

2019 年 2 月,OpenAI发表了一篇论文,描述了基于 AI 的文本生成模型 GPT-2,该模型基于Transformer架构,针对互联网大量的文本上进行训练。从文本生成的角度来看,所包含的演示是令人印象深刻的:在很长的时间范围内,文本是连贯的,语法和标点符号近乎完美。
与此同时,其允许任何人下载模型(考虑到完整的模型可以被滥用于大规模地生成假新闻,这里给的是较小的版本)的 Python 代码和加载下载的模型并生成预测的TensorFlow代码已经在GitHub上开源了。
Neil Shepperd 创建了一个 OpenAI 仓库的派生,该存储库包含额外的代码,允许在自定义数据集上微调现有的 OpenAI 模型。不久之后创建了一个笔记本,该笔记本可以复制到Google Colaboratory,并把 Shepperd 的仓库克隆到微调的 GPT-2,该 GPT-2 由一个免费的 GPU 支持。从那时起,GPT-2 生成文本开始扩散:Gwern Branwen 等研究人员制作了GPT-2 Poetry,而 Janelle Shane 制作了GPT-2 Dungeons和Dragons人物简介。
我等着想看看是否有人会制作一个工具来帮助精简这个微调和文本生成工作流,像我已经为基于递归神经网络的文本生成所做的textgenrnn。几个月后,还没有人做。因此,我就自己动手做了。输入GPT-2-simple,这是一个 Python 包,用来将 Shepperd 的微调代码封装在函数式接口中,并为模型管理和生成控制添加了很多实用程序。
幸亏有了 GPT-2-simple 和这个Colaboratory Notebook,我们可以轻松地在我们自己的数据集上用简单的函数对 GPT-2 进行微调,并根据我们自己的规范生成文本。
GPT-2 的工作原理
到目前为止,OpenAI 已经发布了三种 GPT-2 模型:“小型的”1.24 亿参数模型(有 500MB 在磁盘上 ),“中型的”3.55 亿参数模型(有 1.5GB 在磁盘上 ),以及最近发布的 7.74 亿参数模型(有 3GB 在磁盘上 )。这些模型比我们在典型的 AI 教程中所看到的要大很多,并且更难使用:在用消费者 GPU 进行微调时,“小型”模型达到了 GPU 内存限制;在“中型”模型能够在服务器 GPU 上微调并且有足够内存之前,它要求额外的训练技术;“大型”模型在使用 OOM 之前,即使采用了这些技术,也完全无法用目前的服务器 GPU 进行微调 。
实际的 Transformer 架构 GPT-2 的使用是非常复杂的,难以解释(这是一个很棒的讲座)。出于微调的目的,由于我们无法改动架构,把 GPT-2 看作一个有输入和输出的黑匣子就更容易些。像以前的文本生成器形式,输入是一个标记序列,而输出是该序列中下一个标记的概率,把这些概率作为权重,供 AI 在该序列中选取下一个标记。在这种情况下,输入和输出标记都是字节对编码的,而不是使用字符标记(训练的速度更慢,但是包含大小写/格式化)或单词标记(训练的速度更快,但是不包含大小写/格式化),像大多数 RNN 方法那样,输入被“压缩”到最短的字节组合,包含大小写/格式化,可以作为两个方法之间的妥协,但是,不幸的是,给最终的生成长度添加了随机性。字节对编码稍后被解码成用于人类生成的可读文本。
预先训练过的 GPT-2 在链接自Reddit的网站上训练。因此,该模型对英语掌握地很好,可以将这类知识转移到其他数据集,并且,只需要进行很少的额外微调就能很好地运行。由于编码结构中的英语偏见,像俄语和CJK等非拉丁字母语言在微调中表现不佳。
在微调 GPT-2 时,由于其是速度、大小和创造力上的最佳平衡,我建议使用 1.24 亿参数模型(默认值)。如果我们有大量的训练数据(超过 10MB),那么,3.55 亿参数模型可能工作地更好。
GPT-2-simple 和 Colaboratory
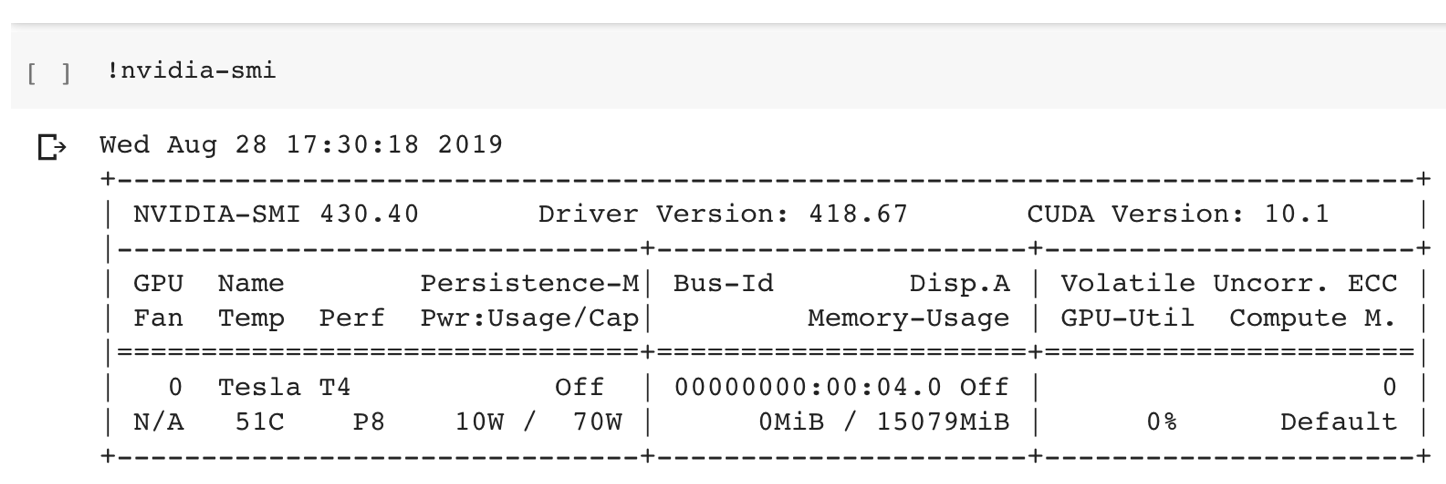
为了更好地利用 GPT-2-simple 并展示其功能,我创建了我自己的Colaboratory Notebook,大家可以把它复制到自己的谷歌账号中。Colaboratory Notebook 实际上是Jupyter Notebook,运行于免费(用谷歌账号)的虚拟机上,该虚拟机具有 Nvidia 服务器 GPU(随机为 K80 或 T4,T4 更理想) ,通常成本高昂。
打开后,该笔记本的第一个单元格(通过在该单元格中同时按下 Shift 和 Enter 键运行或者把鼠标悬停在该单元格上并按下“Play”按钮)安装 GPT-2-simple 及其依赖项,并加载该包。

在该笔记本中,随后是 GPT2.download_GPT2(),其下载所请求的模型类型到 Colaboratory 虚拟机(该模型托管在谷歌的服务器上,因此,下载速度很快)。
展开该 Colaboratory 侧边栏,我们可以看到一个用来上传文件的 UI。比如,tinyshakerspeare数据集(1MB)提供原始的char-rnn实现。通过该 UI(我们可以拖放)上传一个文本文件,运行该 file_name = ''单元格,在该单元格中修改我们的文件名。
现在,我们可以开始微调了!这个微调单元格加载指定的数据集,并训练指定数量的步骤(默认的 1000 个步骤足以允许出现不同的文本,大约需要 45 分钟时间,但是,如果有必要,我们可以增加训练的步骤数)。
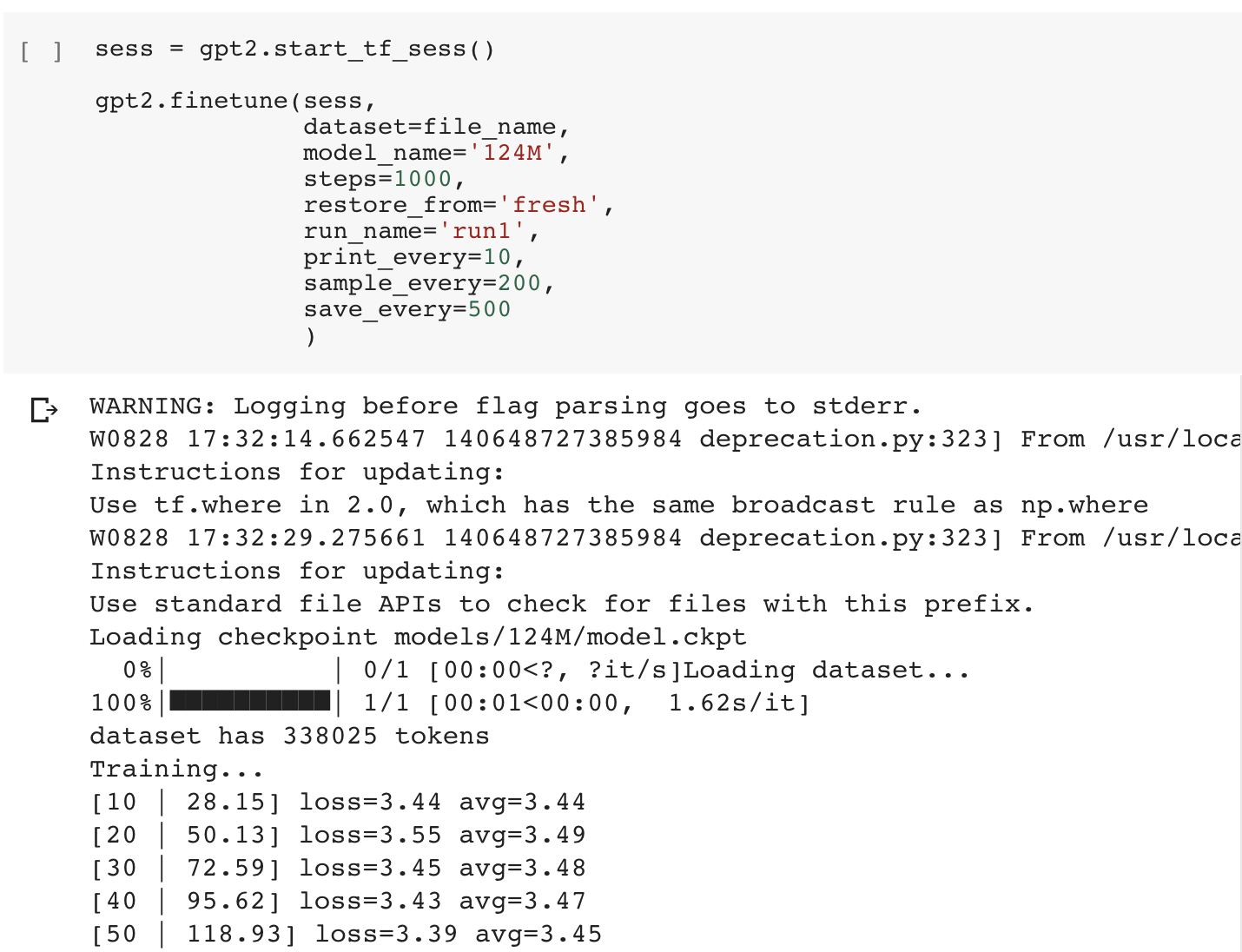
在模型微调时,平均训练损失每隔一段时间就输出到该单元格。该损失的绝对值并不重要(输出文本的质量是主观的),但是,如果平均损失停止减少,那表明该模型已经收敛,并且,额外的训练可能无助于该模型的改进。
默认情况下,我们的模型保存于 checkpoint/run1 文件夹,并且,我们还需要使用该文件夹来加载该模型(在使用其他函数对微调的模型进行分类时,我们可以指定 run_name)。如果我们希望从 Colaboratory 导出该模型,建议大家通过Google Drive来做(因为 Colaboratory 不能导出大型文件)。运行 GPT2.mount_gdrive()单元格,在 Colaboratory 虚拟机上中安装我们的 Google Drive,然后运行 GPT2.copy_checkpoint_to_gdrive()单元格。接着,我们可以从 Google Drive 下载压缩的模型文件夹,并随时随地地运行该模型。类似的,我们可以使用 GPT2.copy_checkpoint_from_gdrive()单元格来检索被存储的模型,并在该笔记本中生成。
谈到生成,一旦我们已经微调了模型,就可以马上从它生成自定义文本了!默认情况下,GPT2.generate()函数将生成尽可能多的文本(1024 个标识),带有一点点随机性。一个重要的警告:我们不能在所有的时间里都获得好的生成文本,即使用恰当训练的模型也是如此(上面 OpenAI 的演示尝试了 25 次才获得好的文本)。

我们还可以提高 temperature,通过允许网络更加可能地做出次优的预测来增加“创造性”,提供 prefix 来指定我们到底希望自己的文本如何开头。有很多其他有用的配置参数,如用于原子采样的 top_p。

作为一种红利,我们可以使用 GPT-2-simple,通过设置 nsamples(总共要生成的文本数量)和 batch_size(一次生成的文本数量)来批量生成文本;Colaboratory GPU 可以支持的 batch_size 最大为 20 个,并且,我们可以用和 GPT2.generate()有同样参数的 GPT2.generate_to_file(file_name)来生成这些到一个文本文件中。我们可以通过侧边栏,在本地下载所生成的文件,并使用这些文件,以便轻松地保存和分享所生成的文本。
该笔记本还有很多其他功能,具有更多的参数和细节解释!如果我们想在该笔记本外部使用该模型,可以使用该GPT-2-simple README列出的 GPT-2-simple 的其他功能。
(注意:目前,我们需要通过运行时(Runtime)来重置 Notebook → 重启运行时来微调不同的模型/数据集或加载不同的微调过的模型。 )
用于短文本的 GPT-2
GPT-2 和其他开箱即用的 AI 文本生成器的一个缺点是,它们是为长格式内容构建的,并且不断地生成文本直到达到指定的长度为止。我想做 GPT-2-simple 的另一个原因是,给生成的文本添加明确的处理技巧,以解决短文本的这个问题。在这种情况下,可以给 GPT2.generate()传递两个额外的参数:truncate 和 include_prefix。比如,如果每个短文本都是以一个<|startoftext|>标记开始和以<|endoftext|>标记结束的话,那么,设置 prefix=’<|startoftext|>’、 truncate=<|endoftext|>'和 include_prefix=False,并设置足够的长度,那么,即便在批量生成的时候,GPT-2-simple 都将自动提取短格式文本。
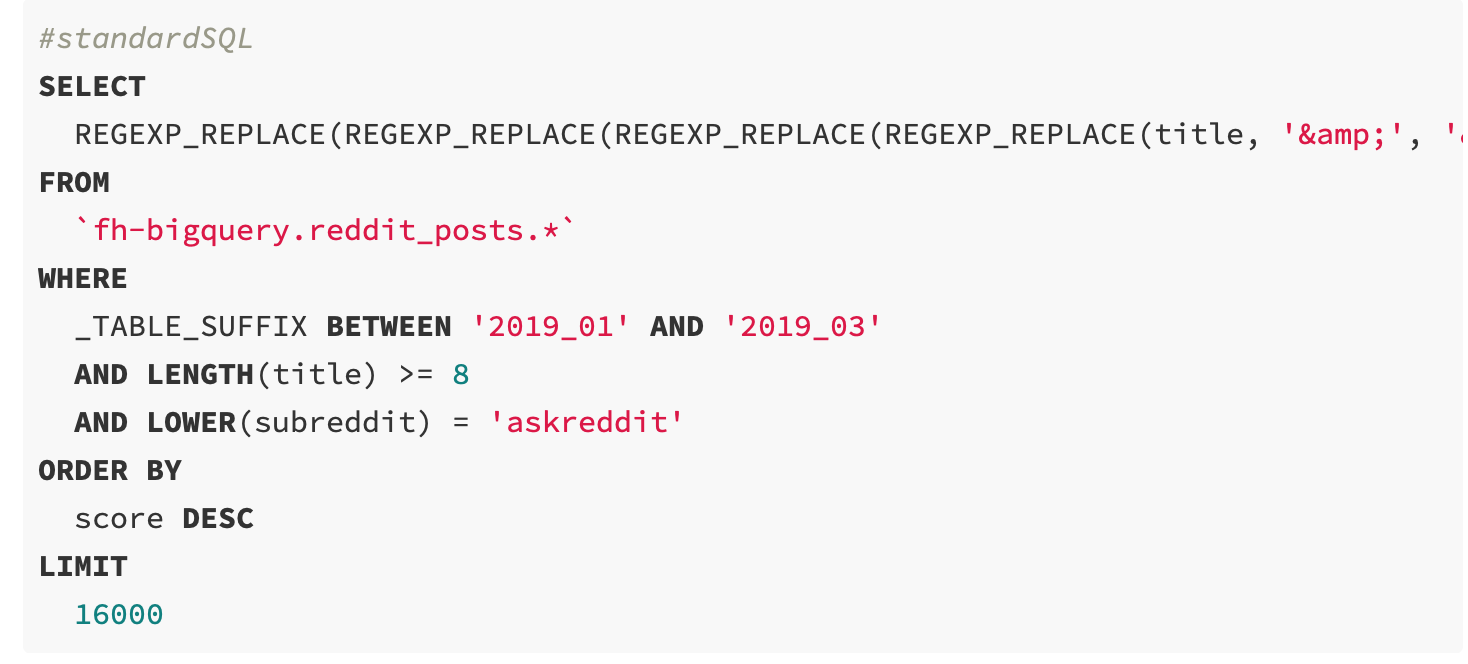
让我们在 Reddit 提交标题上微调 GPT-2 模型。在BigQuery(免费的)上运行时,对于给定的 Reddit 子 reddit(在这种情况下,/r/AskReddit)+ 次要文本预处理,该查询返回在 2019 年 1 月到 3 月期间得分最高的 16000 个标题,这些可以在本地下载为一个 1.3MB CSV 文件(Save Results → CSV [local file]):
借助 GPT-2-simple,使用像前面生成的单列 CSV 作为输入数据集,将自动恰当地添加<|startoftext|> 和 <|endoftext|>标记。正常地微调新的 GPT-2 模型,然后,用前面提到的附件参数生成:
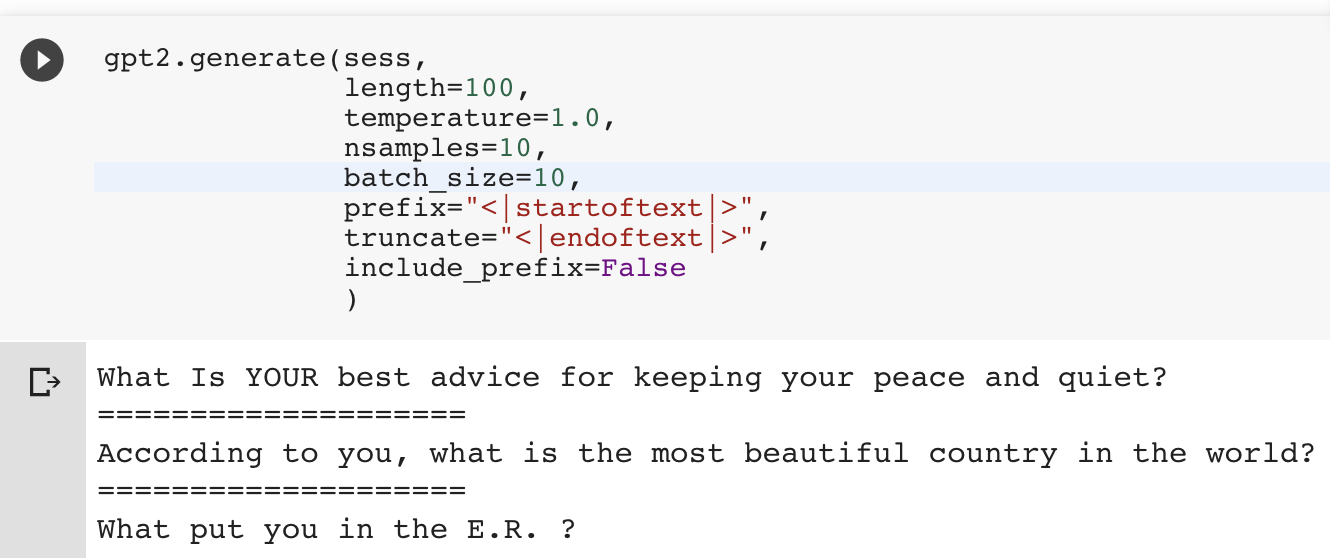
值得注意的是,尽管向模型输入了大量的数据,微调后的网络很容易在短格式文本上过拟合:这些样本标题中的其中一些与现有的/r/AskReddit标题很接近。可以通过减少训练时间或添加更多的输入数据来纠正过拟合。确保仔细检查一下我们所生成的文本是否唯一。
在这个修改过的Colaboratory Notebook上,我们可以试试这个面向 Reddit 的变体。
制作 GPT-2 应用程序
GPT-2 已经有非常棒、非邪恶的用例了,如 Adam King 的TalkToTransformer,它为 7.74 亿参数模型提供 UI(并且已经进行了很多次病毒式传播),还有TabNine,它使用 GPT-2 在 GitHub 代码上微调,以创建概率代码补全。在PyTorch这边,Huggingface 已经发布了他们自己的Transformers客户端(支持 GPT-2),还创建了应用程序,如Write With Transformer,用作文本自动补全器。
很多 AI 教程常常展示如何利用Flask应用程序框架,把一个小型模型部署到 web 服务。GPT-2 的问题是,它是一个巨大的模型,要得到一个高性能的应用程序,大多数传统的建议是没有用的。即使我们让它运行得很快(如通过在 GPU 上运行该应用程序),它也不会便宜,特别是如果我们希望它能适应随机的病毒式传播。
借助 GPT-2-simple,我提出的解决方案是GPT-2-cloud-run,这是一个小型的 web 应用程序,旨在通过 GPT-2-simple 支持的Google Cloud Run来运行 GPT-2。这样做的好处是,Google Cloud Run 只对用到的计算计费,可以随流量的增长而无限扩展;对于日常使用,与运行一个不间断的 GPU 相比,它具有极高的成本效益的。我已经使用 Google Cloud Run 为Reddit范围的提交标题制作了一个 GPT-2 文本生成器,并为 Magic 制作了一个 GPT-2 生成器:The Gathering cards!

归因于 AI 生成的文本
我开发 textgenrnn 和 GPT-2-simple 的主要原因之一是,让 AI 文本生成更容易访问,不需要有很强的 AI 或技术背景来创作有趣的故事。但是,在 GPT-2 的情况下,我已经注意到,不断增加的“我训练了一个 AI 来生成文本”文章/Reddit 贴文/YouTube 视频提到他们使用了 GPT-2 来训练一个 AI,但是,没有提到他们是如何训练这个 AI 的:因为微调不是 OpenAI 提供的一个开箱即用的功能,所以特别可疑。
尽管这不是法律上的要求,但是,我要求,任何分享通过 GPT-2-simple 生成的文本的人添上一个指向该仓库和/或 Colaboratory Notebook 的链接,不只是为了贡献,而是为了传播关于 AI 文本生成可访问性的知识。它是一种技术,应该是透明的,不是为了个人利益而混淆视听。
GPT-2 的未来
我希望,本文在如何有创意地微调和生成文本方面给大家提供一些想法。还有很多未开发的潜力,还没有触及很多很酷的应用程序,还有很多很酷的数据集没有用于 AI 文本生成。GPT-2 很可能会更多地用于大规模生产疯狂的色情内容,而不是假新闻。
然而,GPT-2 和 Transformer 架构并不是 AI 文本生成的最终目标。从长远来看不是。
原文链接:
https://minimaxir.com/2019/09/howto-gpt2/
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论