

数据中台的概念如今在国内风靡一时,而人们渐渐开始有这样的疑问:中国的数据中台市场如此火热,而国外的数据中台却没有什么声音。事实并不是这样,硅谷的公司其实已经早于中国建设了所谓的”数据中台“。只不过,在国外,并没有数据中台这个称谓,而是统一以数据平台的名称命名,但是这个数据平台已经具备我们所说的数据中台的全部功能。那么,作为全球技术风向标的硅谷企业的“数据中台“到底什么样,他们的“数据中台”是如何建设的?想必很多人对此多充满着好奇和疑问。本期InfoQ公开课的直播嘉宾宋文欣博士在美国取得博士学位后就开始在硅谷从事大数据方面的工作,并曾任职美国四大搜索引擎之一的 Ask.com 以及久负盛名的美国游戏公司 EA(艺电),本次直播课将由他来讲述硅谷“数据中台”的故事。
大家好,非常荣幸有机会跟大家分享硅谷的数据中台实践,我叫宋文欣,在美国纽约州立石溪大学完成博士学位后到硅谷的搜索引擎公司 Ask.com 工作,担任大数据部门的负责人,当时 Ask.com 搜索引擎的市场份额在美国排第四位,前三名分别是谷歌、微软和雅虎,随后我加入硅谷的游戏公司 EA(艺电),在数字平台部门担任高级研发经理。在此期间,我经历了从 0 到 1 打造 EA 数据平台的过程。2016 年 8 月,我同在 Twitter 担任大数据架构师的室友共同创立了武汉智领云科技公司,从事企业级大数据操作系统的开发和推广,以下是我今天分享的主要内容。

以下内容希望可以从侧面给大家提供参考,并不是说硅谷的经验一定要全盘照搬,但可以看硅谷在数据中台建设方面的方法论和技术对自己的业务发展是否有帮助。
硅谷的中台论
首先分享下硅谷的中台论,硅谷其实没有中台这个词语,这是国内特有,最先由阿里提出,但是硅谷很早就有类似中台的建设,比如 Hadoop 将分布式计算和分布式存储等技术作为中台开放出去,让开发者共享和复用。
我在 Ask.com 任职期间,我们内部的中间件团队会将整个分布式系统里面的监控系统、文件存储等做成组件提供给公司的各技术部门使用,这也是技术中台对外输出的示例。在 EA,整个游戏公司有一个寒霜游戏引擎,刚开始是为射击类游戏创建的开发引擎,整个界面集成了很多功能,游戏开发人员通过拖拉拽的方式将需要的样式和组件拉到开发工具里,当寒霜引擎发展到 3.0 阶段时,EA 的大部分游戏都是通过该平台开发的,这就相当于游戏公司的技术中台,这样的例子在硅谷还有很多,这就是我们今天直播要分享的内容。
当然,我们首先需要了解数据中台的概念,简单来说,数据中台构建在大数据平台之上,重点强调数据能力的抽象、共享和复用,其目的是通过数字驱动公司业务,当然关于此的理解有很多,我这里不再赘述,主要分享今天的主要内容——EA 的数据中台建设。
EA 的数据中台建设
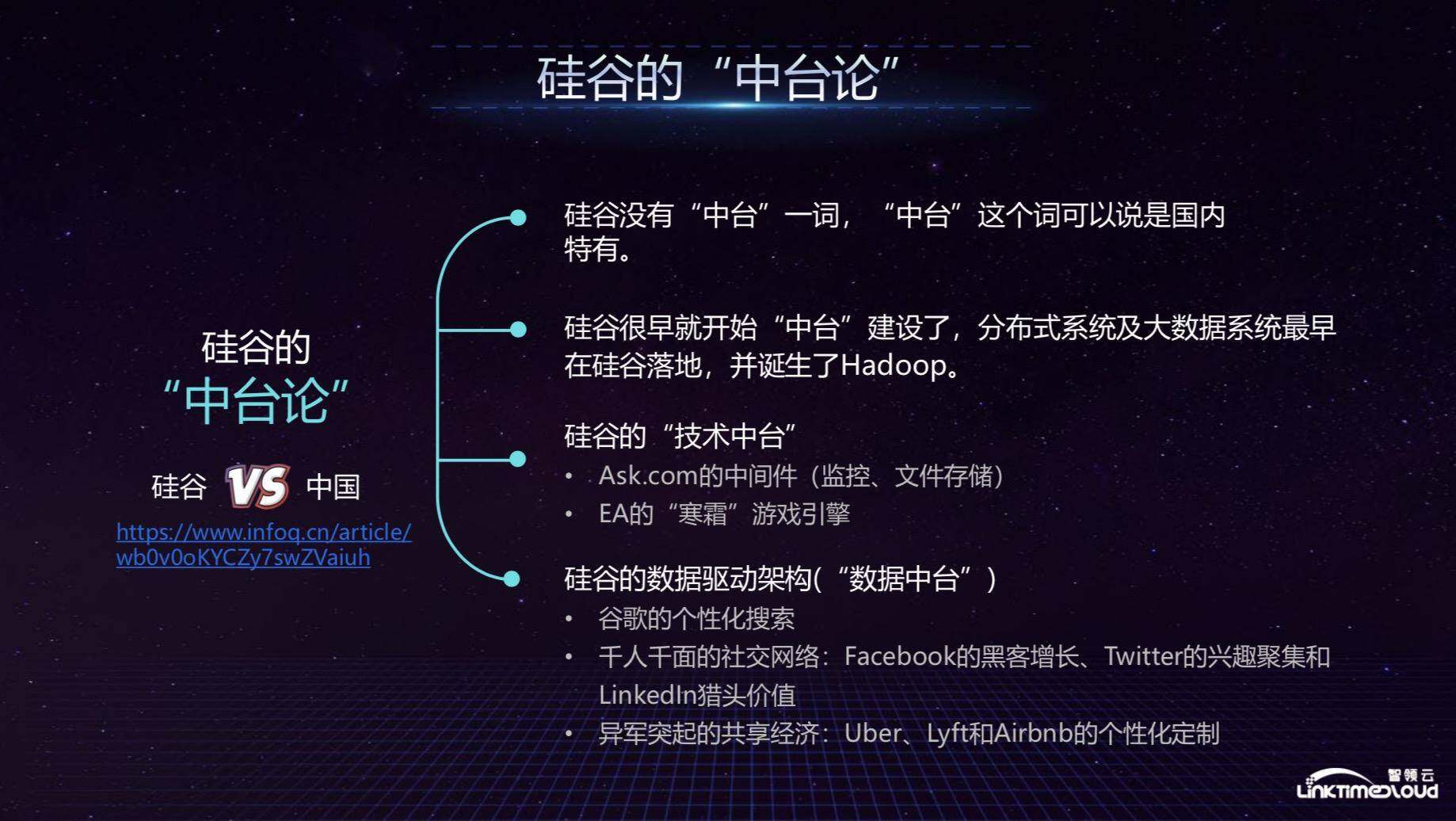
先为大家介绍 EA 的游戏家族,如下图,EA 的游戏分为几大类:第一类是体育,比较有名的包括 FIFA 足球游戏、MADDEN 橄榄球游戏以及 NBA 游戏等;第二类是射击,比如 BATTLEFRONT;第三类是社交类的游戏,类似 SIMS4。
在 Moblie 方面,手机游戏比较有名的比如植物大战僵尸,很多人应该都玩过,还有 RealRacing,在某一年 iPhone 手机的发布会上将 RealRacing 作为展示 iPhone 手机强大硬件功能的游戏。
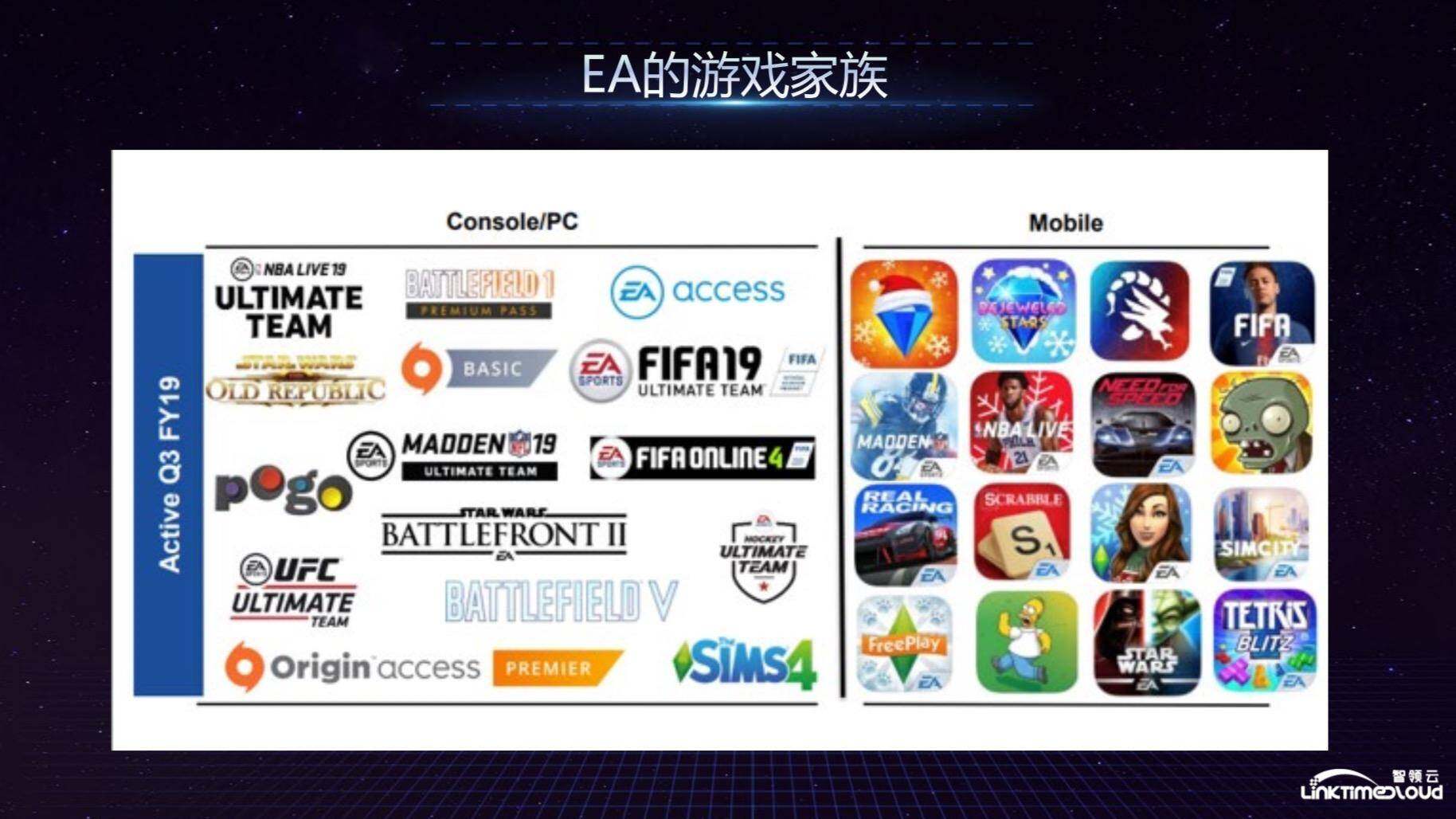
EA 的大数据部门成立于 2012 年,下图展示了游戏玩家玩游戏的过程中在数据层面发生的变化,从左边往右边看,首先需要通过 Facebook 或者电子邮件获取玩家信息,通过数据来发现潜在玩家,包括 Push Notification 通知玩家来邀请他进入游戏,进入游戏以后,数据发挥重要价值的地方就是应用内的广告显示,包括 In-game Banner,会有一些个性化在里面,最后就是玩家的体验,包括游戏体验、客服体验等,这是整个 EA 后台数据发挥作用的地方。
那么,我们接下来看 EA 的游戏数据,以 FIFA 为例,FIFA 在 2019 财年拥有 4 千 5 百万 Unqiue player,这些玩家 90 分钟可完成将近 50 万场比赛,300 多万脚射门,考虑到 EA 有将近一百个游戏,这些游戏总和加起来的数据量还是很大的。

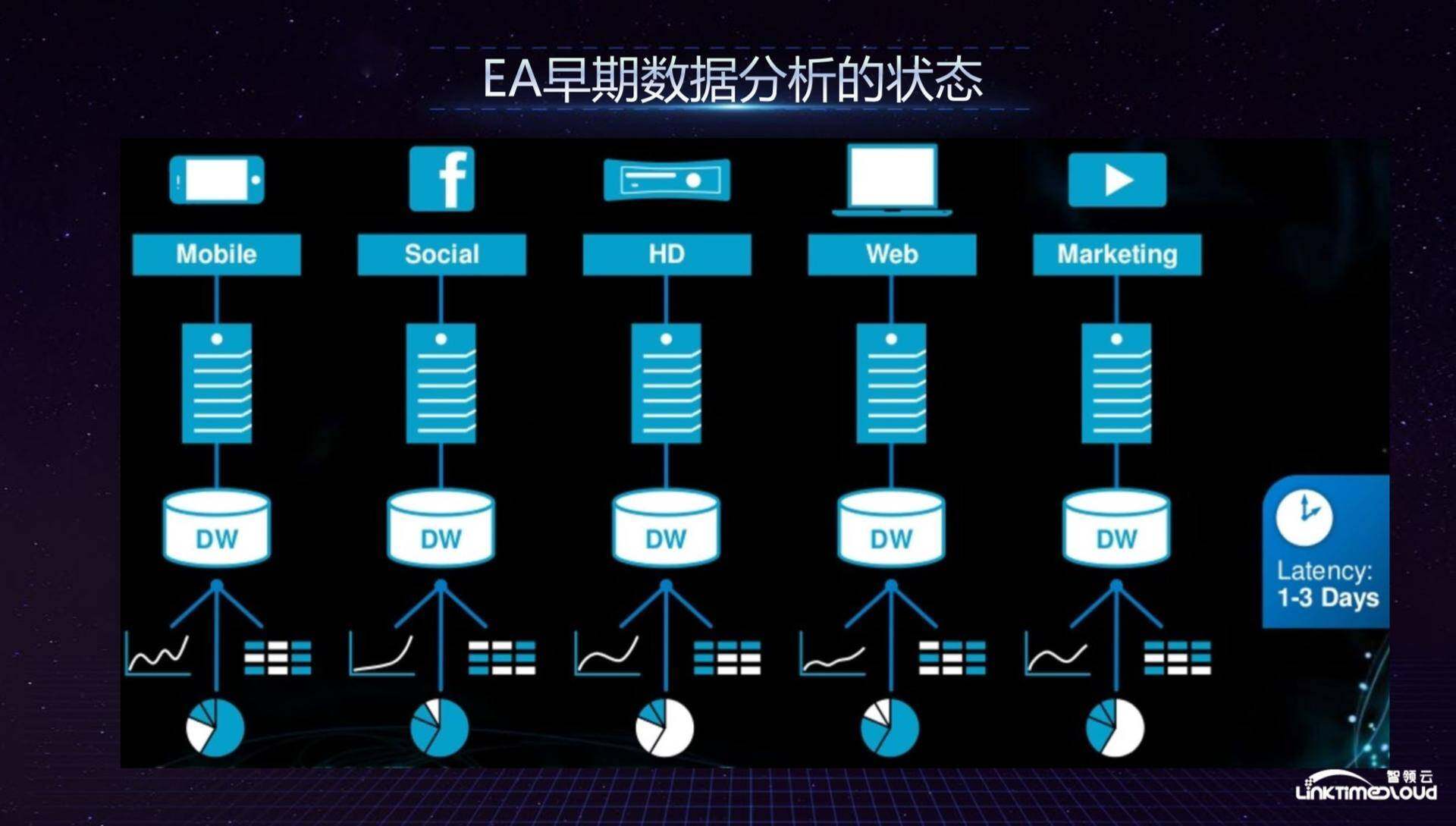
面对这么庞大的数据量,EA 早期的数据分析是怎么做的呢?EA 的特点是很多游戏工作室分布在全国各地,且大部分是收购而来,那么每个游戏工作室按业务部门就会在早期形成自己的烟囱式数据分析管道,每个游戏都有一套数据分析流水线,这就导致数据延迟较大,如果希望得到整个公司的数据全貌需要花费两到三天的时间才能梳理出来,因为要到各个烟囱里面收集数据,这就导致在 2012 年的时候,整个 EA 的游戏体验不是特别好,游戏发布经常出现宕机,客服也很糟糕,当年的美国消费者杂志将其评为最差劲的公司之一,这促使 EA 的领导层决心改变现状,开始成立数字平台部门,我就在那个时候加入 EA,从 0 到 1 打造整个数据平台。
2014 年到 2015 年,EA 的数字平台初步形成,各游戏工作室及业务部门的数据均通过统一的数据管道进入以 Hadoop 为基础的大数据平台,有了统一的数据仓库、服务和算法来支撑业务部门分析、推荐及报表等诉求,此时的数据延迟从两到三天缩短为几个小时。
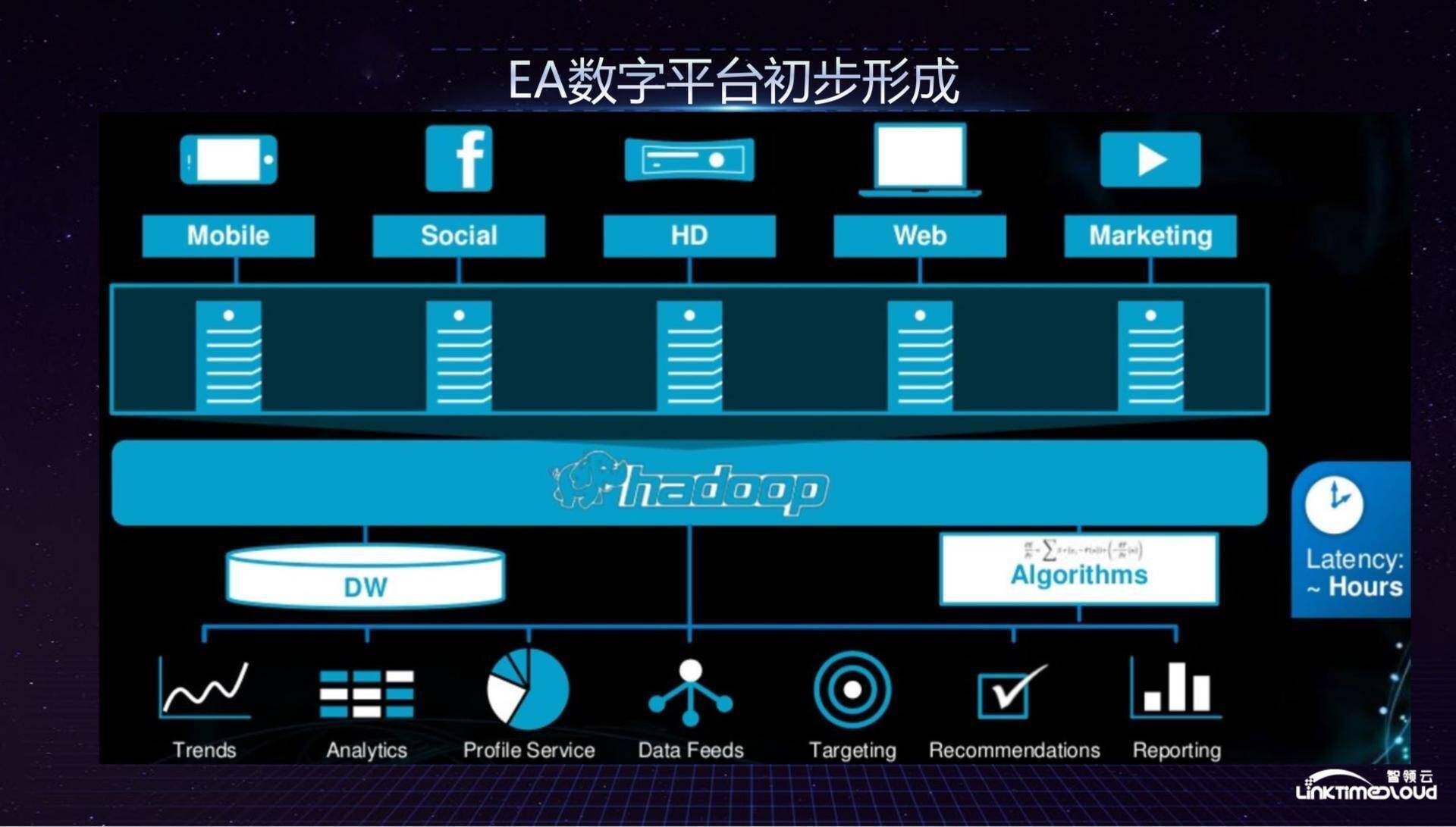
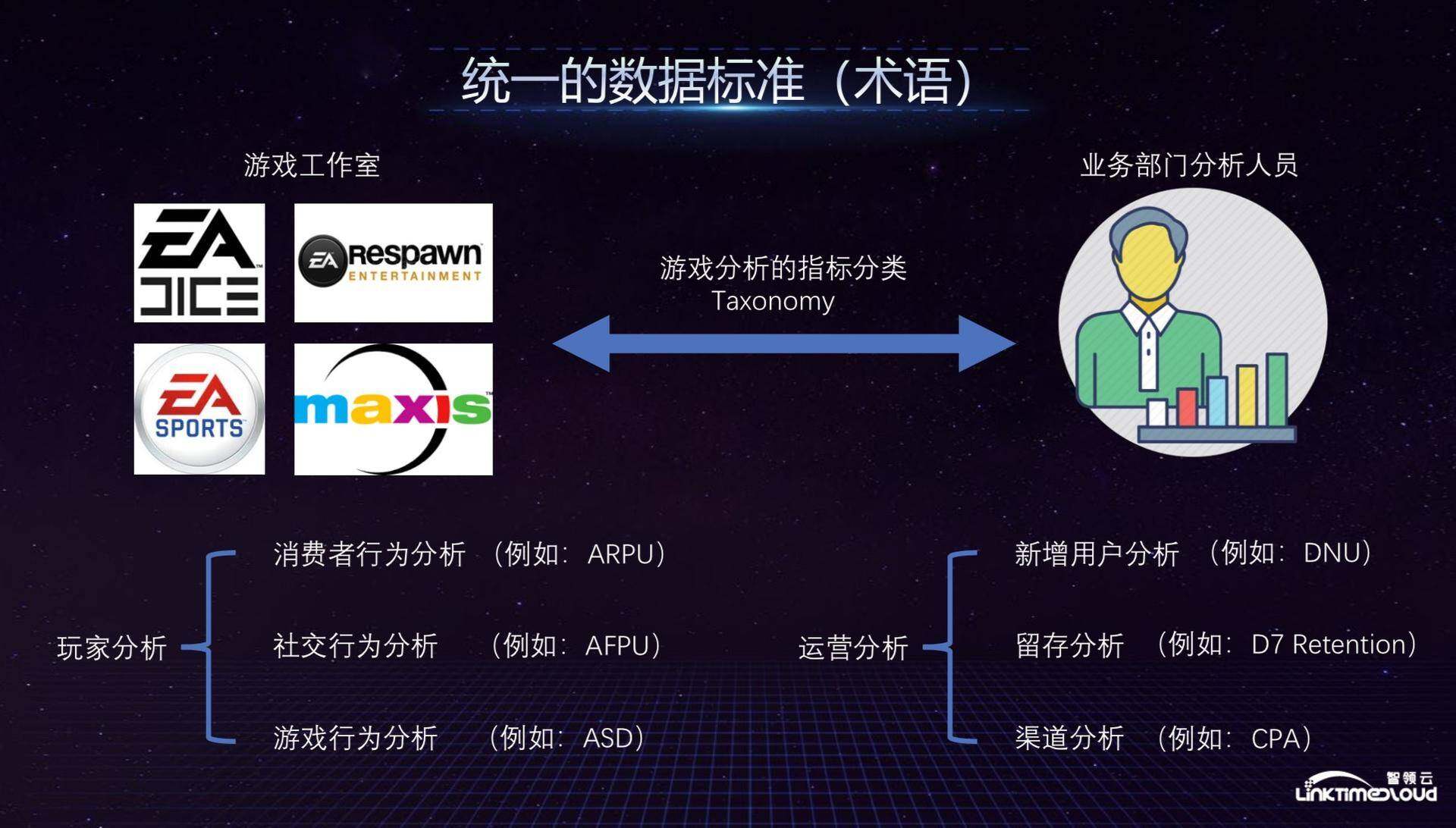
具体来说,大数据部门当时做的第一件事情是在全公司建立统一的数据标准和数据规范,不管是哪个游戏公司和业务部门都用同一套语言来讲同一件事情,我们建立了游戏分析的指标分类 Taxonomy,以玩家分析为例,其需要统一的数据有玩家的消费行为分析、社交行为分析以及游戏行为分析,比如平均游戏时长等指标。在运营分析层面,新增用户分析、留存分析和渠道分析也需要进行统一。
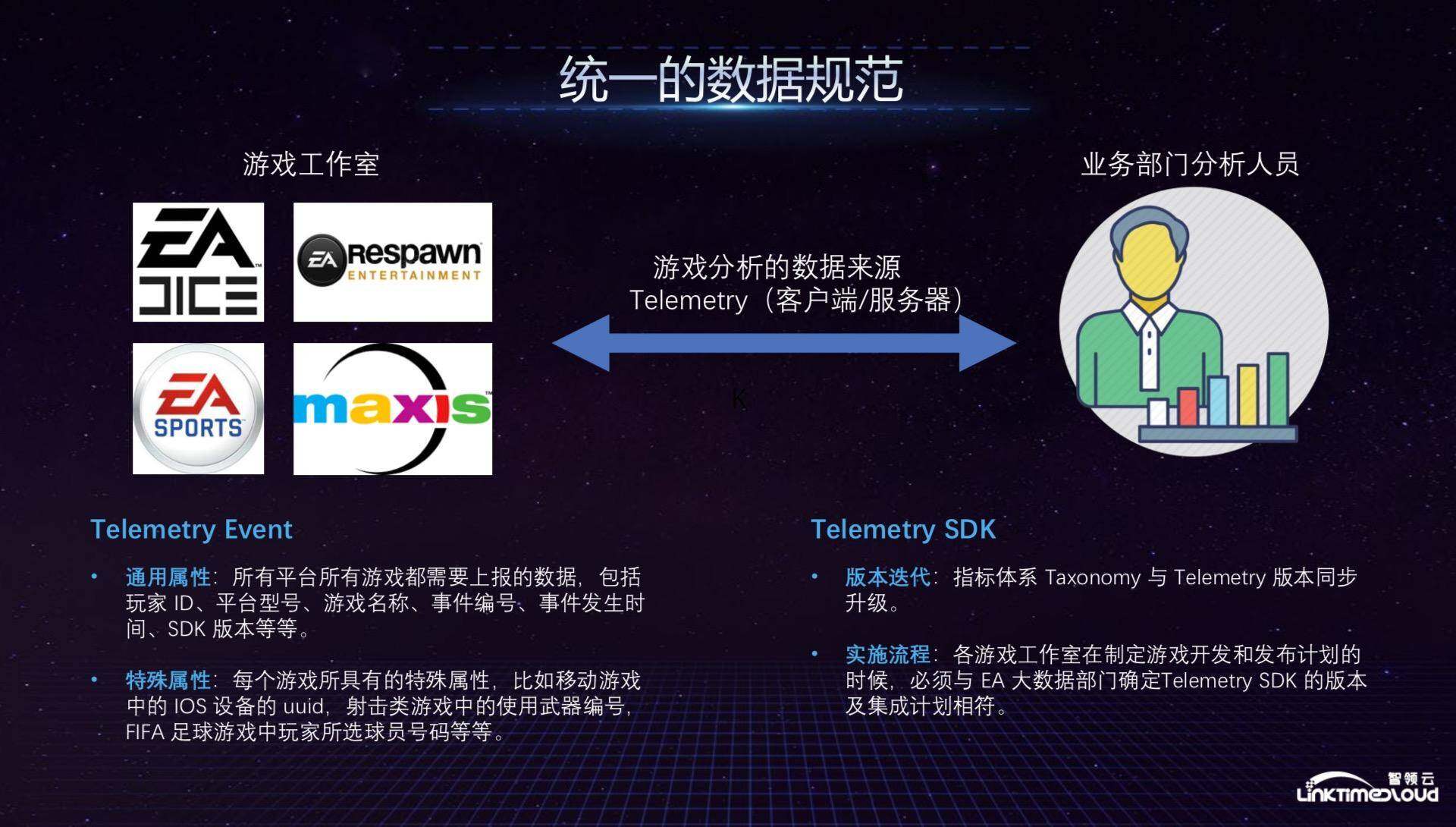
在数据标准统一之后,我们开始建立统一的数据规范,那么,数据规范是什么意思?游戏分析数据从客户端以及服务器发送到我们的大数据平台,看似对数据进行统一管理进而消除了烟囱,但实际上由于不同部门的数据格式不尽相同,数据本身并未统一。我们建立了统一的数据来源 Telemetry,将客户端和服务器端发送的数据定义为一个事件,也就是下图提到的 Telemetry Evnet,我们定义了事件的两类属性,一类是通用属性,所有平台游戏都要上报数据,包括玩家 ID、游戏运行设备、游戏名称、事件编号、事件时间等,在定义了数据规范后,所有数据就可以很方便的统计,并计算一些公司需要的共性指标,比如日活、月活等;另一类是特殊属性,根据不同的业务也会有一些特殊属性,整个过程只需要将 Telemetry SDK 植入游戏客户端即可完成。
在完成如上两个步骤之后,就可以具体聊聊数据中台的建设。首先,数据中台的建设肯定以业务为驱动,我们做数据中台是希望以数字化的方式来驱动业务发展,比如支持游戏设计和开发、支撑游戏在线服务、支持游戏的市场部门、支持玩家获取游戏广告推送等,这是整个数据中台的发展方向,建设步骤如下图所示。
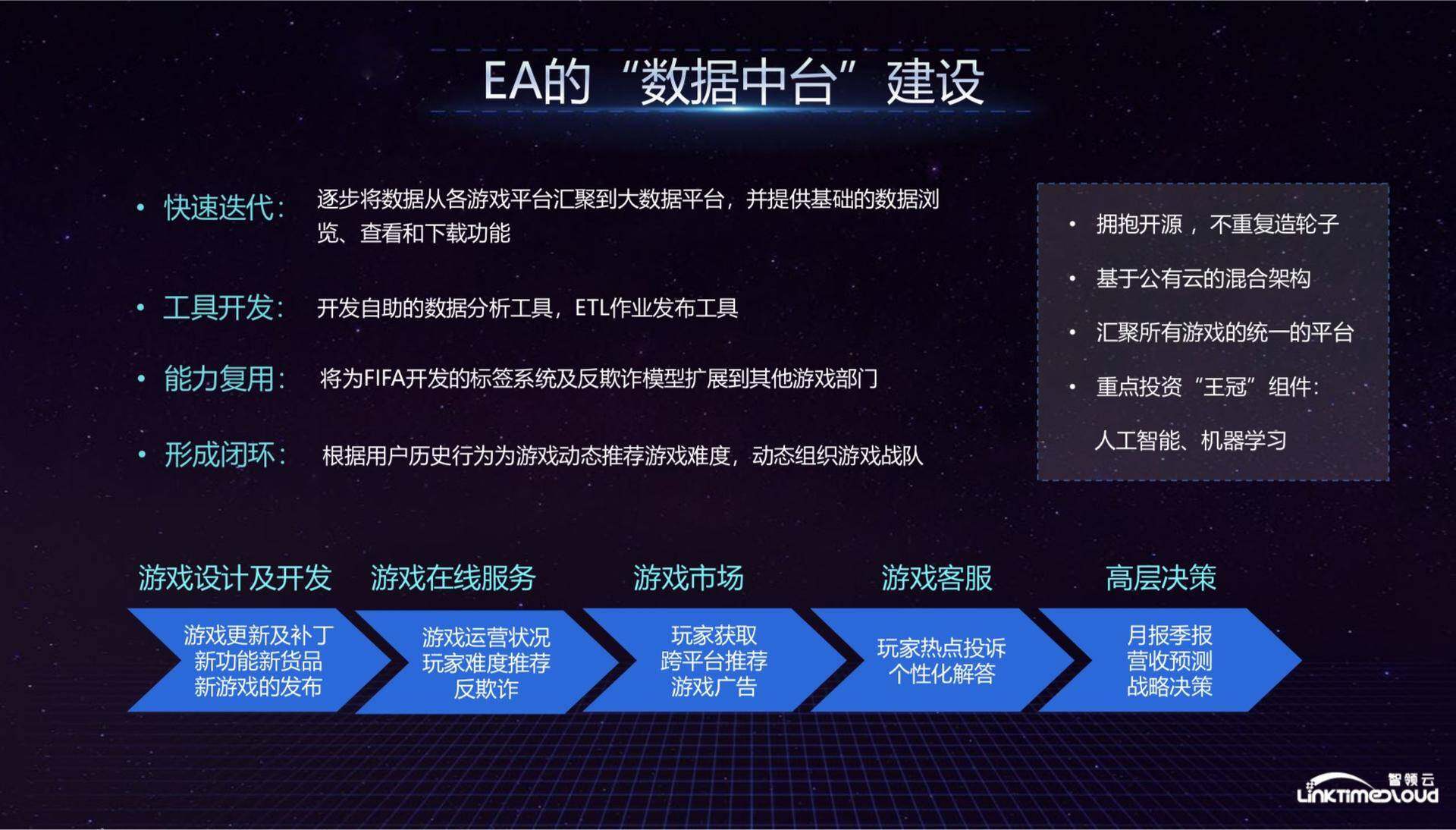
起初,我们的大数据平台采用了快速迭代的方式,逐步将数据从各游戏平台汇聚到大数据平台,并提供基础的数据浏览、查看和下载功能,因为数据中台的建设投资是巨大的,所以一定要快速见效,这又是一个需要长期投入的过程,如果短期内没有任何效果,参与其中的大数据部门、业务部门,甚至公司高层都会对后续建设缺乏信心,因此我们选择了快速迭代的方式,短期就可以看到初步成效,但这个数据中台的功能非常初级,效果是将从各游戏部门拉数据变成了从统一的平台拉数据。
第二步进入工具开发阶段,我们开发了一些自助分析工具,业务部门可以自主进行数据分析,他们的日常工作由原来的 Excel 换到了统一的大数据平台上,这个阶段让业务部门能够把数据用起来。
第三步是能力复用,以当时 EA 营收的主要贡献者 FIFA 为例,我们开发了标签系统可以让 FIFA 快速地从几千万玩家中迅速锁定地区、年龄、日均游戏时长符合要求的玩家,并针对性地进行游戏推广、推送打折券等优惠活动,以促进更多营收。类似的,我们也建立了反欺诈模型,对于一些积攒游戏币再高价售卖的玩家会有查封账号等处罚,这些能力都是可以复用的。
第四步是形成闭环,就是把从游戏中获取的数据形成服务再反馈给游戏,最简单的是将用户的游戏行为反馈给游戏动态推荐的同学,可以优化推荐结果。
总结下来,首先,我们基本每个季度都会推出一些新功能,逐步让游戏可以更好运行下去,各业务部门能够在每个季度都用到一些新功能,并感受到数据中台的建设效果;其次,需要开发一些自助工具,让业务部门能够自助分析数据;然后,尽可能将为某个业务部门开发的功能抽象出来进行能力服用;最后,形成数据闭环反馈给业务,对业务有所促进。
在建设过程中,我们也有一些原则,这些基本是硅谷的科技公司建设数据中台都在采用的:一是拥抱开源,不重复造轮子,比如大数据平台基本都基于 Hadoop 生态;二是基于公有云的混合架构,游戏服务器部署在私有云,但数据中台部署在 AWS 的公有云上面,两者打通可以快速扩展数据中台的规模;三是汇聚所有游戏的统一平台,对 EA 这样一个每年要发布数十款游戏的公司而言,要做到这一项的难点并不全在于技术,而在于说服每个业务部门用统一的平台来支撑他们的业务;四是要重点投资“王冠”组件,数据中台最终能够产生的价值一定是数据收集起来后经过处理、分析和人工智能机器学习算法让他在业务中产生更大的价值,这是整个平台的重点。接下来,我们重点介绍技术层面的内容。
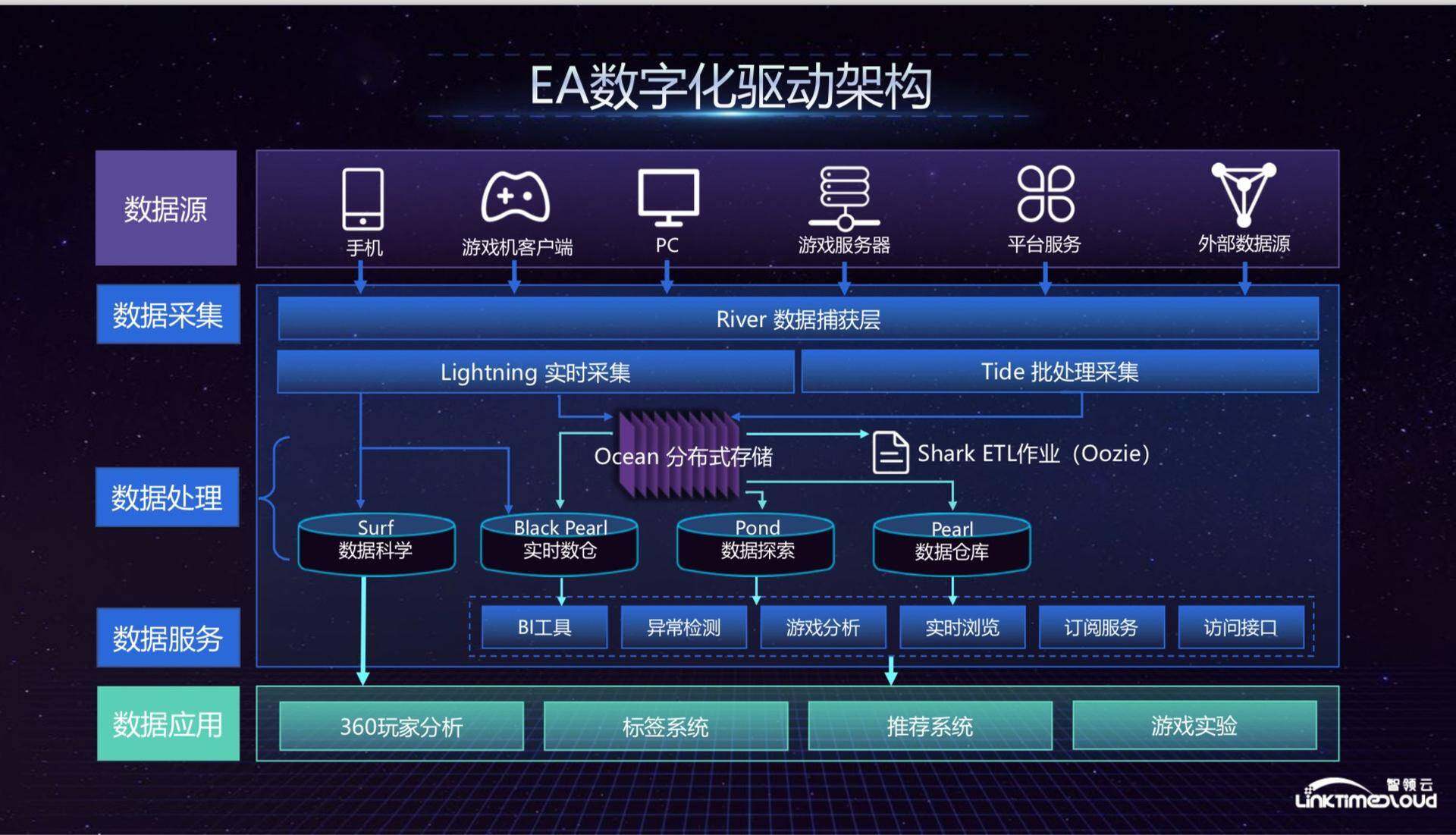
如上是 EA 的数字化驱动架构,最上面是 EA 的数据来源,包括手机、游戏机客户端、PC 等渠道,这些数据通过我们定义的 Telemetry 数据格式发送到数据采集层,也就是数据捕获层 River,数据采集分为两部分:Lightning 实时采集和 Tide 批处理采集,后面会详细介绍这两者的架构,采集过后的数据进入 Ocean 分布式存储,分布式存储又分为两部分:基于 HDFS 的分布式文件存储系统和 AWS S3 的面向对象存储,这里其实牵扯到冷热存储的问题,因为 S3 比较便宜,所以存储比较老的数据,HDFS 主要存储比较新的业务数据。在数据处理这一层,与 Ocean 匹配的 ETL 工作流是 Shark,不停的吞吐大量数据,我们当时对 Onzie 进行了一些改造,将其作为工作流管理工具。数据处理再往下就是数据仓库,存储了一些实时玩家数据,主要用在数据科学领域,比如推荐算法等,我们的实时数据仓库基于 Couchbase 建立,Pond 是自助数据探索工具,我们的一些生产数据会从 Ocean Push 到 Pond 这一端,Pond 也可以直接对 S3 读取面向对象存储数据进行查询,Pond 也是各业务部门运行作业的小集群,每天支撑了四五百个作业,再往后就是 Pearl 数据仓库,这是一个传统的数据仓库,我们刚开始用的是 Tide,后来因为 Tide 开销太大,我们就转移到 AWS 的 Redshift 数据仓库,可以给传统的 PI 工具提供支撑,数据仓库这一层也为下面的数据服务提供支撑。
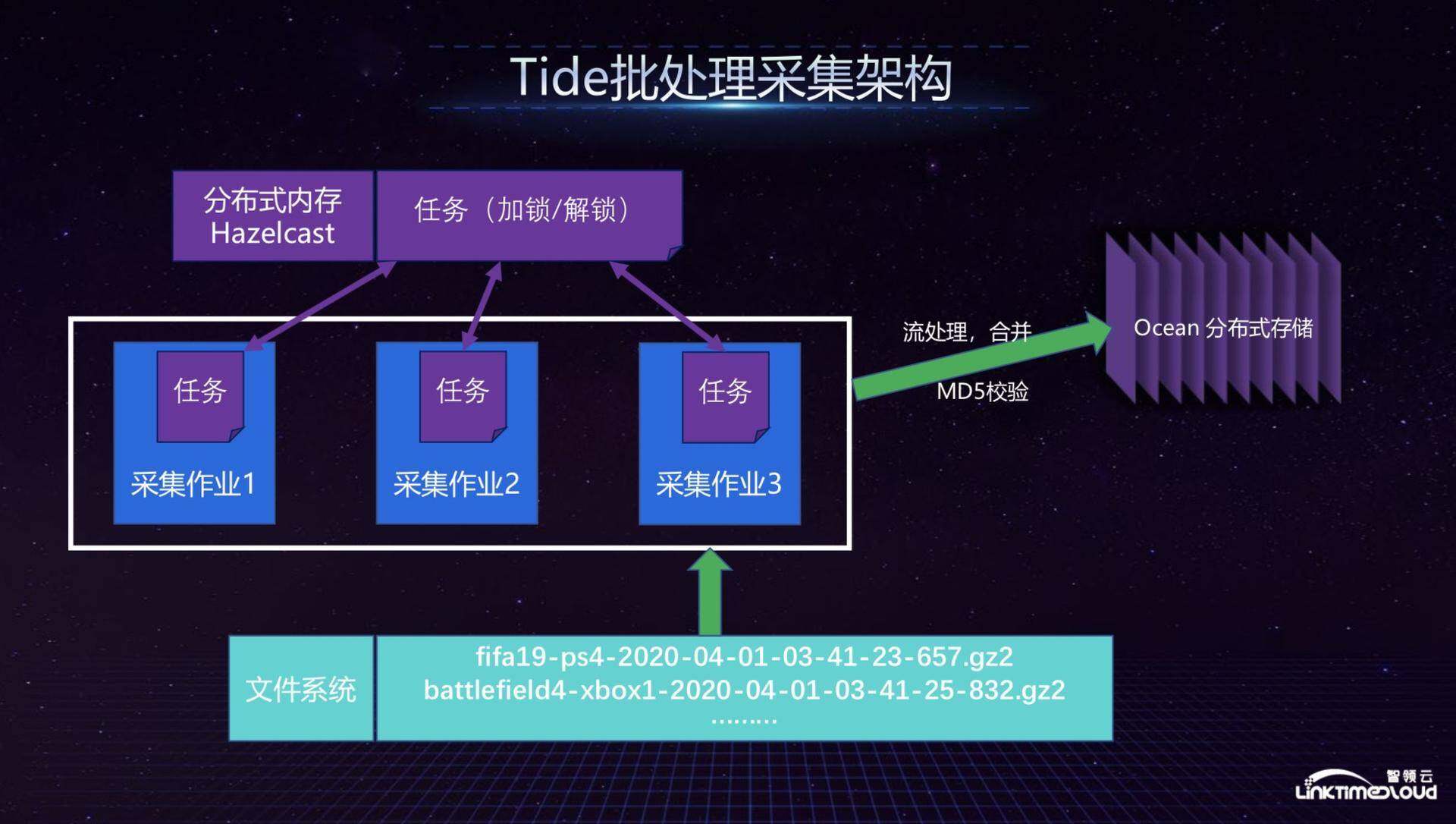
接下来为大家具体介绍 Tide 批处理采集架构,因为整个批处理文件存放了从游戏服务器送过来的大量数据,由于当时业界没有特别合适的分布式系统,所以我们自己构建了一个分布式采集系统,解决的问题就是每个任务能够自主到文件系统里面拉取想要处理的文件。那么,如何保证不同任务之间互不冲突呢?我们通过任务锁的方式来实现,任务锁通过 Hazelcast 分布式内存启动,如果对某一个文件加锁,那么其他任务是拿不到的。在文件流处理部分,我们将采集上来的文件归为不同的文件流合并处理,然后发布到 Ocean,当时没有选择 Flume,是因为 Flume 当时刚出来,我们又有太多定制化需求,因为我们不仅要把文件进行合并,还有很多小文件放在 Hazelcast 上面,会严重影响性能。如果按照现在的技术,我们可能会采用一些更新的系统来做整个事情。
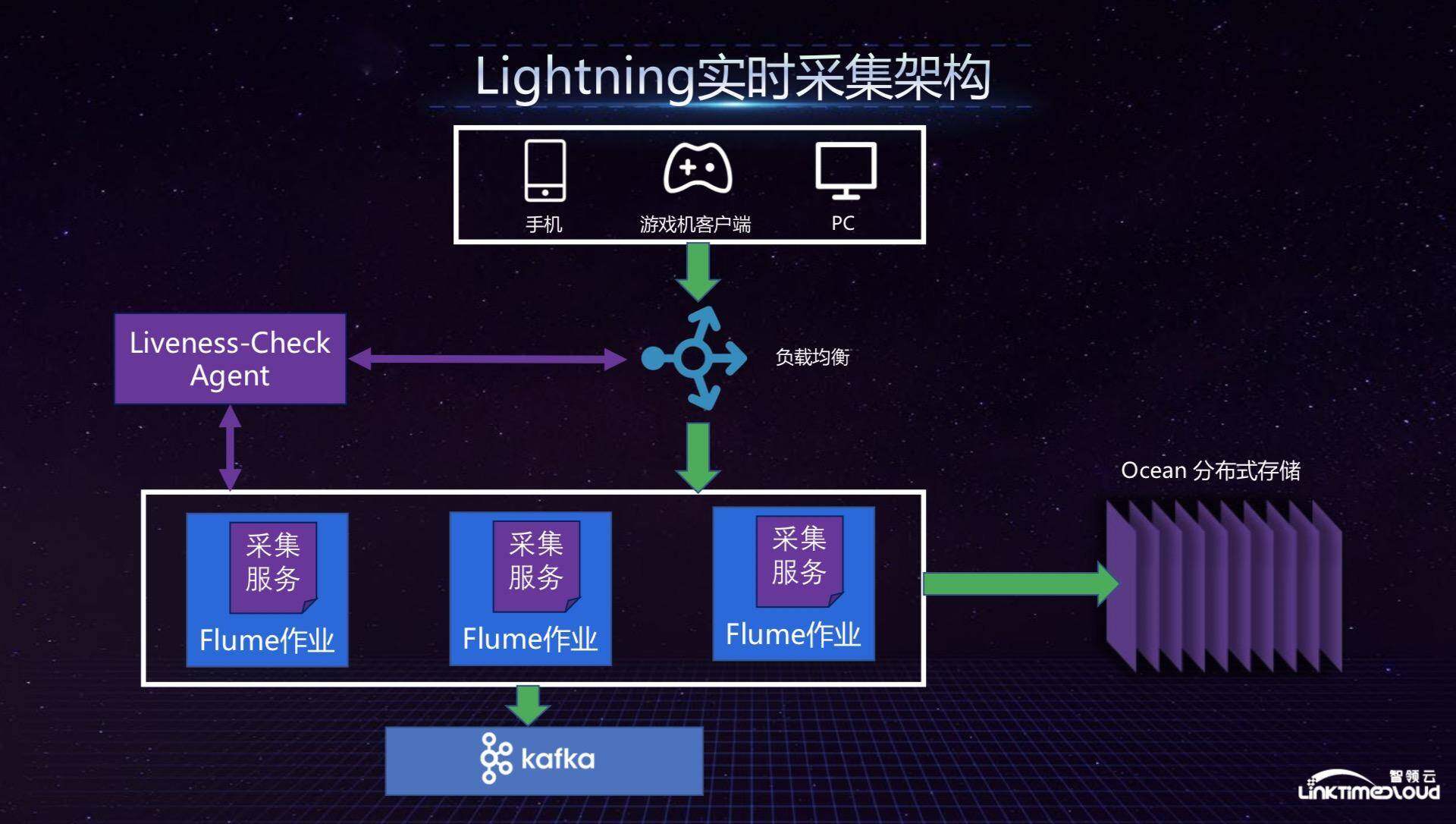
在实时采集服务部分,我们有一个整体检查采集节点是否工作的设置,我们叫 Liveness-Check,如果有一个节点不工作,它会通知负载均衡拿掉,如果生成一个新的采集服务,它会把这个节点加到负载均衡里面,也就是动态调整负载均衡,保证服务的高可用。在这套架构中,我们使用了 Flume 服务,因为文件的方式比较直接,Flume 作业一份发送到 Oceam 里面做备份,另外一份发送到 Kafka 集群,这里面更多的考虑是容错,就是在采集服务节点挂掉以后,如何保证数据不丢失,一方面是通过 Ocean 进行备份,另一方面是在这个挂掉之后把它切断,使数据不被破坏。
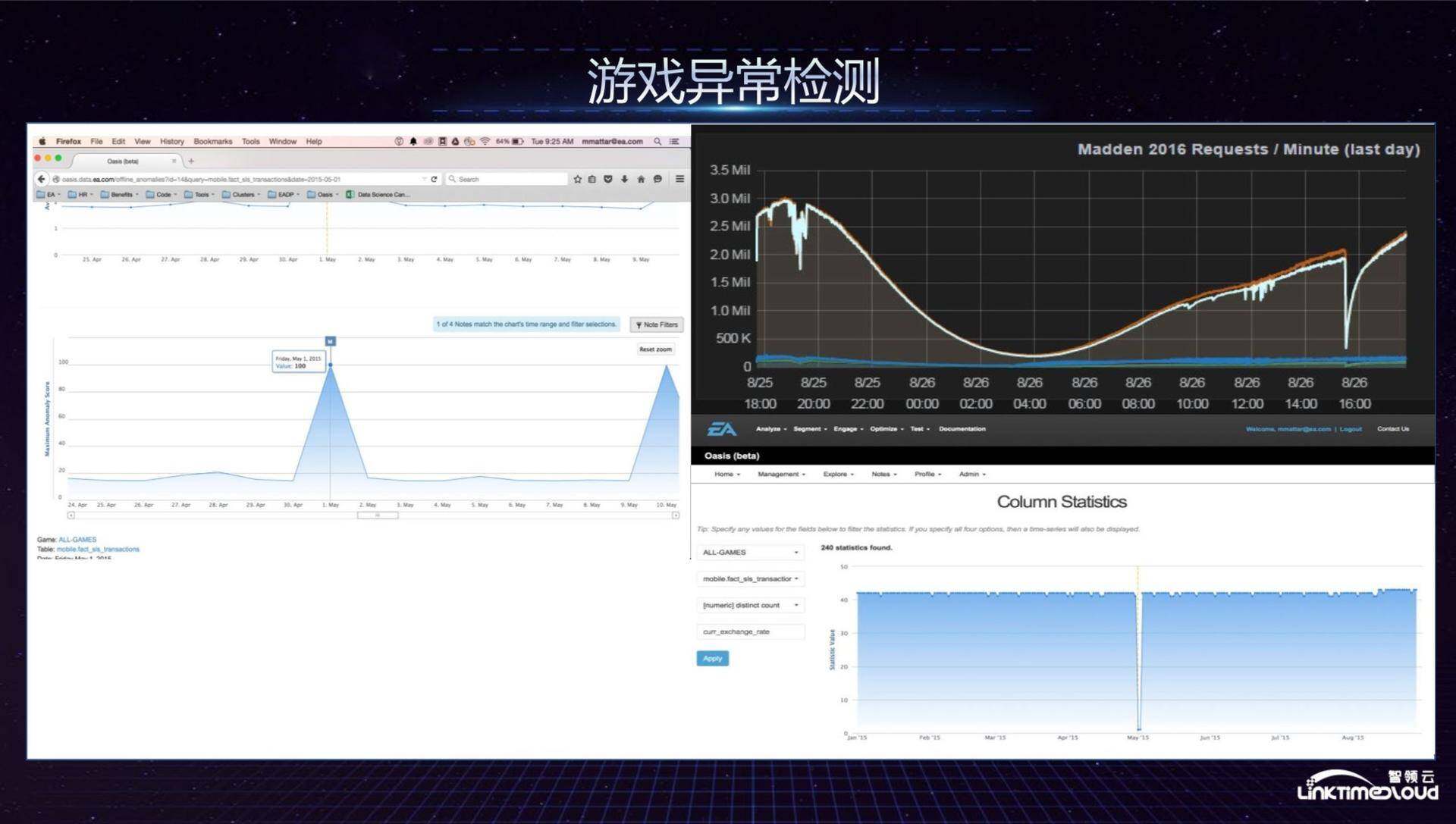
至于游戏的异常检测,我们主要完成了自动配置游戏指标检测,EA 的游戏有上百个,每年发布新游戏或版本的同时还需要维护历史版本,游戏指标体系里有接近上万个指标,所以异常检测必须智能化,而不是每一个指标都手工配置。此外,我们通过拉取历史数据进行机器学习建模来分析异常情况。
接下来重点介绍游戏的推荐系统,也就是数据中台的第四个部分,最终形成数据闭环的部分。EA 的游戏推荐系统作为典型的数据能力首先请求从游戏客户端和服务器端向推荐系统发出,但在之前有一个建模的过程,这个过程是客户端和服务器的数据都会发送到数据仓库,数据仓库将数据发送到模型及服务板块,当然这个模块也会存储一些代码,因为 EA 不仅能够支撑各种系统,比如推荐系统,也可以支撑异常检测和反欺诈等,这其中的模型和代码都可以复用到其他部门。
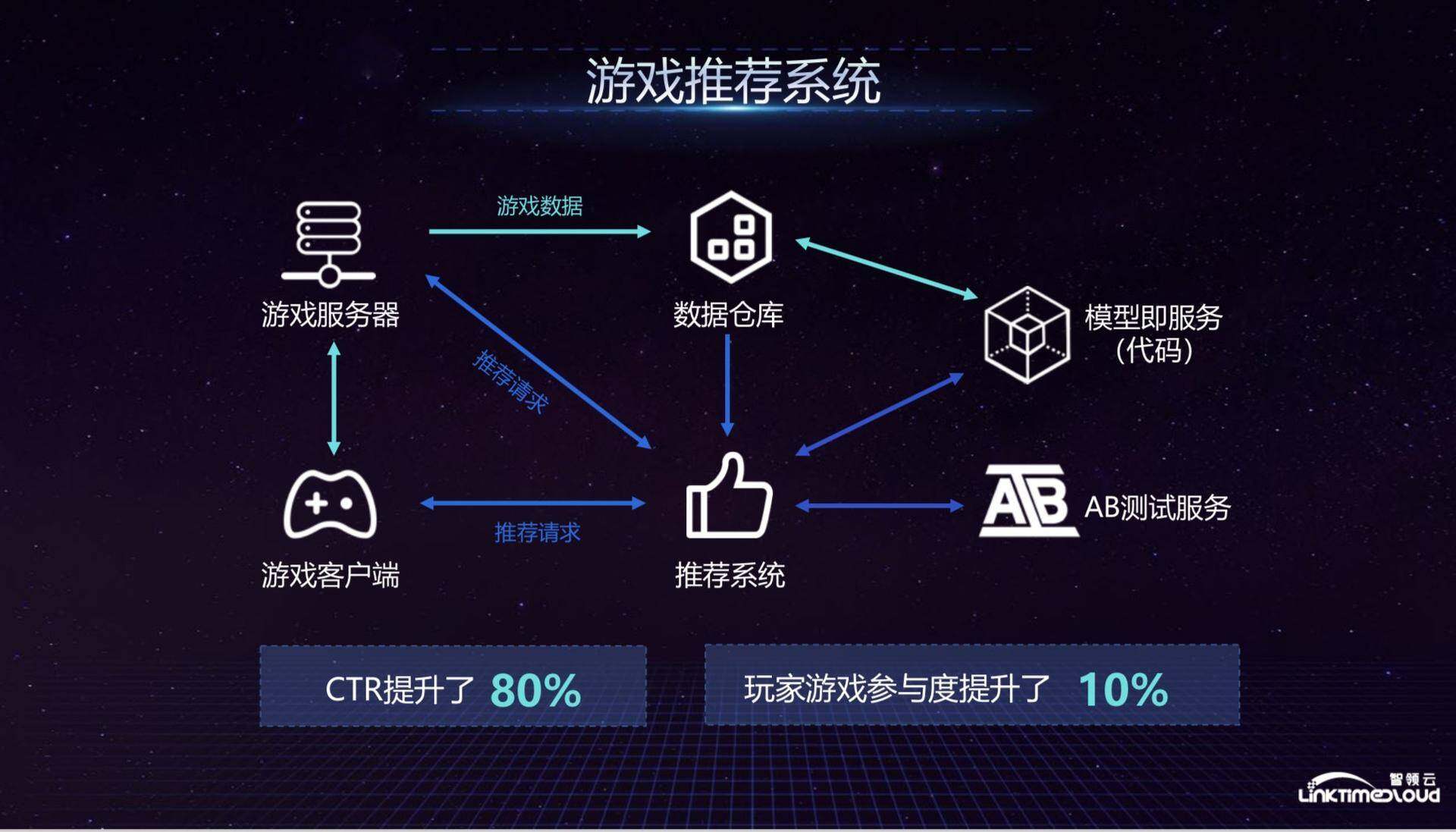
那么在整个推荐系统里面,推荐系统会拉取数据仓库最近 24 小时的数据,然后结合向模型及服务发出请求,模型及服务根据这些参数进行计算来匹配并将结果返回到推荐系统,推荐系统又会把结果返回给客户端以及服务器端,形成整个推荐机制。
整个后台还有一个比较重要的部分就是 AB 测试,推荐系统可以根据推荐请求的不同性质(生产环境还是测试环境)发送到不同的服务器上,后续会跟后面的一系列推荐请求数据进行捆绑来评价整个结果是不是符合预期,EA 推荐系统的逻辑大致如此,整个系统上线后对业务的推动作用还是很明显的,比如广告点击率提升了 80%,游戏玩家的参与度提升了 10%等。
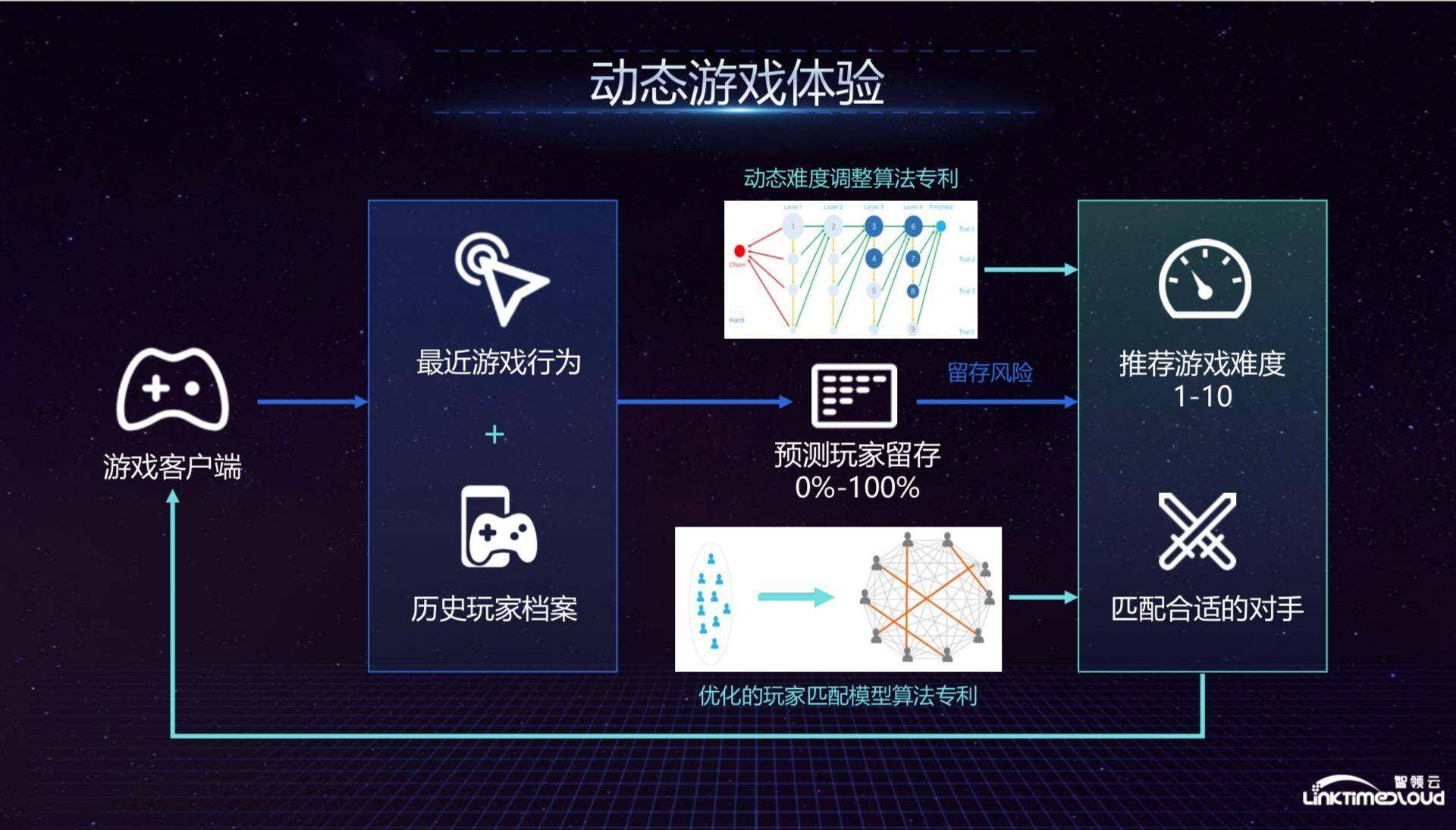
硅谷独角兽如何建设“数据中台”?
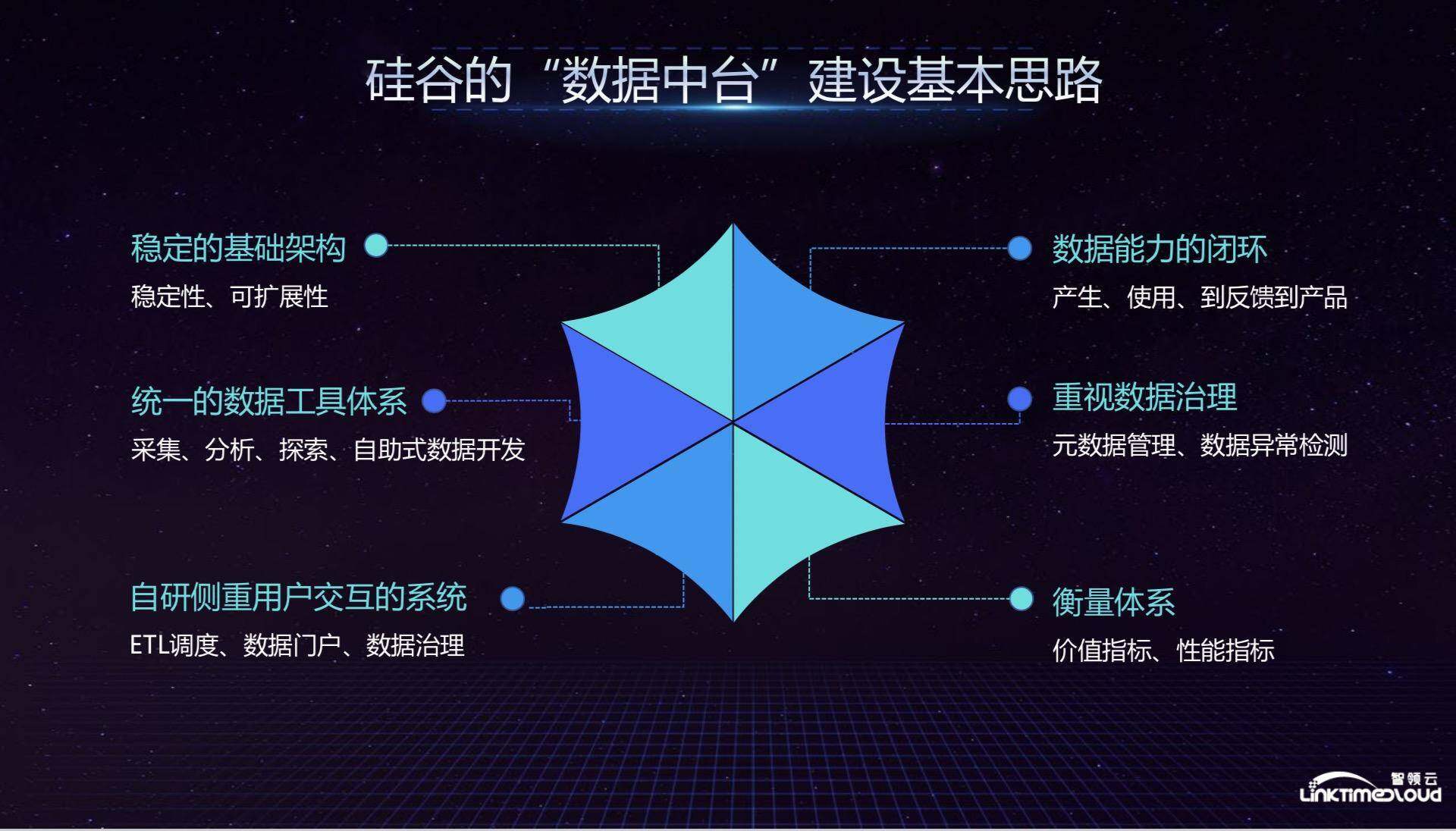
硅谷的其他独角兽建设数据中台的思路基本与上述类似,首先需要有一个稳定的基础架构,基本都基于 Hadoop 生态系统打造,然后加入自研的基础组件,使用统一的数据工具来进行管理和开发;在自研部分,重点是侧重用户交互的系统,其目的是希望能够让各业务部门自助使用系统进行数据能力的开发,包括 ETL 调度、数据门户和数据治理等功能;强调数据能力的闭环,也就是大量数据回馈到产品中,并对业务有较大提升;重视数据治理,元数据管理和数据异常检测;衡量体系,因为数据中台建设是一个投入很大的系统,需要能够衡量出哪个业务部门使用最多,哪些环节的资源消耗最多。
接下来简单介绍 Twitter 的数据中台架构,基本上与 EA 架构类似,从上往下看有 Production 节点,日志通过 Kafka 进行实时采集,也可以通过 Gizzard 批量采集到 Hadoop 里面,还有一些数据会存到 MySQL 集群里面,这些数据进来以后会进入到自己生产环境的 Hadoop 集群中,通过 Nighthawk 可以让业务部门自助使用集群,Twitter 还有数据仓库 Vertica 可以为分析师、工程师和产品经理提供支撑,对用 BI 工具来看的数据,MySQL 也会存储一些,也会作为数据仓库的一部分提供这样的功能。
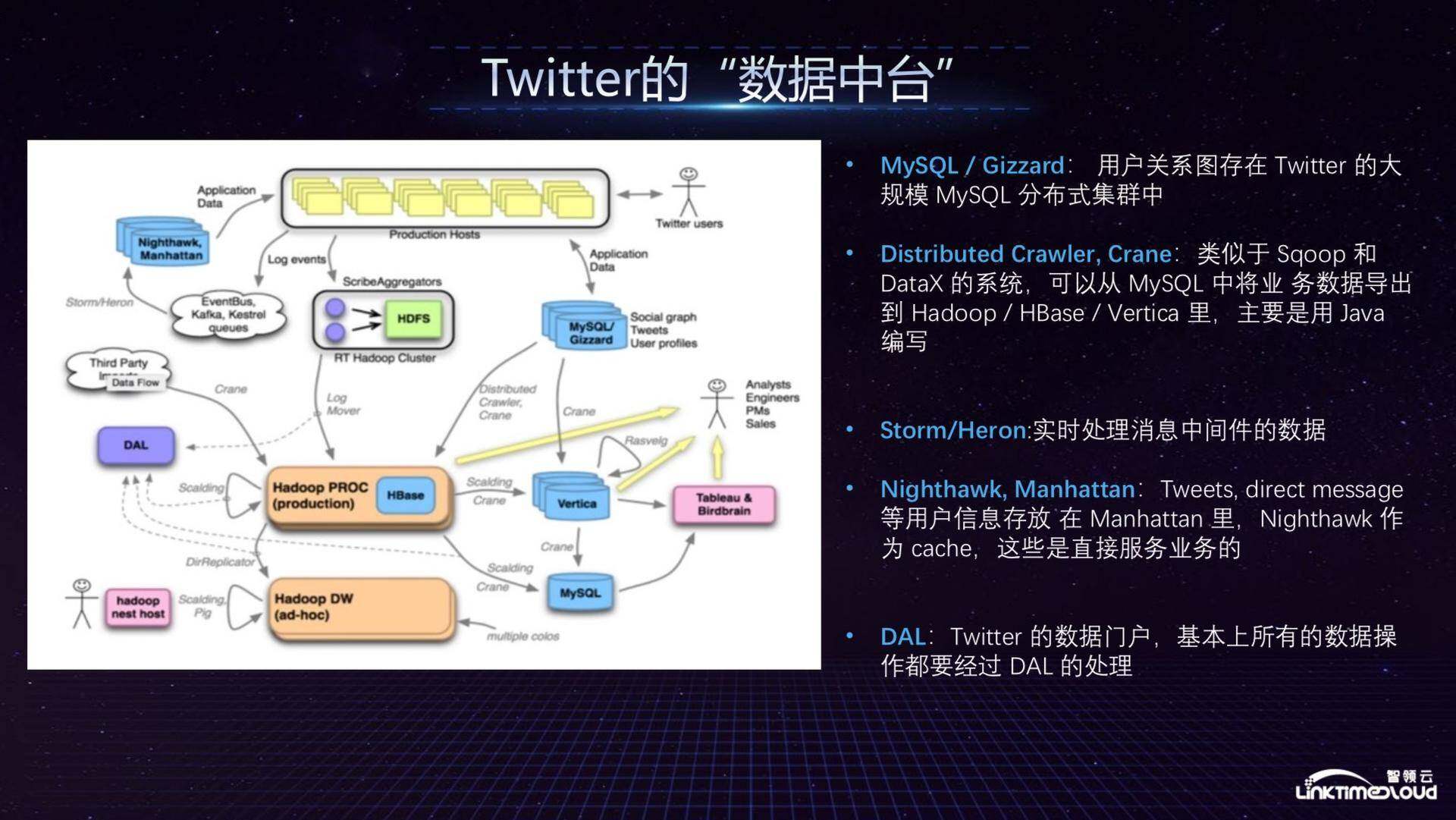
从技术上来讲,重点介绍 MySQL/Gizzard,这是 Twitter 用来存储用户关系图的;Crane 分布式采集器类似于 Sqoop 和 DataX 的系统,可以从 MySQL 中将业务数据导入到各种数据仓库里面,这也是 Twitter 早期的技术,现在可能也有些新的开源工具取代;在实时处理方面,Twitter 使用 Storm/Heron 这样的实时采集工具;Tweets、direct message 等用户信息存放在 Manhattan 里,Nighthawk 作为 cache,这些是直接服务业务的;DAL 是 Twitter 的数据门户,基本上所有的数据操作都要经过 DAL 的处理,比如说需要对特定人群做一些特定分析,就可以拿到这些数据,并在一两周内完成数据原型开发,这就是数据能力的抽象、共享和复用。Twitter 的数据中台主要是数据量也很大,对业务的支撑体现在新产品上线之前对竞品分析、用户行为分析、具体位置分析等,保证能够进行精准的广告推送,Twitter 还将部分数据服务对外开放,比如舆情/选情分析等,这些都是 Twitter 数据中台具备的能力。

接下来是 Airbnb,从左到右,整个数据从 Event logs、MySQL Dumps 通过批处理 Sqoop,流处理 kafka 进入 Gold Hive Cluster 生产集群,它有一个副本 Silver Hive Cluster,应该也类似做一些自助式查询,最后流转至 Spark 集群,数据基本存储在 S3,底层通过 Presto 集群支撑各种服务,比如业务部门的数据分析,Airpal 让业务人员能够轻松写出数据查询请求,Tableau 开源可视化工具可以让业务部门自助可视化报表分析。
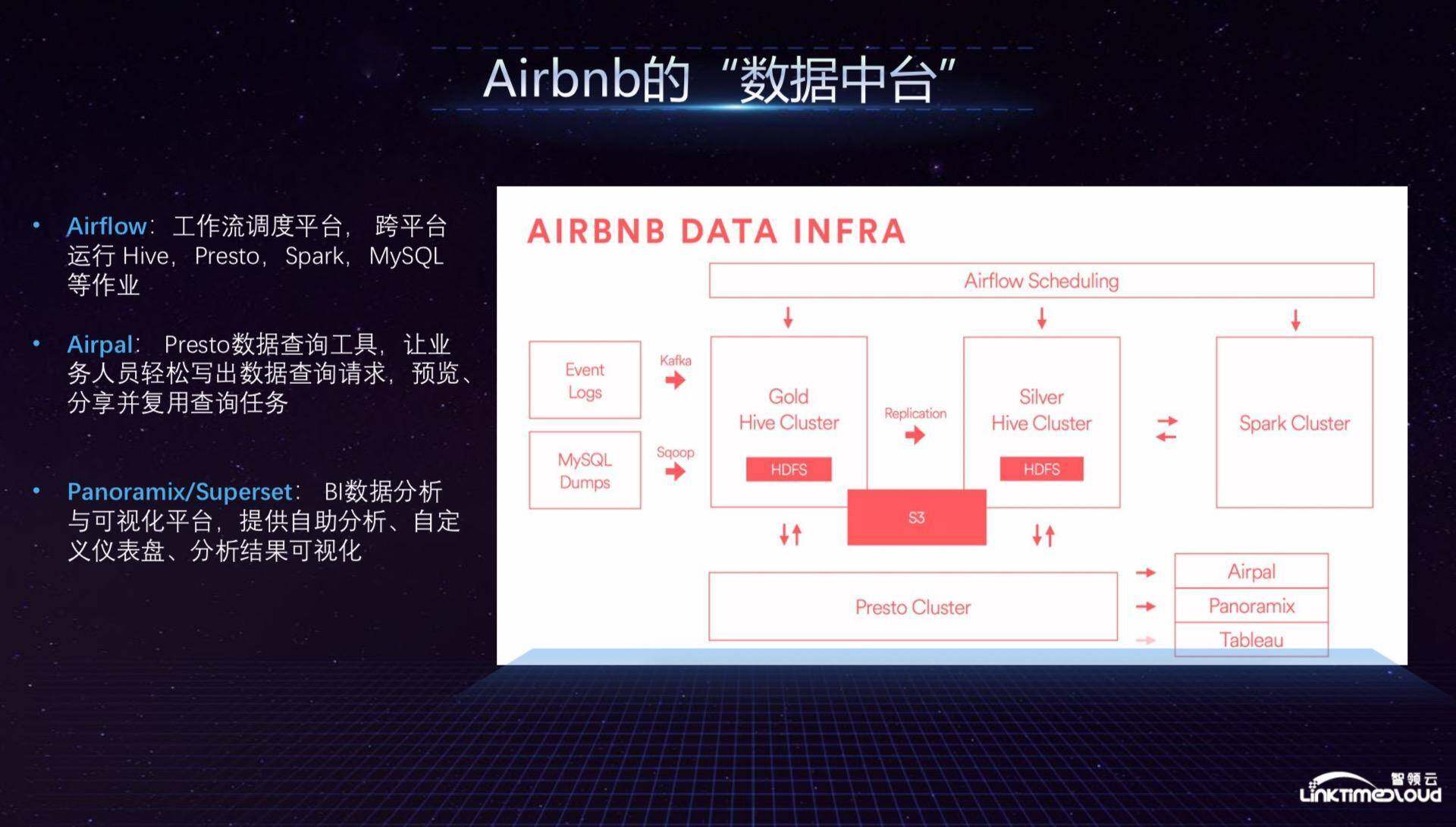
如上是 Airbnb 数据中台的架构,作为在线租赁订购平台,数据平台支撑的业务主要体现在通过人工智能算法分析用户喜爱的图像,比如用户在某一张房型图片上的停留时间较长或者对下单起决定性作用,Airbnb 会据此提醒房东展示图片的选择和陈列;通过自然语言分析评论的情感倾向,根据用户评论的正/反向判断推荐的房型;动态房租价格预测模型,根据供需数据、季节性数据及特殊事件的预测推荐房型价格;协同过滤分析房东喜好,分析房东喜好以提升下单批准率,这是 Airbnb 整个数据中台对业务的支撑。

最后,我们来看 Uber 的数据中台,Uber 的所有数据分别从 Microservices、MySQL、Schemaless 和 Cassandra 进入,其中 Cassandra 对数据实时性要求较高,数据再经由 Kafka 进入数据采集平台 Marmaray,然后进入 HDFS,其特点是利用 Hudi 在 HDFS 中做增量处理,因为在原来的 HDFS 里做增量处理是比较困难的,但是 Hudi 可以高效实现,对上经由 YARN 支撑众多生态系统,最后通过 Vertica 数据仓库把数据能力开放给业务分析人员。
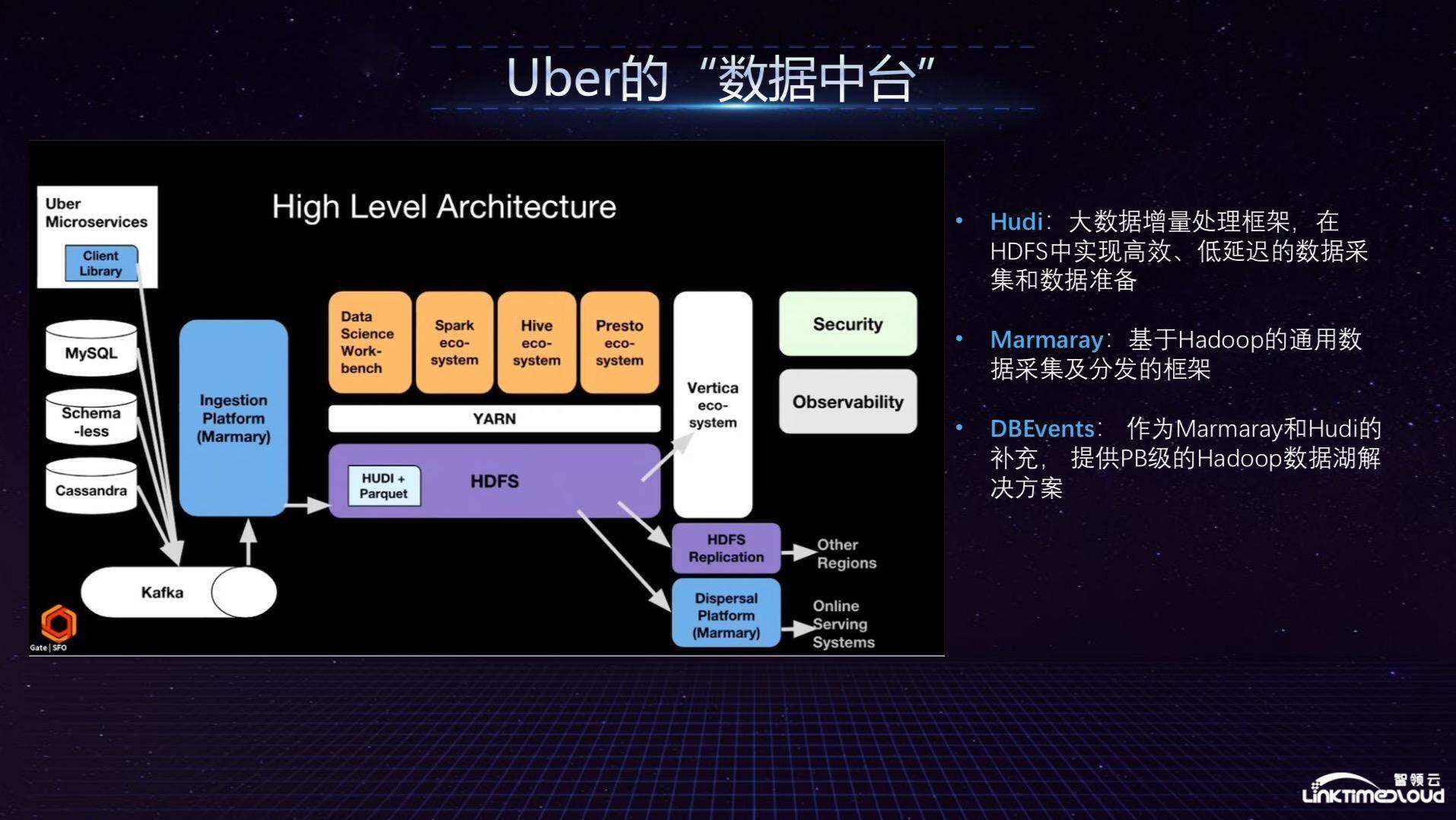
以上就是 Uber 数据中台的架构图,主要支撑了其内部动态价格调整模型,根据供需关系、短期/长期效益进行实时价格调整;提供各种预测模型,向司机提示搭乘需求高发点、对集群资源预测以降低开销;大规模实时数据可视化,为城市运营人员提供决策依据;提供数据模型训练自动驾驶,模拟城市车辆、行人移动情况,各交通路口的真实状况。

综上抽取了几点比较有代表性的内容,Uber 本身在做自动驾驶业务,所以也会使用数据来训练自动驾驶,这是整个 Uber 数据中台架构对业务的支撑。值得注意的是,他们通过数据中台对数据能力进行抽象,共享和复用一些技术能力,所以从这个方面讲一些案例,希望能够对大家有所帮助。
Q&A
Q:Telemetry 的指标是如何指定的?主要考虑因素是哪些?
A:Telemetry 指标就是游戏数据指标,首先要能够覆盖游戏的所有用户行为,其次是要能够为公司业务分析提供支撑,包括日活、月活、用户平均时长、平均消费等公开可获取的数据,一定要用规定好的格式呈现出来,同时也为游戏开发部门提供一些灵活的地方,方便他们自助分析。一般来说,我们会在游戏上线前一年确定 Telemetry 框架,但是后期会做一些调整,主要还是从业务角度考虑需要分析什么样的指标,然后以年为单位进行讨论和迭代。
Q:过去一年听到一些数据中台建设失败案例,您怎么看?
A:我觉得数据中台建设要根据各自企业的情况来讨论,建设过程是分阶段的,我们回顾一家企业的数字化驱动历程可以发现首先是要有信息化建设;其次进入数据仓库阶段,可以在数据仓库上做一些统计分析;然后是当数据量大到数据仓库无法支撑时,我们就进入大数据平台的建设阶段,将数据拉取到 Hadoop 生态做分布,并将数据汇集到一起做离线数据分析;最后是随着业务线的增多,大数据平台建设开始出现烟囱式的架构,此时需要为所有业务线提供统一的数据中台,将能力共享出来以让业务线复用。这是一个逐步升级的过程,企业需要根据自己的实际情况看自己所处的阶段,来判断是否适合搭建数据中台。
Q:大数据平台和数据中台是一样的吗?
A:大数据平台跟数据中台是有区别的,大数据平台主要还是基于 Hadoop 的生态系统,可能有一条数据流水线做数据采集、数据处理、数据分析等,就好像 EA 早期如果不做统一的数据规范和数据标准,可能只是把数据集中到一起了,但本质还是烟囱式的。此外,数据中台可以把一些数据能力抽象出来共享给其他业务线,而不是专为某个业务部门打造数据能力。目前,硅谷没有数据中台的说法,但他们数据平台的设计思路就是按照中台的理念建设的。
Q:中台建设的经费和考核指标一般是什么?
A:考核指标主要是投入产出比,首先要知道投入了多少,包括硬件资源、人力资源、存储成本等,然后要清楚这些资源消耗在哪些环节,被哪些业务部门使用。Twitter 之前有一个很有意思的案例,他们发现某段时间的电费特别高,最后发现大量的计算资源花在用户关系的建立上。如果大量资源被某一个非核心业务部门占用可能就意味着内部的优先级排序出现问题,核心部门反而没有得到中台资源的支撑。在使用上,对频繁使用的业务部门提出奖励,对几乎没有使用的业务部门进行敲打。
Q:国内做数据中台的公司多吗?市场如何开拓?
A:我需要强调的是数据中台不是一个开盒即用的产品,每个公司可能都有自己的一套方法论以及技术基础打造符合公司业务特点的平台,你也可以选择在大数据平台之上做数据能力的共享和复用,做数据中台底层技术架构的公司还是比较多的,市面上有很多做大数据平台的公司。就市场而言,目前国内的很多公司已经到了数据中台的建设阶段,说明大家已经开始思考这个问题,也就是说数据中台这样一个数字化驱动的架构确实是有必要的,从过去的粗放式经营到现在的精细化运营,通过数字化的方式推动业务发展,我觉得数据中台的前景还是很可观的。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ 主编

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论