
【编者的话】A /B 测试曾在多个领域产生深远的影响,其中包括医药、农业、制造业和广告。 在软件开发中, A/B 测试实验提供了一个有价值的方式来评估新特性对客户行为的影响。在这个系列中,我们将描述 Twitter 的 A/B 测试系统的技术和统计现状。
本文是该系列的第二篇,主要介绍了 Twitter 的 A/B 系统后端的实现。
注:本文最初发布于 Twitter 博客,InfoQ 中文站在获得作者授权的基础上对文章进行了翻译。
正文
在前一篇文章中,我们讨论了 Twitter 进行 A/B 测试的动机和 A/B 测试如何帮助我们进行创新。在这篇文章中,我们将介绍 Twitter 的 A/B 系统后端是如何实现的。
概述
Twitter 实验工具 Duck Duck Goose(简称 DDG)最早构建于 2010 年。它已经演变成一个系统,能够聚合许多 TB 的数据,比如 Tweets、社交图谱变化、服务器日志和用户在 Web 和移动端的交互记录,从而对大量的柔性指标进行测量和分析。
在一个很高的层次上,其数据流相当简单。
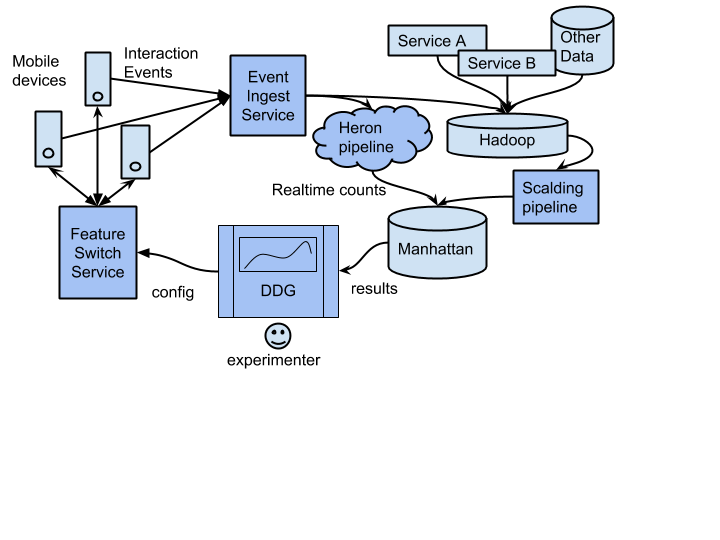
数据处理管道
工程师通过 Web UI 配置实验,并指定一些细节:
-
_Ÿ谁符合实验的条件?_ 我们可能希望将实验限定到特定语言、国家、操作系统,等等。
-
Ÿ“实验桶(_Treatment Bucket)”是什么?_ 我们可能有数种替代实现或者设计,对照当前生产版本即“控制桶(control)“进行测试。
-
Ÿ_ 实验假设是什么?_ 这一变更将如何影响用户行为?希望改进哪些指标?
-
_ 应该跟踪哪些指标?_ 除了与实验假设直接相关的指标,可能还有其它一些有意义的指标需要跟踪。有些指标会被所有实验跟踪;其它的可以在实验配置过程中创建或者从其它现有指标库中选取。
然后,DDG 会提供给工程师一些代码,用于检测哪种实验桶应该推送给客户。对于特性开发人员,这就是一种简单的“特性开关”——一种用于控制特性可用性的通用机制。任何时候当应用决定用户是否是一个实验体时,我们就记录一个 “A/B 测试印象(a/b test impression)”。将决定延迟到用户即将收到实验影响之前会增大统计功效。
Twitter 应用程序的使用数据将被发送到“事件采集服务(event ingest service)”中。一些轻量级的统计使用运行在 Heron 平台上的 TSAR 通过流处理任务实时计算。大部分工作是离线完成的,使用 Scalding 管道,结合了客户端事件交互日志、内部用户模型和其它数据集。
可以认为,Scalding 管道具有三个不同的阶段。
首先,我们将原始数据聚合成每个用户每小时的指标值数据集。结果如下:
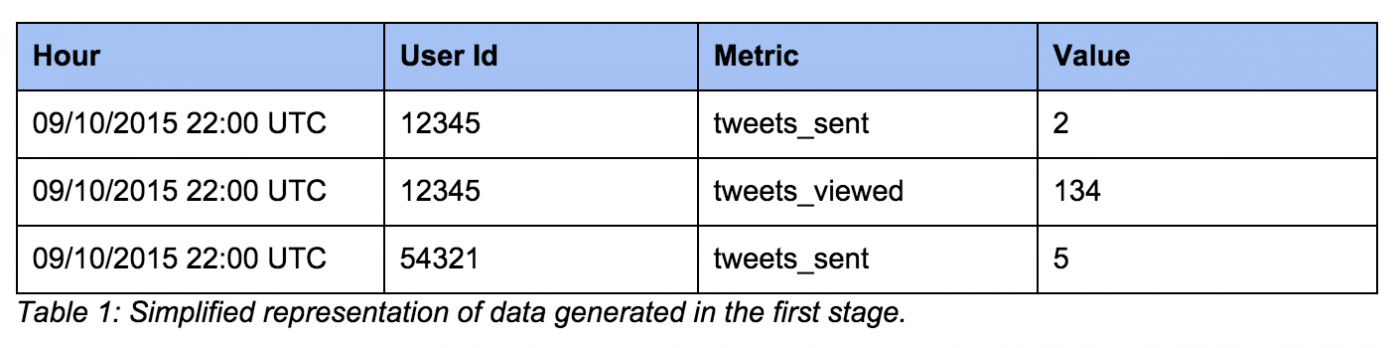
这些数据将作为下一阶段的输入数据,除了实验外,也将作为分析的数据源——顶层指标计算、“特殊队列(ad-hoc cohorting)”,等等。
然后,我们结合实验 A/B 测试印象中每个用户的指标信息,在实验运行时计算每个指标、每个用户的聚合值。由于用户可能在不同的时间进入不同的实验,因此这种聚合在不同的实验中可能有不同的值。
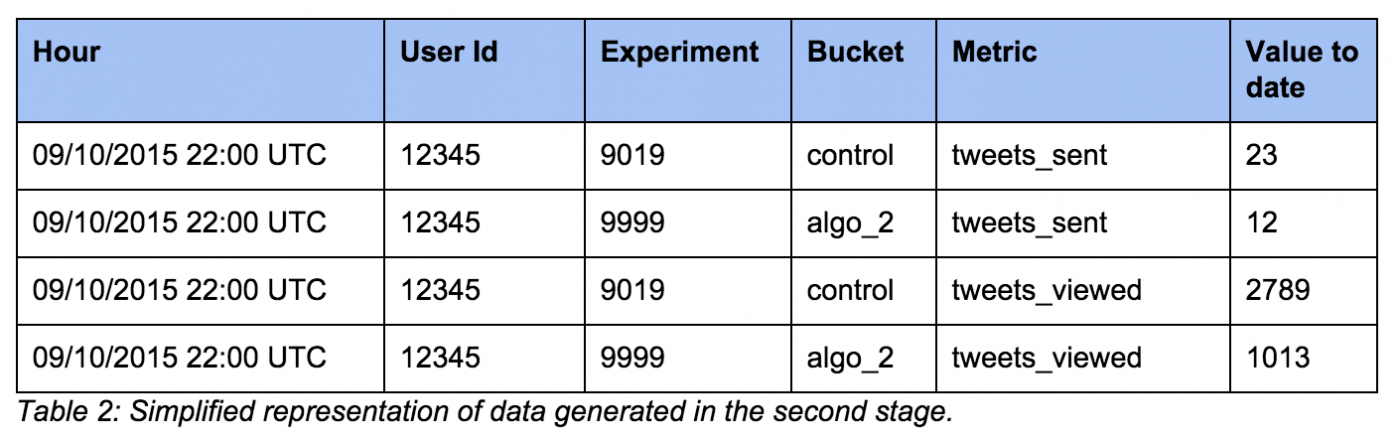
同时我们也会记录用户第一次进入实验的时间,记录他们是否是新的、偶然的或者频繁的用户以及其它元数据。这能够在实验过程中实现实验结果的分割和属性值变化的测量。
第二阶段的结果对深入挖掘实验和研究替代分析方法非常有帮助——它们让我们能够迭代不同的聚合技术、分层方法和各种处理异常值的算法,等等。
最后,第三阶段会聚合所有实验数据。

这就是加载到 Manhattan 的最终实验结果数据,产品团队可以通过内部仪表板进行浏览。
指标的定义
DDG 是一个能够衡量显著差异特性的平台,其中一些特性还没有被发明出来。这意味着我们需要平衡柔性指标定义的可预测性和稳定性。
我们提供了三种指标类型,按集中控制和规范降序排序如下:
- _ 内置指标:_ 大部分内置指标由实验团队定义和维护;比如“发推次数”或者“登录次数”这些核心指标。所有实验都会自动跟踪这些指标。
- _ 实验者定义和配置的指标:_ 实验者可以使用轻量级 DSL 指定需要计数的“事件”。许多指标可以通过匹配特定的特性谓语,简单定义为计算通用客户端事件日志中的所有行。DDG 管道会评估这些谓语,并为实验者实现所有计算。
- _ 导入的指标:_ 这些指标完全由 Twitter 工程师创建和维护。实验者可以根据上表 1 创建自己的聚合方法,并导入系统。创建自己的聚合方法的工作量比其他两种选择多很多,但是能够实现数据源及转换和聚合逻辑的最大适应性。
为了帮助实验者找到合适的指标集,并保持指标定义的正确和通用,指标会被收集和整理成“指标组”。每个指标组由创建团队维护和变更。指标组的历史版本、所有权和其它属性都将被跟踪。这鼓励实验者之间的共享和交流。
随着时间推移,有意义的跟踪事件的组合数量和实验者数量逐渐增长,会出现冗余的指标。这会引起混乱(比如内置的 “Foobar Quality”指标和 Bob 定义的 “Quality of Foobar”指标的区别?)。在我们“TODO”列表上有一个有趣的项目是创建一种能够自动识别度量相同内容指标的方法,并建议指标调和。
管道的伸缩性
实现聚合管道高效运行是系统最大的挑战之一。数据源的交互每天就会产生数千亿的事件;相对而言,低效率会显著影响总运行时和处理成本。
我们发现 Hadoop 的 Map-Reduce 任务的轻量化、恒定分析对性能问题的快速分析很重要。为此,我们与 Hadoop 团队合作,在 Hadoop 构建中实现按需的 JVM 分析任务(实现 YARN-445 及若干后续事项),同时安装一键式线程转储,并为所有任务开启自动 XProf 分析。
通过分析我们发现了一些提高效率的机会。比如,我们发现一些地方可以存储自定义指标事件匹配的结果。如果可能,我们用生成的数字 ID 替换字符串。针对 Hadoop Map-Reduce 我们还应用了一些技巧:map 和 reduce 阶段的排序和溢出缓冲调优、数据排序实现聚合过程中 map 端的最大压缩、“及早规划(early projection)”等等。
在 2015 年初的 Hack Week,我们发现在 Hadoop 映射任务的 SpillThread 上浪费了大量的时间,SpillThread 负责对部分映射输出进行排序,并写入磁盘。SpillThread 的大部分时间浪费在反序列化输出键,并对其进行排序。Hadoop 提供了一个 RawComparator 接口帮助 Hadoop 高级用户避免这种情况,但是不适合我们使用的 Thrift 对象。
我们构建了一个原型,为序列化 Thrift 结构实现了一个通用的 RawComparator,并用基准问题测试了收益。我们的原型做了一些修改,针对最坏情况做了基准测试,但是由此产生的 80% 的收益已经足够重要,因此我们从 Scalding 团队招募了一些工程师,切实地为 Thrift、Scala Tuples 和 Case 类实现这个想法。最终以 OrderedSerialization 特性发布在 Scalding 0.15 中。在 DDG 任务中开启该特性能够节省 30% 的整体计算时间!更多细节可以参考 Scalding 团队在 Hadoop Summit 2015 上所作的题为 “ Performance Optimization At Scale ”演讲。
最后,我们有两层防护可以确保我们没有引入性能衰退:预防和检测。为了预防衰退,除了常规单元测试,我们还有自动化测试,让我们在交付准备环境中能够运行完整的端到端管道,并比较两者的结果(保证正确性)和所有的 Hadoop 计数器(检查是否存在性能衰退)。为了检测生产环境中是否存在性能问题,我们创建了 Scala 特性,使得 Scalding 任务能够向 Twitter 的内部可观测基础设施导出所有的 Hadoop 计数器。这意味着,我们能够轻松地使用公共模板为 Scalding 任务生成仪表板,创建问题警报,比如长时间运行或者长时间不运行,快速检查以过高速度发生的特定类的允许误差,等等。
结论
支撑 Twitter 实验平台的基础设施非常广泛,主要是由于需要处理大量的数据,以分析实验。该系统必须在可用指标的灵活性和预测性及易于分析之间进行权衡;管道设计实现了多粒度数据的生成,使不同类型的分析成为可能。我们在效率处理方面投入了大量的精力,包括全面的自动化测试和持续改进,以分析和监控 Hadoop 的性能。
致谢
多年来,许多 Twitter 工程师一直从事这些工具的开发;我们要特别感谢 Chuang Liu , Jimmy Chen , Peter Seibel , Zachary Taylor , Nodira Khoussainova , Richard Whitcomb , Luca Clementi , Gera Shegalov , Ian O’Connell , Oscar Boykin , Mansur Ashraf 所做的贡献,以及 PIE,Scalding 和 Hadoop 团队所作出的贡献。
编后语
《他山之石》是 InfoQ 中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到 editors@cn.infoq.com。









评论