
网络结构
BILSTM-CRF 模型结构如下图所示。
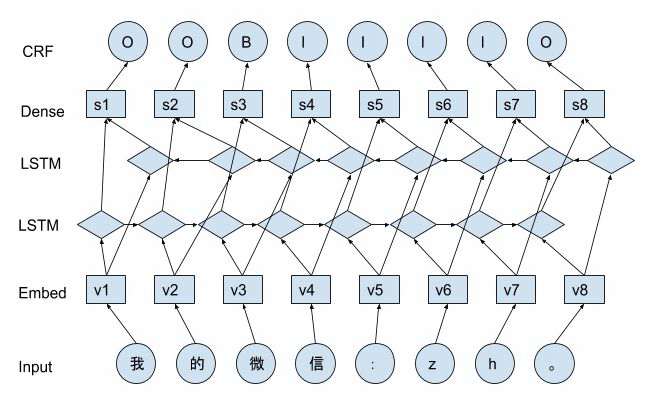
第一层为 Embedding 层,将输入文本转换为词向量表示。
第二层为双向 LSTM 层。LSTM 具有强大的序列建模能力,能够捕捉长远的上下文信息,同时还拥有神经网络拟合非线性的能力。相比单向的 LSTM,双向 LSTM 不仅能够利用以前的上下文信息,还能利用未来的上下文信息。
第三层为一个全连接层。作用是将上一层的输出,映射为 [T,C] 的向量,T 为输入序列长度,C 为标签数量。输出的也就是每个 timestep 对应的状态 score。
最后一层为 linear-chain CRF 层。CRF 计算的是一种联合概率,优化的是整个序列(最终目标),而不是将每个时刻的最优拼接起来。在 CRF 层,使用 viterbi 解码算法从状态 score 和转移矩阵中解码得到输出状态序列。
BILSTM-CRF 模型同时结合了 LSTM 和 CRF 的优点,使得其在序列标注任务上具有极强的优势。
CRF
从上述网络结构,可知要优化的目标函数由最后一层决定。
通常给定一个线性链条件随机场 ,当观测序列为时,标签序列为的概率可写为
其中,Z(x) 为归一化函数,对所有可能的标签序列求和。是特征函数,通常考虑转移特征和状态特征两方面。状态特征描述标签之间的相似程度,是上一层网络的输出。
转移特征考虑状态之间的变化趋势
在模型的概率给出之后,可以使用最大似然估计优化参数,即最小化负对数似然 -logP(y|x),从而得到整个网络的 loss function。
是否包含前后缀?
训练模型之前,我们需要标记训练数据。
标记训练数据的一个问题是,是否要包含导流信息的前后缀。如「加 V:xxxxxx」,是否需要包含「加 V」。通常情况下,答案应该是不包含,因为我们的实体是微信号,「加 V」不属于我们要识别的实体。
但是,我们在实验过程中发现,如果不加前后缀,模型会把大量的英文单词,或者字母数字组合,标记为导流内容。原因是,作为中文社区,英文单词出现频率很低,同时大部分导流信息都是字母数字组合,从而使得模型出现错误。
针对这种情况,我们在处理数据时,将导流信息的前后缀也作为实体的一部分,有效的降低了上述问题出现的概率。
实体编码
序列标注模型另一个需要注意的问题是,实体编码的格式。常用的序列实体编码方式有 IO、BIO、BMEWO 三种。
IO 编码是最简单的编码,它将属于类型 X 的实体的序列元素标记为 I_X,不属于任何实体的序列元素标记为 O。这种编码存在缺陷,因为它不能代表彼此相邻的两个实体,因为没有边界标签。
BIO 编码是当前实体编码的行业标准。它将表示实体的 I_X 标签细分为实体开始标签 B_X 和实体延续标签 I_X。
BMEWO 编码进一步区分实体结束元素 E_X 和实体中间元素令 M_X,并为单元素实体添加一个全新的标签 W_X。
上述三种编码的示例,如下所示:
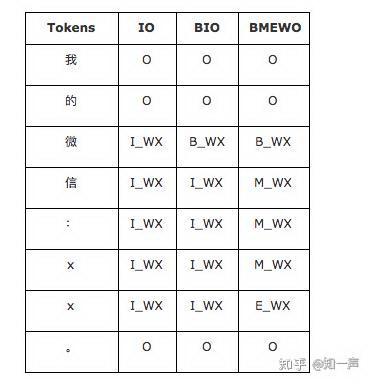
综合考虑,我们选择 BIO 编码,一是满足我们对于导流信息的区分,二是其标记方式相对通用。
效果
在实验阶段,分别将 HMM、BILSTM、BIGRU、BILSTM-CRF 做了一系列的对比,将表现比较好的 BILSTM-CRF 放在线上与原本的 Base 模型进行 AB 实验。从结果上来看,宽深度学习模型在线下/线上都有比较好的效果。线上实验结论如下:

后续的改进
为了提高模型的效果,我们需要使用更多的训练数据,构造更复杂的网络结构,使用更多的超参数设置训练模型。然而,不断增加的模型尺寸和超参数极大地延长了训练时间。很明显,计算能力已经成为了模型优化的主要瓶颈。相比 CNN 和 Attention 等操作,LSTM 仍然不太适应多线程 /GPU 计算,训练速度偏慢,不能充分利用 GPU 的并行计算优势。因此,我们还在尝试 SRU 等 RNN 加速方案,希望在模型效果损失不大的情况下,提高模型的训练速度。
我们当前采用的是 Char-based model,Char-based model 在一个优势在于利用词元(lemmas)和形态学信息(morphological information ),能更好的处理导流内容内部结构,如手机号的组成。另一方面,Word-based model 更多的利用词语信息,词语比字具有更高的抽象等级,通常正确率会更高。我们希望通过训练一个新的分词模型的方式,使得在保持处理导流内容内部结构的情况下,构建 Word-based model。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论