

在 12 月 7-8 日于北京举办的 ArchSummit 全球架构师峰会上,在领英机器学习组从事机器学习算法、特征量和平台的研发的张镭分享了大规模机器学习在领英预测模型中的应用,以及领英在预测模型创建上的成功实践和踩坑经验,以下为演讲的主要内容整理。
预测模型在 LinkedIn 的产品中被广泛应用,如 Feed、广告、工作推荐、邮件营销、用户搜索等。这些模型在提升用户体验时起到了重要的作用。为了满足建模需求,LinkedIn 开发并且开源了 Photon-ML 大规模机器学习库。Photon-ML 基于 Apache Spark,能快速处理海量数据并具有强大的模型训练和诊断功能。
本文将从以下三个方面进行介绍:
LinkedIn 产品使用预测模型的情况
*分享预测模型系统在实践中的成功经验和踩坑教训
*案例研究
LinkedIn 产品使用预测模型的情况
LinkedIn 的很多产品是人工智能(AI)驱动的,如 Feed、广告、工作推荐、邮件营销、用户搜索等。预测模型对 LinkedIn 用户体验产生了巨大的影响。比如,LinkedIn 的 Feed 产品,当用户登录 LinkedIn 主页后,系统会根据用户画像提供个性化信息流,包括热点文章、图像、视频、朋友和同事分享的近况,以及所关注公司新闻等。LinkedIn 还会向用户推荐工作机会,其核心产品被称为 Job You Maybe Interested In(简称 JYMBII)。用户通过 LinkedIn“工作”页面可以看到这款产品。它会根据用户的工作经验、工作本身的需求和描述等信息为用户推荐相关工作。此外,在 LinkedIn 的 Email 营销产品中,针对 LinkedIn 的免费注册用户,其可以通过模型来预测其中哪些用户可能会转化为付费用户。通过给潜在的付费用户发送 Email,吸引他们转化成为付费用户。此外,还有 LinkedIn 还有其他很多产品使用了人工智能和机器学习技术,产品背后都是预测模型在支持。

下面介绍简单介绍一下 LinkedIn 的端到端预测模型系统,如下图所示。
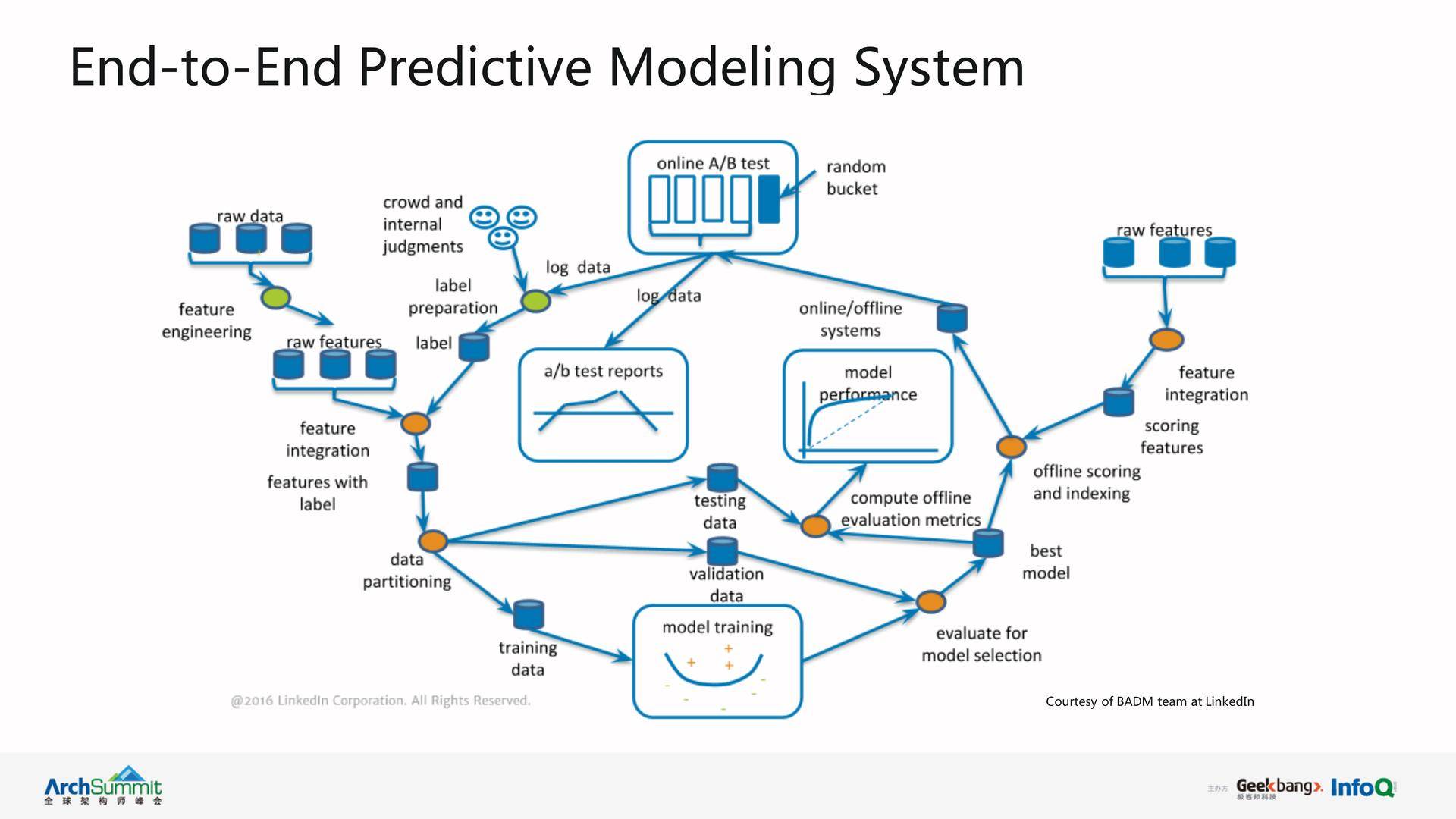
该系统基本上可以分成两大模块:offline learning(离线学习)模块和 online deployment(在线部署)模块。
在离线学习模块,我们的主要目的是训练预测模型。首先我们需要收集一些标签数据(label data),其标签是由具体用例决定的。例如,在 Email 会员营销模型里,我们可以把用户打开邮件这个行为定义为正标签 (positive label),把没有打开邮件动作定义为负标签(negative label)。得到正负标签以后,我们会收集建立模型所需要的一些特征(feature),如用户的在网站上的行为等,形成特征集合(feature set),然后与标签数据集成为训练实例(training examples)。其可进一步划分为训练数据集(training set)、检验数据集(validation set)、测试数据集(testing set),我们使用训练数据集来训练模型,利用检验数据集选择模型参数并选出最佳模型,再把最佳模型运用到测试数据集上进行测试,得到预测模型的基本性能情况,如准确度等。但离线训练的模型只有在在线部署阶段,经过在线 A/B testing 才能衡量出实际的生产效果。一般情况下,我们会先测试少量用户(如 5%的用户),如果用户反馈好,再逐步扩大到 10%、15%到 20%等,直到最后完全替代旧模型。
预测模型系统成功经验和踩坑经验
在建立预测模型系统过程中,有哪些成功经验和踩坑教训可以分享呢?
首先,预测模型需要注意的是目标(objective)。当训练一个预测模型时,第一步需要明确目标来对模型进行优化。目标随着产品的要求不同而不同,有的产品想追求点击率,有的想追求转换率,有的想追求日活用户等。比如, 对 JYMBII 模型来说,找工作的人会希望显示的工作信息越多越好,但是对那些投放工作信息的公司或个人来说,他们会希望把工作只投放给少数有资格的求职者,因此,两方的目标是不完全一致的。针对这种情况,在设计模型时,我们必须综合考虑如何确定一个合适的目标。JYMBII 把用户是否申请工作作为评价模型好坏的指标,把提高用户工作申请率作为目标,这样就综合了两方面的因素。另外,在有些推荐系统中,有时只使用模型可能是不能满足产品要求的,我们会在模型上面增加一层逻辑层叫做产品的规则层(rule layer):其根据产品需求来制定规则对推荐结果进行干预和优化。
第二个是标签数据的质量。 需要避免一些坑,比如第一个坑就是信息泄露(information leak)。一般情况下是把训练数据集和测试数据集混合在一起了,这就造成了模型离线训练效果很好,当在线部署阶段却发现效果不佳。
第二个坑是训练数据不平衡(training data imbalance), 比如,针对检测欺诈模型,负标签很多,但是正标签(欺诈用例)却相对很少,这个比例可能是 1:100,1:1000 或者 1:10000,非常不平衡。在这种情况下可以采用 down-sampling(下采样),up-sampling(上采样)或 SMOTE 方法,可以部分抵消训练数据不平衡的问题。
第三个坑就是数据丢失(missing data)的问题, 在训练数据里有些丢失的数据没有值,这可能是在数据追踪的时候丢失了,或者是硬件故障导致的数据丢失等。此时,我们一般会用插值技巧(imputation)解决,比如采用最频繁的值,中间值,或者取 0 来代替数据丢失值。
最后一个坑就是离群值(outlier)的问题, 这个值大大超出正常值的范围,比如正常值在 1~100,而离群值可能在 1000~10000,这会导致线性模型的表现非常糟糕。这种情况要做转换(transformation)来处理,比如采用 Log 或者 Binning 的方法。

接下来,预测模型的特征工程(feature engineering)也是非常重要的一步,有几个好的实践经验可以参考:首先需要尝试新特征,而且你需要不断的迭代尝试(iterate and try),很多特征如果不去尝试的话,会失去发现可用性的机会。此外,我们在训练数据集大的情况下,可以尝试使用一些具体特征。这些具体特征集中,单个特征可能只能针对小部分用户但整个特征集的覆盖(coverage)高。例如,在做 Email 会员营销模型时,我们会选取用户浏览的网页(page view)等作为具体特征放进模型里面去做训练。有时这种具体特征非常有用。
第四点就是根据数据的原始特征生成一些新的特征, 让预测模型得到更多的信号量。一般规则如下,比如对数字特征(numeric feature),我们可以采取二值化(binarization),即它有值与否可以作为一个新的特征。或者做区间化处理(binning)。例如,用户年龄大小在 18 岁到 100 岁之间,我们可以把它分成年轻人、中年人和老年人等区间,这样有些预测模型可能会发现:青年人的收入是随着年龄增长的,而老年人正好相反等规则。当然我们还可以使用 log/box-cox 等方法对特征进行处理。而对分类特征(categorical feature),比如用户的职称(如软件工程师、硬件工程师等),可以采取独热编码(one-hot encoding)的方式,或者做一些分组(grouping),如把软件工程师和硬件工程师都归结为工程师,这样的分组可以减少分类特征的数量。LinkedIn 用户的头衔超过数万种,如果全部放在模型里去训练,特征向量维度太大,效果有时并不是很好,采用分组操作可以减少维度。
还有就是特征交叉(feature cross), 即将两个或者多个原始特征组合成为一个新的特征。以 JYMBII 模型来说,用户的技能有 Java、Python 等,而工作需要用户具有特定的技能,所以做一个用户技能和工作要求技能的匹配,我们会得到一个新的交叉特征。这种类型的特征比较实用,因为它可以在线性模型中引入一些非线性信号,这对模型训练是非常有效的。

对于 A/B Testing,我们需要注意什么问题呢?首先,做 A/B Testing 的时候不能把模型所有的变化都放在一个测试里,如果只改变了一个模型的一个参数,只需要调整模型的该参数去测试,而不是引入很多改变因素。
另外,A/B Testing 应该是考虑模型的长期影响。比如一个新的模型可能在短期内增加用户的点击率、搜索频率等,但从长远看,它可能会影响用户保留率和用户使用体验。
第三点就是必须精心设计实验用户量来获得具有统计意义的实验结果,才能确定模型的变化是否有效。

针对建立预测模型的需要,LinkedIn 开发并且开源了一套大规模机器学习库 Photon-ML,它基于 Apache Spark,可以处理大规模数据,有很好的训练模型和检测模型的能力。
模型网址: https://github.com/linkedin/photon-ml/。
Photon-ML 的主要功能如下:
支持大规模回归算法、线性回归、逻辑回归等。
支持系数的偏移量、权重和边界。
*支持广义线性混合效应模型(GLMix),这是 GAME(Generalized Additive Mixed Effects)模型的一种实现。
其中,GLMix 模型是由一个固定效应(fixed effect)和多重随机效应(random effects)组成。固定效应和多重随机效应是统计上的概念,一个 GLMix 模型实例的定义和优化问题如下:

案例研究
Feed 排序模型
对于 LinkedIn 的 Feed 产品,当用户登录主页后,系统显示多种信息,如联系人更新、热门文章、广告等。那么如何把这些信息排序发送给用户呢?我们需要建立 Feed 排序模型。 首先,根据用户能点击或互动的更新信息得到标签数据,再寻找模型的特征。我们可以根据用户的行为和发布内容等对特征进行分类,比如用户的联系行为、互动等。这些特征可以进行分类如下:
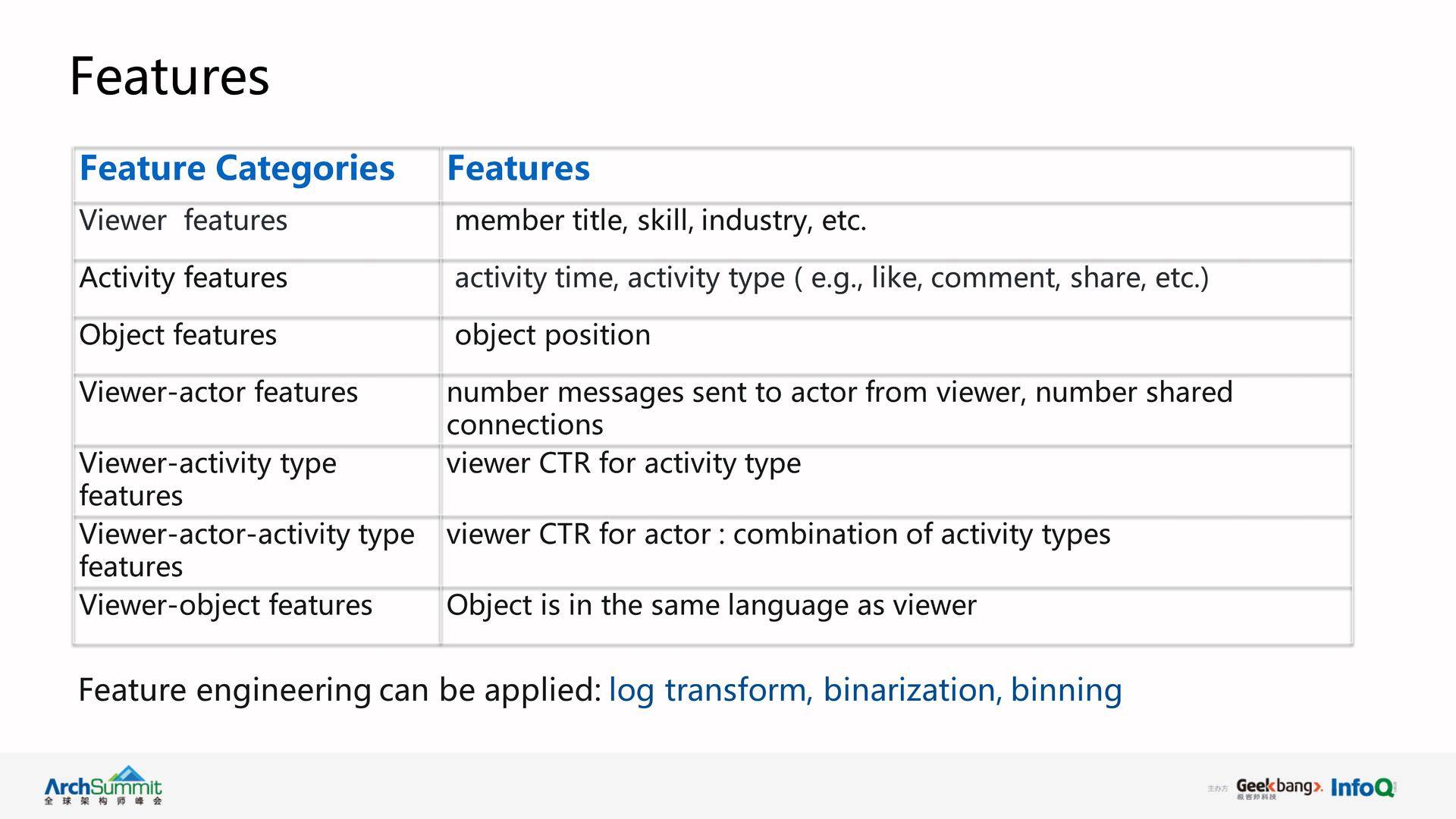
有了特征以后就开始建模了,我们将 Feed 排序问题其当成一个二元分类问题(binary classification problem)。标签数据收集如下,如果用户跟 Feed 内容有了互动如点击,这是 positive label,是 1;如果用户跟 Feed 内容没有互动,则是 negative label, 设为 0 或 -1,这样就有了标签数据。然后选择模型进行训练,模型的基本计算公式如下:

模型训练如下:

GLMix 模型
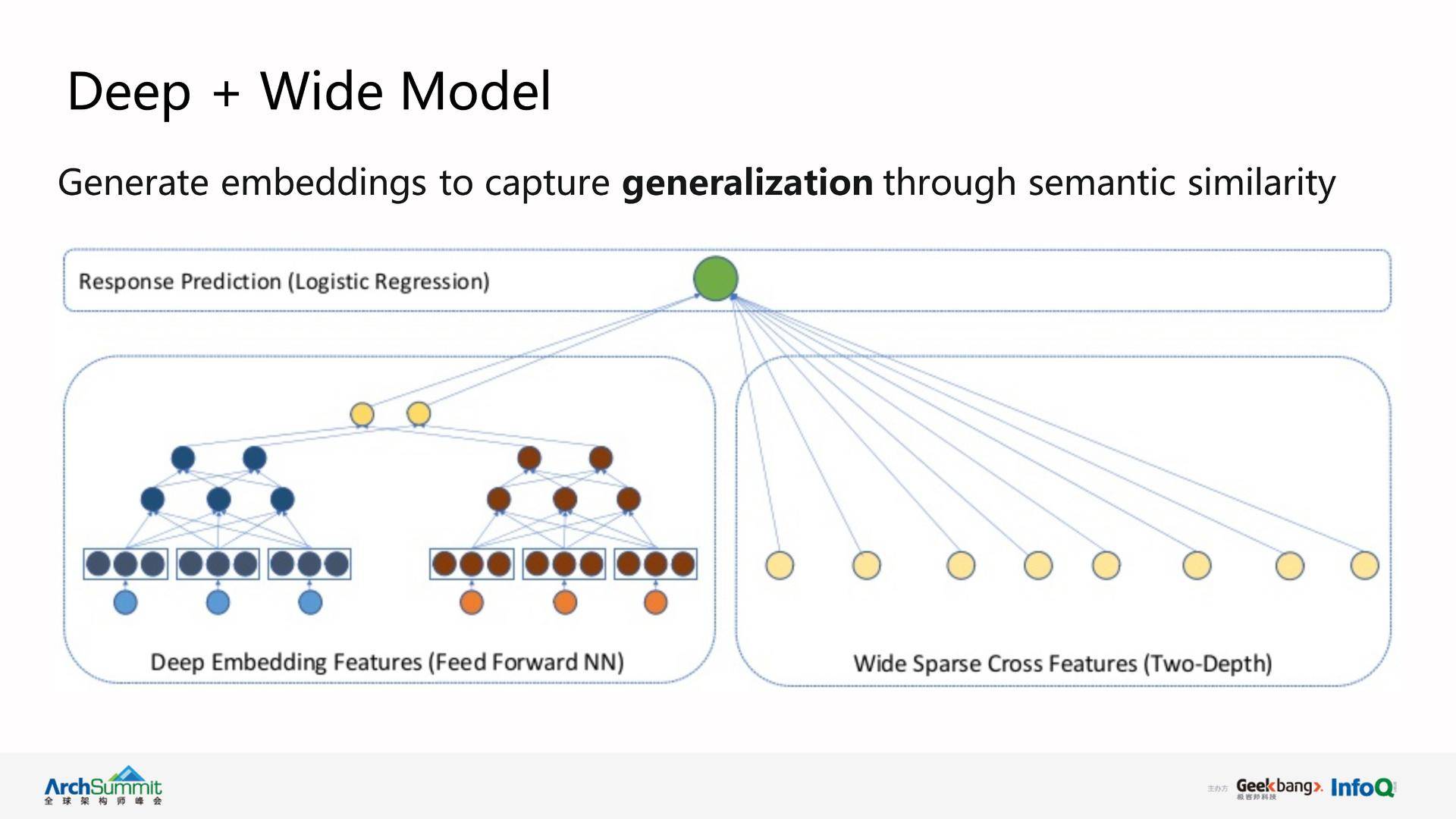
JYMBII 使用 Photon-ML 的 GLMix 算法建模而达到深度个性化工作推荐。JYMBII 模型分为三个主要部分:一是 fixed effect,其针对 LinkedIn 的所有用户,被称为 population average model;另外两个部分是 random effects, 每个 random effect 被称为 entity specific model。针对 LinkedIn 上每个用户,我们为其独立创建模型,叫做 per-member 模型;针对 LinkedIn 上每份工作,我们为其单独建模型,叫做 per-job 模型。GLMix 模型通过 fixed effect 和 random effect 的“相加”处理就实现了非常个性化的推荐。此外,JYMBII 模型也使用了 embedding 特征。例如,用户职称和工作职位需求的文本相似度是一个很重要的特征。JYMBII 开始使用词袋(bag of word) 模型对两者进行相似度计算,但是英文的很多情况下,两个词组的意义类似,但是使用单词完全不同,例如,“application developer” 和 “software engineer”。这时我们可以采用 embedding 来处理。我们会得到用户和工作各自的 embedding 向量,在其向量上进行再进行相似度计算和处理。通过 embedding,我们可以进一步建立了 Deep & Wide 的模型,从而整合了 GLMix 和深度学习技巧。
Photon Gateway

Photon Gateway 基于 Photon-ML 的离线机器学习平台,主要能方便生成 propensity model。 它的目标是实现预测模型的快速原型、快速迭代、快速部署。其主要特点是自带特征库和自动特征工程,进行自动模型高参数(hyperparater)调整,完成模型和特征分析报告,并进行模型的离线部署等。
嘉宾介绍

张镭: 目前在领英公司(LinkedIn)机器学习基础组从事机器学习算法、特征量和平台的研发。伊利诺伊大学芝加哥分校计算机科学博士,主要研究领域是自然语言处理、情感分析、数据挖掘和机器学习。在国内外学术期刊和会议上已发表 20 多篇学术文章,获得多项美国专利,合著有 Mining Text Data 等四本关于文本数据挖掘和大数据计算书籍, 并长期受邀担任国际期刊评委和国际会议程序委员会委员。

更多内容,请关注 AI 前线

公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论