

本文为“InfoQ x 苏宁 2018 双十一”特别策划系列文章之一。
背景
随着苏宁物流的发展,对网点的整合,很好的强化了苏宁物流最后一公里配送能力,可以在相对短期内整合双方在仓储、干线、末端等方面的快递网络资源,编织一张覆盖最后一公里的密织高效网络,整合完成将极大地强化苏宁物流最后一公里配送能力,提高配送效率,降低运营成本。
其中物流移动端在仓储,干线和末端等各个环节都扮演一个非常重要的角色,然而移动端的用户和我们一般的移动互联网用户有相同的地方也有很大区别,首先物流移动端的用户基本上是我们处在一线的操作人员,界面的交互和服务的响应速度直接影响用户的作业速度。另外移动互联网用户一般是手机,而物流移动端的用户包括手机和手持码枪,这就对我们移动应用提出了更高的要求,不仅仅要具有手机的灵活性还要有手持的实用性。最后随着 3G,4G 的普及移动互联网用户手机联网性普通很好,但是我们的一线作业人员可能处在仓库的角落,信号的盲区,这就要求我们的应用不仅要在有信号的情况下可以作业,在无信号的状态下也可以正常作业。
为了实现各大区网点不能满足实时的网络交互环境的情况下正常作业,这就要求我们操作终端多向前走一步,同时能满足各网点无论在网络环境好坏的情况下都能完成作业。如果满足这些条件就需要本来在服务端处理的数据下载到码枪,在码枪本地本地进行校验处理,服务器的主数据量在都在万级以上,最大的一张表数据在百万级,而正常作业下我们用的码枪都是安卓系统,运行内存在 2G,4G,有的码枪甚至处理内存在 1G。如果通过对码枪的更新换代可以更换性能更好的码枪,但是这种成本是巨大的 ,所以通过对技术上的实现去节省成本和增加用户体验是我们苏宁物流要首当其冲面对的问题。
我们的解决方案
一、数据处理实际逻辑
通过网络下载 txt 文件
按行读取每行字符串文本
采用 String.split 函数按照指定的格式分割字符串为字符数组
通过字符数组组装 Entity 数据类,讲数据类添加到 List 里缓存
判断 List 的 Size 大小,达到 3000 条后调用 Greendao 方法启动线程开启事务批量插入,清空 List 继续循环
未达 3000 条继续循环走 2 流程
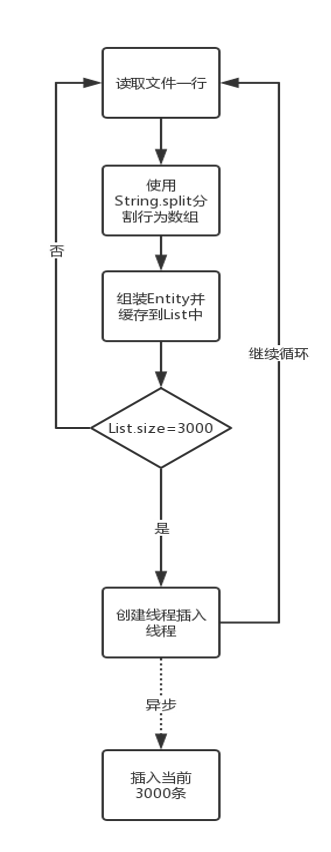
图 1、数据处理逻辑流程
二、性能瓶颈分析
使用 TraceView 找到性能的瓶颈,TraceView 是 Android SDK 中内置的一个工具,它可以加载 trace 文件,用图形的形式展示代码的执行时间、次数及调用栈。
生成 trace 文件有三种方法:
使用代码
使用 Android Studio
使用 DDMS
图 2、开始 trace

图 3、写入到 trace 文件
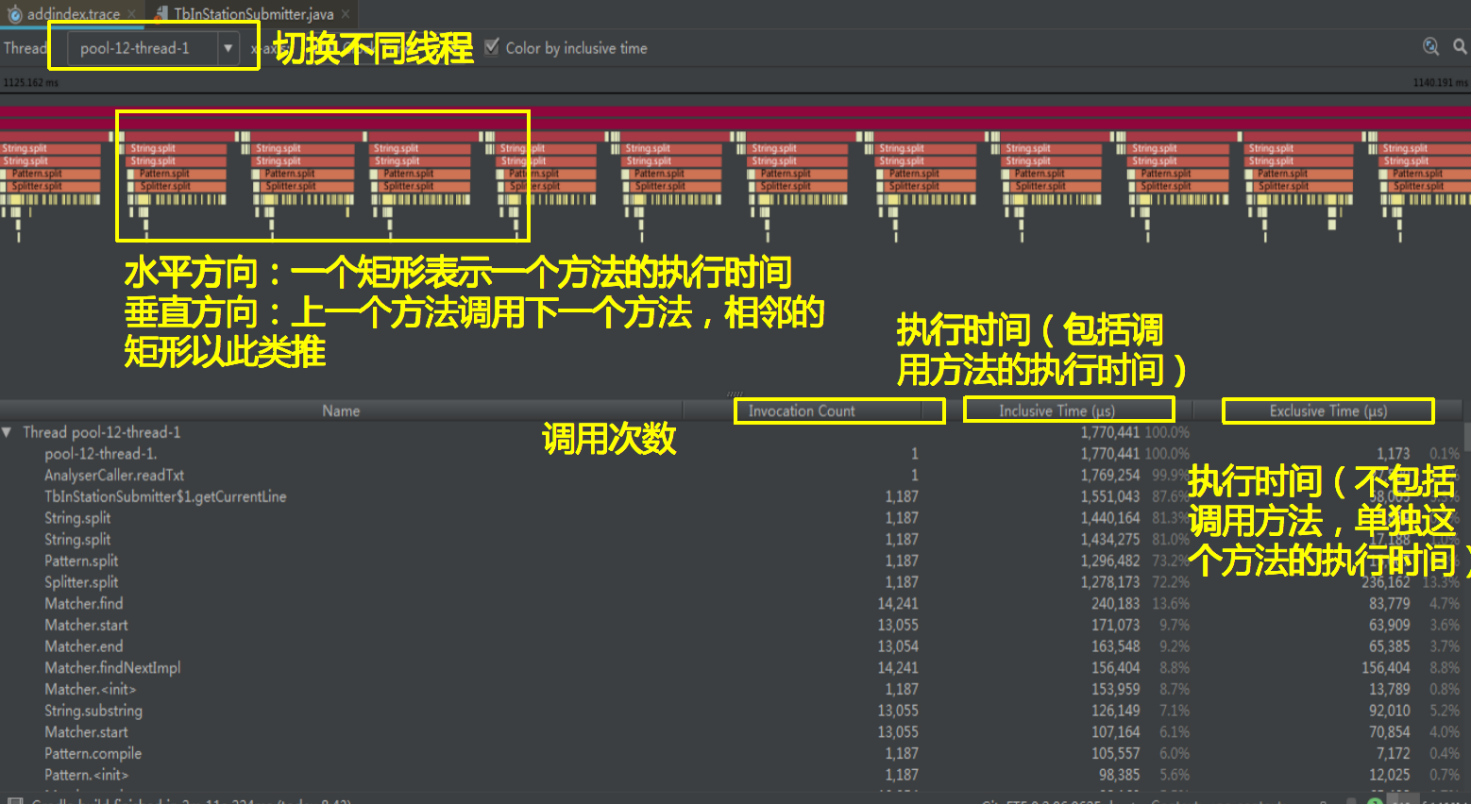
图 4、执行耗时分析

图 5、函数耗时分析
通过 TraceView 分析,另外结合代码分析总结出几个性能瓶颈
String .split 采用正则匹配,大数据量效率低
读文件比较耗时,如果数据库速度大于文件读取速度,则会等待文件读取
插入数据库也比较耗时,如果插入速度小于文件读取速度,则文件读取会阻塞等待
每次使用 GreenDao 开启线程,没有限制最大线程数,开启大量线程,导致数据库连接数超出上限,极易 OOM
另外,通过代码日志分析得出,Entity 没有重用,每次循环创建新的 Entity,导致内存不足,频繁耗时 GC,界面卡顿。
三、解决方案:
针对 Spilt 的优化:重写了 String.split 的实现方式,采用效率更高的 index 方式代替原来的正则匹配,依据业务特点固定了分割数目
针对对象没有重用的优化:采用动态事务,在事务中采用单条连续插入数据库,操作避免创建多余对象,达到指定数量后一起 Commit 到数据库
单次提交数量优化:经过多次测试,统计出单次提交 12000 条为效率最高的提交量
针对相互等待问题:采用阻塞队列,对象池方式减少等待
具体流程图如下:
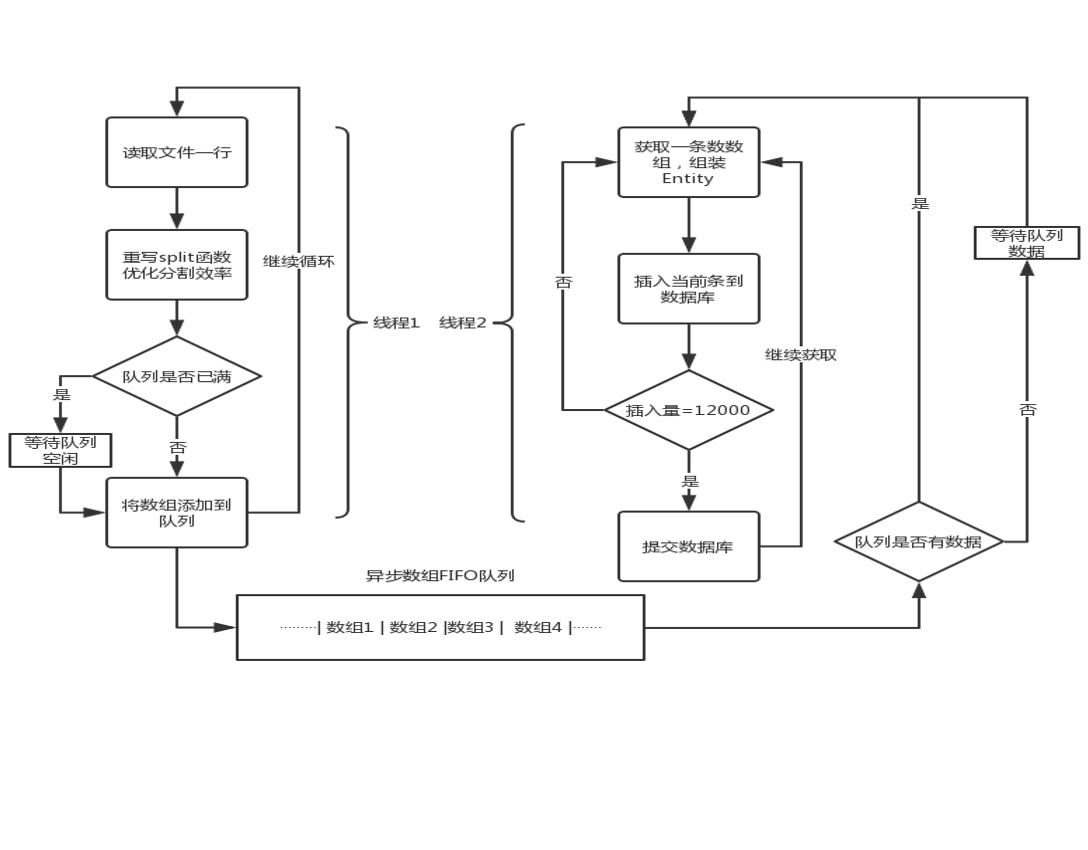
图 6、优化流程图
四、结果对比:
通过测试的对比可以发现,同样的数据,合理匹配文件的读写速度和数据库的读写速度,减少等待间隔。
在单次 8000 量的时候 ,速度可以比原来缩减 3 分 40 秒,
在单次 10000 量的时候可以比原来缩减 3 分 50 秒,
在单量 15000 量的时候可以缩减 3 分 50 秒左右,
在单次 12000 量的时候可以缩减 3 分 57 秒。
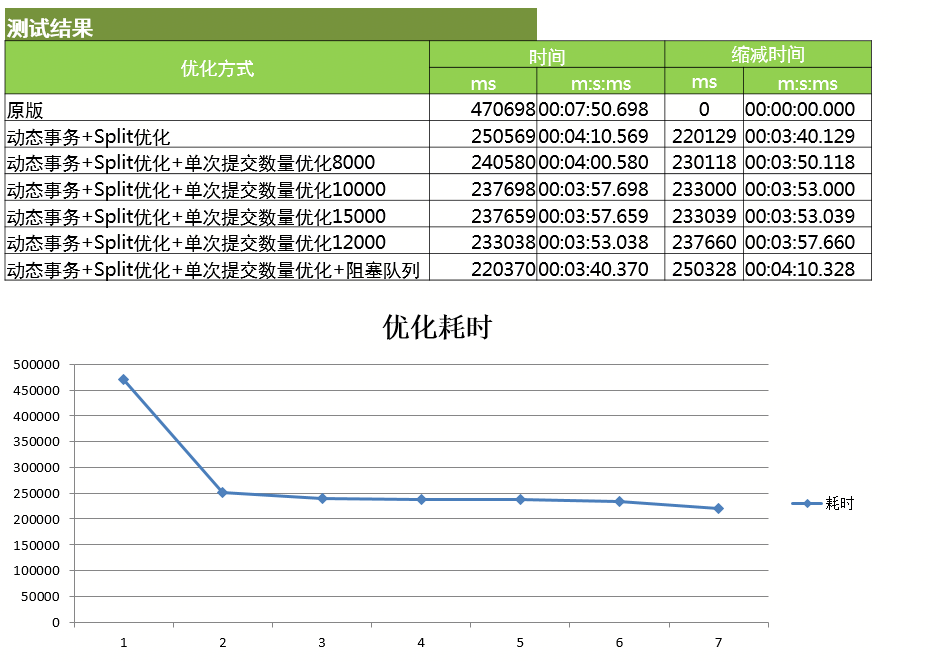
图 7、优化对比
五、优化方案+
完成的上步之后,虽然性能上有了很大的提升,但是为了给一线的苏宁物流用户提供更优的用户体验,我们想到了优化方案+。
1. 传统 Rollback Journal
SQLite 实现 原子性提交和回滚操作 的默认方法是 rollback journal。当对 DB 进行写操作的时候,SQLite 首先将准备要修改部分的原始内容(以 Page 为单位)拷贝到“回滚日志”中,用于后续可能的 Rollback 操作以及 Crash、断电等意外造成写操作中断时恢复 DB 的原始状态,回滚日志存放于名为“DB 文件名-journal”的独立文件中。对原始内容做备份后,才能写入修改后的内容到 DB 主文件中,当写入操作完成,用户提交事务后,SQLite 清空 -journal 的内容,至此完成一个完整的写事务。
Rollback 模式中,每次拷贝原始内容或写入新内容后,都需要确保之前写入的数据真正写入到磁盘,而不是缓存在操作系统中,这需要发起一次 fsync 操作,通知并等待操作系统将缓存真正写入磁盘,这个过程十分耗时。
除了耗时的 fsync 操作,写入 -journal 以及 DB 主文件的时候,是需要独占整个 DB 的,否则别的线程/进程可能读取到写到一半的内容。这样的设计使得写操作与读操作是互斥的,并发性很差。
2. WAL 模式的应用
WAL 模式则改变了上述流程,写操作不直接写入 DB 主文件,而是写到“DB 文件名-wal”文件(以下简称“-wal”)的末尾,并且通过 -shm 共享内存文件来实现 -wal 内容的索引。读操作时,将结合 DB 主文件以及 -wal 的内容返回结果。由于读操作只读取 DB 主文件和 -wal 前面没在写的部分,不需要读取写操作正在写到一半的内容,WAL 模式下读与写操作的并发由此实现。
WAL 写操作除了上面的流程,还增加了一步:Checkpoint,即将 -wal 的内容与合并到 DB 主文件。 由于写操作将内容临时写到 -wal 文件,-wal 文件会不断增大且拖慢读操作,因此需要定期进行 Checkpoint 操作将 -wal 文件保持在合理的大小。Checkpoint 操作比较耗时且会阻塞读操作,但由于时效性要求较低,遇到堵塞可以暂时放弃继续 DB 读写操作,不至于太过影响读写性能。SQLite 官方默认的 Checkpoint 阈值是 1000 page,即当 -wal 文件达到 1000 page 大小时,写操作的线程在完成写操作后同步进行 Checkpoint 操作;Android Framework 的 Checkpoint 阈值是 100 page。
基于 WAL 的基本工作方式,做额外的两个优化点:
写入 -wal 文件时不进行 fsync 操作,因为 -wal 文件损坏只影响新写入的没 Checkpoint 部分数据而非整个数据库损坏,影响相对小;
将需要进行 fsync 的 Checkpoint 操作放到独立线程执行,让写操作能尽快返回。
结束语
物流行业快速发展的今天移动端在作业中的占比量越来越大,苏宁物流一线的作业人员的手持数量每年也在呈几何倍数上涨,在苏宁物流移动端速度发展的这些年,我们从老的黑白机到现在的智能安卓机,从传统过渡到移动互联网和正在进行的智能化,我们一直坚持用技术为一线作业人员减轻作业负责,提升作业效率,在这种大环境下对我们苏宁物流来说是压力也是机遇,不忘初心,砥砺前行,始终不忘造极,以极客的精神打造极致的用户体验。
作者:李健普,苏宁易购物流研发中心移动端开发工程师,负责物流移动端的开发工作,曾负责开发了快递,分拨,仓库,售后等客户端 ,具有较丰富的移动开发经验,对物流作业相关设备开发经验丰富。

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 11 条评论