

一、简介
在企业级业务系统日趋复杂的背景下,微服务架构逐渐成为了许多中大型企业的标配,它将庞大的单体应用拆分成多个子系统和公共的组件单元。这一理念带来了许多好处:复杂系统的拆分简化与隔离、公共模块的重用性提升与更合理的资源分配、大大提升了系统变更迭代的速度、更灵活的可扩展性以及在云计算中的适用性,等等。
但是微服务架构也带来了新的问题:拆分后每个用户请求可能需要数十个子系统的相互调用才能最终返回结果,如果某个请求出错可能需要逐个子系统排查定位问题;或者某个请求耗时比较高,但是很难知道时间耗在了哪个子系统中。全链路追踪系统就是为了解决微服务场景下的这些问题而诞生的。一般地,该系统由几大部分组成:
客户端埋点SDK:集成在各业务应用系统中,完成链路追踪、数据采集、数据上报等功能;
实时数据处理系统:对客户端采集上来的数据进行实时计算和相关处理,建立必要索引和存储等;
用户交互系统:提供用户交互界面,供开发、测试、运维等用户最终使用链路追踪系统提供的各项功能;
离线分析系统:对链路追踪数据进行离线分析,提供诸多强大的链路统计分析和问题发现功能;
二、多语言
有赞目前的应用类型有很多种,已经支持追踪的语言有 Java、Node.js、PHP。那么,如何让跨不同语言的调用链路串到一起呢?有赞的链路追踪目前在使用的是 Cat 协议,业界也已经有比较成熟的开源协议:OpenTracing,OpenTracing 是一个“供应商中立”的开源协议,使用它提供的各语言的 API 和标准数据模型,开发人员可以方便的进行链路追踪,并能轻松打通不同语言的链路。
Cat 协议与 OpenTracing 协议在追踪思路和 API 上是大同小异的。基本思路是 Trace 和 Span:Trace 标识链路信息、Span 标识链路中具体节点信息。一般在链路的入口应用中生成 traceId 和 spanId,在后续的各节点调用中,traceId 保持不变并全链路透传,各节点只产生自己的新的 spanId。这样,通过 traceId 唯一标识一条链路,spanId 标识链路中的具体节点的方式串起整个链路。一个简单的示意图如下:
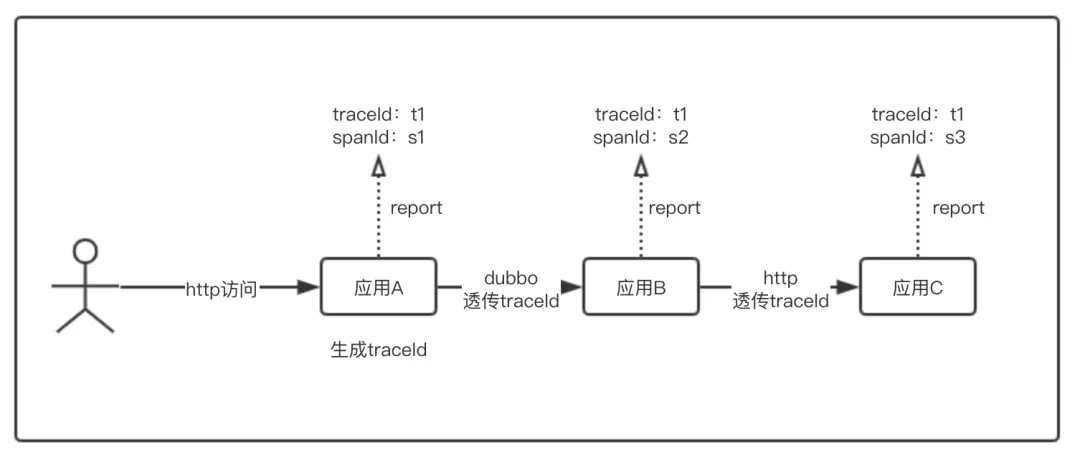
实际每个节点上报的数据中还包含一些其他信息,比如:时间戳、服务标识、父子节点的id等等。
三、客户端埋点 SDK
3.1 Java Agent 与 Attach API
Java Agent 一般通过在应用启动参数中添加 -javaagent参数添加 ClassFileTransformer字节码转换器。JVM 在类加载时触发 JVMTI_EVENT_CLASS_FILE_LOAD_HOOK事件调用添加的字节码转换器完成字节码转换,该过程时序如下:
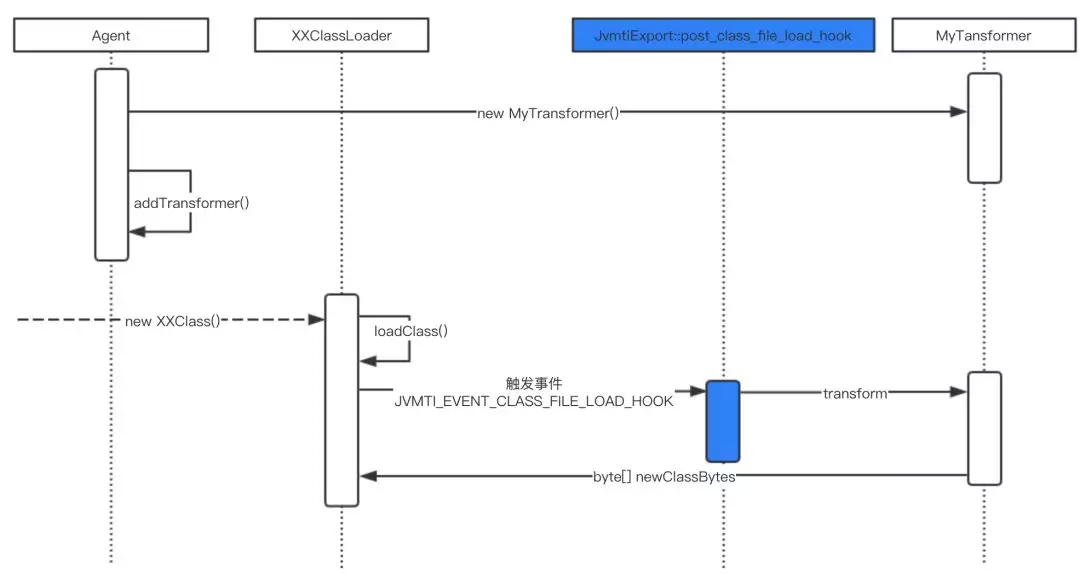
Java Agent所使用的Instrumentation依赖JVMTI实现,当然也可以绕过Instrumentation直接使用JVMTI实现Agent。JVMTI 与 JDI 组成了 Java 平台调试体系(JPDA)的主要能力。
有赞的应用启动脚本都是由业务方各自维护,因此要在成百上千的应用启动脚本中添加 -javaagent 参数是个不小的工作量。Java 从 Java 6 开始提供了 JVMAttachAPI,可以在运行时动态 attach 到某个 JVM 进程上。AttacheAPI需要的进程 pid 参数,如果获取当前进程的 pid 是一个难点。不同的 JVM 版本有不同的方式,比较方便的是,字节码增强框架 Byte-Buddy 已经封装好了上述过程:JMX或 java.lang.ProcessHandle接口获取当前进程的 pid,只需要使用 ByteBuddyAgent.install()就能 attach 到当前进程。
Byte-Buddy是一个优秀的字节码增强框架,基于ASM实现,提供了比较高级的subClass()、redefine()、rebase()接口,并抽象了强大丰富的Class和Method匹配API。
3.2 透明升级
有赞内部的框架和中间件组件已经进行统一托管,由专门的 Jar 包容器负责托管加载工作,几乎所有 Java 应用都接入了该 Jar 包容器,Jar 包容器在应用的类加载之前启动。借助 Jar 包容器提供的入口,链路追踪的 SDK 在应用启动之前完成字节码转换器的装载工作,同时 SDK 也托管在该 Jar 包容器中,进而在实现应用无感知的追踪同时,又实现了全链路追踪 SDK 的透明升级。整个带起过程如下图所示:
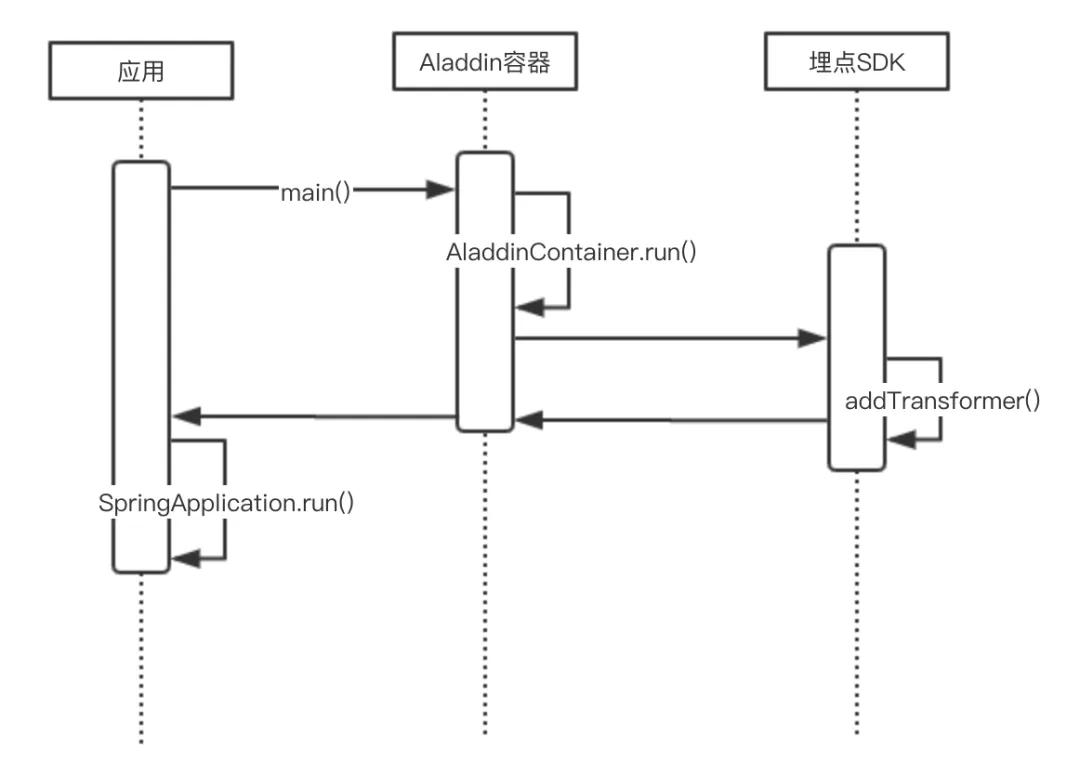
应用无感知的自动化追踪与透明升级方式,大大提升了后续迭代的速度,应用接入成本降到 0、追踪应用的比例接近 100%,为后续发展带来了更多可能。与非透明方式的追踪对比如下:
3.3 异步调用追踪
请求在一个进程内部可能会有多个子调用,Trace 信息在进程内部共享一般是通过 ThreadLocal实现的,但是当有异步调用情形时,这部分调用可能就会在链路中丢失。我们需要做的是跨线程透传 Trace 信息,虽然 JDK 内置的 InheritableThreadLocal支持父子线程传递,但是当面对线程池中线程复用的场景时还是不能满足需求。
比较常见的解决方案是 Capture/Replay模型:在创建异步线程时将当前线程上下文进行 Capture快照,并传递到子线程中,在子线程运行时先通过 Replay回放设置传递过来快照信息到当前上下文。具体流程如图:
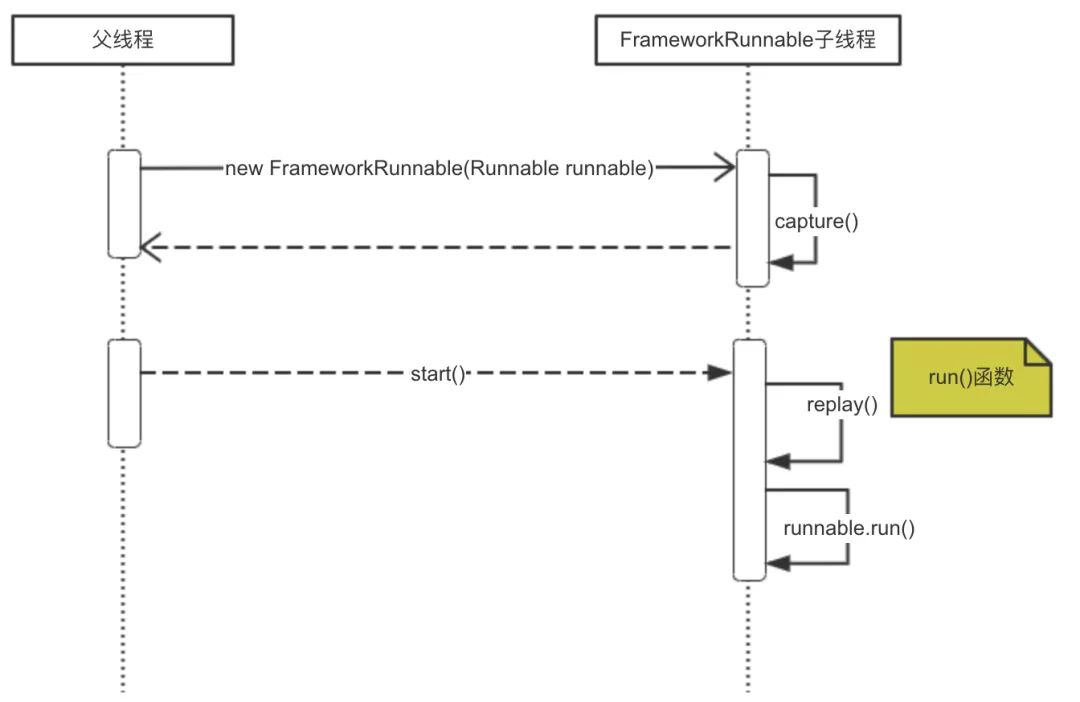
因为内部有通用的线程工具类 FrameworkRunnable和 FrameworkCallable,因此只需要对这两个工具类进行统一增强就可以满足大部分异步调用的追踪场景。另外提供了异步处理工具 AsyncUtil,在使用了自定义线程时,使用 AsyncUtil.wrap()对自定义线程进行包装即可实现 Capture/Replay的过程。
3.4 遇到的问题
包冲突问题:链路追踪SDK依赖的一些包可能会与业务系统的依赖发生版本冲突,比如SDK依赖的Byte-Buddy框架在很多应用中也有间接依赖,SDK在使用过程中加载的Jar可能会与应用依赖的版本冲突。使用maven的shade插件可以有效的解决这个问题,shade插件基于ASM实现,通过扫描SDK Class中的import引用进行包名替换,可以有效避免这个问题,详细的使用用法请参照maven-shade-plugin文档;
API耦合问题:除了Java Agent透明追踪外,某些场景需要提供API给业务系统显式调用,而API要完成相关功能就必须与SDK的逻辑有交互,这样业务系统就必须通过API间接依赖SDK。这时可以提供空的API实现,然后用SDK增强API实现原来的逻辑,将原来要依赖SDK才能实现的逻辑通过运行时字节码增强注入到API实现中。方便的解耦API与SDK依赖耦合问题;
Child-first类加载可能死锁问题:如果Jar包容器没有遵循双亲委派模型,而链路追踪的SDK又是由Jar包容器托管加载的,则可能因为字节码增强本身需要加载类并且类加载过程中的锁机制导致线程死锁,这时需要在
ClassFileTransformer中进行Classloader过滤;
四、系统间集成
4.1 与统一接入系统集成
统一接入系统是有赞外部流量的接入代理系统。
因为链路有采样率设置,有时在测试或排查线上问题时不方便。为了支持链路 100%采样,我们支持在前端页面请求的 HTTP Header 中设置类似 -XXDebug参数,统一接入系统判断在 HTTP 请求头中包含特定的 -XXDebug参数时,生成符合链路采样特征规则的 traceId 从而实现测试请求 100%采样。
4.2 与日志系统集成
为了使业务系统在上报日志给天网日志系统时自动记录 traceId,链路追踪 SDK 在开启追踪后会将 traceId put到 MDC中,天网日志 SDK 在记录日志时会获取 MDC 中的 traceId,并作为日志的描述数据一起上报,并进行索引。在日志查询时,支持按 traceId 查询。
同时天网日志系统对每次查询的结果数据页的日志 traceId 进行批量计算,判断哪些日志记录对应的请求在链路追踪系统中被采样,对采样过的日志记录的 traceId 替换成超链接,支持一键跳转到对应的链路详情页。
五、数据处理架构
链路数据处理使用 Spark Streaming 任务准实时计算,处理过的数据进行 ES 索引,并存储在 Hbase 中。数据上报过程使用常见的本地数据上报 agent + remote collector 的方式,然后汇到 kafka 队列供实时任务处理,架构视图如下所示:
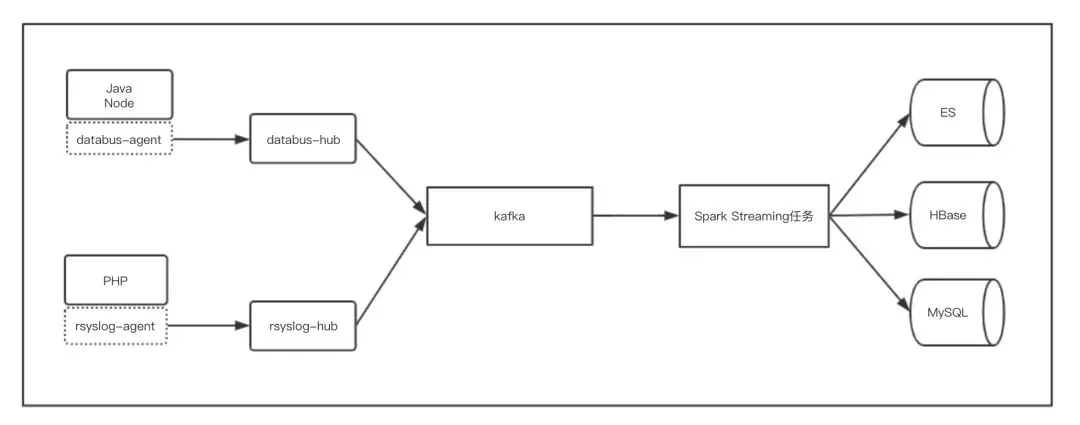
本地agent 之所以采用本地agent与远程collector方式,一方面考虑到大流量数据上报时的网络拥塞,使用本地agent,SDK可以将数据发送给agent由agent异步发送出去,减轻了SDK中数据上报队列溢出的风险;另一方面,如果数据直接从应用端连接到kafka队列,整体架构虽然变简单了,但是kafka所能承受的连接数比较有限,随着应用数的增长,整体架构会变得无法扩容。
链路优化 数据上报的链路经历了多次迭代优化,因为不同语言客户端上报数据的格式问题,旧版本的链路很长,多了几步数据格式转换与转发的过程。随着链路的优化迭代,每减少一个转发与转换的环节对于有赞的数据量都能节省许多资源。
数据处理优化 数据处理部分旧版本使用的是Java任务,改成Spark Streaming处理数据后整体计算资源的消耗也节省了原来的一半,包括CPU核数与内存总量。
六、总结与展望
全链路追踪系统包含几大部分:链路采集 SDK、数据处理服务、用户产品。SDK 部分比较偏技术。数据处理更考验数据处理的吞吐能力和存储的容量,采用更高级的链路采样解决方案可以有效降低这部分的成本。用户产品主要考验的是设计者对用户需求的把握,全链路追踪可以做很多事情,产品上可以堆叠出很多功能,怎样能让用户快速上手,简洁而又易用是链路追踪产品设计的一大挑战。未来一段时间,有赞全链路追踪会围绕以下几个方面继续演进:
赋能有赞云:给有赞云开发者用户提供有容器应用的链路追踪能力;
开源协议支持:数据模型与链路追踪API迁移到OpenTracing协议上,支持更多新语言的快速追踪;
用户产品迭代:持续提升产品体验,提供更切合用户使用场景的产品;
支持更多组件:支持更多组件和中间件的追踪能力;
离线分析能力:基于链路追踪的数据,挖掘离线分析能力,提供更丰富和强大的功能;
本文转载自公众号有赞 coder(ID:youzan_coder)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论 1 条评论