

目前不管是广告还是推荐业务,最底层的技术都是检索,由于候选集合非常大,可能从千万甚至亿级别取出数十个用户感兴趣的商品。在算力和时间复杂度的约束下,往往采用分阶段漏斗的算法体系。具体来说就是分成召回 ( match ) 以及排序 ( rank )。本文主要介绍阿里在 match 阶段的最新实践——深度树匹配,分成几个部分:
检索召回技术现状
深度树匹配(TDM)技术演进
TDM 业务应用实践
总结与展望
检索召回技术现状
1. 互联网业务中检索召回技术的发展
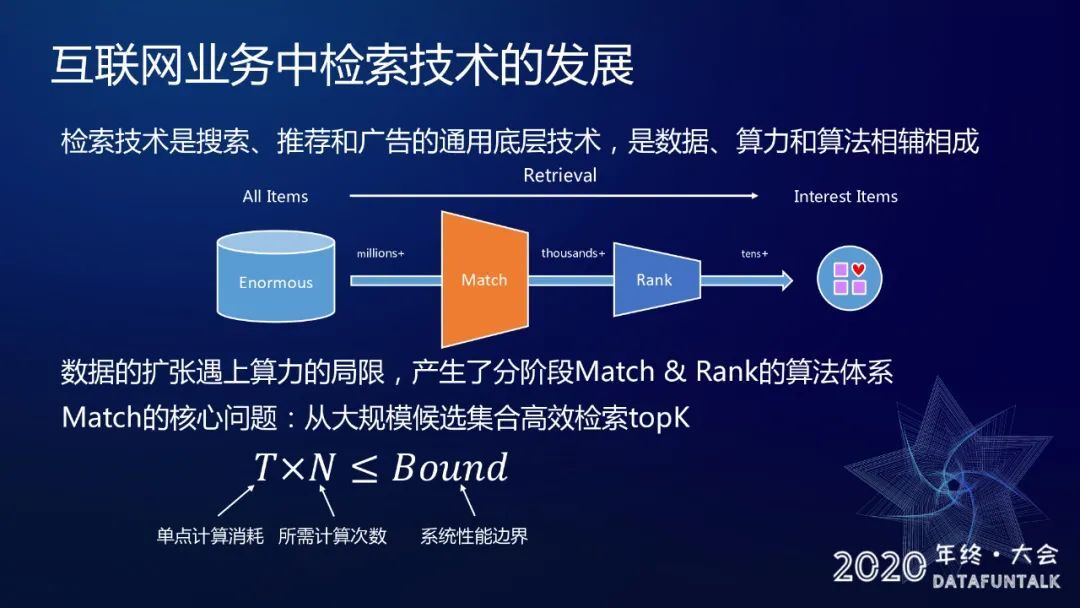
对于 match 这一部分来说,我们的核心问题是要从一个大规模的候选集合里面高效检索出 topK。单点计算消耗和所需计算次数决定了系统性能边界。我们需要在实际设计系统的时候考虑两个平衡,首先是我们的对于每个 item 使用模型打分,有单点计算消耗的约束,从广告库里面解锁商品,有计算次数上限,我们需要保证在现有的系统性能边界下,无论是单点的计算消耗以及所需的计算次数,他们的乘积不能超过这个性能边界。
2. 两段式 Match 的经典实现
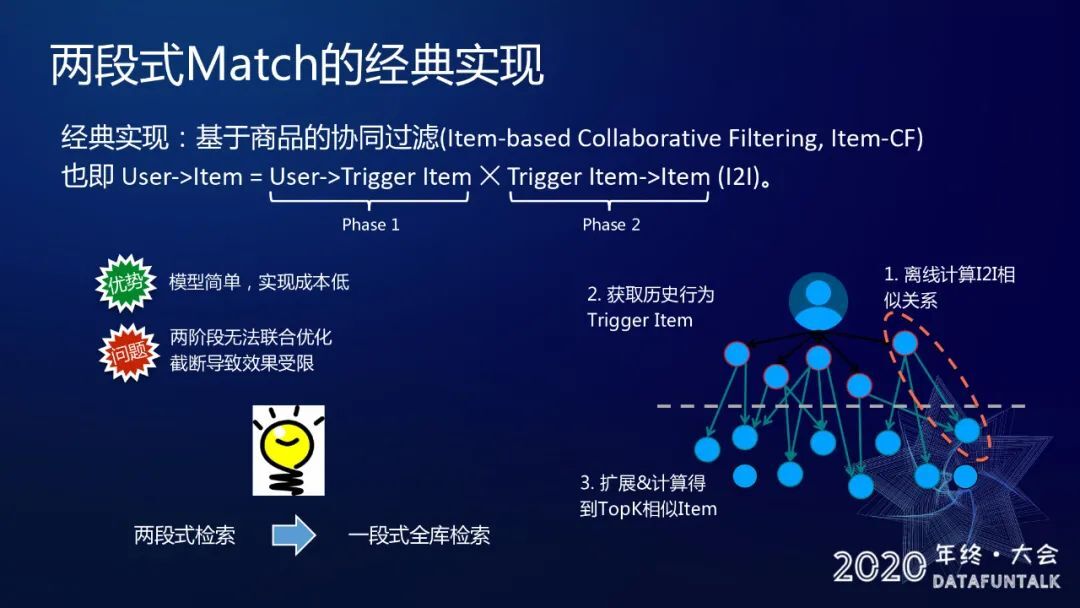
在我们系统里面最早期的是一个经典的两段式 match,例如基于商品的协同过滤,就是说对我们对于每一条用户的请求我们去找到用户历史的 item,然后再通过这些 item 查询离线计算好的 I2I 相似关系表找到我们需要召回的 item,并且最终做合并取 topK。这个方法它的优势在于模型非常简单,而且实现成本非常低,我们所有的迭代只需要在离线计算一份 I2I 表就完成了。但是它的缺点也很明显,因为是一个两段式的召回框架,整个过程是没有办法联合优化的,有一些很多先进的模型,像深度神经网络没有办法很好的应用,导致召回效果受限。一个很自然的想法是我们是否能把这种两段式的检索升级成为一段式,并且对整个全库做一段式检索。
3. 内积模型向量检索
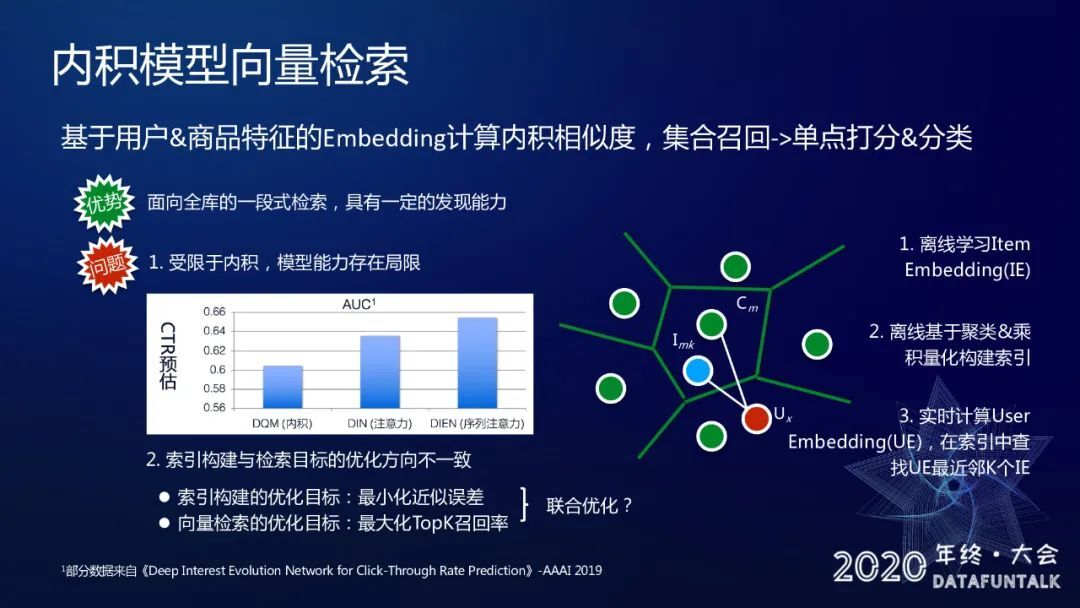
基于上述思路,有一个非常广泛的应用是通过内积模型来做向量检索,具体思路就是我们基于用户以及商品特征的 embedding 去设计一些网络,类似双塔这样的结构,然后根据这些 embedding 去计算内积的相似度,这样就把 match 阶段对候选商品集合召回的问题转化成一个单点打分以及分类这样一个问题。
具体实现是三个阶段:
首先离线训练双塔模型,得到 item embedding;
训练完成之后,对这些 item embedding 做聚类,并且根据乘积量化去构建索引;
在线上使用时,对于每一条用户请求能够计算得到 user embedding,然后在已经构建好的索引里面去进行查找,得到 user embedding 最接近的 K 个 item,作为 top K 的召回。
这样一个流程它的优势非常显然:面向全库一段式检索,从数据里面获取一些发现能力,而不依赖于用户历史行为触发。但是它的缺点也很明显,对于我们使用的模型结构上有一个非常强的约束,就是我们的模型必须是类似双塔这样的结构,最终 user 以及 item 的相似度必须由内积来计算,这样对于模型能力有一个很大的局限。我们有过好几版升级,最早是类似双塔这样的內积模型,接下来是 DIN 和 DIEN,分别是把 attention 的机制引入了 CTR 预估问题里面,如果我们只看 auc 的话,引入 user 和 item 之间的交互模型的性能有一个比较大的提升。这里面启发我们一个自然的思考,如果我们想要把更加先进的模型引入到 match,那么我们应该怎么做?第二个问题是我们在向量检索模型里离线做索引构建的时候,它的目标与我们在线上使用的时候检索目标是完全不一致的,离线索引构建的时候优化目标是最小化 embedding 近似误差,但是实际上线上想要的是最大化 topK 召回率,彼此之间有 missmatch,所以一个很自然的想法,我们是否能够把这两点统一起来联合来优化,然后这启发了我们去做深度树匹配召回这件事情。
深度树匹配(TDM)技术演进
模型能力的升级需要相应的索引结构升级来支持,我们需要设计一个通用的索引结构,使得能够支持任意复杂的模型来做召回。对于 user 和 item 之间复杂交互,如果不依赖双塔这样的模型结构,我们需要什么样的索引结构?
首先,想到散列表,但是散列表同样基于距离度量,融合先进模型比较困难。加入选择图的话,对于模型结构没有任何要求,但是图的一个问题就是它结构非常复杂,并且在图上做检索很难有确定性的检索次数的控制,会存在指数爆炸的问题,所以我们最后选择了树。树的结构相对简单,可以通过控制树的层高来控制检索次数。
1. 深度树匹配的提出
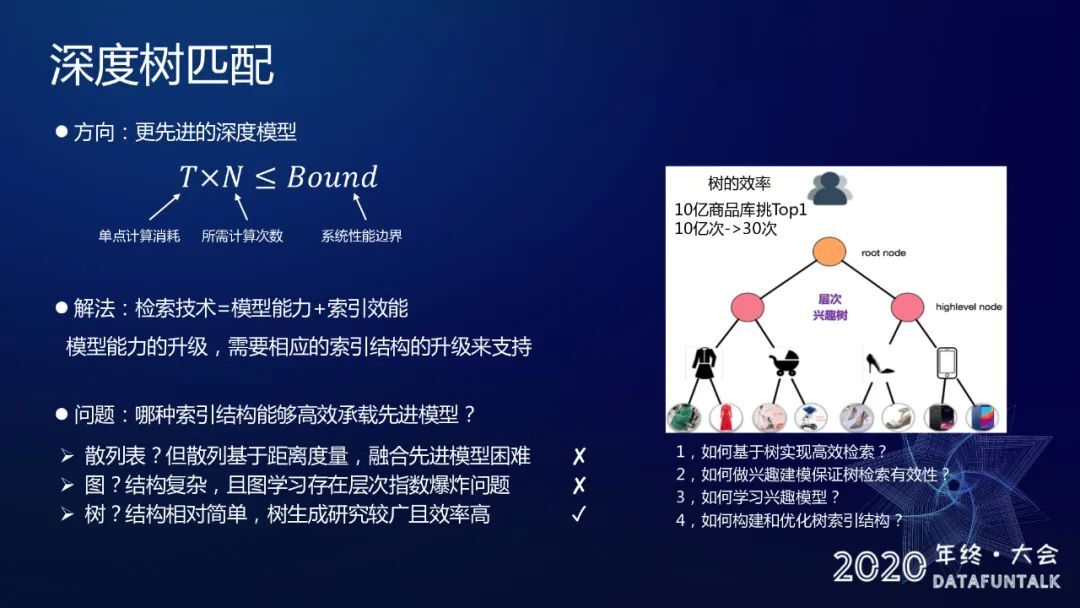
我们提出了深度树匹配这样一套技术,它的基本想法就是我们把所有 item 商品库聚合成为一个层次的兴趣树,把从商品库里面的检索转换成一个在树上做检索的过程。比如说是一个二叉树,由于树的特性,我们能把从十亿商品库里面挑商品的问题转化成在树上做 30 层的检索问题,这样的话计算次数就会大大减小。
虽然有这样一个想法,但是我们后续需要解决非常多的问题:
如何基于树实现高效检索
如何做兴趣建模保证树检索的有效性
如何学习兴趣模型
如何构建和优化树索引结构
2. 基于树的高效检索方法—Beam Search
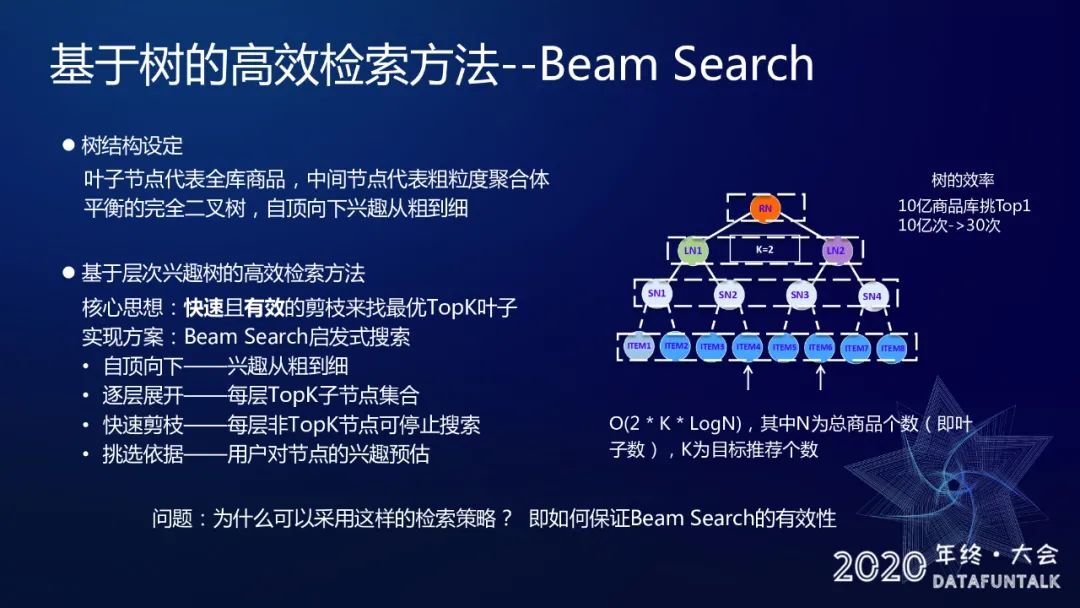
我们让叶子节点表示全部商品,中间节点表示商品的粗力度的聚合,比如是对于兴趣的聚合,这样的话我们通过构建一个完全平衡二叉树就能够保证这棵树自顶而下的兴趣划分是从粗到细的。在这棵树上就能够通过 Beam Search 实现一个启发式检索的方法来找 topK 叶子节点,它的时间复杂度是 logN, N 是总的商品个数,计算性能是符合线上开销的,那么一个很自然的问题就是怎么保证这样的检索出的就是全局最优?
3. 最大堆树:支持 Beam Search 检索的兴趣建模
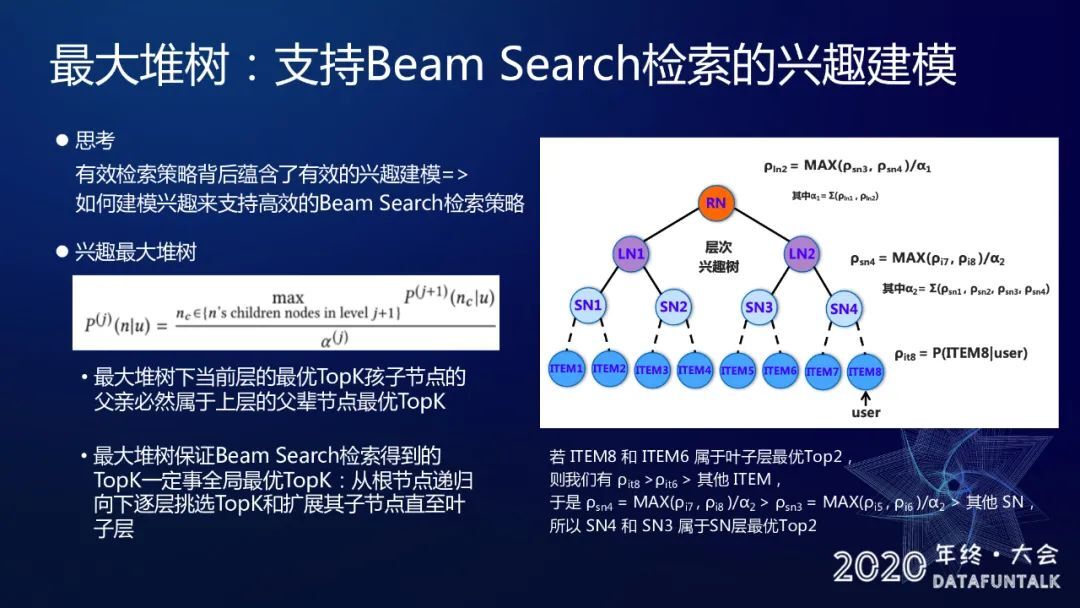
我们提出了一套方案,要求模型保证用户的兴趣分布必须服从最大堆的性质
最大堆树下当前层的最优 TopK 孩子节点的父亲必然属于上层的父辈节点最优 TopK;
最大堆树保证 Beam Search 检索得到的 TopK 一定是全局最优 TopK:从根节点递归向下逐层挑选 TopK 和扩展其子节点至叶子层。
4. 最大堆树的模型学习
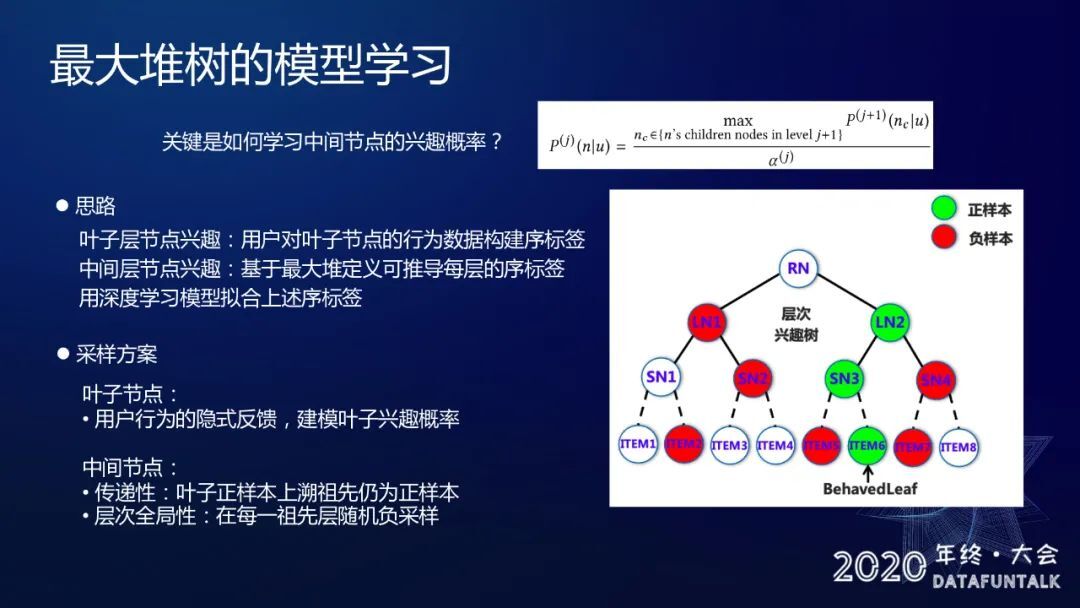
如何学习中间节点的兴趣概率?
叶子层节点兴趣:用户对叶子节点的行为数据构建序标签
中间层节点兴趣:基于最大堆定义可推导每层的序标签
用深度学习模型拟合上述两个序标签
采样方案:
叶子节点:用户行为的隐式反馈来建模叶子节点的兴趣概率
中间节点:
传递性:叶子正样本上溯祖先仍为正样本
层次全局性:在每一祖先层随机负采样
5. TDM1.0:容纳任意先进模型
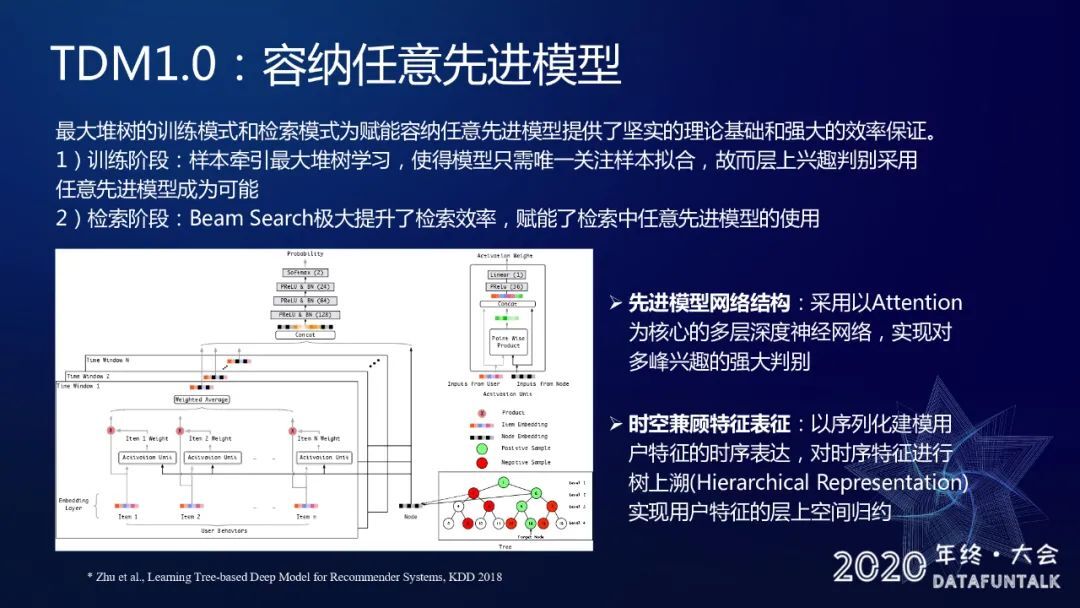
最大堆树的训练模式和检索模式为容纳任意先进模型提供了坚实的理论基础和强大的效率保证。我们主要做的工作是在最大堆树这样一个约束之下,我们引入了一些更加先进的模型,它跟双塔模型最大的区别在于我们模型里面考虑了用户的特征以及 Item 特征的交叉,它不是一个双塔结构,这里面用户特征简单来说就是用户历史的 Item 行为序列商品特征。商品特征比如商品的 ID,如果是在树里面非叶子层的话,它就是 node 的 ID,在这种模型结构里面,我们把用户的历史行为拆分成一系列时间窗,然后我们在每个时间窗里面做一个基于 Item embedding 的 attention,然后得到最终的 attention 向量。在这种模型结构之下,我们利用到了用户以及 item 之间的交叉信息,所以它的模型能力是比双塔结构强的。
然后在这种情况下,我们在训练的时候就用之前所说的最大堆树学习的方法,把它拆分成 H 层的分类问题,在检索阶段的话,直接用 Beam search,然后对这棵树检索,得到我们最终想要的结果。大概在两年前,我们已经到线上后取得了大概两位数的一个性能的提升。
6. TDM2.0:模型 &索引联合学习

在 1.0 的时候,我们是在给定的一个树的范式之下,只考虑模型的学习,但其实树的结构本身对于我们召回结果有非常大的影响,比如说考虑左下角这样一个例子,在一些女装女鞋男装拿些这样个商品集合里面去构造一棵树,那么在这种情况下,树构造有两种办法,一种是把女装和男鞋做一个聚合,然后把女鞋和男装聚合,但这种方法可以看到它得到的聚合其实是没有什么意义的。一个更加合理的划分方法是把女装和女鞋、男装和男鞋划分到相同的树节点,这样的话对于高层的非叶子节点我们就有一些抽象的含义。所以我们在 2.0 想要解决的问题就是如何对模型以及索引做联合的学习,这个问题抽象出来,其实就像右上角所示。所以在这种情况下,我们整个树模型的学习过程就可以看成是对两项的优化问题。一项是模型的参数,也就是对带权二部图的最大匹配问题,我们用了贪心的算法,最终得到一个分段式树学习算法。这就是我们在 2.0 所做的一些基本事情。
7. TDM3.0:模型 &索引 &检索联合学习
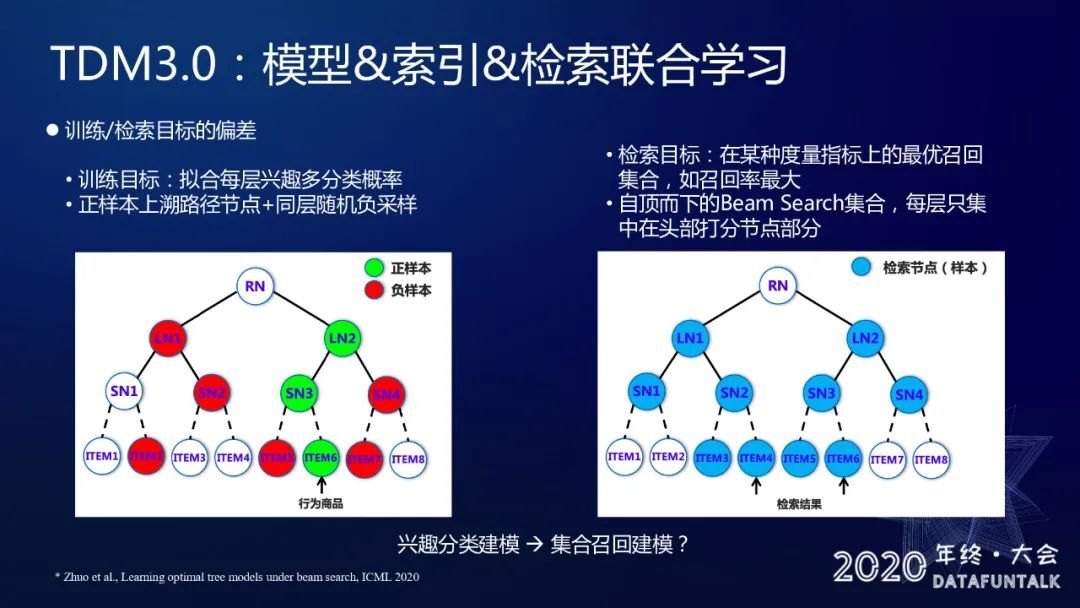
不论是 1.0 还是 2.0 都有一个问题就是训练和检索的目标偏差。训练的目标:拟合每层兴趣多分类的概率。正样本上溯路径节点+同层随机负采样。检索目标:召回率最大,自顶而下的 Beam Search 集合,每层只集中在头部打分节点部分。
一个最典型的例子就是我们在训练的时候,所用到的样本是一部分上述的正样本以及一部分随机采样的。没有考虑到在线上检索的时候,实际上是自顶而下的一个扩展的方式,每层用到的 Item 其实是相对打分比较高的那一部分,这就会导致我们在检索中可能检索到的某些 Item 在训练的时候没有得到充分的训练。我们希望把线上检索的目标以及过程完全考虑到训练中,保证我们离线训练以及线上使用的一致性。这样的话,实际上我们又从兴趣分类建模这件事情重新回到对于集合召回建模这个事情上。为了达到这一点,我们做了以下两件事情。
对检索过程建模:对齐数据分布
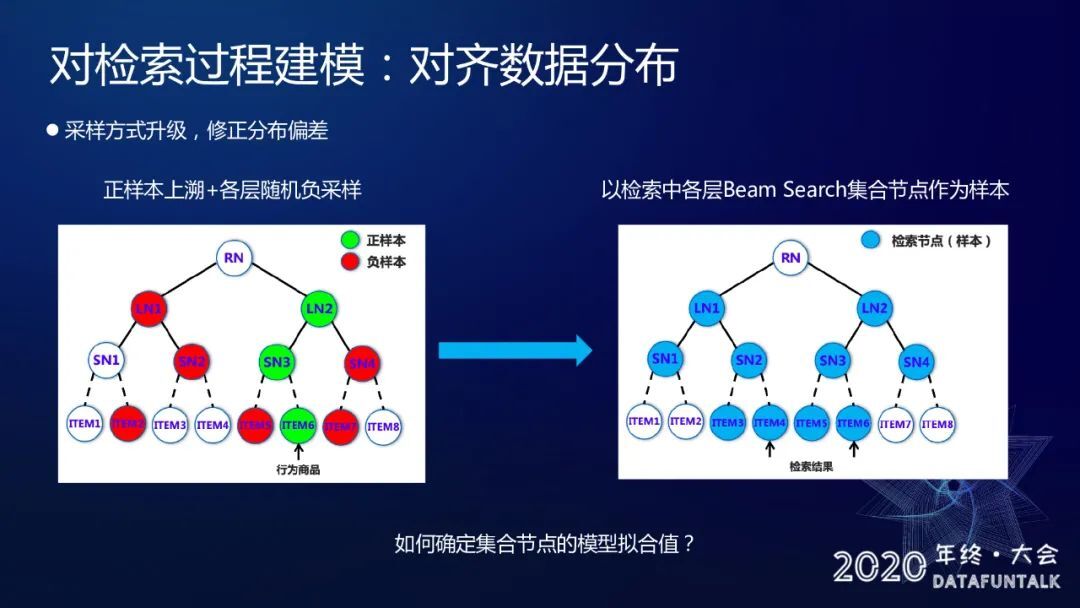
首先第一是我们对采样方式做了一个升级,就是我们不再通过正样本加负样本采样这套方式来构造我们的训练样本,我们直接对我们这棵树做一个 BeamSearch 检索,然后以检索出来的这些 topK 集合作为我们的训练样本。这样我们在离线训练时和在线 Serviceing 的样本产生逻辑以及样本分布是完全保持一致的。
对检索过程建模:对齐训练目标
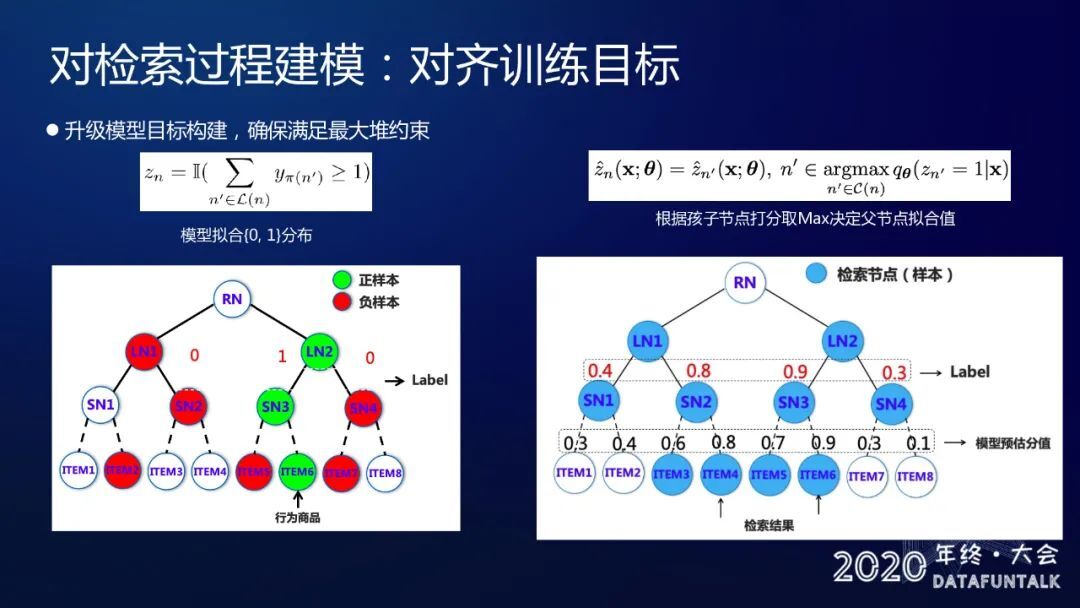
我们做的第二件事情就是说我们对于本身模型学习的目标做了一次改造,确保我们能够满足最大堆约束,也就是保证我们的 BeamSearch 的局部最优一定是全局最优。我们与之前的方法做一个对比,在之前的方法,我们对于节点的标签的设定就是它本身以及它的上溯路径全部标为 1,然后剩下的节点全部标为 0 作为负样本,从里面随机采样作为它的训练样本。我们后来发现这样一个设定方式,其实并不符合最大堆的需求,我们对它做 BeamSearch 得到的 topK 也不是全局的最优。所以我们换了一个样本构建的方式,就如右图所示,比如说这里面蓝色节点都是我们检索到的集合,那么我们对于每个节点的标签,我们不只依赖于本身 item 用户是否点击了这个行为,每个节点的标签还依赖于从它的子节点上溯的标签,以及模型对于它的子节点的一个预估分数。
8. Beam Search 下理论最优的训练范式
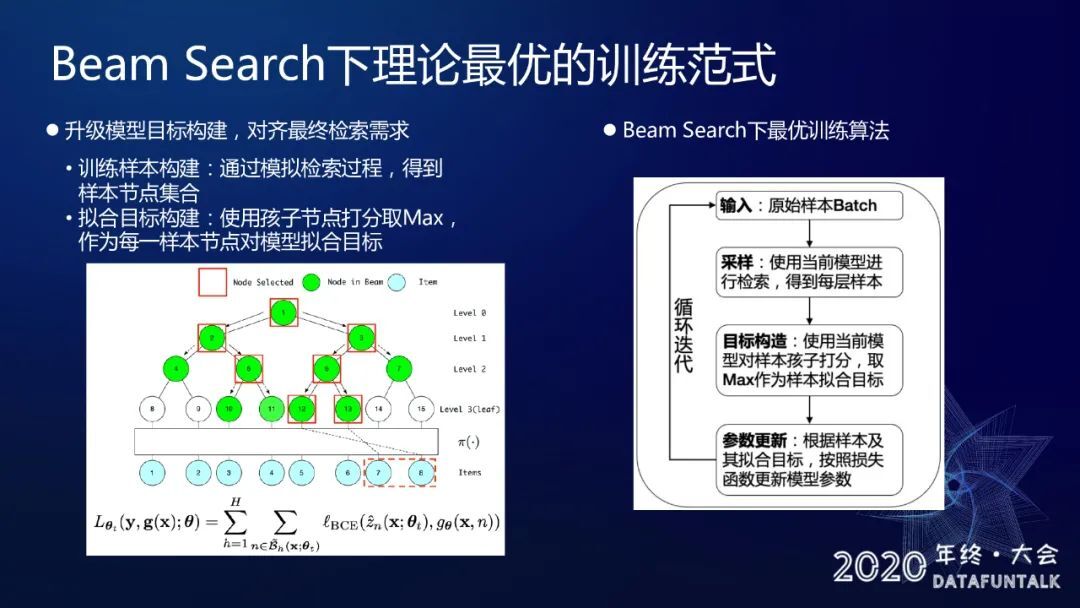
我们做了上述两版升级,就得到了一个在 BeamSearch 下理论最优的一个训练方式,具体来说就是我们以 BeamSearch 来构造我们的样本集合,我们通过基于打分上溯的方式去设计每一层样本的拟合目标,还是一个 H 层的但是存在上下层依赖的这样一个分类问题来做我们的模型的训练。他的训练方法也是一个循环迭代的方式,就是我们输入原始样本的 minibatch,使用当前的模型做一遍采样就是做一 BeamSearch 检索,得到每层的样本,然后采用目标构建的方式,对于这个样本里面的每一个节点得到它的一个模型的标签,得到标签之后类似一个二分类问题设计一个 loss,然后去对参数更新,然后如此反复迭代,直到收敛。
9. TDM 显著性效果
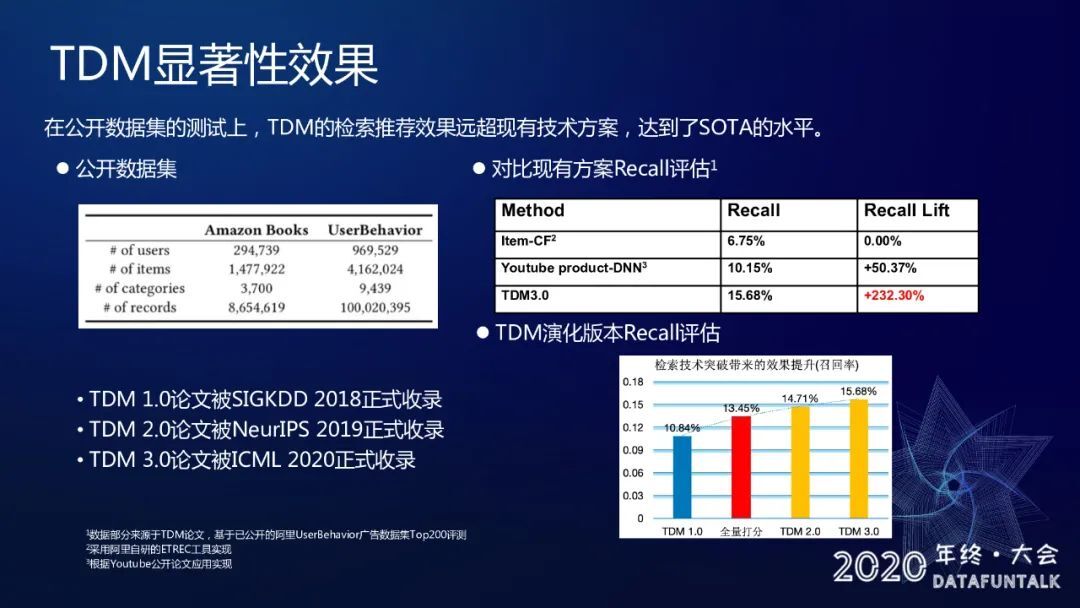
离线的话我们也做了一些公开数据集的测试,可以看到不管是从 1.0、2.0 以及 3.0,它的召回率都有一个显著的涨幅,跟现有的方法,比如说 ITemCF 以及 YoutubeDNN 这两个经典的方法来比,有个非常大的提升。
我们在每个阶段的思考也有一些论文产出,如果大家对具体的细节感兴趣的话,可以参考我们的论文。
10. TDM 在定向广告场景落地实践
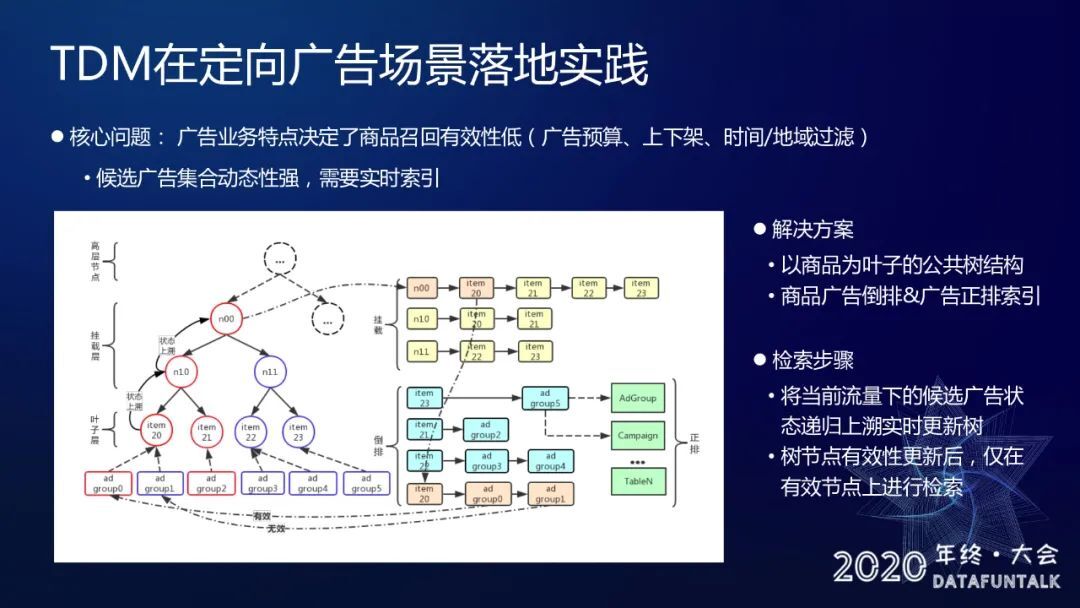
最后,讲一下我们在定向广告场景的一些落地使用,广告业务本身它有非常显著的一个特点,就是我们商品召回的有效性其实比较低的,因为存在广告主的预算是否花光,商品的上下架以及投放的时间的影响。所以这导致了在广告里面,我们候选广告集合它的动态性非常强,但是 TDM 这样的树结构,是一个相对比较静态的结构。所以在实际中我们采用了静态树结构加动态的正排倒排表这样一个实现方式。具体来说就是我们本身这个树的结构是以正常的商品作为叶子,我们在这样的结构之上做了一个实时的商品以及广告的倒排表,以及广告本身的信息做正排表。我们在线上 Servicing 的时候,树结构是保持不变的,我们根据实时的变化去实时更新广告正排倒排表的顺序结构,这样使得整体能够保持一个比较高的召回有效性。
展望
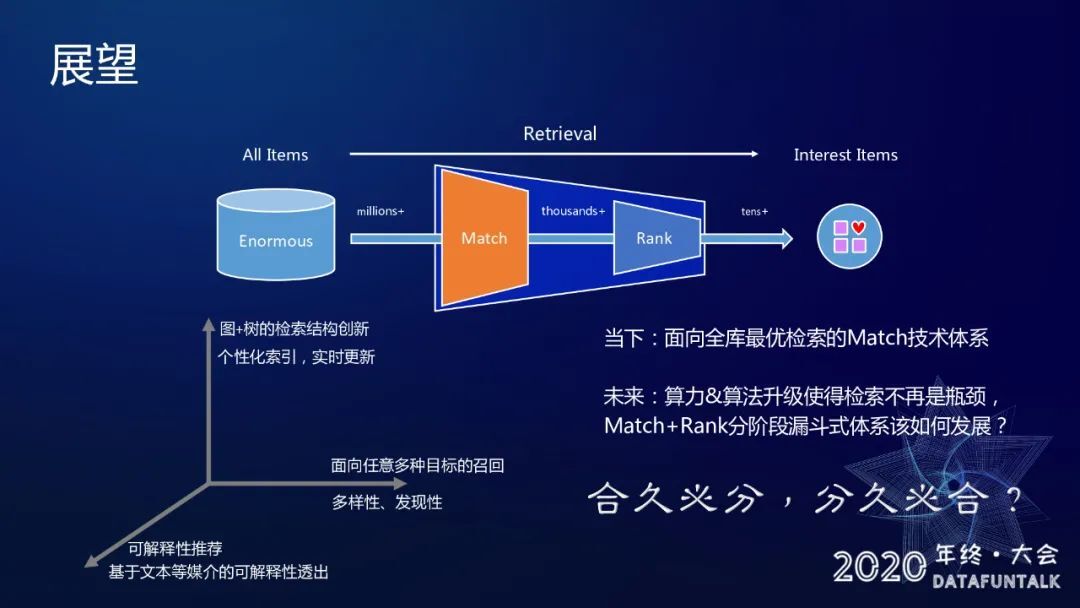
最后是总结与展望,然后我们还是回到我们本身检索这样一个问题,因为算力的约束,导致形成了大家都认可的一个分阶段漏斗的形式,就是把整个检索过程拆分成召回以及 rank 这两个阶段。在后续的话,我们希望也把 TDM 这一套技术把它做得更加扎实一点。大概是三个维度,首先是检索结构上,我们希望利用图对本身树这样一个召回结构做一些近似的扩展,第二我们希望它能够去对多种目标进行召回,比如说多考虑一些多样性发现性这些指标,另外还有一点是我们希望能够把这种形式做一些可解释性的推荐。
最后回到检索问题本身,未来算力 &算法升级使得检索不再是瓶颈,Match+Rank 分阶段漏斗式体系该如何发展?我觉得可能是把 match 和 rank 作为一个整体,用一个整体的技术方案去实现从千万级百万级量级到个位数或者十位数这召回,也就是所谓的合久必分,分久必合。
今天的分享就到这里,谢谢大家。
嘉宾介绍:
卓靖炜,花名靖炜,阿里巴巴广告产品技术事业部定向技术团队成员,主要负责商品/广告推荐算法匹配(Matching)相关工作,在 IJCAI, ACL, ICML 等会议上发表论文多篇。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:阿里深度树匹配召回体系演进

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论