

本篇文章选自数据库内核杂谈系列文章。
在之前的文章中,我们通过存储和索引,了解了如何把数据存储在文件系统里,然后根据不同的查询语句,通过建立索引来提速读取。今天,我们来聊一下当数据读进内存后,数据库怎么继续执行查询。
之前系列文章都是以自底向上的线索来介绍数据库内核。但在介绍具体的执行前,我觉得有必要从宏观角度来看一下数据库的内部结构是如何对输入的 SQL 语句做处理,并返回结果集(Resultset)的。这样一个宏观的了解也会让读者对后续的数据库执行和优化更加期待。在系列的第一期里,我们介绍的一小时数据库是直接根据 SQL 语句来看如何实现,那一个正儿八经的数据库内部是怎样的呢?下图给出了一个宏观数据库的内部架构,我们跟着图片一一介绍。
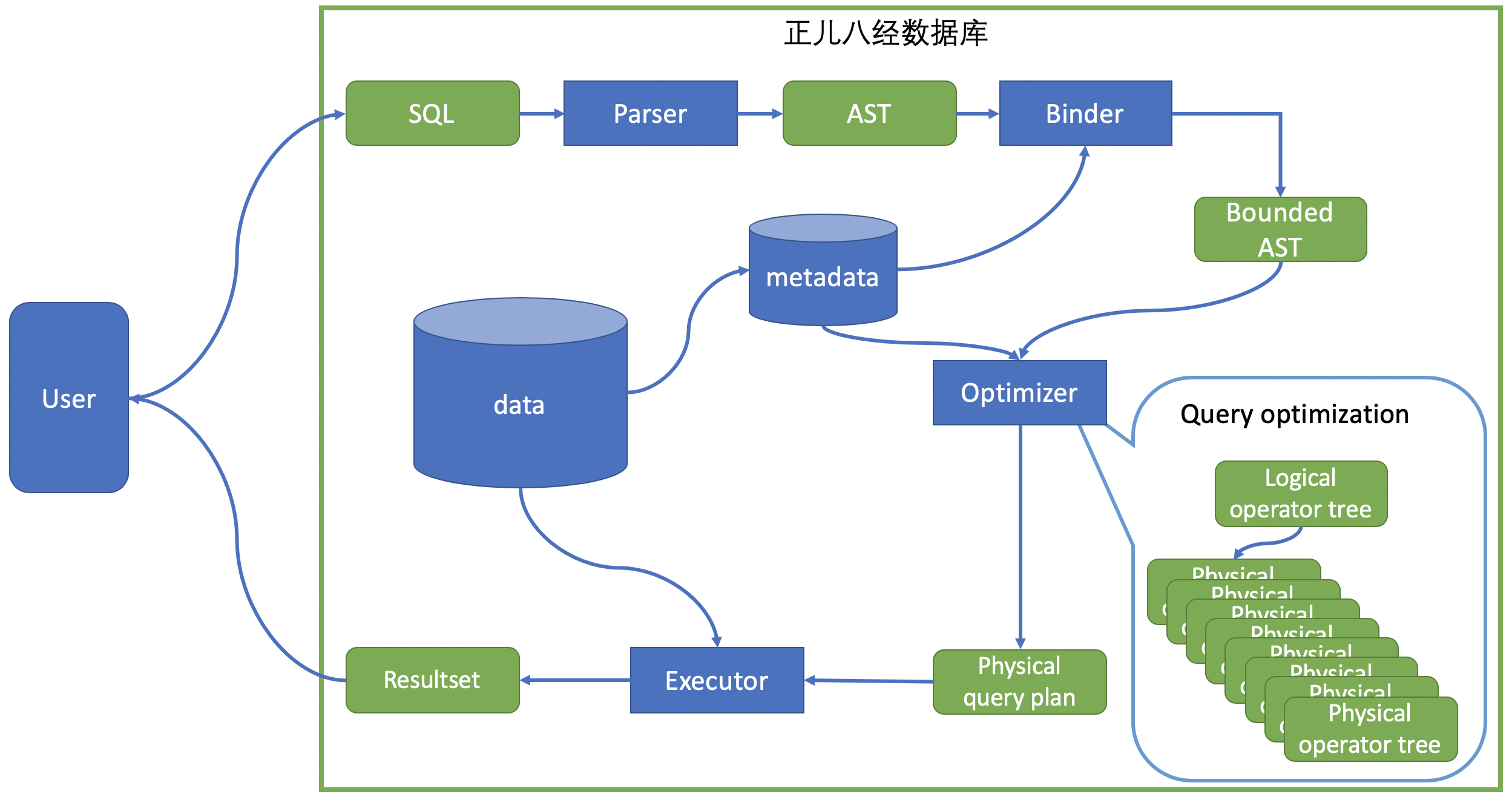
数据库内部结构
编译(parsing)
当用户输入 SQL 语句后,第一步是通过编译器(parser)把语句编译成抽象语法树(Abstracted Syntax Tree)。这一步的主要过程就是确保输入语句没有 SQL 语法和词法错误。常见的语法错误如:关键词拼写错误-把"SELECT"拼成"SELCT"; 是否有多余的标点符号; 整个语句是否合法-SELECT 后需要跟有 FROM 子语句,并且不应该有两个 WHERE 子语句等等。编译器的实现,一般不需要手动一个规则一个规则地去实现,而是会通过定义词法和语法,然后由编译器的库来生成相关的代码。一般每个语言都有比较成熟的编译器库,比如 Java 语言的JavaCC。这是网上找到的一个开源 JavaCC 实现的SQLParser ,有兴趣的同学可以去深入了解下。生成的语法树就是一个保留原语句的结构化的树。比如,把下面示例语句编译成语法树
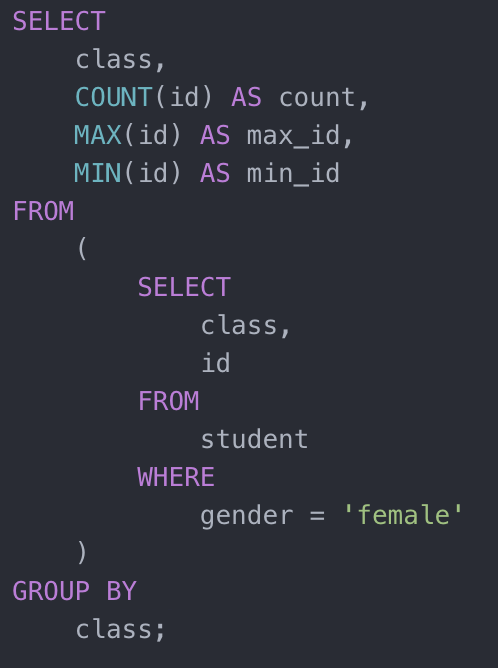
示例 SQL
得到如下图所示:
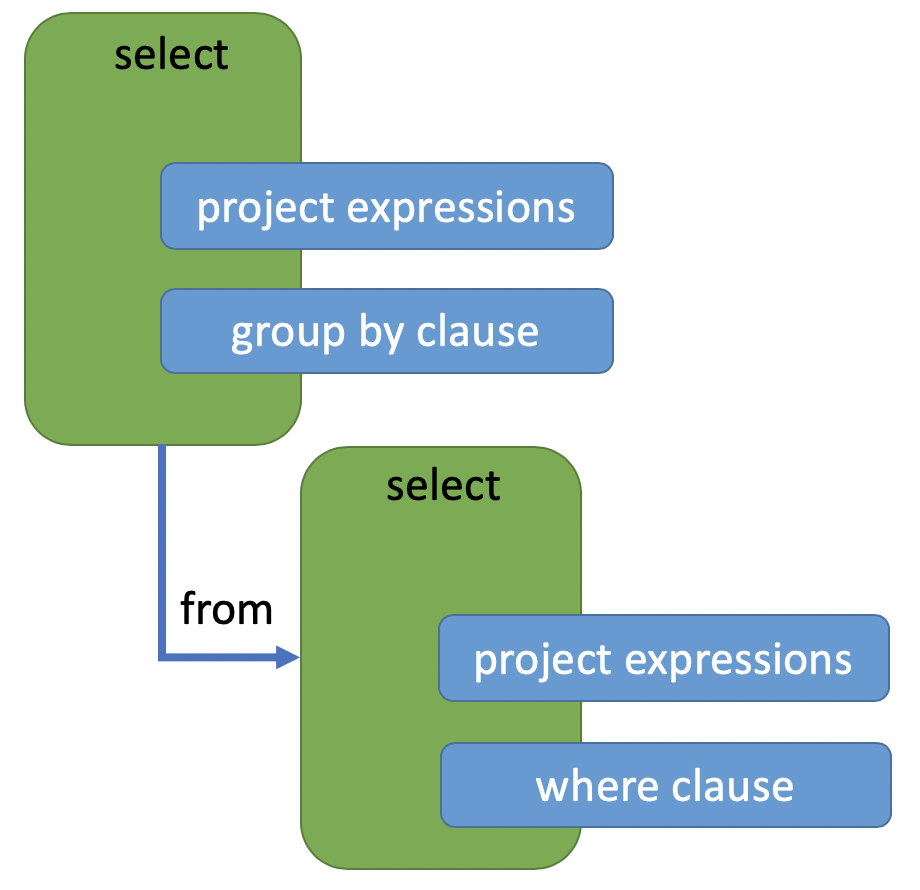
语法树
根节点 SELECT 包含 Projection-expression 和 GroupBy-expression,并且它有一个同为 SELECT 的子节点。这个子节点有自己的 Projection-expression 和 Where-clause。这里,留一个小问题,假如查询语句如下(查询一个不存在的数据表),编译器会报错吗?
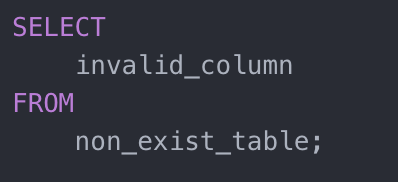
错误示例 SQL
绑定(binding)
揭晓答案,编译器是无法察觉上面的 SQL 中的错误的,因为它只负责把文本的 SQL 语句转化成了一棵符合 SQL 语法结构的树。那谁来赋予这棵树灵魂呢?答案就是 binder(姑且就翻译为绑定器吧)。顾名思义,绑定器的作用就是将语法树通过和数据库的元数据(metadata)结合,为它附上语义(semantic)。比如语句里有 SELECT…FROM student,绑定器会去查询元数据确认 student 表是否存在;如果存在,是否有 class 和 id 两个属性;对于属性的后续操作是否符合规则-比如,对于 SUBSTR()这个方法,输入表达式必须是字符串类型等的一系列检查。检查过程是自底向上对整棵语法树的节点依次进行,检查的同时也把相关表的元数据,属性的元数据附在语法树上,最后生成含有语义的语法树(bound AST)。绑定器在绑定的过程中就能察觉到上述 SQL 的问题而返回编译错误。一旦绑定完成,这个 SQL 语句就算是通过编译过程了。
优化(optimizing)
下一步就是优化器(Optimizer)的表演了。有这么一个传言,有这么多很好用的开源数据库,为什么商业数据库还卖这么贵?贵就贵在优化器这。优化器实现非常复杂,往往需要一个团队来开发。但同时,一个好的优化器可以把执行速度提高好几个数量级,特别是在针对复杂语句的优化上优势更加明显,可能就是一个小时和几秒的差距(是不是应该买买买!)。后面会有专门的章节介绍优化器,今天稍微提一下大概。给定了语法树,优化器会先生成一个逻辑执行树(logical operator tree)。这个执行树和我们第一章(一小时数据库)末尾的执行树类似。以上面的示例语句为例,生成的执行树如下:
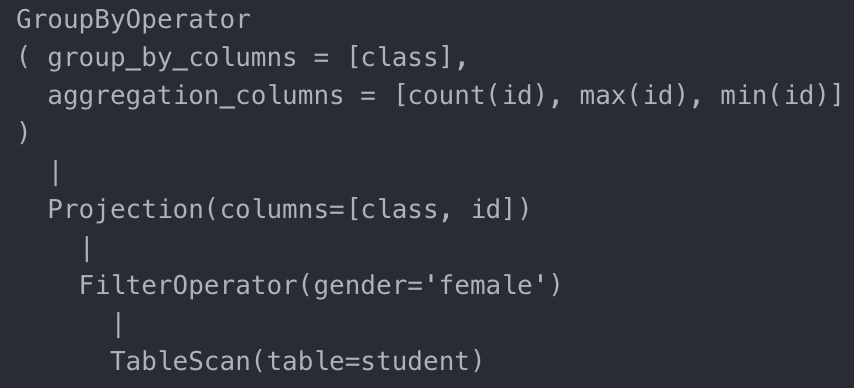
逻辑执行树
这个过程通常是语法树节点到操作符节点一对一生成。生成后执行树上的每个节点,称为逻辑操作符(logical operator)。再下一步,就是对应每个逻辑操作符,扩展出所有的物理操作符(physical operator)。何为逻辑和物理操作符呢?比如 TableScan,只是说明了这个操作符所要做的就是读取某个表的数据,这就是逻辑操作符。而对应的物理操作符则同时表明了应该用什么方法来实现这个功能,比如 SequentialTableScan(全表扫描)就是 TableScan 的一个物理实现,指明了通过扫描全表来得到数据。而如果用 BTreeIndexScan 就表明通过读取该表的 BTree 索引来读取数据(建立在相应属性已建立 BTree 索引的前提下)。再比如示例中的 GroupByOperator,有什么样对应的物理操作符呢?方法一,通过建立 Hash 表来实现 GroupBy(HashGroupByOperator);方法二,通过对子节点的输入的 key 属性进行排序,然后对于相同 key 进行聚合操作再输出(SortGroupByOperator)。(注:后续文章讲 GroupByOperator 实现的时候我们会深入讲解,这边就先简略带过)扩展之后的物理执行树,相对应与原来的逻辑执行树,相当于变出了很多分身:每个逻辑节点对位多个物理节点,比如一个物理执行树可以用 HashGroupBy 配 SequentialTableScan,也可以用 HashGroupBy 配 BTreeIndexScan。对应示例的逻辑执行树,相当于总共形成了 4 棵物理执行树。下一步就是最最困难的,在这浩如烟海的物理执行树中选出最好的一个,作为执行计划(Physical query plan)。看到这,读者可能一脸懵比?4 个等于浩如烟海?这只是因为示例的语句很简单,没有太多的组合可能。那什么情况会形成执行树数量的爆炸呢?就是表的联合(join)。假如一个 SQL 语句包含 10 个表的联合,这 10 个表可以相互两两联合形成中间表(intermediate result),这些中间表还需要再一次进行两两联合,然后再继续。并且,每一次联合有两种选择(table1 join table2 或者 table2 join table1),而且联合对应的物理操作符又有好几个(HashJoin 或者 MergeSortJoin 注:在讲 Join operator 的时候会深入讲解)。这样一来,一个复杂的查询语句对应上百万个执行树就不难理解了。这里先不深入讲解优化器是怎么做出选择的,我们暂且假设它就是个黑盒操作选出了一个它认为最优的作为执行计划。
执行(executing)
有了这个执行计划,执行器要做的就是加载相应操作符的代码,然后依次执行这些代码。这些代码和我们第一章的一小时数据库给出的示例代码功能类似。从执行树的底层,由读取表数据开始,依次向上执行。最后把执行得到的结果以 Rowset 的形式返回给用户。
至此,一个完整的由输入 SQL 语句开始,到输出结果集的生命周期完整结束。梳理一下:
1)用户输入 SQL 语句 -> 编译器 -> 抽象语法树
2)抽象语法树 -> 绑定器 -> 绑定语义的语法树
3)绑定语义的语法树 -> 优化器 -> 物理执行计划
4)物理执行计划 -> 执行器 -> 运行执行计划,得到结果集,返回给用户
执行模式
了解了整个流程,我们就可以更好地来看执行器是如何根据执行计划,一步一步将数据读取出来,然后计算出结果集的。先回到咱们第一章的一小时数据库的执行器,看看它是怎么执行的。在那个执行器里,我们定义了两个抽象的操作符,单元操作符(unary operator)和二元操作符(binary operator),示例代码如下。
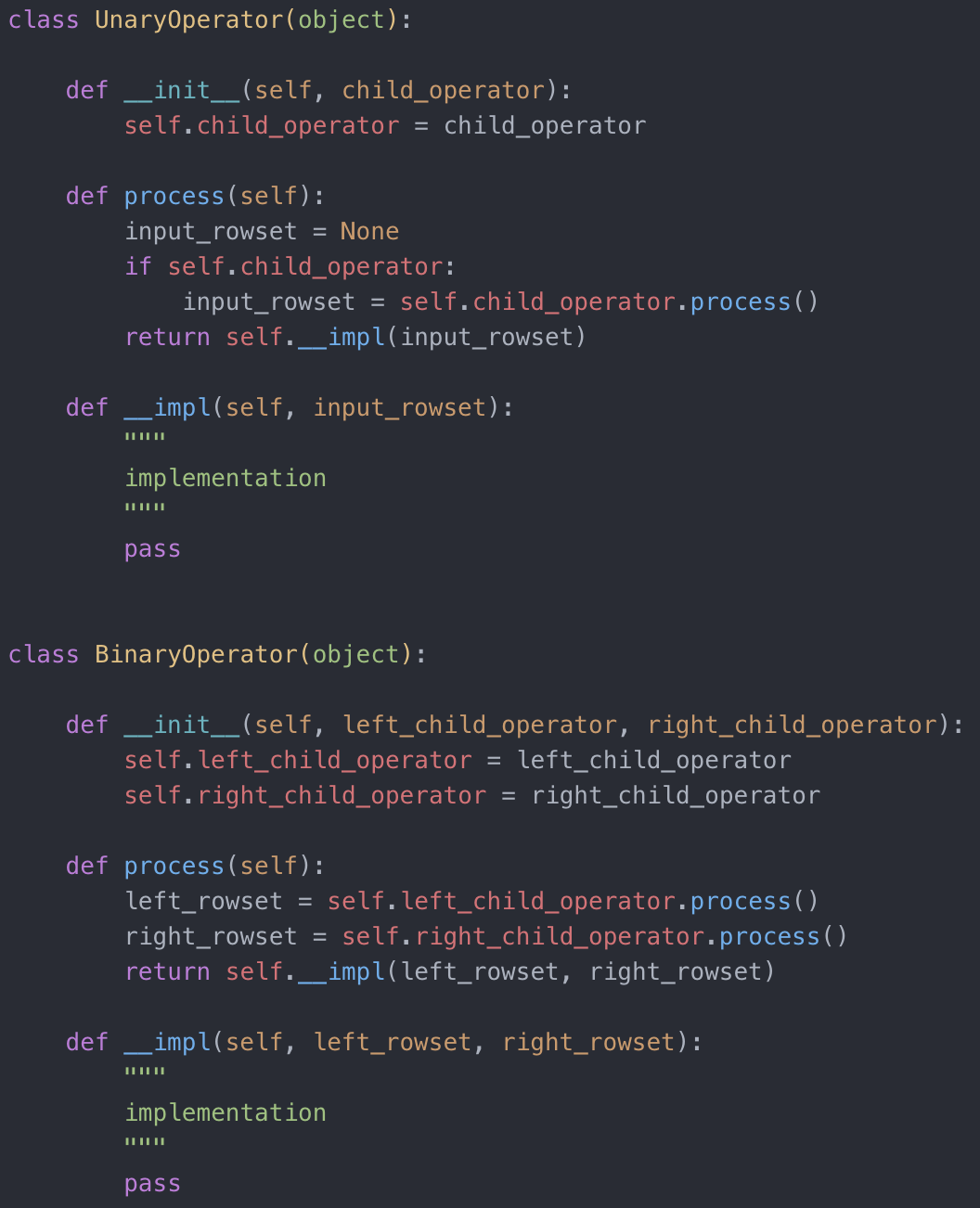
UnaryOperator 和 BinaryOperator
它们都实现了 process 逻辑,然后相应的物理操作符比如 SequentialTableScan 或者 SortOperator 只需要实现具体的__impl 方法即可。根据这样的执行器,生成如下的执行计划代码,即可运行我们示例中的 SQL 语句:
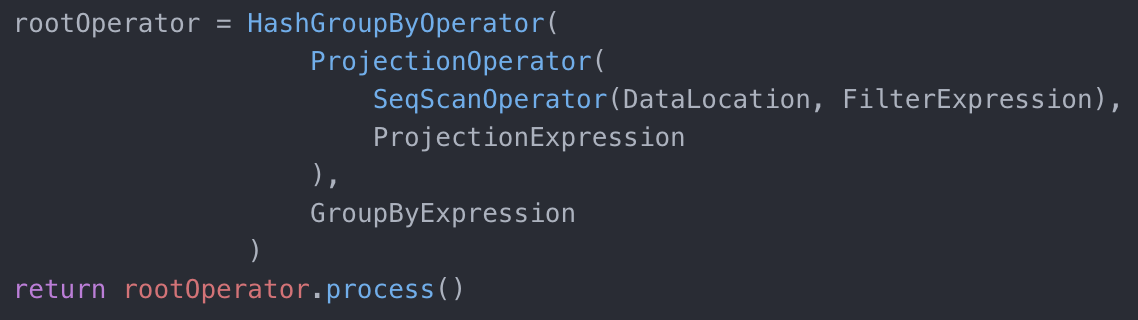
对应示例语句的执行计划代码
代码运行时,自底向上,每个节点 process 方法只需要运行一次,一次性处理子节点的全部输入 Rowset,__impl 处理后,返回处理过的 Rowset。这种执行模式称为 materialization 模式(额,不知如何翻译成中文)。寓意为把自己的输出打包一次性传给上层节点。这种执行模式有哪些优点呢?首先,非常直观,实现起来也相对容易,上下 operator 的交互只有一次。那这种模式有什么缺点吗?所谓成也风云,败也风云。简单就是它的缺点:一次性需要处理所有的输入。如果我们要处理的数据特别大,假设某个表有 1 亿条数据,TableScan 需要把所有数据先读取到内存中,再传输给上层节点,可能在这个过程中,就已经 OOM(out of memory)了。因此,materialization 模式并不适用数据量相对很大的 OLAP(online analytical processing)查询语句。
如何改进能够避免 OOM 呢?有同学可能想到了,每个操作符并不需要把所有数据一次性处理完再打包传给上层节点,完全可以借鉴时下流行的流系统(streaming system)的运行模式:每一个操作符既是 producer,又是 consumer:consume 子节点的输入,然后 produce 输出给上层节点:数据就像水流那样流过所有的节点,最后以一个一个 tuple 的形式返回给 user。其实呢,可能正确的说法应该是 streaming system 借鉴了数据库的这种运行模式。这个模式称之为 iterator model(迭代模式)或者叫 Volcano model(火山模式),最早由科学家 Goetz Graefe 于 1990 年提出(再次感谢一下计算机先贤)。下图给出了简单的伪代码实现:
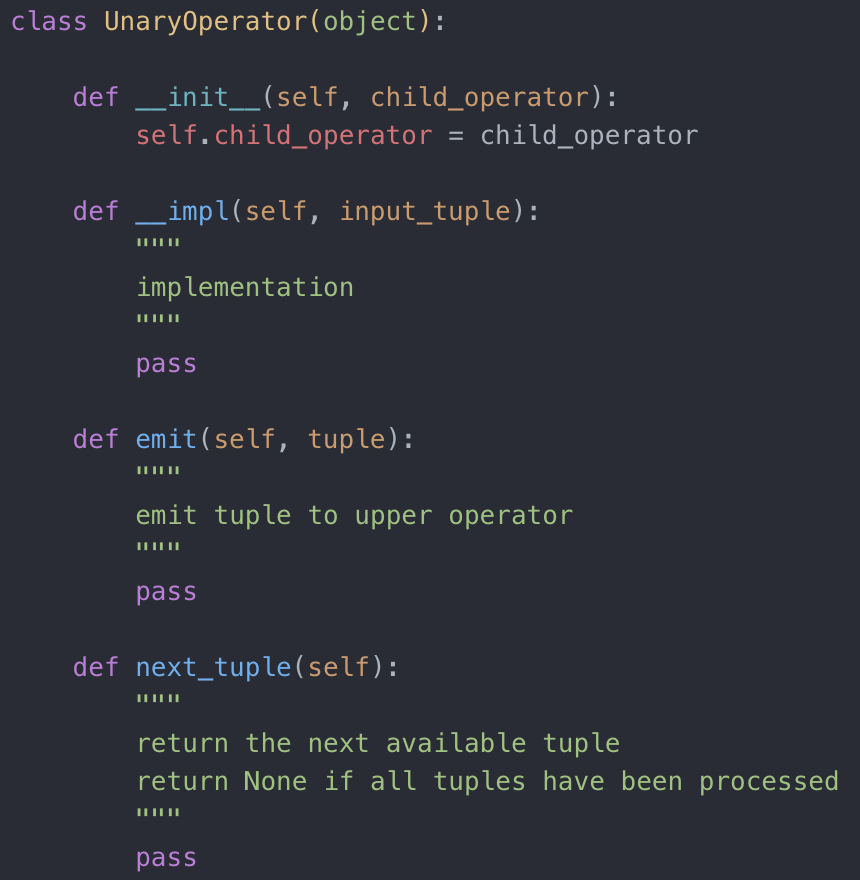
迭代模式下的 UnaryOperator
每个 operator 会有一个 next_tuple 函数,用来让上层节点调用来获得下一个 tuple,以及 emit 函数用来输出一个处理过的 tuple 到上层节点。整个 process 的过程入下图示例代码:

迭代模式下的 process 逻辑
在 while 循环中,不断获取子节点的下一个输入 tuple,处理后输出给上层节点直至子节点输入全部处理完毕。这个迭代模式,是不是就完美解决了所有的 OOM 问题呢?答案是否定的。因为,并不是所有的操作都适用于流模型,比如处理 order by 语句的 SortOperator,如果要对全部输入进行排序,必须等到所有输入都得到后才能进行排序,因此执行过程会堵塞(block)。再比实现示例语句中的 group by 语句的 HashGroupByOperator,也是需要获取所有的输入后才能做聚合操作来得到正确的结果再输出。下图给出了 HashGroupByOperator 的伪代码实现:
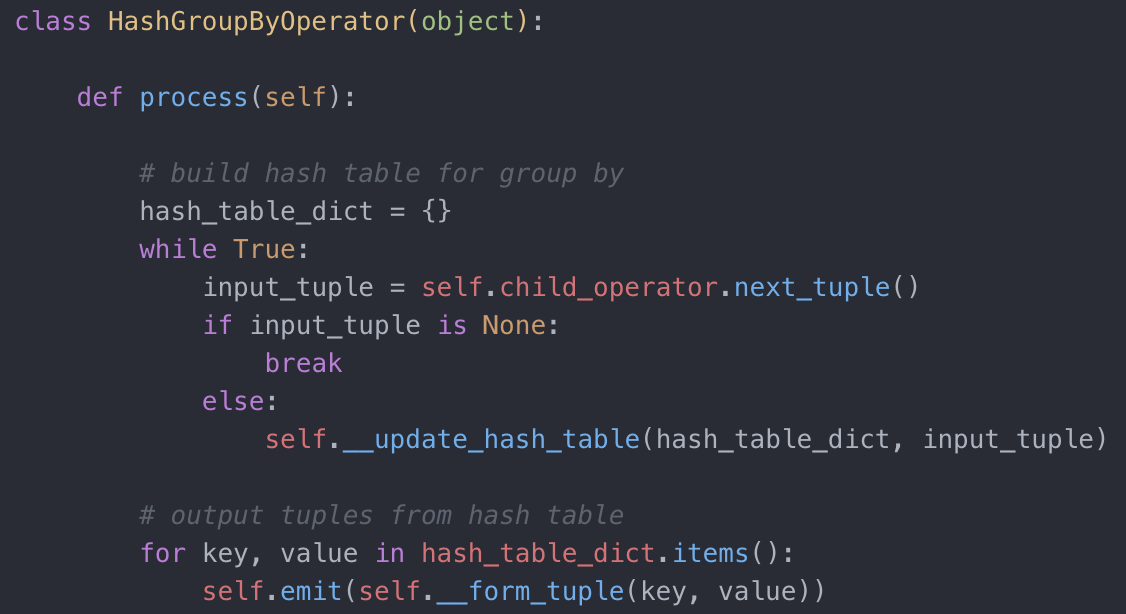
迭代模式里的 HashGroupByOperator
对于子节点的每个输入,我们先进行哈希表的建立和更新,当所有的输入都结束后,依次输出哈希表的键值对。这类操作也称之为堵塞操作(blocking operator)。那如何解决堵塞操作的 OOM 问题呢?这就需要这些操作能够在处理的过程中把中间的结果集(intermediate result)暂存到文件系统中(spill to disk)。比如 sort,可以用 external file sorting algorithm。具体的这些操作符的实现我们会在后续的章节中详细介绍。这里插个题外话:大家可能觉得,实现 spill to disk 功能对数据库引擎是必须的。但从工程角度来说,实现正确又高效是挺有难度的。比如作者公司内部使用最多的Presto, 已经是一个比较出名的开源数据库系统实现。但至今为止,感觉 spill to disk 功能也没完全实现。在运行某些语句时,经常因为遭遇单个节点内存 limit 或者集群内存 limit 而报错。吐槽一下!既然吐槽了自家公司,就再吐槽一家很出名的大数据公司。当时它们也推出了一款分布式数据库执行引擎。然后在测试的过程中发现,执行 order by 语句必须同时加上 limit 限定语句。哈,这一看就是当时 sorting 还不支持 spill to disk. 留个思考题给大家,猜猜当时他们是怎么实现 sorting 的。答案在结尾揭晓。
总结一下,迭代模式实现了流式处理,配合上 spill to disk 的实现来解决堵塞操作符,就是一个非常通用的执行模式,完美解决了 materialization 模式的缺点。那它自己有什么缺点吗?其实 materialization 的优点就是它的缺点:实现复杂度很高。而且数据是一个一个 tuple 在操作符间传递,这导致不同的操作符之间需要多次的协调,因此处理相同的数据,迭代模式比前者更慢。
materialization 模式是一次性处理所有数据,而迭代模式是一个一个 tuple 处理数据,有没有一种折中的方式呢?就是今天的最后一个知识点向量模式(vectorization model),或者叫批处理模式(batch model)。相比于迭代模式一个一个 tuple 处理,向量模式是一批一批处理数据,伪代码如下图所示:
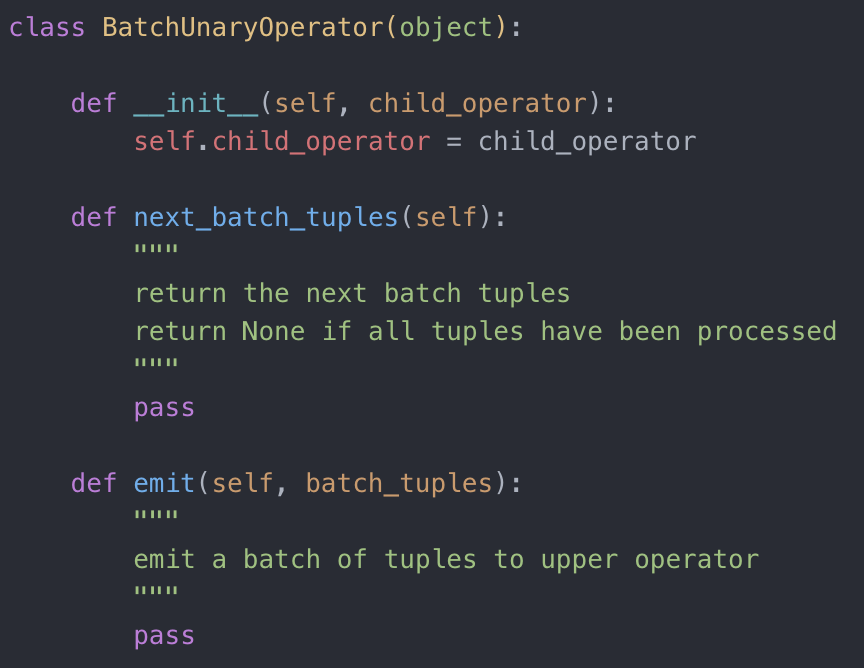
向量模式下的 UnaryOperator
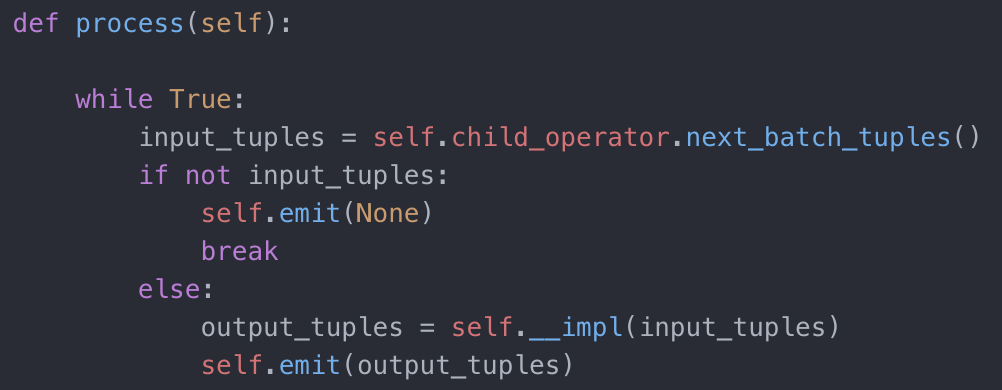
向量模式下的 process 逻辑
向量模式相比于迭代模式,每一次处理多个数据,减少了操作符之间的交互;而相较于 materialization 模式,又更不容易导致 OOM,所以实现相对容易。并且,可以更好地利用处理器的 SIMD(single instruction multiple data)指令来提高执行速度。向量模式的另一个优点在于,很切合列存:批量从列存中读取数据后进行批量处理。因此,比较适用于数据量很大的 OLAP 查询语句。
最后,我们对今天介绍的所有执行模式来一个总结:
1)materialization 模式:执行的过程自底向上,每个节点都一次性处理所有数据。优势是实现简单,但对于数据量很大的 OLAP 语句不太合适,但比较适合单次操作数据量较小的 OLTP(online transactional processing)语句。
2)迭代模式(或者叫 volcano model): 一种通用的执行模式。流式的执行过程,数据以一个一个 tuple 形式传递与操作符之间。有一些操作符会需要阻塞等待所有数据,需要 spill to disk 实现。缺点是实现复杂,由于操作符之间不断交互,所以效率相对较低。
3)向量模式:介于前两者之间,批量处理数据。更好地利用 SIMD 来提高执行速度。对于大量数据处理比迭代模式高效,所以也更适合 OLAP 语句。
这一期,我们先从宏观上大致讲解了数据库的内部构造,然后具体聊了聊不同的执行模式以及它们的优缺点。下一期,我们聊一聊那些比较复杂的操作如 sorting, join 和 GroupByOperator 的具体实现,尽情期待。
揭晓上面的思考题,要求 sorting 加 limit 语句来限制总数,应该是用了 minHeap 来实现的排序。
作者介绍:
顾仲贤,现任 Facebook Tech Lead,专注于数据库,分布式系统,数据密集型应用后端架构与开发。拥有多年分布式数据库内核开发经验,发表数十篇数据库顶级期刊并申请获得多项专利,对搜索,即时通讯系统有深刻理解,爱设计爱架构,持续跟进互联网前沿技术。
2008 年毕业于上海交大软件学院,2012 年,获得美国加州大学戴维斯计算机硕士,博士学位;2013-2014 年任 Pivotal 数据库核心研发团队资深工程师,开发开源数据库优化器 Orca;2016 年作为初创员工加入 Datometry,任首席工程师,负责全球首家数据库虚拟化平台开发;2017 年至今就职于 Facebook 任 Tech Lead,领导重构搜索相关后端服务及数据管道, 管理即时通讯软件 WhatsApp 数据平台负责数据收集,整理,并提供后续应用。
相关阅读:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 16 条评论