

本文为 Robin.ly 授权转载,文章版权归原作者所有,转载请联系原作者。
本期Robin.ly CVPR 2019 专题访谈特邀 PAII Inc. 美东研究院的执行院长、前美国国家卫生研究院(NIH)资深研究员吕乐博士,在美国长滩 CVPR 大会现场分享他将深度学习应用在医疗图像领域的研究经历及个人工作心得。
PAII 隶属于平安科技公司,是一家技术驱动型公司,专注于智能城市、智能教育、医疗影像和临床信息学的技术解决方案。在加入 PAII 之前,吕乐博士曾在美国西门子研究院、美国国家卫生研究院(NIH)临床中心和英伟达公司一共工作了近 12 年。他的研究致力于改进现代医学图像理解和语义分析,以推动预防性医学、精准医学、癌症影像诊断治疗以及医疗大数据等领域的革命性临床工作流程实践。到目前为止,他共发表了科研论文 130 余篇、美国/PCT 专利 26 项,并获得了 NIH 多项科研临床贡献奖励、MICCAI 5 年最有影响力论文奖和 RSNA 2016/2018 年杰出论文奖。他曾多次担任 CVPR、MICCAI、 WACV 和 ICIP 领域主席。
个人研究背景
主持人:吕乐,感谢你今天接受我们的采访,很高兴在 CVPR 见到你!
吕乐:
谢谢,很高兴来到这里。
主持人:你在 2006 年获得了约翰·霍普金斯大学的计算机视觉和机器学习博士学位。能介绍一下你的博士研究项目吗?
吕乐:
我的博士研究是关于统计方法的计算机视觉。在加入西门子研究院之前,我做了大约 10 年的计算机视觉研究。20 世纪 90 年代的后十年是几何学的十年,人们基本上都在做射影几何和 3D 重建。我在中科院自动化所(导师胡占义)和微软亚洲研究院(导师沈向洋)度过了 1996-2001。从 2001 年到 2006 年,我在约翰·霍普金斯大学度过了五年时光,也同时参与了微软美国研究院的实习项目,毕业论文题目是统计学习在计算机视觉里的应用。深度学习一般可以视为概率学习或统计学习方法的特例。

吕乐博士在美国长滩 CVPR2019 大会接受 Robin.ly 专访
主持人:CVPR 的日程安排非常紧凑,有很多讲座和讨论环节。你对大家讨论的哪些话题最感兴趣?
吕乐:
我们有几个医学影像相关的研讨会。我本身是一个研讨会的组织者,也接受邀请在另一个研讨会上发表演讲。我自己的研讨会是关于医学影像和深度学习的,叫做医学计算机视觉,我组织这个研讨会有八年了。从 2015 年起,这个研讨会的房间都是一整天都座无虚席。我今天主会参与的“Low-shot Learning”和“Weakly Supervised Learning”两个主题讨论很有意思,跟我所研究的大数据弱标记(Big Data Weak Labeling)课题关系非常密切。作为大会的一名领域主席(Area Chair),我确实看到了各个相关领域都取得了不少进展。
NIH 工作期间的主要成就
主持人:NIH 是美国的主要政府医学研究机构,你在那里工作了六年多,还曾获得了表彰卓越的研究工作的 2017 年 NIH 临床中心院长奖 (NIH Clinic Center Director Award for Research Excellence and Patient Impact)。你的研究主要专注于图像处理中机器学习和深度学习的应用,尤其是放射图像和图像分割。能否分享一下你在 NIH 工作期间的主要成就和收获?
吕乐:
实际上在进入 NIH 之前,我还在工业界工作了 6 年。西门子美国研究院和美国医疗部门也是全世界医疗科技业界的翘楚。那段时期跟医生和医院接触不算太多,但一年也有 6 天,跟医生的交流中,让我意识到当时工作环境的局限性。因此,我决定在 2013 年初,NIH 内部的临床中心找一份联邦政府雇员研究科学家的工作,做一些其他地方没机会做或者不敢做的研究。比如我在 2012 年建议西门子开始深度学习研究,但推动很缓慢,因为西门子是行业领先的,就缺乏动力搞当时比较新的、有一定风险的研究。我们在 NIH 的研究变得非常独特,不用担心 funding,有比较大的自由度,而且我们是全球最大的以研究为中心的临床转化型医院(Translational Medicine Hospital)。我可以跟非常著名的医生们一起做临床研究,探索更好的诊断和治疗方法。
我在那里总共工作了六年,以员工身份工作了五年,又以特殊的志愿者身份工作了一年。我们是采用深度学习进行医学成像的早期实验室之一。2013 年当时很多人都不相信可以使用深度学习进行医学成像,因为医学图像跟 ImageNet 有很大不同 ——ImageNet 有 120 万张精确标记过的图像,但很少有人给医学图像添加标签。尽管如此,我们依然取得了巨大的进步,我们 2013 年底完成的工作,增大淋巴结检测就是一个例子。增大淋巴结是癌症放射影像中重要的临床生物标记物,我们将检测率从之前最好的西门子研究院的工作的 55%提高到了 83%。有一点可以说明深度学习实际上能够应用于有限的数据集,例如大概 180 名患者。与以前的手段相比,深度学习的效果非常好。
但是深度学习并不意味着要重新去做那些使用传统方法就能够做得很好的事情,其更大的意义在于帮助你解决以往很难解决的一些非常重要的问题。比如我们 2013~2014 年致力于在疾病生物标记物检测方面做出开创性的工作。去年我们的这一篇 MICCAI-2014 年发表的关于计算机辅助影像诊断和检测的文章被评为了过去五年中 MICCAI 最具影响力的论文。现在许多医院和创业公司都在研究类似的问题,这个问题的确很重要。但其实还有一个更重要的、更迫切的实际问题需要解决,那就是精准医学(Precision Medicine)。
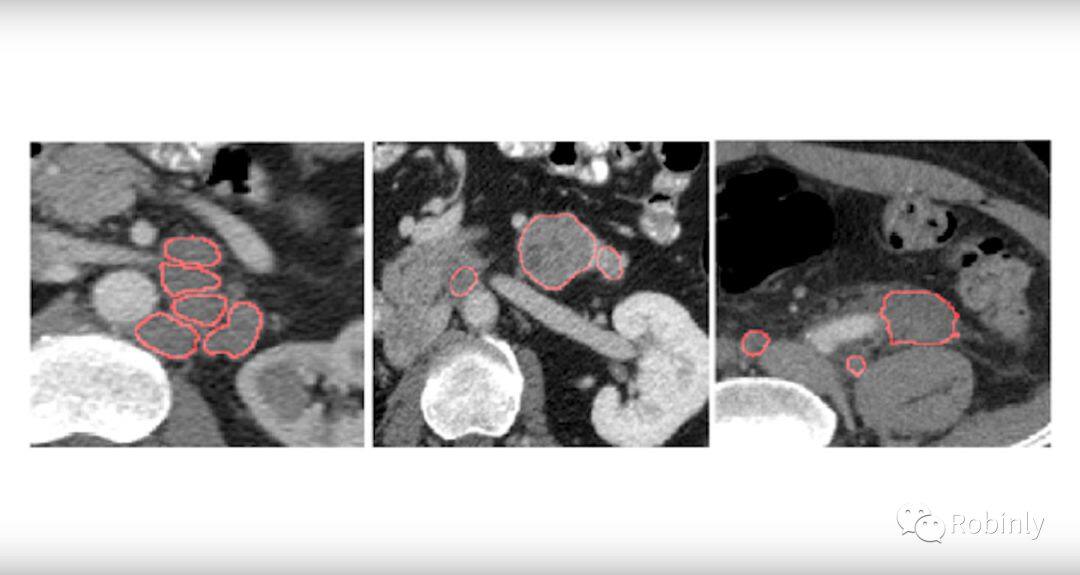
NIH 研究的精确肿瘤测量工具。图片来源:NVIDIA Developer
主持人:可以具体谈谈精准医学吗?
在我看来,精准医学更可行,它对我们的实践影响更大,手段也更加直接。在美国最好的医院,医生通常接诊一名患者的时间是 20-25 分钟,在有限的时间内能达到的诊断和治疗手段不一定最佳方法,多借助计算机或计算应用会有很大的改进空间。比如用测量的肿瘤的大小作为例子,从理论上讲,测量体积会更好,但实际操作起来非常困难。因为人类医生没有时间在 3 维甚至 4 维图像中通过一个一个标注像素来计算肿瘤的体积,更不要说随着治疗的进行反复多次测量了。所以目前的手动处理方法并不理想。你需要在观察到的肿瘤放射影像切片中找到长得最大的切片,然后测量最长的直径,即所谓的长轴,再测量跟长轴垂直的短轴,再把这两个结果添加到患者的病例中来记录肿瘤的大小。但是这测量的只是面积的近似而不是 3 维体积,即便是同一个医生,下一次测量结果也可能有偏差。
医生非常擅长做复杂的抽象推理判断,这是目前机器学习无法做到的。即使到了今天,我们也没有为机器开发出这样的算法,我们的大脑太复杂和精细了。但是对于这种简单的测量,却是机器的长项,比人类的肉眼观察结果准确得多,可以作为精准医疗中的肿瘤测量手段。我们正在从事这方面的研究。例如检查、切割和测量淋巴结,胰腺,肿瘤等等的体积。
还比如胰腺癌,仅在美国每年就有超过 40,000 人因胰腺癌死亡。胰腺癌致死率很高,几乎没有有效的治疗方法,因为发现的时候通常都已经是晚期了。所以我们可以对一些成像生物标记物进行计算,模拟体积和形状,并从原始立体像素中得提取一些医生可以理解的元特征(meta-feature),由此来判断某个病人是否患上了胰腺癌。这就是定量到精准医学。
深度学习在医疗研究的挑战
主持人:谢谢你的解释。谢谢你的解释。我们知道在精准医学和其他研究中,将深度学习之类的“黑盒子”技术应用于临床试验时会面临着很多限制。在你的研究中是如何应对这些限制的呢?
吕乐:
很难否认深度学习是一个“黑盒子”,许多方面很难解释其工作原理,或者在架构方面太复杂、参数太多。但我觉得这不是一个大问题。因为统计模型之前也是一种“黑盒子”,使用数千个特征参数,让很多人感到迷惑不解。这正是 Boosting 和 Random Forest 等统计学习算法的工作原理。我认为从某种意义上讲,深度学习反倒更容易解释。
我们的确需要在这个方向上进行大量研究,让其中的原理更容易解释。我想我们可以采取另一种方式,使我们学到的东西更易于管理。比如你正在学习判断一个肿瘤是良性还是恶性的,要如何验证?正因为无法验证,我们倾向于称之为“黑盒子”。不能在临床实践中使用一种技术,并不是因为它无法解释,而是因为它不可验证。你必须告诉医生你为什么认为这是良性或恶性的。你的根据不一定是充分的,但是可以分割成很多子任务,比如纹理特征、形状特征等等。这些子任务人类是可以验证的,医生可以判断机器是否出错了。所以在拥有所有这些可解释的、可验证的元特征之后,需要将所有这些特征整合后得出最终的决定。
我们的目标非常简单。现在,人类医生用 30 分钟可以得出一个非最优化的决定。如果我们能提供更多的信息,让他们能在 15 分钟内做出更好的判断,就可以促进医疗决策的最优化,降低成本,为医生节省很多时间,而且最重要的是服务好病人。所以一个机构只有具备重要的好价值观,才能为这个社会带来积极的价值,进而才能实现自身的可持续发展。
PAII 的精准医疗
主持人:我们聊聊你目前的职位。你在大约一年前加入 PAII 担任执行院长。你和你的团队目前在做什么?
吕乐:
我先解释一下 PAII。PAII 是一家保险公司巨头创立的研究型公司。这家公司的业务范围包括金融投资、银行、以及医疗相关业务。如果你在医疗医药行业工作,就知道这个行业可以分为三个部分:患者、医疗服务提供方和付款方,也就是保险公司或者政府。如果医疗服务提供方和付款方是独立的两个公司,那么就出现了一个比较大的问题,他们的目标不一样。

图片来源:PAII
主持人:从 PAII 的角度看,你和你的团队准备怎么解决这个问题?
吕乐:
我认为最重要的是有清晰的目标。我们正在尝试精准医疗手段,怎样才能为更多患者提供精准医疗?斯坦福在 2016 年发布了一个人工智能 100 报告。我的博士导师 Gregory D. Hager (AAAS/ACM/IEEE/MICCAI/AIMBE fellow) 撰写了其中一部分内容。报告中说在美国一部分创新会来自 Kaiser Permanante 或者 Geisinger 这样的医院保险公司一体化的公司。因为他们既是保险公司,又是医疗服务提供者,所以医院和保险公司是同一个组织。这样一来他们就更有动力提供更好的医疗服务并降低成本。因为这两方没有利益冲突,唯一的客户就是患者。我希望将来这样的保险公司和医院的结合体会成为趋势,这样他们就会争取更高的效率和更低的成本,以提供更好的诊断和治疗服务,更快的改善患者的的健康状况。
PAII 正在帮着医疗体系朝着这个方向努力。PAII 的母公司是全世界最大的综合保险公司之一,医疗是很重要的一块,他们很早就看到了这种体系的优势,也一直致力于做出改变。所以我们会更积极的进行患者管理,健康管理,而不只是被动的为医疗服务买单。
深度学习的发展方向
主持人:我的最后一个问题是,一开始,许多人工智能研究人员认为深度学习可以颠覆整个行业。然而,深度学习严重依赖数据,其性能与可用来训练的数据量密切相关。在你看来,深度学习的局限在哪里?能不能总结一下你认为深度学习在未来会朝哪个方向发展?我们应该为此做哪些准备?
吕乐:
这是一个非常好的问题。首先,我们人类的学习能力很厉害,并不需要依靠大量数据来学习。从数据科学的意义上来说,我建议从数据本身的规律和特征入手,找到它们之间的相关性,模拟不同数据样本之间的关系,再将观察和结论映射到具体的问题上,从而解决问题。这是从数学角度得出的答案。
另一个答案是在临床领域。我跟医院的负责人和医生们都交流过。其中的一个问题在于,医生不会被要求做用于训练计算机进行图像标记的专用标注,用 Amazon Mechanical Turk 之类的工具创建像 ImageNet 这样的图库也是不太可行。很多情况下,人类医生的医学训练和从事的医学日常工作并不是像给图像打标签这样的任务。举一个例子,一个主治医生遇到了无法立刻诊断的病例,他会翻阅患者的病例查看之前的诊疗记录和拍过的片子,并整合自己在医学院学到的知识和自己的从业经验来做出判断。
我们工作中有很大一块的内容在试图构建一种整合医疗信息的新方法。最近几年,我们的六篇 CVPR 论文和一篇 WACV 论文都是关于这方面的研究,比如整合病人医学图像,临床报告和其他病人信息。我们的日常临床工作中每时每刻都在产生这样的信息。凭借这些大量的病例文字储备,我们就有可能理解医生所传达的信息,并将其作为标签来训练机器对图像进行学习。这样一来就能节省大量的时间和成本。两年前,我们围绕胸部 X 光图片构建了一个庞大的公开数据集。而在去年的 CVPR,我们发布了另外一个大数据集,包含不同类型肿瘤的 1 万多个患者研究案例。没有任何标签是通过 Amazon Mechanical Turk 生成的,当然也不推荐这样做。这个数据集包含了医生的诊疗信息,还有视觉图像数据分析。所以你必须训练新的算法,让算法来理解图像,文字描述和肿瘤学之间的关系,来进行自我注释。它也是一种学习过程,人类就是这样学习的。在我看来,这就是未来。
个人经历感想
吕乐:
1. 工作生涯要勇于走出自己的舒适区,不要像温水煮青蛙一样混日子,要理解现在工作的局限性和优势所在。还要有拼搏精神。
第一次从西门子工作换到 NIH, 很多同事和朋友是不理解的。当时比较幸运,前五年,一直集中精力在西门子的肠癌和肺癌计算机辅助检测诊断项目上做出了比较核心的贡献,也提升了两次从 C 级到 E 级,但第六年已经感觉再做下去有很大的局限性了。必须要找一个地方能够换一个方法来做出下一波比较重要的工作。当时 NIH 在计算方面和人工智能上比西门子还是差距比较大的,但是可以提供自由空间发展,当然更重要的,符合我想要"技术和医生医疗无缝合作"的理想。
在 NIH 的几年研究生涯中,我很幸运一直有一个富有活力,多种族文化融合的博士后和学生团队,我们保持了比较高的研究热情和好奇心。年复一年热情十足的赶了一个又一个项目, 经常工作到第二天早上天亮。在政府里面也算是一景了。以至于前一段时间我们放射系的医生见到我,还说很想念我们在的时候, 那时系里总是很热闹。有道是天道酬勤,我们在 2013-2018 年间,也作出了对整个行业和研究领域,有比较重要推动作用的一系列工作。获得了 NIH 内外的多个奖项,研究工作也得到了英伟达和平安科技两个大公司的合作和资助。直到在 CVPR 2017 期间,被英伟达的老黄直接招聘,并给我们在马里兰州建立一个新的实验室。从学术界出来,有两个原因,一个是为了能够帮助到更多的病人和医生,实现社会理想。第二是为了一起奋斗的博士后们找个正式的工作,可持续发展。

吕乐博士与 NIH 团队成员
2. 在工作中找到真理,找到最应该追求的并有理想。
“因为相信,所以看见”这句话是非常有道理的。新的有价值的东西往往开始并不存在,要创造出来才会有。因此,第一,需要勤思考,有视野,能够有找到真理;第二要能够执行好,坚持不懈。因为相信所以看见的东西往往有比较大的不确定性,大概方向对就好了。人要有好奇心,有探索精神,好的科学训练,卓越科研能力和工程能力,有能力走到彼岸。
3. 职业生涯中期的研究者可以考虑做一个有视野、有担当,善于培养人,善良并有原则的领导者。
我在 1996 到 2006 年间一直都在研究院:中科院自动化所三年,微软研究院两年,约翰霍普金斯大学五年。我有幸有三位德艺双馨的导师们相伴,一直是我人生的楷模,特别是沈向洋博士和 Greg Hager 教授,教会了我什么是身体力行的领导力和亦师亦友的关系。人生不可能一帆风顺,这些温暖让我在之后的挫折中,也一直对人性没有失去希望。爱是永恒。长存感恩之心,自己也无比幸福!
主持人:非常感谢你分享的见解!
原文链接:
公众号推荐:
2024 年 1 月,InfoQ 研究中心重磅发布《大语言模型综合能力测评报告 2024》,揭示了 10 个大模型在语义理解、文学创作、知识问答等领域的卓越表现。ChatGPT-4、文心一言等领先模型在编程、逻辑推理等方面展现出惊人的进步,预示着大模型将在 2024 年迎来更广泛的应用和创新。关注公众号「AI 前线」,回复「大模型报告」免费获取电子版研究报告。


硅谷AI科技、创业、领导力访谈

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论