

导读:图数据有着复杂的结构,多样化的属性类型,以及多层面的学习任务,要充分利用图数据的优势,就需要一种高效的图数据表示方法。与表示学习在数据学习中的重要位置一样,图表示学习也成了图学习领域中的十分热门的研究课题。
作为近几年深度学习的新兴领域,GNN 在多个图数据的相关任务上都取得了不俗的成绩,这也显示出了其强大的表示学习能力。毫无疑问 GNN 的出现,给图表示学习带来了新的建模方法。表示学习本身具有十分丰富的内涵和外延,从建模方法、学习方式、学习目标、学习任务等等方面都有所涵盖。这些内容在前面章节均有阐述,所以本章我们主要就基于 GNN 的无监督图表示学习进行讲解。这也有另外一方面的考虑,在实际的应用场景里面,大量的数据标签往往具有很高的获取门槛,研究如何对图数据进行高效地无监督表示学习将具有十分重要的价值。
本文内容分 2 节,第 1 节主要从三种建模方法上对图表示学习进行对比阐述。第 2 节分别从两类无监督学习目标——重构损失与对比损失,对基于 GNN 的无监督表示学习进行阐述。
图表示学习
在前面我们通常用邻居矩阵 A∈RNxN 表示图的结构信息,一般来说,A 是一个高维且稀疏的矩阵,如果我们直接用 A 去表示图数据,那么构筑于之上的机器学习模型将难以适应,相关的任务学习难以高效。因此,我们需要实现一种对图数据的更加高效的表示方式。而图表示学习的主要目标,正是将图数据转化成低维稠密的向量化表示方式,同时确保图数据的某些性质在向量空间中也能够得到对应。这里图数据的表示,可以是节点层面的,也可以是全图层面的,但是作为图数据的基本构成元素,节点的表示学习一直是图表示学习的主要对象。一种图数据的表示如果能够包含丰富的语义信息,那么下游的相关任务如点分类、边预测、图分类等,就都能得到相当优秀的输入特征,通常在这样的情况下,我们直接选用线性分类器对任务进行学习。图 1 展示了图表示学习的过程:
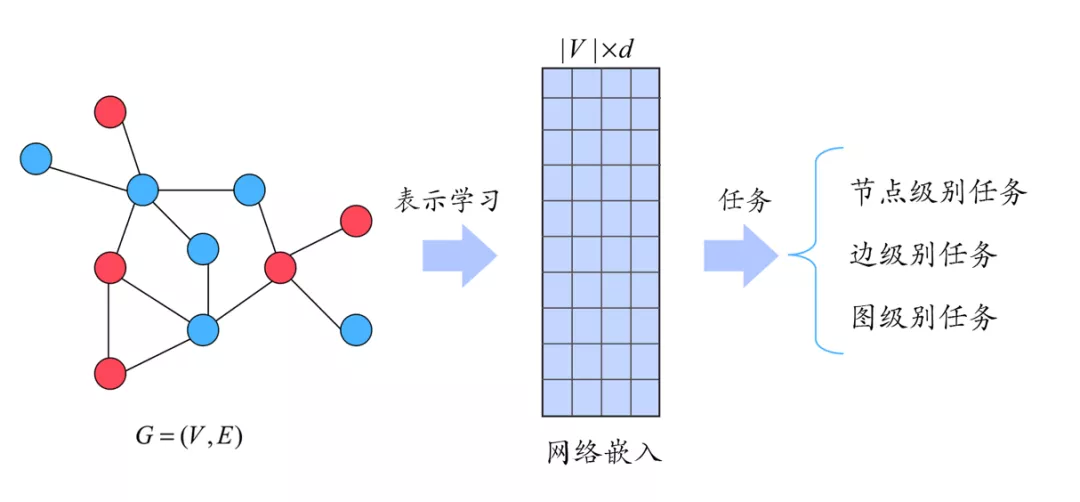
图 1 图表示学习过程
同表示学习一样,图表示学习的核心也是研究数据的表示。特殊的是,图表示学习的研究对象是图数据。我们知道图数据中蕴涵着丰富的结构信息,这本质上对应着图数据因内在关联而产生的一种非线性结构。这种非线性结构在补充刻画数据的同时,也给数据的学习带来了极大的挑战。因此在这样的背景下,图表示学习就显得格外重要,它具有以下两个重要作用:
将图数据表示成线性空间中的向量。从工程上而言,这种向量化的表示为擅长处理线性结构数据的计算机体系提供了极大的便利。
为之后的学习任务奠定基础。图数据的学习任务种类繁多,有节点层面的,边层面的,还有全图层面的,一个好的图表示学习方法可以统一高效地辅助这些任务的相关设计与学习。
图表示学习从方法上来说,可以分为基于分解的方法,基于随机游走的方法,以及基于深度学习的方法,而基于深度学习的方法的典型代表就是 GNN 相关的方法。下面我们回顾一下前两类方法:
在早期,图节点的嵌入学习一般是基于分解的方法,这些方法通过对描述图数据结构信息的矩阵进行矩阵分解,将节点转化到低维向量空间中去,同时保留结构上的相似性。这种描述结构信息的矩阵比如有邻接矩阵[1],拉普拉斯矩阵[2],节点相似度矩阵[3]。一般来说,这类方法均有解析解,但是由于结果依赖于相关矩阵的分解计算,因此,这类方法具有很高的时间复杂度和空间复杂度。
近些年,词向量方法在语言表示上取得了很大的成功,受该方法的启发,一些方法开始将在图中随机游走产生的序列看作句子,节点看作词,以此类比词向量从而学习出节点的表示。典型的方法比如 DeepWalk[4]、Node2Vec[5]等。图 2 给出了 DeepWalk 算法的示意图:
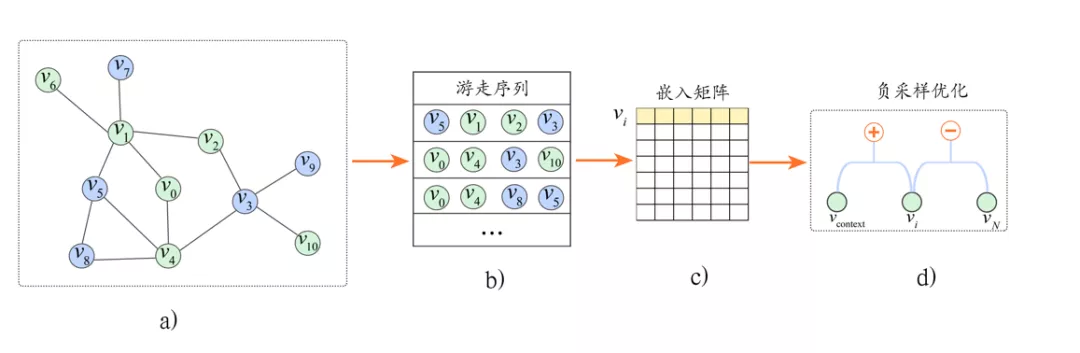
图 2 DeepWalk 算法示意图
DeepWalk 通过随机游走将图转化成节点序列,设置中心节点左右距离为 w 的节点为 上下文 ( context ),如图 2b 所示。同词向量方法一样,DeepWalk 本质上建模了中心节点与上下文节点之间的共现关系,这种关系的学习也采用了负采样的优化手段,如图 2d 所示。
基于随机游走的方法相比上一类方法,最大的优点是通过将图转化为序列的方式从而实现了大规模图的表示学习。但是这也导致了两个缺点:一是将图转化成序列集合,图本身的结构信息没有被充分利用;二是该学习框架很难自然地融合进图中的属性信息进行表示学习。
关于 GNN 方法的建模细节,作为本书之前相关章节的重要内容进行了阐述,这里就不再赘述。通过之前的学习,我们可以知道基于 GNN 的图表示学习具有以下几点优势:
非常自然地融合进了图的属性信息进行学习,而之前的方法大多把图里面的结构信息与属性信息进行单独处理。
GNN 本身作为一个可导的模块,能够嵌入到任意一个支持端对端学习的系统中去,这种特性使得其能够与各个层面的有监督学习任务进行有机结合 ( 或者以微调学习的形式进行结合 ),学习出更加适应该任务的数据表示。
GNN 的很多模型如 GraphSAGE、MPNN 等都是支持归纳学习的,多数情况下对于新数据的表示学习可以直接进行预测,而不用像之前的多数方法需要重新训练一次。
相较于分解类的方法只能适应小图的学习,GNN 保证了算法在工程上的可行性,对大规模图的学习任务也能适应。
综上,基于 GNN 的相关方法具有强大的学习能力与广泛的适应性,是图表示学习重要的代表性方法。
基于 GNN 的图表示学习
凭借强大的端对端学习能力,GNN 这类模型可以非常友好地支持有监督的学习方式。但是 GNN 本身作为一种重要的对图数据进行表示学习的框架,只要与相应的无监督损失函数结合起来就能实现无监督图表示学习。无监督学习的主体在于损失函数的设计,这里我们分两类损失函数进行介绍:基于重构损失的 GNN 和基于对比损失的 GNN。
1. 基于重构损失的 GNN
类比于自编码器的思路,我们可以将节点之间的邻接关系进行重构学习,为此可以定义一个如下的图自编码器 ( Graph AutoEncoder ):
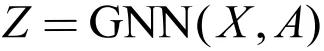
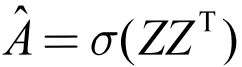
其中,Z 是所有节点的表示,这里借助 GNN 模型同时对图的属性信息与结构信息进行编码学习。 是重构之后的邻接矩阵,这里使用了向量的内积来表示节点之间的邻接关系。图自编码器的重构损失可以定义如下:
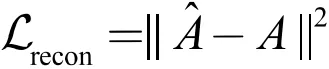
由于过平滑的问题,GNN 可以轻易地将相邻节点学习出相似的表达,这就导致解码出来的邻接矩阵 能够很快趋近于原始邻接矩阵 A,模型参数难以得到有效优化。因此,为了使 GNN 习得更加有效的数据分布式表示,同自编码器一样,我们必须对损失函数加上一些约束目标。比如,我们可以学习降噪自编码器的做法,对输入数据进行一定地扰动,迫使模型从加噪的数据中提取有用的信息用于恢复原数据。这种加噪的手段包括但不限于下面所列的一种或多种:
对原图数据的特征矩阵 X 适当增加随机噪声或置零处理;
对原图数据的邻接矩阵 A 删除适当比例的边,或者修改边上的权重值。
另外,其他的许多自编码器中的设计思路都可以被借鉴。接下来,我们看看比较重要的变分图自编码器 ( Variational Graph Autoencoder ,VGAE ) [6]。VGAE 和变分自编码器的基本框架一样,不同的是使用了 GNN 来对图数据进行编码学习。下面分三个方向来介绍其基本框架包括推断模型 ( 编码器 )、生成模型 ( 解码器 )、损失函数。
① 推断模型
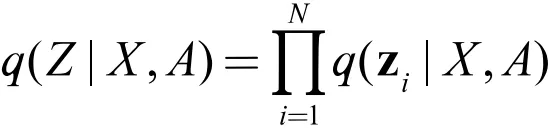
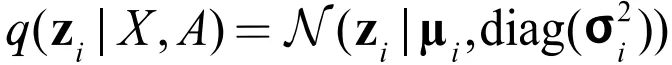
与 VAE 不同的是,这里我们使用两个 GNN 对 μ、σ 进行拟合:
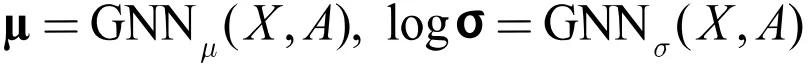
② 生成模型
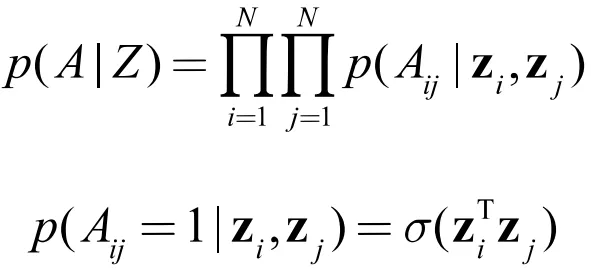
这里也简单使用了两个节点表示向量的内积来拟合邻接关系。
③ 损失函数
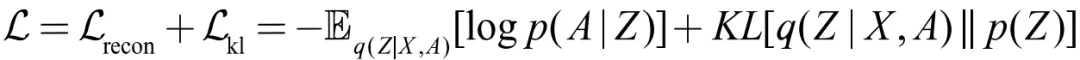
同样地,隐变量 z 的先验分布选用标准正态分布:
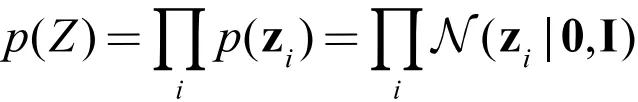
VAE 与 GNN 的结合,不仅可以被用来学习图数据的表示,其更独特的作用是提供了一个图生成模型的框架,能够在相关图生成的任务中得到应用,如[7][8],用其对化学分子进行指导设计。
2. 基于对比损失的 GNN
对比损失是无监督表示学习里面另外一种十分常见的损失函数。通常对比损失会设置一个评分函数 D(·),该得分函数会提高 “真实” ( 或正 ) 样本 ( 对 ) 的得分,降低 “假” ( 或负 ) 样本 ( 对 ) 的得分。
类比于词向量,我们将对比损失的落脚点放到词与上下文上。词是表示学习的研究主体,在这里,自然代表的是图数据中的节点了,上下文代表的是与节点有对应关系的对象。通常,从小到大,图里的上下文依次可以是节点的邻居、节点所处的子图、全图。作为节点与上下文之间存在的固有关系,我们希望评分函数提高节点与上下文对的得分,同时降低节点与非上下文对的得分。用式子表示如下:
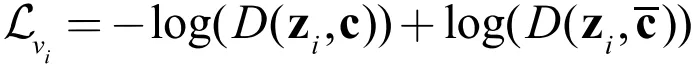
这里 c 表示上下文的表示向量, 表示非上下文的表示向量。下面我们依次来看看该损失函数在不同上下文的具体形式。
① 邻居作为上下文
如果把邻居作为上下文 ,那么上述对比损失就在建模节点与邻居节点的共现关系。在 GraphSAGE 的论文中就描述了这样的一种无监督学习方式,与 DeepWalk 一样,我们可以将在随机游走时与中心节点 vi 一起出现在固定长度窗口内的节点 vj 视为邻居,同时通过负采样的手段,将不符合该关系的节点作为负样本。与 DeepWalk 不一样的是,节点的表示学习模型还是使用 GNN,即:
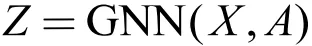
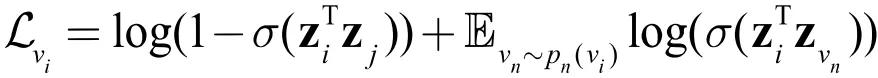
这里的 pn是一个关于节点出现概率的负采样分布,得分函数使用了向量内积加 sigmoid 函数,将分数限制在[0, 1]内。这个方法在优化目标上与图自编码器基本等同,但是这种负采样形式的对比优化,并不需要与图自编码器一样显式地解码出邻接矩阵 ,由于 破坏掉了原始邻接矩阵的稀疏性,因此该方法不需要承担 O(N2) 的空间复杂度。
② 将子图作为上下文
将邻居作为上下文时,强调的是节点之间的共现关系,这种共现关系更多反应了图中节点间的远近距离,缺乏对节点结构相似性的捕捉。而通常节点局部结构上的相似性,是节点分类任务中一个比较关键的因素[9]。比如图上两个相距很远的节点如果具有一样的子图结构,基于共现关系的建模方法就难以有效刻画这种结构上的对等性。因此,论文[10]就提出了直接将子图作为一种上下文进行对比学习。具体子图的定义如图 3 所示:
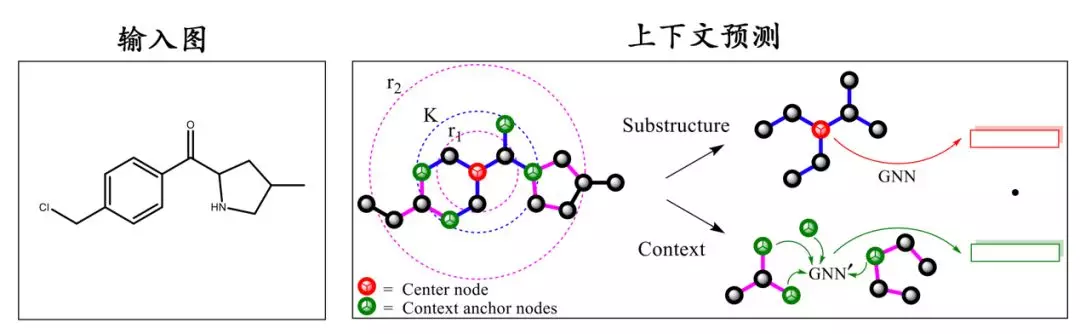
图 3 将子图作为上下文进行预测[10]
对于一个中心节点,如图 3,图中的红色节点所示,我们用一个 GNN 在其 K 阶子图上提取其表示向量,同时我们将处于中心节点 r1-hop 与 r2-hop 之间的节点定义为该中心节点的上下文锚点,如图 3 所示。设 K=2、r1=1、r2=4,我们用另一个 GNN 来提取每个节点作为上下文锚点时的表示向量,同时为了得到一个总的,固定长度的上下文表示向量,将使用读出机制来聚合上下文锚点的表示向量。式子表示如下:
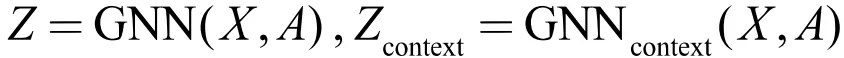
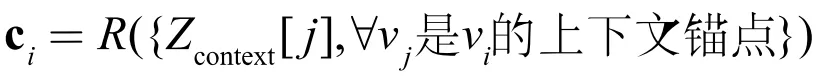
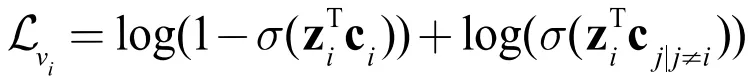
③ 全图作为上下文
在引文[11]中,提出了 Deep Graph Infomax ( DGI )[11] 的方法对图数据进行无监督表示学习。该方法实现了一种节点与全图之间的对比损失的学习机制。其具体做法如下:
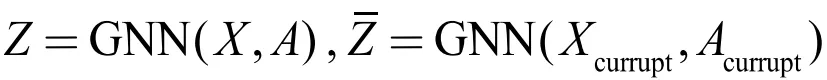
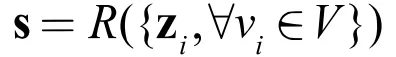
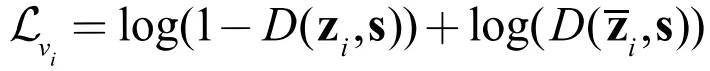
首先为了得到负采样的样本,需要对图数据进行相关扰动,得到 ,具体的加噪方法,上文中已有概括。然后将这两组图数据送到同一个 GNN 模型中进行学习。为了得到图的全局表示,我们使用读出机制对局部节点的信息进行聚合。在最后的损失函数中,作者固定了全图表示,对节点进行了负采样的对比学习。这样处理的原因是为了方便后续的节点分类任务。从互信息[12][13]的角度看,通过一个统一的全局表示,最大化全图与节点之间的互信息,这样可以在所有节点的表示之间建立起一层更直接的联系。比如上面提到的,相距较远节点之间的结构相似性的学习问题,这种设计可以保障该性质的高效学习。图 4 给出了上述过程的示意图:
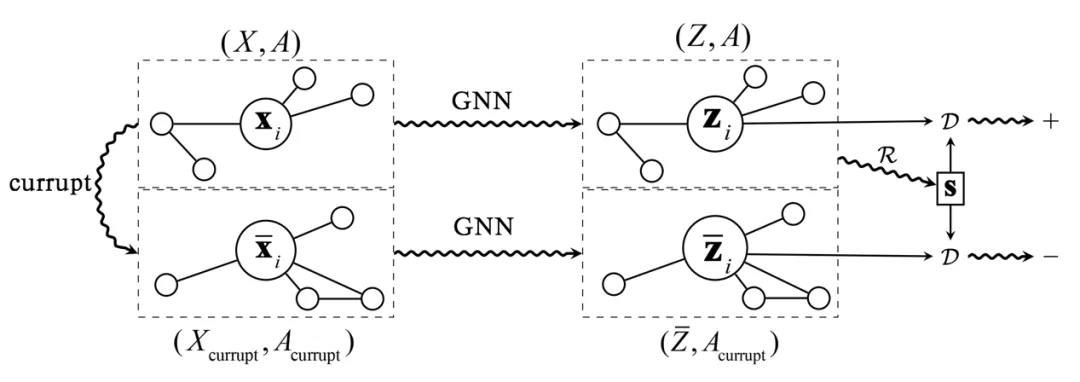
图 4 节点与全图对比损失学习机制[11]
同时在全图层面的无监督学习上,上述损失函数的负样本刚好相反,需要抽取其他图的表示 来代替,即:
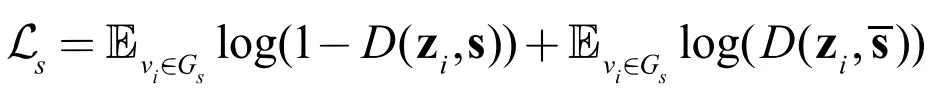
此时,由于是全图层面的任务,所以我们希望通过上式让全图与其所有局部节点之间实现互信息最大化,也即获得全图最有效、最具代表性的特征,这将对图的分类任务十分有益。
03 参考文献
[1] S. T. Roweis, L. K. Saul, Nonlinear dimensionality reduction by locally linea embedding, Science 290 (5500) (2000) 2323–2326.
[2] M. Belkin, P. Niyogi, Laplacian eigenmaps and spectral techniques for embedding and clustering, in: NIPS, Vol. 14, 2001, pp. 585–591.
[3] M. Ou, P. Cui, J. Pei, Z. Zhang, W. Zhu, Asymmetric transitivity preserving graph embedding, in: Proc. of ACM SIGKDD, 2016, pp. 1105–1114.
[4] Perozzi B, Al-Rfou R, Skiena S. Deepwalk: Online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 701-710.
[5] Grover A, Leskovec J. node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2016: 855-864.
[6] Kipf T N, Welling M. Variational graph auto-encoders[J]. arXiv preprint arXiv:1611.07308, 2016.
[7] Simonovsky, Martin and Komodakis, Nikos. Graphvae:Towards generation of small graphs using variational autoencoders. arXiv preprint arXiv:1802.03480, 2018.
[8] Samanta, Bidisha, De, Abir, Ganguly, Niloy, and GomezRodriguez, Manuel. Designing random graph models using variational autoencoders with applications to chemical design. arXiv preprint arXiv:1802.05283, 2018.
[9] Claire Donnat, Marinka Zitnik, David Hallac, and Jure Leskovec. Learning structural node embeddings via diffusion wavelets. In International ACM Conference on Knowledge Discovery and Data Mining (KDD), volume 24, 2018.
[10] Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay S. Pande and Jure Leskovec. Pre-training Graph Neural Networks. arXiv preprint arXiv:1905.12265,2019.
[11] Veličković P, Fedus W, Hamilton W L, et al. Deep graph infomax[J]. arXiv preprint arXiv:1809.10341, 2018.
[12] Hjelm R D, Fedorov A, Lavoie-Marchildon S, et al. Learning deep representations by mutual information estimation and maximization[J]. arXiv preprint arXiv:1808.06670, 2018.
[13] Melamud O, Goldberger J. Information-theory interpretation of the skip-gram negative-sampling objective function[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2017: 167-171.
[14] Berg R, Kipf T N, Welling M. Graph convolutional matrix completion[J]. arXiv preprint arXiv:1706.02263, 2017.
作者介绍:
刘忠雨:毕业于华中科技大学,资深图神经网络技术专家,极验科技人工智能实验室主任和首席技术官。在机器学习、深度学习以及图学习领域有 6 年以上的算法架构和研发经验,主导研发了极验行为验证、深知业务风控、叠图等产品,极验科技目前服务于全球 26 万家企业。
李彦霖:毕业于武汉大学,极验人工智能实验室技术专家。一直从事机器学习、深度学习、图学习领域的研究工作。在深度神经网络算法研发、图神经网络在计算机视觉以及风控中的应用等领域实践经验丰富。
周洋:工学博士,毕业于武汉大学,目前在华中师范大学任教。曾受邀到北卡罗莱纳大学访学,长期在大数据挖掘前沿领域进行探索和研究,并应用于地理时空大数据、交通地理等诸多方向,已发表 SCI&SSCI 及核心期刊论文 10 余篇。
本文来自 DataFunTalk
原文链接:
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论