

我是腾讯技术架构部的工程师杨原,今天我给大家分享的题目是腾讯云 Kafka 自动化运营实践,主要想跟大家分享一下我们在运营 Kafka 过程中遇到的一些问题,那么我们是怎么去解决这个问题的?我们是怎样根据解决问题的经验去做自动化运营的系统?
先给大家介绍一下,腾讯云的 Kafka 是基于 Apache Kafka 的高可扩展、高吞吐的云端 kafka 服务。我们的优势是不需要用户去部署集群,不需要用户去维护整个系统。另外,我们的 kafka 是按实例售卖,用户只要购买了实例之后,就可以直接使用 kafka 的所有功能,同时我们也为用户提供了多维度的监控。对用户来讲,我们支持动态升降实例配置,用户只要根据自己的需求,按照自己的需求去付费购买就 OK。最后腾讯云的 kafka 是与大数据套件、云存储等服务无缝对接的,使用起来非常方便。
从现在运营现状可以看到,我们日消息量达到了万亿条,总流量也达到了 10PB 的级别,单集群的峰值每分钟能达到达到十亿条,Broker 节点过千个,集群也达到数百个,付费实例超过千个,topic 也有数千个。
面临哪些挑战
正是因为我们运营一个如此庞大的集群,我们面对的问题就会非常多。我把这些问题概括了为五类。

首先第一,由于我们是一个云端的产品,我们面对客户肯定是不同的,那么用户使用的 kafka 版本也是多种多样的,解决用户不同版本的问题也是我们首先需要考虑的问题。第二,是由于我们是一个云端的版本,是按照一个实例去售卖的,所以我们的实例怎么样分配在云端的所有节点上,才能保证我们一个资源的合理利用率,从而降低成本。再者,如何实现用户之间实例升降配的需求?用户在使用的过程中,往往初期购买一个测试实例,测试成功后,用户才会把实例升级成生产环境的实例版本规格。最后,在运营整个节点和整个集群的时候,什么时候需要处理一个节点的加入或移除?一个分区的创建,新增分区的时候,我们会基于哪些维度去考虑这几个操作?
分区的创建、新增和迁移
首先讲讲不同版本的 kafka 是如何选择的,起初 kafka 运营的时候,我们发现这么一个问题,今天可能老王使用,使用的是 kafka 的 0.9 版本,而第二天老张使用的 kafka 版本可能就变成 0.10 了,这时候我们要怎么解决不同版本之间的问题呢?其中一种解决方案,就是在后端部署多个版本的集群,这样的话如果老王接入的时,实例就分布为版本 0.9 的集群,老张接入的时候,我们将版本分布在一个 0.10 的集群。但是这样做有一个问题,用户接入我们云端的 kafka 的时候,我们需要提前预知它是什么版本,这样我们才能将它实例分布到对应的集群上,那这无疑是大大增加了用户接入的代价。
对于这样的不同版本的集群,运维起来也会增加相应的成本,每个节点不能对所有集群透明,那我们怎么解决这个问题呢?我们改造了 kafka 生产的底层,底层会进入多个版本的消息格式,在不同消息格式之间,我们支持格式的转换,这样用户接入 kafka 的时候,我们就无需知道这个用户使用的什么版本,因为对于用户来讲,集群是统一透明的。
实例选择合适的 Broker
接下来讲讲我们实例在创建的时候是如何选择一个合适的 Broker。我们云端的 kafka 是按照一个磁盘和带宽流量两个维度去进行售卖的。每售卖一个资源,就会在相应的机器上扣除需要的服务能力。比如我们现在有一个实例,它的服务能力上限是 300 兆的带宽跟 500GB 的磁盘,假设我们现有候选节点如下:broker1/broker2/broker3,可以看到他们剩余的带宽跟磁盘容量资源都是不一样的。假设用户把实例的容量服务能力分配到我们的节点,大家可以发现我们剩余的带宽剩余为 0,但是我们还剩下了 500GB 的磁盘服务能力,这时候会造成什么情况呢?就是说我们剩余这 500GB 的磁盘服务能力是无法售卖的,因为已经没有带宽,因此我们不能把一个实例的服务能力再分配到这个服务中,于是我们采用了一个方法去解决这一问题。
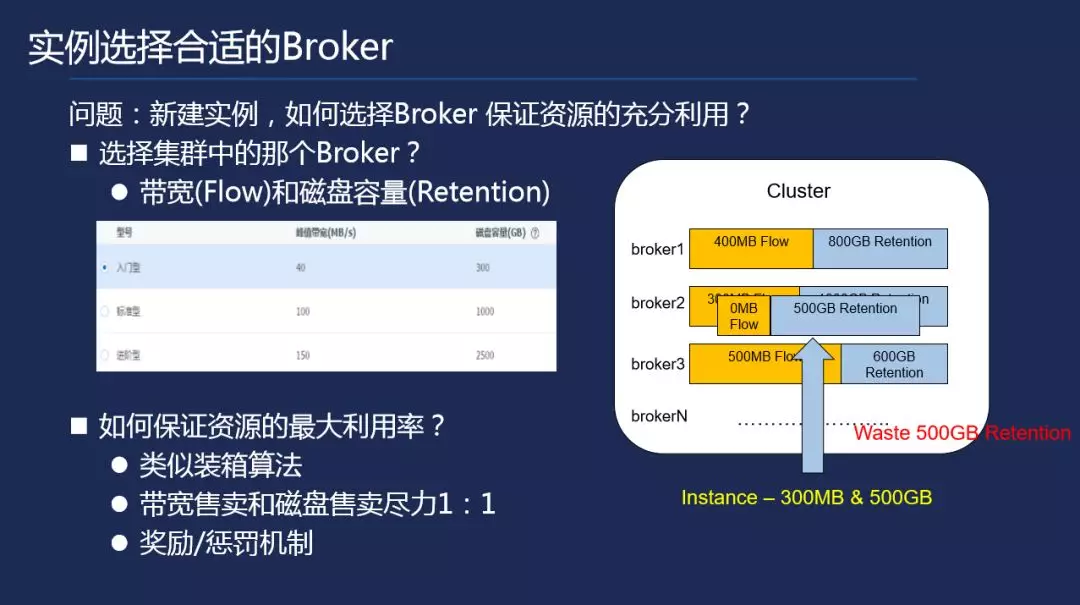
如何保证最大的资源利用率呢?我们采用一个类似装箱算法的方式,把这些实例全按照权值计算出合理的方案分配到上面。分为带宽售卖和磁盘售卖,我们希望尽力保持在在 1:1 的比例,比方说这个节点上,我们带宽卖了 50%,我们也希望磁盘售卖 50%。这样这样就可以尽可能的避免带宽跟磁盘的售卖不均。
我们还有一个奖惩机制,当一个实例分配到该节点上之后,它剩余的资源如果不足以满足我们下一个最小实例的售卖的时候,我们会进行计算并进行降权处理,尽力不让这个分配发生。假如说我们一个分配完成之后,剩余的资源恰好满足一个最好实例的话,我们就会按照它的带宽跟磁盘的售卖比去计算,计算权值越大,就其更倾向于分配到这个节点上。通过这种算法,我们发现整个技术群的资源利用率是有百分之十几的提高。
实例的升配
用户刚开始会买一个比较小的实例,因为用户一般会先做一个功能性测试,当满足它功能性测试之后,用户就会升级实例,去升级成满足生产环境测试的规格。做这种实例升级的时候,我们又会遇到了两种情况。第一种是用户所在的节点的剩余的资源满足这一次实例变更需要的服务能力,比如用户现在需要升级 100G 和 100M 的带宽,这个节点上有足够资源,那么直接升级就好了。第二种情况是当 broker 资源不够的时候,我们怎么样将实例的服务能力扩展到其他机器上,以满足这个升级的要求。假设我们现在有一个实力占据了三个节点,分别是 300M 和 1.5T 的服务实例。发现节点一节点二剩余的资源都满足这一次升级的要求,但是节点三不够了,这时候我们要怎么办呢?实例服务能力的迁移我们有多种方式,我们可能会考虑把实例换一个新的节点,因为没有这么多的节点能完成一个实例升级和扩展,或者我们会把这三个节点的服务能力扩展到更多的机器上,这时候可能每个机器上的需要的能力就相对减少了,每台机器只需要 75M 带宽跟 375GB 的磁盘服务能力。当有这种变更方法之后,我们需要知道我们把它扩展到哪些节点上,这就使用到刚刚提到的资源售卖的公式,我们会选择一个合适的机器去保证实例升级,不会影响后续的资源利用率。

计算完所有的变更方案,我们需要计算一下它迁移代价,大家可以看到不同的迁移方案迁移代价是不一样的,我们现在迁移代价基本考虑的是一个 partition 磁盘的占有量,也就是迁移的时候,它会将实例所占据的 broker 上的 partition 进行迁移,那么迁移的时候最致命的是什么?如果它数据量非常大的话,迁移时间会非常长,可能不可控,所以我们会选择迁移量最小的一个方案去进行迁移。迁移完毕之后,我们就可以满足实例升降配的需求了。
我们运营这么大集群之后,第一,什么时候进行节点的加入和移除?先讲讲我们新增节点,当我们一个资源池里面资源不足以售卖,或者不足以一个实例进行升降的时候,我们会增加节点进行实例迁移,或者增加准数和资源,为了实例后续的售卖,这种情况下,我们必须需要新增几点。第二,我们节点资源碎片整理,即使是我们采用了一个像类似创伤算法的方式去分配实例,资源的浪费也是不可避免的。当我们节点资源有碎片的时候,我们可能会加入新的节点,把这些小碎片节点空闲出来进行下一次的售卖。
最后一点是当我们需要机器负载均衡的时候,我们也会添加节点,当你发现一个集群里面每个机器都处于比较高负载的状态,当然,高负载是大家自己定义的,比如 CPU 利用到 60%这种情况下,你认为它是一个高负载状态,这时候也可以考虑通过添加一个节点这种方式,将现有的服务迁移到这些空闲的节点上,来达到整个集群处于一个相对负载均衡的状态,一个比较健康比较理想的状态。
那么当节点增加之后,我们什么时候会移除节点呢?首先第一点是当一个实例收缩的时候,我们会移除我们的节点实例。比如某些用户扩容之后,发现生产环境的需要的实例又不需要很大,它缩容之后可能只需要在部分节点上满足他这个服务需求,也就是同样也会将部分空闲机器进行一个下降。第二点是当节点故障的时候我们也会移除。当节点故障的时候,partition 进行迁移的服务。
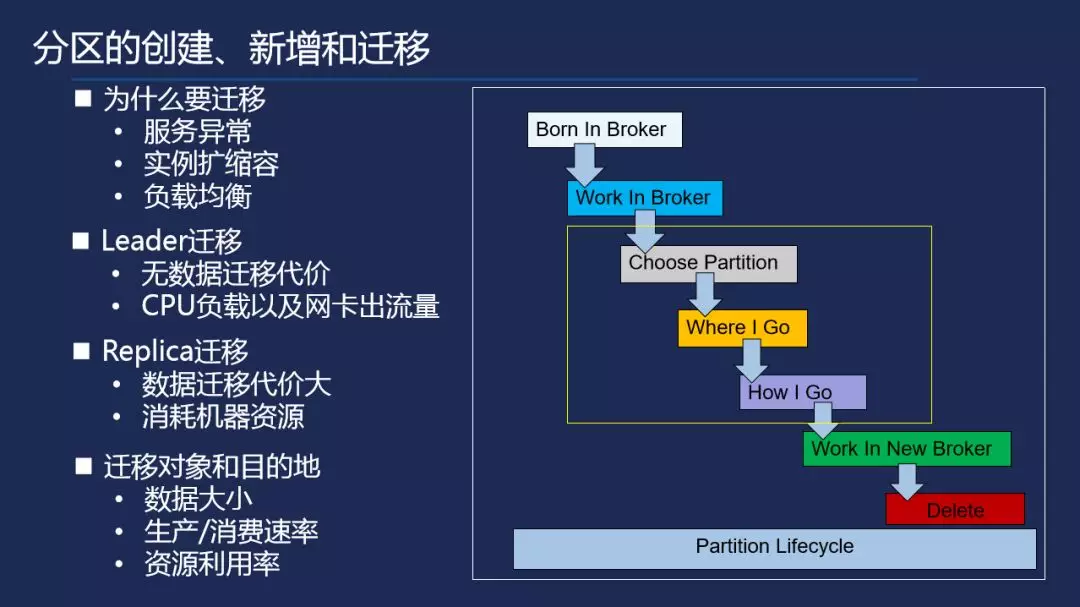
最后我们讲讲迁移对象的和目的迁移对象是怎么选择的?首先迁移对象,我们会根据刚刚说到 partition 的数据大小来选择迁移对象,因为 partition 数据大小直接决定了我们整个迁移过程中消耗的时间,而且不可控除了数据大小之外,还有生产跟消费速率。我们先尽力去选择一些生产跟消费数据,对比较小的数据进行迁移,这样的话用户的感知相对小一点。如果它生产消费速率比较大,迁移的过程中,流量会非常大,会影响到我们节点上的其他用户,其他用户可能就会感知到。迁移目的地,会根据资源利用率去选择,我们会尽力选择资源利用率比较高方案去进行迁移。迁移的时候我们会考虑以下两个因素,一个是实例的分布,我们希望一个集群一个下的实例,平均分布在服务的每一个节点上,从而数量上达到均衡。其次我们会考虑网络流量的均衡,比方说我们现在有一个实例,迁移之后我们希望 paitition 是 20M 的带宽,我们首先会排序,尽力将大的平台上小的部分组合起来,迁移到某一个节点上,这样的话我们就能尽力的保证在这里整个实例服务后端的这些节点处于流量相对均衡的状态。
未来展望
对于未来的展望,我们认为现在的管控对自动调度系统,维度还是相对不足够的。我们会考虑 replica 跟 leader 的数量,同时进行负载均衡,但是其实后续我们希望能够根据更多的资源维度,比如 CPU/MEN/IO 这些维度去进行我们更多的负载经营决策的资源。
另外,我们发现在迁移一些比较大的实例情况下,执行时间是无法衡量的,我们也不知道这个任务执行了这么久之后,他是成功还是异常的状态,是不是健康的。我们希望后续根据更多的维度,更好地衡量迁移时候的时间。也希望我们后续能做到预测调度的功能,我们现在调度是基于已经发生的情况进行调度,也就是肯定已经遇到了问题,我们才会去调度,那么我们后续希望我们能做到根据集群或者节点的负载增长,提前去预判这个节点,这个集群是否需要增加节点,以达到资源后续的健康服务。
最后我们还是希望能提高资源利用率的使用。即使根据刚刚所说的算法去计算分配方式,还是会有不少的资源浪费的情况,后续会根据实际运营数据去更好训练这个模型。
Q/A
Q:你好,请问你们限制时限的时候是怎么做的?怎么保证他只用了这么多?
A:购买实例的时候,我们会有一个的流量控制的模块,然后每个 broker 在生产运营过程中,系统会知道用户所分配的定额,每次我们会有一个流量模块在 broker 里面,broker 根据每秒钟生产的吞吐率扣除资源,我们有一个单独的流量控制中心,去显示它的实时的状态。比如说我们现在有三个节点,假设用户购买的实例是某一个节点,他可能只占用了 20M 的资源,然后我们是能统计到每个节点上面的资源使用率,我们可能会将另外的资源分配在更多的节点上,以此来满足用户的流量总需求。如果用户实际上吞吐率超过了网卡 100M,那怎么办?我们就会把这个消息挂起来,把系统的请求挂在我们的一个资源轮里面,等到延迟回复。
Q:你好,杨老师。请问售卖的部分是根据有带宽跟硬盘的大小,我没有看到其他一些资源,比如说 CPU 内存好像是不受影响,而你说的这两个资源我们是会消耗的,但是首先是不是需要考虑它是一个高吞吐模型呢?
A:首先的带宽肯定是有影响的,比如说一个水管,我们一个网卡在这里,一个用户占据了这么多带宽资源之后,另外一个用户肯定会受损。消息保存时间固定的情况下,带宽越大,它磁盘容量也会变大。根据是当前的一个运营情况来说,第一,对于当前场景,CPU 不是我们的瓶颈。第二,我们的带宽和磁盘对于我们机型来讲相对吃紧一些,这个会直接影响了后续的售卖。也就是说我们现在根据磁盘和带宽去售卖是根据我们实际运营情况决定的。
Q:你好,我想问一个问题,死循环的话要一般多长时间可以发现?传送到大的文件什么时候发现?
A:我们的每个任务会有初步的估值,比如说它传输的数据量,每个实例有一个宽带,我们会将这个数据量除以宽带值做一个初步的分析。在我们调度过程中,我们会把每个调度细分到小任务,每个 partition 单独去迁移,这样的话整个时间相对可控,我们管控系统在数据量迁移的过程中,可能会每小时或每一段时间提醒我们开发跟运维人员,如果发现一个任务持续时间很长,会自动报警,由业务人员介入处理。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/OlVERexiX6QuwgIhzp7Scg

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论