

作者: Wesley Du, Junwei Deng, Kai Huang, Shan Yu and Shane Huang
作者是英特尔人工智能和分析团队的解决方案架构师,该团队一直致力于 BigDL 的开发。数据科学家和数据工程师可以使用 BigDL 轻松构建端到端的分布式 AI 应用。
介绍
Ray是一个能够非常快速和简单地去构建分布式应用的框架。BigDL是一个在分布式大数据上构建可扩展端到端 AI 的开源框架,它能利用 Ray 及其本地库(Native Libraries)来支持高级 AI 用例,如 AutoML 和自动时间序列分析。
在这篇博客中,我们将介绍 BigDL 中的一些核心组件和展示 BigDL 如何利用 Ray 及其本地库来构建底层基础设施(例如 RayOnSpark、AutoML 等)以及这些将如何帮助用户构建 AI 应用(例如使用Chronos 进行自动时间序列分析)。
RayOnSpark:在 Apache Spark 上无缝运行 Ray 程序
Ray 是一个开源分布式框架,允许用户轻松高效地运行许多新兴的人工智能应用,例如深度强化学习和自动化机器学习。BigDL 通过 RayOnSpark 可以将 Ray 无缝集成到大数据预处理流水线中,并已经在一些特定领域构建了多个高级的端到端 AI 应用(例如 AutoML 和 Chronos)。RayOnSpark 在基于 Apache Spark 的大数据集群(例如 Apache Hadoop* 或 Kubernetes* 集群)之上运行 Ray 的程序,这样一来在内存中的 Spark DataFrame 可以直接传输到 Ray 程序中用于高级 AI 应用。因此借助 RayOnSpark,用户就可以在生产环境现有的大数据集群上直接尝试各种新兴的人工智能应用。此外,RayOnSpark 能将 Ray 的程序无缝集成到 Apache Spark 数据处理的流水线中,并直接在内存中的 DataFrame 上运行。
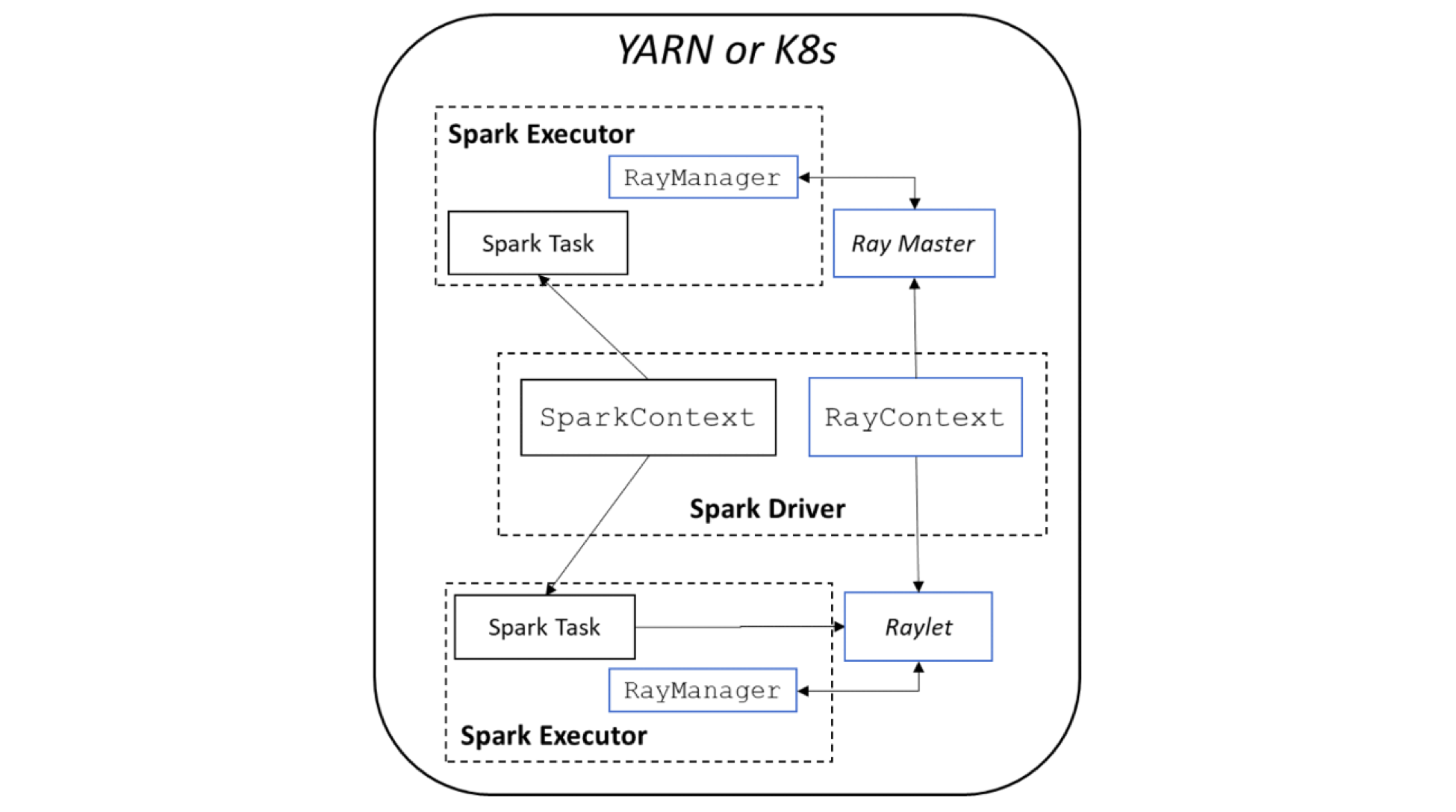
图 1:RayOnSpark 架构
图 1 展示了 RayOnSpark 的架构。在 Spark 的实现中,Spark 程序会在 driver 节点上创建 SparkSession 对象,其中 SparkContext 会负责在集群上启动多个 Spark executors 以运行 Spark 任务。在 RayOnSpark 中,在 Spark driver 节点上会额外创建一个 RayContext 对象,该对象会在同一集群中伴随每个 Spark executor 一起自动启动 Ray 进程。RayContext 同时会在每个 Spark executor 内部创建一个 RayManager 来管理 Ray 进程(例如,在程序退出时自动关闭进程)。下面的代码块演示了用户如何在初始化 RayOnSpark 后,直接在标准 Spark 应用程序中编写 Ray 代码。
图 2:RayOnSpark 的示例代码
AutoML (orca.automl):使用 Ray Tune 为 AI 应用程序轻松调参
在机器学习或深度学习模型的准确性、性能等方面,超参数优化 (HPO) 对于数据科学家实现其目标非常重要。但是手动对超参数进行调优可能十分耗时且结果也并不能令人满意。与此同时,分布式超参数优化编程也是一个具有挑战性的工作。Ray Tune 是一个用于深度学习可扩展的超参数优化框架。BigDL 引入了构建在 Ray Tune 之上的 AutoML 功能(orca.automl),可以让数据科学家的工作更轻松。
orca.automl 介绍
很多情况下,数据科学家更愿意在笔记本电脑上对他们的 AI 应用程序进行原型设计、调试和调参,如果可以将相同的代码完整地迁移到集群中并直接运行,这将大大提高端到端的生产力。
BigDL 的 Orca 项目可帮助用户将他们的代码从笔记本电脑无缝扩展到大数据集群。此外,BigDL 的 orca.automl 充分利用了 RayOnSpark 和 Ray Tune,提供了一个名为AutoEstimator的分布式超参数调优 API 。得益于 Ray Tune 与框架无关的特性,AutoEstimator 同时适用于 PyTorch 和 TensorFlow 模型。用户可以在他们的笔记本电脑、本地服务器、K8s 集群、Hadoop/YARN 集群等上,用一致的方式对他们的模型进行调参。
凭借这些特性,BigDL 中的 orca.automl 可用于许多 AI 应用的自动化调优(包括模型、超参数等)。例如,我们使用 BigDL 的 orca.automl 实现了 AutoXGBoost(XGBoost with HPO)用以自动拟合和优化 XGBoost 模型。相比 Nvidia A100 上的类似解决方案,使用 AutoXGBoost 的训练速度提高了约 1.7 倍,最终模型更加准确。
设计细节,可参阅orca.automl User Guide
实际操作,可参阅AutoXGBoost Quick Start 或者 Auto Tuning for arbitrary models
Chronos:在 Ray 上使用 AutoTS 构建自动时间序列分析
我们还开发了一个为自动时间序列分析的应用框架,称为 Chronos。它基于 orca.automl 在自动分析期间进行超参数优化。
为什么我们需要 Chronos?
时间序列(TS)分析现在被广泛的应用于各个领域(例如电信中的网络质量分析、数据中心运营的日志分析、高价值设备的预测性维护等),并且变得越来越重要。在最为常用的预测与检测领域,传统统计学方法在准确性与灵活性上都面临巨大的挑战,深度学习方法通过将时间序列任务视为序列建模问题,在多个领域获得了成功。
但在另一方面,为时间序列预测/检测构建机器学习应用程序可能是一个费力且需要很多专业知识的过程。超参数设置、预处理和特征工程都可能成为影响深度学习模型表现的瓶颈。为了提供一个高效、强大且易用的时间序列分析工具箱,我们推出了 Chronos,这是一个用于构建大规模时间序列分析应用程序的框架。它可以使用 AutoML 并进行分布式训练,因为它建立在 Ray Tune、Ray Train 和 RayOnSpark 之上。
Chronos 架构介绍
Chronos 具有多个 (10+) 用于时间序列预测、检测和模拟的内置深度学习和机器学习模型,以及大量 (70+) 数据处理和特征工程工具。用户可以自己调用独立的算法和模型(预测器(Forecasters), 检测器(Detectors), 模拟器(Simulators))以获得最高的灵活性,或者使用我们高度集成、可扩展和自动化的时间序列工作流 (AutoTS)。推理过程也以多种方式进行了优化,包括集成ONNX runtime。。
下图展示了在 BigDL 和 Ray 之上的 Chronos 架构。本节重点介绍 AutoTS 组件。AutoTS 框架使用 Ray Tune 作为超参数搜索引擎(运行在 RayOnSpark 之上)。在自动数据处理中,搜索引擎为预测任务选择最佳回看值。在自动特征工程中,搜索引擎会从各种特征生成工具(例如,tsfresh)自动生成的一组特征中选择最佳特征子集。在自动建模中,搜索引擎会搜索超参数,例如隐藏层的维度、学习率等等。
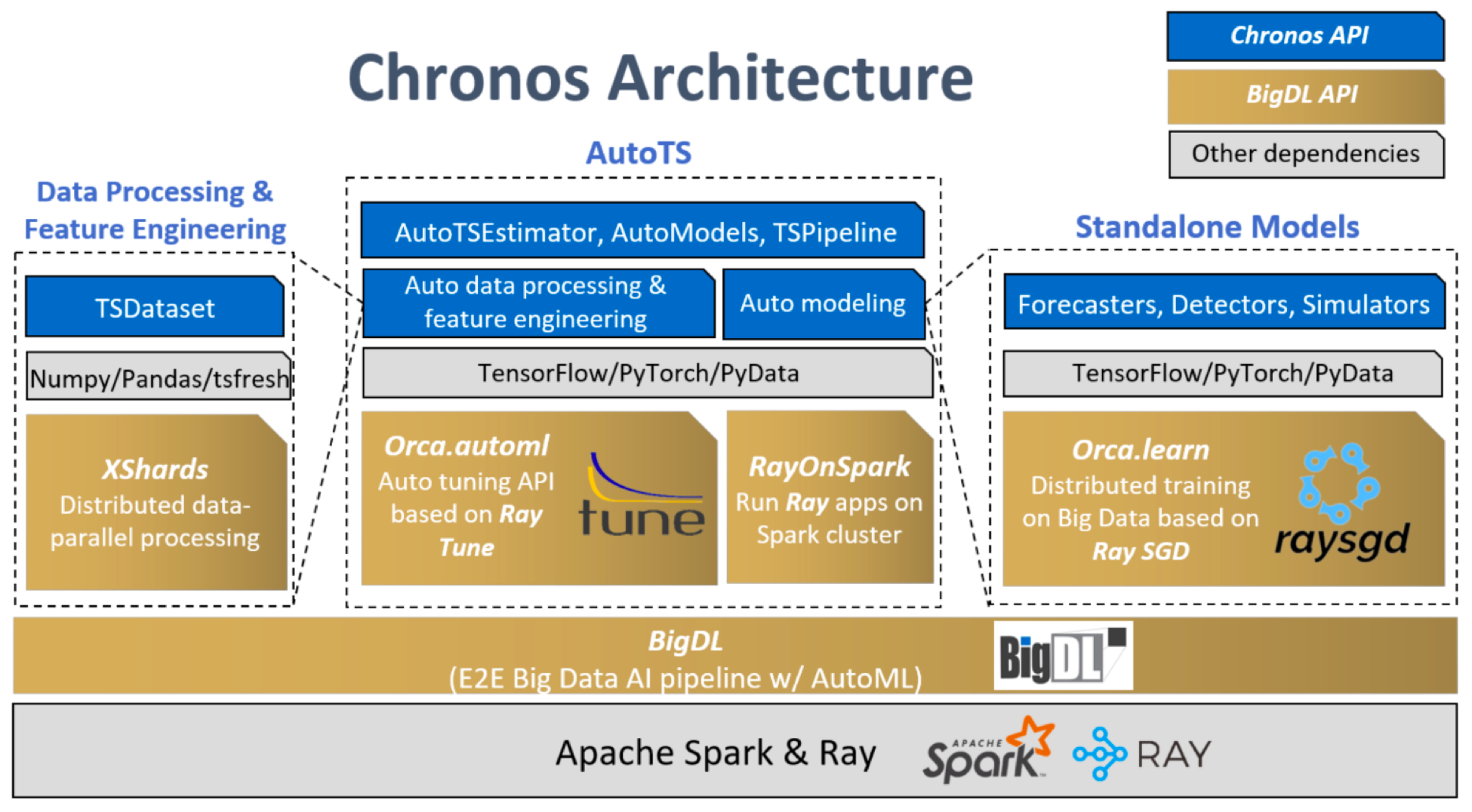
图 3:Chronos 架构
Chronos AutoTS 工作流的实操示例
下面的代码展示了,使用 Chronos 易用且高度集成的 AutoTS 工作流的时间序列预测流水线的训练和推理过程。这个工作流利用 TSDataset 上简单的 API 来执行一些典型的时间序列处理(例如,填充,缩放等)和特征生成。
然后用户可以通过模型名称(model)(内置模型名称/为第 3 方模型创建函数)、回看值(past_seq_len)和预测步数(future_seq_len)来进行初始化 AutoTSEstimator。该 AutoTSEstimator 在 Ray Tune 上运行搜索工序,每运行一次生成多个 trials(每个 trial 具有不同的超参数和特征子集组合),并把 trials 分布在 Ray 集群中。在所有 trials 完成后,根据目标指标检索最佳超参数集、优化模型和数据处理工序,用于组成最终的 TSPipeline。
TSPipeline 可用于预测,评估和增量拟合。
更多详细信息,可参阅Chronos User Guide。
使用 Chronos AutoTS 进行 5G 网络时间序列分析
Chronos 已被广泛应用于许多领域,例如电信和 AIOps。Capgemini Engineering 在其 5G 介质访问控制 (MAC) 中利用 Chronos AutoML 工作流和推理优化来实现认知功能,作为智能 RAN 控制器节点的一部分。在这个项目中,Chronos 用于预测 UE 的移动性,以帮助 MAC 调度程序在 2 个关键 KPI 上进行有效的链路自适应。通过 Chronos AutoTS,Capgemini Engineering 将他们的模型更改为我们内置的 TCN 模型并选用了更加适合的回看值,成功将 AI 准确率提高了 55%。
详细信息请参考白皮书。
结论
在本文中,我们介绍了 BigDL 如何利用 Ray 及其库为大数据构建可扩展的 AI 应用程序(使用 RayOnSpark)、提高端到端 AI 开发效率(在 Ray Tune 之上使用 AutoML)以及构建特定领域的 AI 用例(例如使用 Chronos 进行自动时间序列分析)。BigDL 在其他方面也采用了 Ray,例如 BigDL Orca 项目中正在使用 Ray Train,用以跨大数据集群无缝扩展单节点 Python notebook。我们还在探索其他用例,例如推荐系统、强化学习等,这些将利用在 Ray 上构建的 AutoML 功能。
原文链接:
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论