

HDFS 是一个 Apache 基金会开源的一款分布式文件系统。HDFS 文件系统可以部署在低成本的硬件上,对外提供高吞吐的数据访问和海量数据存储的服务。本文总结 HDFS 磁带存储资源池建设的实践,拓展 HDFS 异构存储到磁带存储介质,强化了 HDFS 低成本海量数据存储能力。
HDFS 在 2.6.0 版本后引入了异构存储架构,支持内存、固态盘、HDD 磁盘、SATA 盘等存储介质。HDFS 异构存储可以根据各种介质读写特性,发挥各自的优势。针对低频访问数据存储的需求,采用容量大的,读写性能不高的大容量磁盘存储介质存储。对比普通的 Disk 磁盘,容量大成本低。而对于热数据而言,可以采用 SSD 的方式进行存储,这样就能保证高效的读性能,在速率上甚至能做到十倍于或百倍于普通磁盘读写的速度。对于最热的数据,甚至可以直接存放内存。HDFS 通过定义各种存储策略,可以根据数据的使用要求,把数据存储到相应的介质上,实现性能和成本的平衡。
目前 HDFS 的存储资源池有:
热 -用于存储和计算。流行且仍用于处理的数据将保留在此策略中。块热时,所有副本都存储在 DISK 中。
冷 -仅适用于计算量有限的存储。不再使用的数据或需要归档的数据从热存储移动到冷存储。当块处于冷状态时,所有副本都存储在 ARCHIVE 中。
温暖 -部分热和部分冷。当一个块变热时,其某些副本存储在 DISK 中,其余副本存储在 ARCHIVE 中。
All_SSD-用于将所有副本存储在 SSD 中。
One_SSD-用于将副本之一存储在 SSD 中。其余副本存储在 DISK 中。
Lazy_Persist-用于在内存中写入具有单个副本的块。首先将副本写入 RAM_DISK,然后将其延迟保存在 DISK 中。
但是 HDFS 目前支持的存储介质也存各种不足。相对 SAN 和 NAS 存储,分布式文件系统 HDFS 的成本不高($1000/TB),但是对于 EB 级别的数据量而言,HDFS 仍然高达亿元的存储成本。其次 HDFS 文件系统基于廉价的通用硬件,通过数千上万台 PC 服务器组成庞大的分布式集群才能提供 EB 级存储空间服务,这种架构的数据能耗密度高,数据空间密度低,不适合绿色数据中心的长久发展。
为了克服 HDFS 异构存储介质的不足,本项目尝试采用磁带技术进行数据存储。磁带技术发源于上世纪五十年代,是一项悠久的计算机存储技术。磁带技术具有成本低(¥500/TB)、存储时间长(理论保存时间长达 30 多年)、低能耗(磁带不使用时不消耗电力)、高空间密度(9P/机柜)等特性,磁带技术广泛应用于数据备份、数据归档、异地备援等方面。
本项目采用 LTFS 磁带文件系统技术,构建 HDFS 磁带存储资源池。LTFS 格式是由全球网络存储工业协会(SNIA)标准化的自描述的媒体格式,该 LTFS 格式是包含定义格式的文件的剩余部分头部中的自描述的媒体格式。标头包含有关数据数组,文件元素和属性以及元数据使用的说明。
LTFS 卷有两个或多个分区,在 IBM Spectrum®归档程序始终使用以下两个分区:数据和索引。数据分区包含所有数据和元数据。索引分区包含数据分区和元数据中的数据子集。所有分区都从 VOL1 开始。首先使用 XML 标头信息写入分区,然后再写入文件数据和元数据。所有元数据都放在文件标记之间。
LTFS 卷使用标准的 POSIX(便携式操作系统接口)文件操作,从而允许挂载 LTFS,而无需访问其他信息源。LTFS 在操作系统级别工作,可以将 LTFS 文件写入和读取 LTFS 卷,然后仅使用该卷中写入的信息在其他站点和应用程序之间传递。该体系结构的目标允许 LTFS 可以通过非专有或替代的数据管理和归档解决方案进行寻址。
LTFS 支持 LTO 带机和 IBM 企业级带机,支持 IBM 入门级的 TS2900 和企业级的 TS4500 带库。

HDFS 磁带存储资源池由多个 data node 节点组成,每个 data node 则是由节点服务器和带库组成。节点服务器采用 IBM 的 HSM 技术, HDFS 块文件以存根文件(stub file)的形似存储在节点服务器上,HDFS 块文件可以通过存根文件进行检索文件大小等属性。带库连接节点服务器,为 HDFS 块文件提供 LTFS 格式的存储空间。节点据服务器一般带有少量的本地磁盘,提供数据缓存服务。HDFS 客户端写数据时,数据通常先缓存在节点服务器的本地磁盘上,然后由迁移服务把数据迁移至位于带库的磁带中。HDFS 客户端读数据时,节点服务器首先通过存根文件实时召回位于磁带上的数据回本地磁盘缓存中,然后 HDFS 客户端读取位于本地磁盘缓存中的数据。由于采用 HSM 技术,磁带存储资源池支持随机读文件和批量预读文件的功能。
HDFS 多介质存储架构如下:
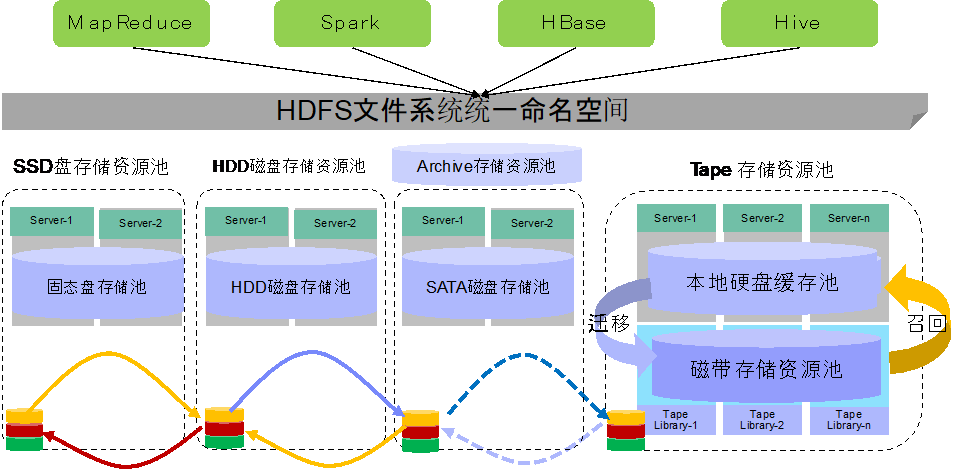
基于磁带顺序读写的特点,建议 HDFS 磁带存储资源池独立建 HDFS 集群。现有的 HDFS 的自动迁移的存储策略不适合于 HDFS 磁带存储资源池;磁带资源池和其他的存储资源池之间的数据同步需要采用 HDFS 集群间数据拷贝的方式进行。
和传统的 Hadoop 部署架构一样,连接磁带介质的数据节点用来存储数据,节点连接接入交换机,同时通过 FC 光纤直接连接带库(也可以通过以太网交换机连接)。HDFS 的 Name Node 存储用来 HDFS 文件的索引信息,对外提供统一的命名空间。由于磁带节点的计算负载比较重,一般磁带节点不同时提供计算服务。
整个 Hadoop 的部署架构如下:
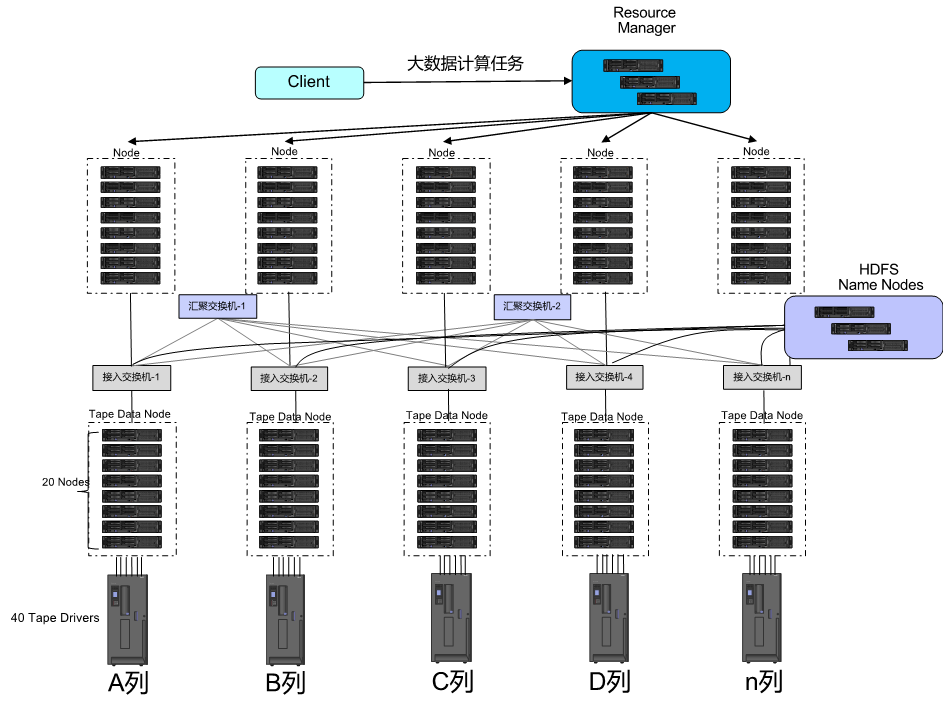
大数据计算时 Hadoop 客户端向 Resource Manager 提交一个计算请求,计算节点的 Node Manager 产生若干个计算 task(Map/Reduce),Task 所在的计算节点作为 HDFS 客户端,向 HDFS 文件系统进行读写操作。当向 HDFS 文件系统写数据时,客户端首先向 Name Node 发送一个写文件请求,Name Node 则会检查是否已存在文件、检查权限。若通过检查,直接先将操作写入 EditLog,并返回客户端输出流对象。然后 HDFS 客户端按一定大小进行文件切片,一般大小为 128MB。再后 HDFS 客户端将 Name Node 返回的分配的可写的 Data Node 列表和 Data 数据一同发送给最近的第一个 Data Node 节点,此后 HDFS 客户端和 Name Node 分配的多个 Data Node 构成 pipeline 管道,HDFS 客户端向输出流对象中写数据。HDFS 客户端每向第一个 Data Node 写入一个 packet,这个 packet 便会直接在 pipeline 里传给第二个、第三个…Data Node。每个 Data Node 写完一个块后,会返回确认信息。HDFS 客户端在写完数据后,关闭输输出流。最后 HDFS 客户端向 Name Node 发送完成信号。
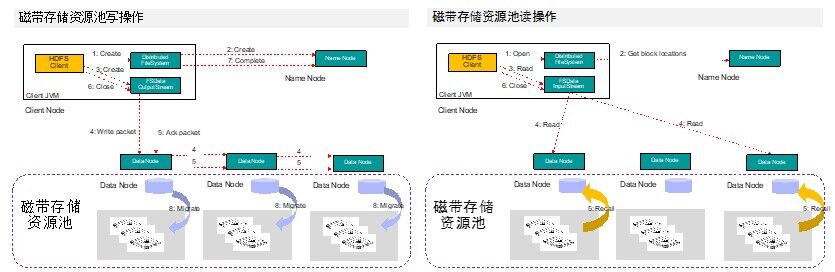
HDFS 磁带存储资源池的写操作比传统的 HDFS 写还多一个异步操作,位于节点服务器的迁移程序会把位于本地磁盘缓存的数据以异步的方式迁移到后端的磁带上,同时创建一个文件的存根文件(Stub file)。
HDFS 磁带存储资源池的读操作比写操作要更复杂。一般 HDFS 读操作时, HDFS 客户端首先访问 Name Node,查询文件的元数据信息,获得这个文件的数据块位置列表,返回输入流对象。然后 HDFS 客户端会就近挑选一台 data node 服务器,请求建立输入流。Data Node 向输入流中中写数据,并以 packet 为单位来校验。最后 HDFS 客户端关闭输入流,数据读取成功。
由于 HDFS 磁带存储资源池的数据真实存储在节点服务器的后端磁带中,Data Node 没有数据可以向输入流中中写。所以 Data Node 在读取服务器上的块文件 Stub file 时,会触发一个 HSM 的 recall 操作,这个操作会自动把位于磁带上的数据复制到本地磁盘缓存中。
整个 HDFS 磁带存储资源池的读写操作流程如下:
随着项目的上线投产,通过对系统的监控,系统单个 Data Node 的写性能能够达到 600MB/s,读性能能够达到 500MB/s。整套系统由多个数据节点和多套带库组成,整套 HDFS 文件系统磁带存储资源池能够提供几十 GB/s 级别的数据吞吐能力和 EB 级别的数据存储能力。
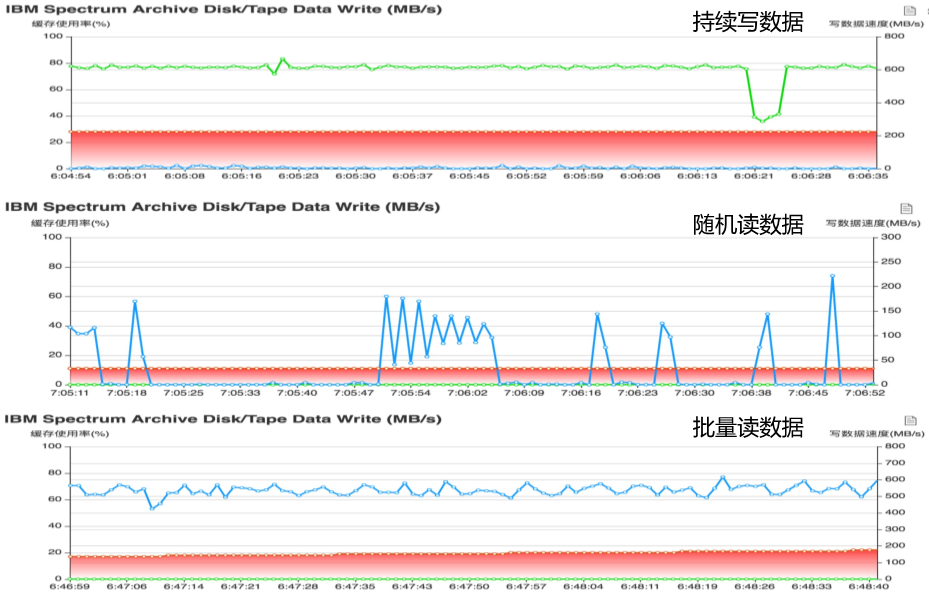
目前整套 HDFS 磁带存储资源池系统支持海量数据的连续写能力,每天可以持续写入的数据多达数 PB。同时系统也支持随机读数据,大数据计算的大批量使用数据,则建议使用批量预读取数据的方式,批量复制磁带上的数据到其他存储资源池后才能使用数据。
项目通过对 HDFS 磁带存储资源池的建设,实现了 HDFS 的内存存储、闪存存储、磁盘存储、磁带存储等多种存储介质的有机整合。在企业层面的统一文件命名空间的前提下,实现了数据在不同存储资源池之间无缝流转。磁带存储资源池极大地提高了 IT 对业务的支持力度,满足了业务的低成本存储需求。相比其他存储介质存储资源池,磁带存储资源池有低成本、低功耗、高空间数据密度,绿色数据中心等特点,极大的降低企业对低频数据归档数据的存储成本。
当然 HDFS 磁带存储资源池建设还处于初级摸索阶段,项目建设过程中也遇到很多困难,踩过很多坑,整套系统还有很多需要完善的地方,在后续项目中会继续优化完善。由于磁带和带库的机械特性,整套系统不足以支持随机高并发数据访问请求,随机读数据性能也不是很高。在 HDFS 磁带存储资源池建设时,需要调研业务的 IO 需求特性,选择合适的使用场景。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论