

导读:在天猫、淘宝网购过程中,商品的推荐与广告的前端展示是怎样的?两者的底层数据服务又是怎样构建的?今天跟大家讲述面向阿里 1688 业务的实时数据工程实践。
本次分享主要分为三部分:首先讲解实时数据工程实践的意义;然后介绍中台体系,因为中台的基础非常完善,所以面向业务时,工程实践特别高效、低成本;最后通过实际案例让大家深刻了解实时数据工程。
01 实时数据工程
1688 是一个电商网站,每天会有千万级的访问流量,百万级的订单流量,每天能有数十亿成交额。
一个网站想要发展,最关注的肯定就是买家数,营收等一些指标;如果涉及到目标,就离不开匹配效率、市场机制、商业化 ( 如广告投放等 )。
支撑这些目标的通常是算法:
❶ 针对匹配效率,有实时个性化搜索,推荐算法的开发;
❷ 针对市场机制,有业务需求方的实时调控策略;
❸ 针对商业化,有搜索推荐即广告物料的实时上下架调整。
算法模型的底层就是实时特征工程,分为两部分:
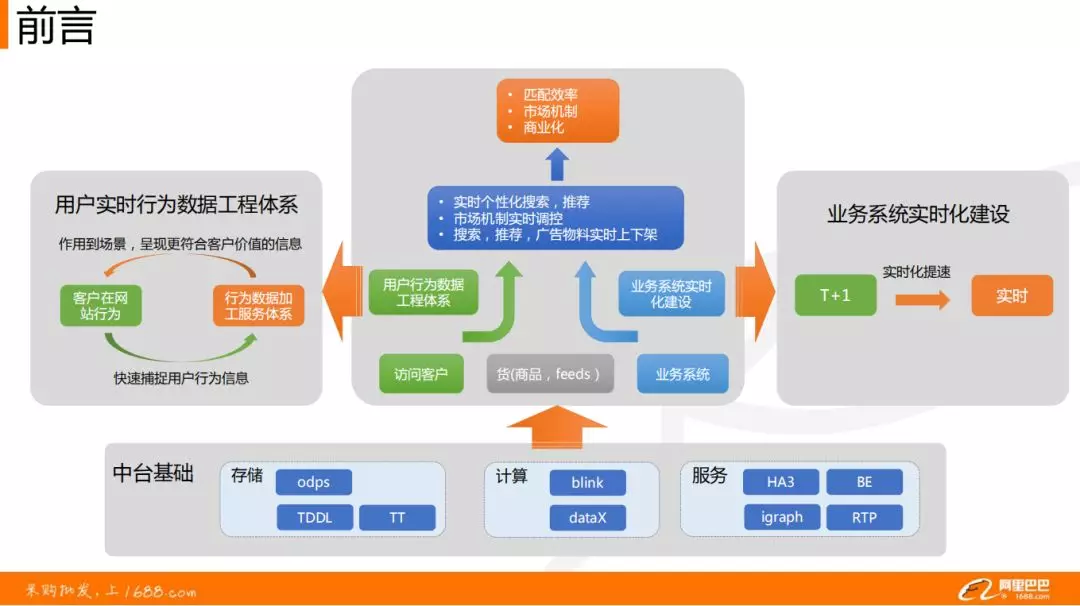
❶ 用户行为数据工程体系。主要作用在场景中,通过捕捉用户的行为信息,构建用户的数据特征体系,呈现更符合客户价值的信息。
❷ 构建业务与货物的实时系统。由原先在搜索推荐中离线计算,进行实时化提速,由原来的 T+1 天改进到现在 1h、1min 甚至秒级的数据计算响应。
实时数据工程所实现的用户行为数据工程体系、业务实时化建设依赖于阿里巴巴非常完善的中台基础体系。
02 中台基础
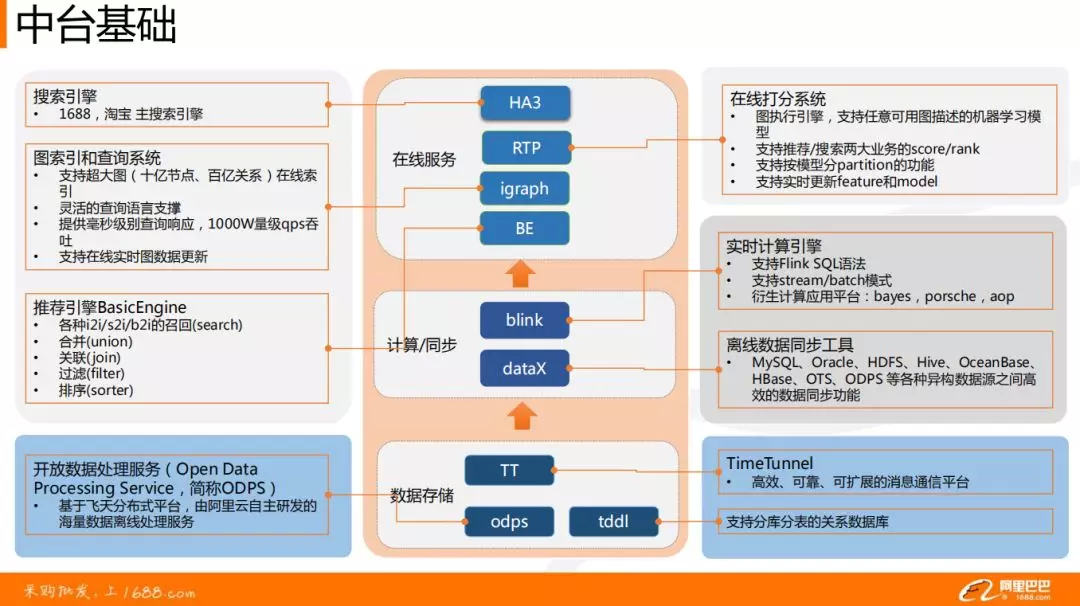
简单介绍下中台基础,主要分为:在线服务体系、实时计算引擎与离线数据同步工具、数据存储。
在线服务体系:
❶ 搜索引擎 HA3,是阿里巴巴搜索团队开发的搜索引擎平台,它为阿里集团包括 1688、淘宝、天猫在内的核心业务以及各垂类业务提供搜索服务支持。
❷ 推荐引擎 BE(BasicEngine ),包含搜索 Query 的各种召回 ( 如 item2item,behavior2item ) 及一些简单的数据处理逻辑如合并、关联、过滤、排序等。
❸ 在线打分系统 RTP,在搜索与推荐之上,支持业务中深度模型的在线打分服务。
❹ igraph 图索引及查询系统,存储用户的行为信息。在实践中,还会用来存储如 kv、kkv 结构的服务化数据。
实时计算引擎与离线数据同步工具:
❶ 阿里内部使用较多的 Blink。大家可以认为是 Flink 的升级版,功能更加完善,也更加强大,甚至已经成为了阿里巴巴实时计算的主流引擎,下面将要讲的案例大都是以 Blink 为基础实现的。
❷ 异构数据源之间的同步工具 DataX。即通过底层的 ODPS ( Open Data Processing Service ) 服务将不同数据源的数据进行同步。
数据存储:
❶ OPDS 开放数据处理服务,基于阿里飞天分布式平台,支撑 GB/TB/PB 级的数据计算服务。
❷ Tddl 是分表分库的一个中间件,可以认为是类似于 MySQL 的一种工具,在其上进行封装后,分表分库可以横向纵向的无限扩展。
03 工程实践
下面将面向业务类型,进行案例讲解,一是系统业务数据实时化的案例;二是根据用户行为的实时数据服务。
系统业务数据实时化
任务:因为搜索推荐以及促销活动商品池更新汰换,将导致商品的各种信息发生变化。从原始数据源中的数据实时同步更新到服务引擎中,就显得非常有必要。
案例 1:商品统计数据实时化
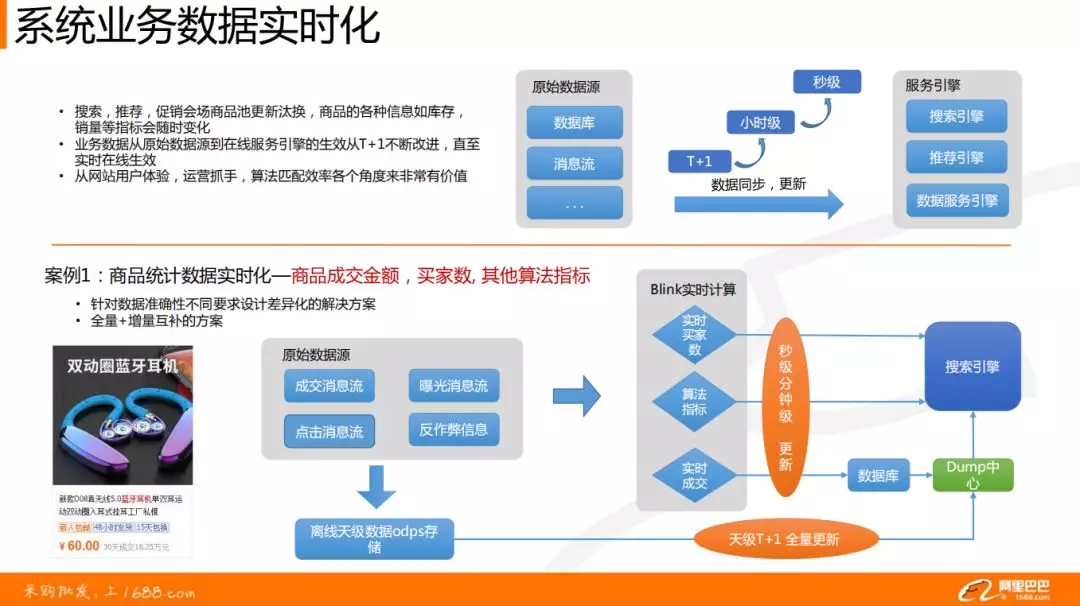
要求:商品的成交金额、买家数、其他算法指标在线上发生变化时候,就能在线上的搜索引擎中实时显示出来。
❶ 针对数据准确性不同要求,设计了差异化的解决方案:
卖家或者买家在前端页面展示出来的数据是非常精准的,这个用中间的数据库做转存,然后再进入搜索引擎。
在线打分、商品排序阶段,一些算法的因子可能存在时效性的误差,我们是实时计算算好直接进入搜索引擎,更加高效,更加轻量,延迟更低,并发度可以更多。
❷ 全量+增量互补的方案
上面是实时的解决方案,对于 T+1 级别的数据,要把 T-n->T 天的数据做一个全量的计算,再进到搜索引擎中,因为每天的搜索引擎是做一个全量更新的。
案例 2:推荐商品的实时更新汰换
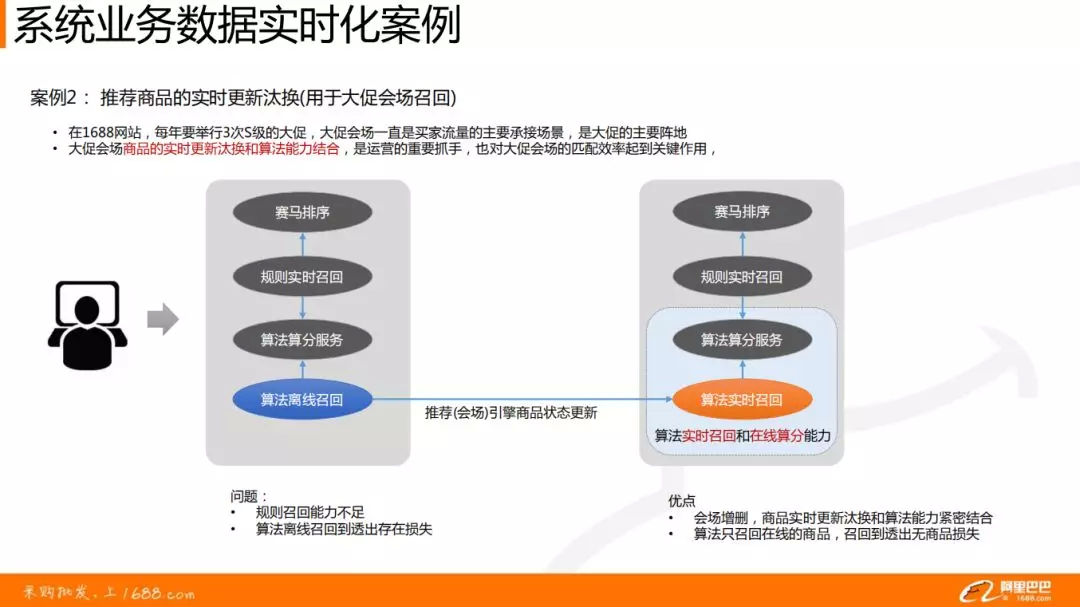
背景:在 1688 网站,每年要举行 3 次 S 级的大促,类似于天猫淘宝的双 11 大促,大促会场一直是买家流量的主要承接场景,是大促的主要阵地。
原来的时候,算法是通过离线进行召回的,存在召回能力不足,效果不好的问题。
改进为算法实时召回,并且运营可以配置召回及打分方式,实现大促会场商品的实时更新汰换和算法能力结合,是运营的重要抓手,也对大促会场的匹配效率起到关键作用。
案例 3:广告引擎和推荐引擎之间的数据实时同步
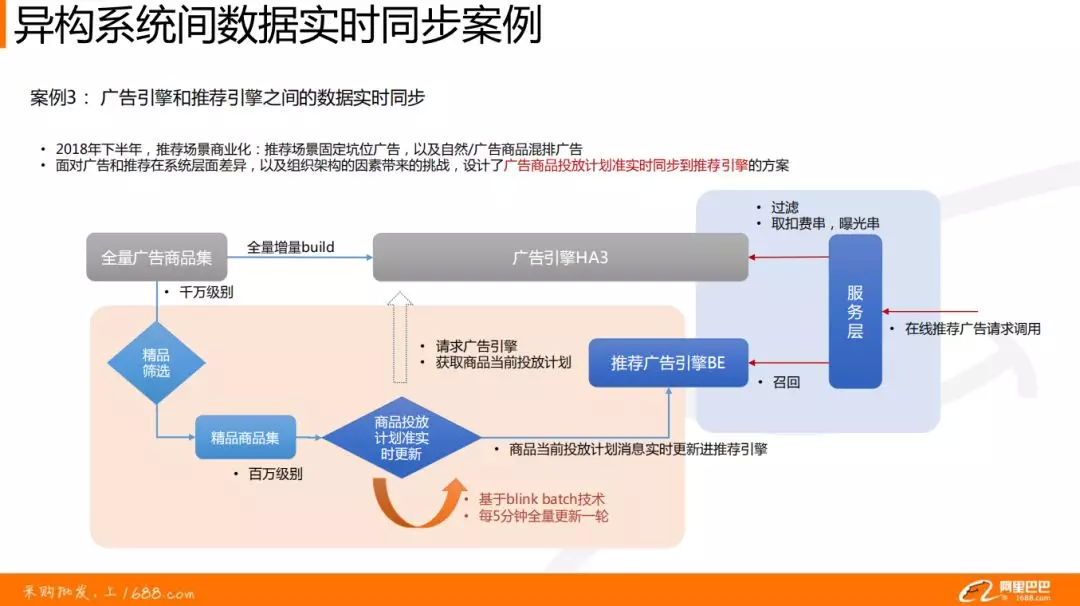
背景:2018 年下半年,推荐商业化:当时广告引擎和推荐引擎是异构的,召回的方式完全不一样,广告走的是搜索的逻辑,根据 Query 词;而推荐根据用户行为、或者冷启动进行召回。
现在将广告的数据同步到推荐引擎中,将千万级别的全量广告商品集进行精品筛选,得到百万级别的精品商品集。使用 Blink batch 将这些数据每 5 分钟全量更新一次,并按照商品投放计划消息把数据更新给推荐广告引擎。
实时数据服务
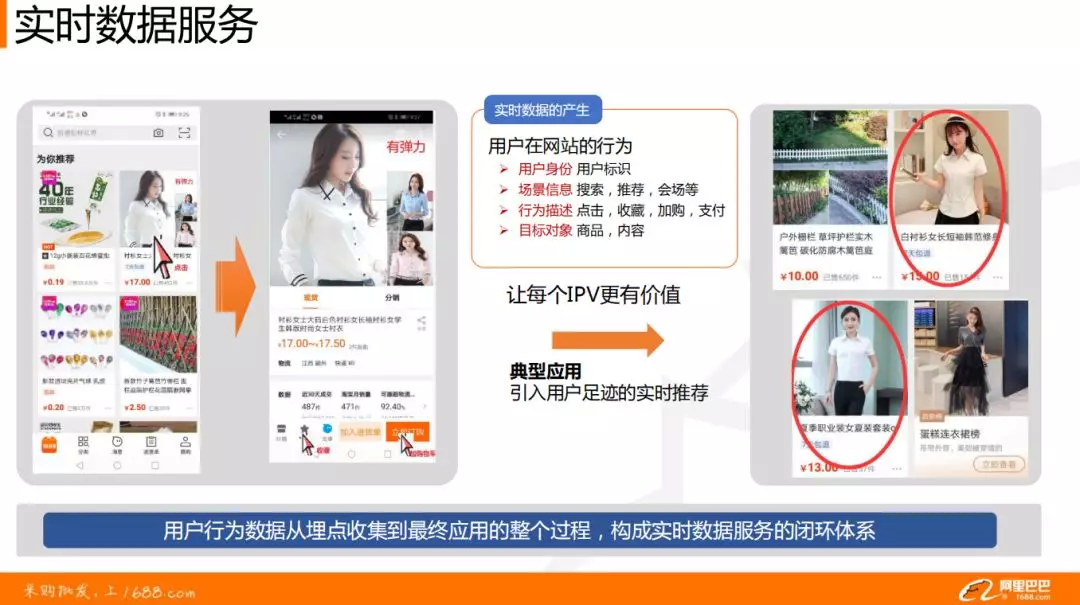
实时数据服务就是将用户行为数据从埋点收集到最终应用的整个过程,构成实时数据服务的闭环体系。利用用户的历史行为数据,进行加工、计算、孵化,作用到每一个算法需要介入的场景中,比如实时搜索、个性化推荐、会场场景等。
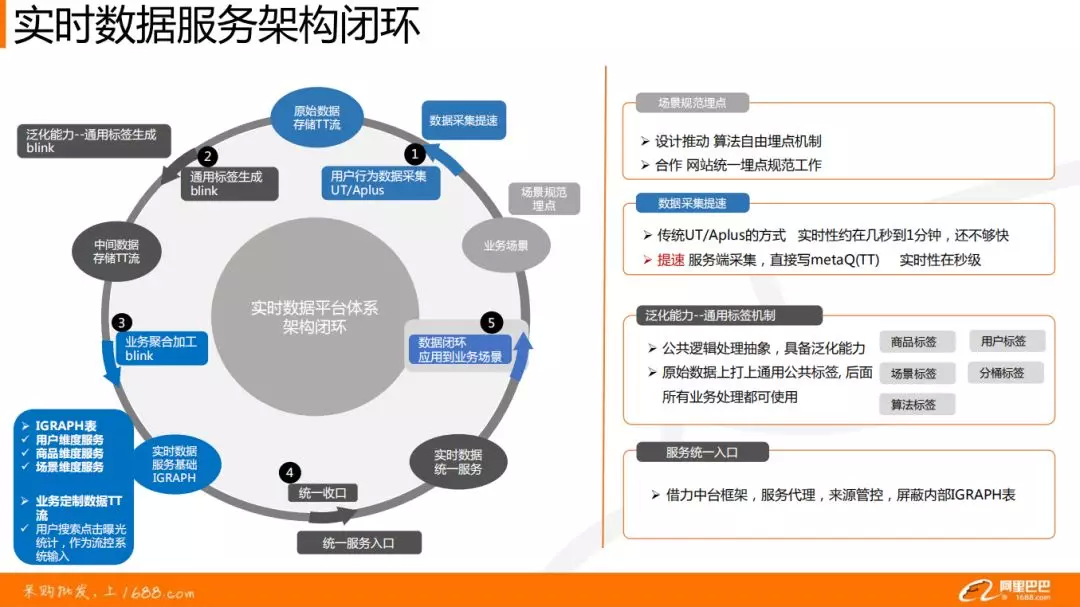
首先,通过场景的规范埋点进行用户行为数据的采集,得到原始数据存储 TT 流,这些是阿里日志中台做的工作。
其次,将数据通过 Blink 进行打标签,这里是通用标签,跟业务无关。然后,根据业务场景对数据进行多维度的聚合加工,如用户维度、商品维度、场景维度等。最后,建立统一的服务层,对外提供接口,将数据应用到业务场景中。
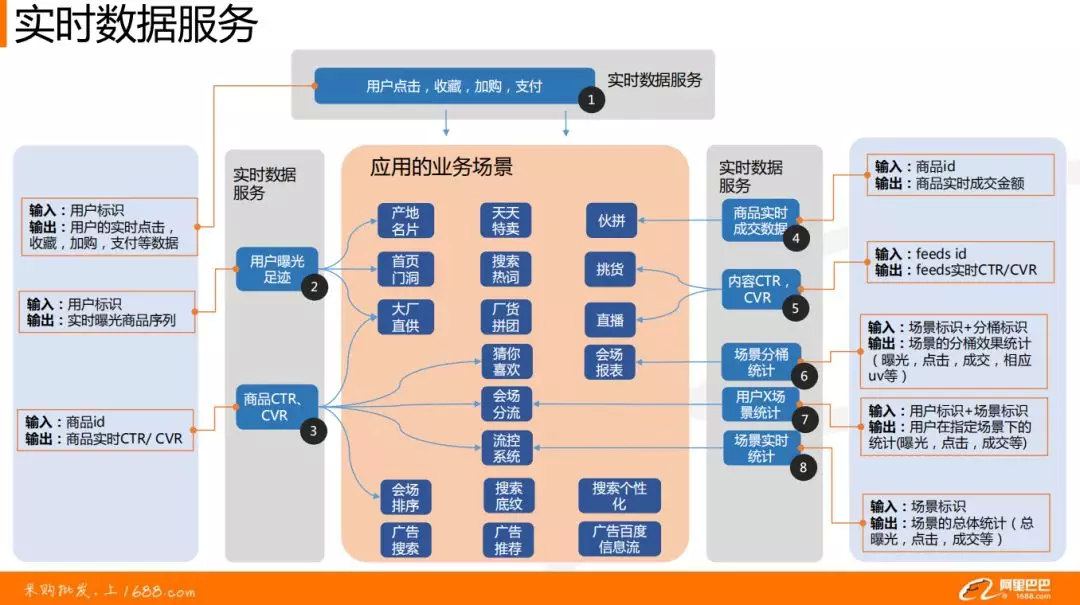
最后搭建的实时数据服务解析如上图所示:
❶ 当用户进入网站后,通过用户标识,用户的点击,收藏,加购,支付的数据将会实时进入到实时数据服务层。
❷ 用户在浏览商品的时候,会对商品做曝光过滤处理,因为不希望用户每次进入网站都看到相同的东西,而是根据算法将商品展示的序列进行优化。
❸ 每个商品,根据商品的 id 可以在后台得到商品实时的 CTR/CVR 数据,由中台基础的 Blink 提供实时计算。
❹ 根据商品 id,可以实时查询某种商品的成交额,支持批量查询。
❺ 针对于新形态的挑货与直播,通过 feeds id 可以得到 feeds 的实时 CTR/CVR。
❻ 在大促会场中,可以通过场景标识+分桶标识,快速得到对应场景的一些报表数据 ( 曝光、点击、成交、相应的 uv 等 )。
❼ 用户标识+场景标识,根据得到的用户在指定场景下的统计数据,可用于实时化的个性化分流、推荐等。
❽ 场景的标识,得到场景的总体统计,可以用于流量分配机制的完善。
作者介绍:
半醒
阿里巴巴 | 技术专家
本文来自 DataFunTalk
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论