
导言
本系列文章探讨了网络及其相关技术如何能够帮助解决众多长期困扰着我们的信息管理、数据集成和软件架构等方面的问题,目的在于以一种可扩展和足够灵活的方 式实现面向服务架构的部分承诺。文中的观点并非成功构建现代系统的唯一方式,它们在某些场合下也并不适用。本系列文章试图从致使网络如此成功的选择出发, 展示一个一致的、连贯的,以及切实可行的愿景。就某些方面看来,这似乎是在公然挑战软件行业的各种指导意见。而就其他方面来看,本系列则展示了来自于研究 人员与实践人员(他们花费了比我们所能想象得到的更多的时间来思考这些问题)的一些最佳想法。
在本系列的第一篇文章里面,我们对具象状态转移(REpresentational State Transfer,简写REST)式架构风格,作为后续讨论的共同基础做了比较深入的探讨。非REST(Non-RESTful)风格的系统当然也可以实 现这一愿景,但采取关注于信息的方法拥有着特别的优势。我们系统的客户很少关心我们使用了什么工具来满足他们的需要,除非特定的选择能确实带来显著的优化 或生产率提升。但是,他们非常关心能否浏览信息,以及控制信息被使用的上下文。
RESTful 的系统提供的好处包括灵活性、可发现性、生产率、可扩展性和一致性,以及简单的交互方式。充分拥抱 RESTful 风格不容易,但它的确能带 来一些立竿见影的回报。虽然我们通常强调使用统一接口(URL)来调用服务,但我们经常忘记它作为标识符的作用。例如下面的 URL:
http://someserver.com/report/2010/01/05
看起来确实像某类报表系统提供的 HTTP 调用接口,但这也是一份特定报表的唯一标识符。请记住,URL 也是 URI,因此它们满足了资源识别和可解析的双重 目的。如果我们想就此报表发表评论、打分评级、标识来源或者任何其他类型的元数据,该 URL 可以用来有效地实现上述这些要求,即便我们不解析引用。这是一 个全局性的名称,唯一地标识了报表服务的实例。这样,Web 上的 URI(通常为 URL)提供了统一的方式访问文件、数据、服务,以及我们即将看到的——概 念。这种一致的命名模式只是个开始。能够以内容协商的方式实时解析引用则是强大的下一步。现在,所有的种种信息资源都有了自己的命名,我们需要一种不限于 数据类型、能够以一种通用的机制从整体上描述它们的方式。
资源元数据
作为描述上述资源的例子,我们可能会这样讲:
- Brian Sletten 创建了服务 http://someserver.com /report/2010/01/05。
- Brian Sletten 是一个人。
- 该服务 http://someserver.com/report/2010/01/05 发布于 2010 年 1 月 5 日。
- 该服务 http://someserver.com/report/2010/01/05 是 一项薪资报表的服务。
这些事实展示了不同类型的关系,但它们都遵循相同的模式:通过某种关系,把值(value)和主体(subject)关联在一起。如何识别并表示主体、关系以及值,这一项选择将产生深远的影响,所以让我们稍微深入地探讨这个话题。
发布日期的陈述似乎比较简单,日期就是符合日期格式的日期值。创建作者的陈述则有一点复杂。我们可以简单地使用名称“Brian Sletten”作为陈述的值。在某些情况下,这也许就足够了。但是,如果有人想联系负责创建该项服务的人,怎么办?要是没有更多的信息,他们就得自己千 方百计去查找创建者的联系信息。如果我们能使用 URL(假设存在的话)指代创建者,那[译注 1]就轻而易举了。例如 http://server/employee/bsletten 这样的 URL 可以很好地满足要求,也让我们能够在全局范围内消除“Brian Sletten”引用的歧义。创建资源定位器(service locators)还有一个额外的好处就是,它们像其他事物一样变成为可解析的内容。一旦我们知道是谁创建了服务,我们能够解析引用获取相关的事物(比如 联系信息)。
这里我们又跟 REST 不期而遇了。如果用户请求来自于浏览器,我们可以针对人物的引用定义默认的 HTML 格式响应信息。如果能让人们方便地查找到自己正在 查找的信息,这是值得的。而且,我们也可以支持请求返回 XML、JSON 或者 RDF 格式的内容协商。资源的信息是表达成数据(在解析引用时获得),抑或是 表达成元数据(保存在外部的资源),这是资源特定的。在某些情况下,你可能希望两者都做。给非联网的资源——比如人们和概念,指定可解析的 URL 历来是个 问题。你引用的是人,还是关于该人的文件?我们将后续的文章中讨论一些解决办法。现在,我们将假设已经拥有了解决该不确定性的机制。
使用 URL 表征“Brian Sletten”的另一个好处是,我们可以把相关的陈述关联其上,比如他是一个人、他有一个电子邮件地址等等。这样,我们可以有机地衍生出一个相关事实的 联系图。我们把一个主体的事实与其他的主体关联在一起(作为值的形式进行关联)。我们可以把对关联到其他主体的值发问想象成发现新主体引用的过程。图是一 个比表更具扩展性的模型,所以随着时间的推移,我们可以很容易地在任何已经存在的节点上增加对新事实的支持。在了解了资源的新的事物之后,我们可以将其附 加到我们的模型中来。这使得我们可以从各种知识来源里面积聚知识。它还将产生一个离散的系统,任何人都可以在里面表达关于任何事物的事实。我们是否选择将 他们的事实包括进来,这个决定权属于我们。
上面我们识别出的最后一项值——薪资报表服务,这是一个对我们的组织有一定含义的术语。如果假定同样存在其他类型的服务,而且它们按照有意义的方式组织在 一起(比如,薪资报表服务属于报表服务的类型)。我们需要额外的机制把这些术语按照它们之间的关系组织在一起,但我们将会在后续的文章中继续讨论这一点。
我们必须首先考虑把这些值关联到主体的关系。如果我们使用关系数据库来保存这些结果,我们可以创建诸如“creator”、“publish_date” 或者“instance_of”这样的列名。我们可能会使用像 Hibernate 的技术,把这些列映射到对象模型上面,这样就可以编程使用这些信息。这种 方法在关系数量比较少的时候或许还能工作,但显然不能扩展到支持任意数量的元数据;不可能一旦有人声明资源的新事物,我们就去增加新的列。我们可能会得到 大量的只有很少条目的、而且层次关系不深的表。
假设我们沿着这条路走下去,在考虑合并多个资源元数据数据库的时候,无论如何我们会遇上更多的问题。工程部门和市场营销部门可能有不同的 IT 人员使用不同 的方式归纳元数据。为了提供跨越这些系统的共同看法,我们很可能不得不创建新的一层,创建一个合并数据库或者做其他令人痛苦不堪、较之原本更困难的事。这 样做一两次是还能接受,但每一次新的集成都这样去做则是无法想象的。要是我们盘算跨越组织边界,构建合作伙伴服务一体化的战略,那我们几乎可以直接放弃了。
WS-* 技术栈的拥蹙们可能会跳起来说,借助于公共架构体系—— UDDI 元 数据库以及其他类似的技术,他们已经解决了这个问题,可惜事实上他们并没有。问题在于任何使用脱离特定社区关注点的通用模型的办法很可能会失败。强迫合作 伙伴使用同样的架构忽略了一个事实——一般来说,我们不会使用同样的方式来看世界。此外,我们也没有同样的信息需求。通用模型成为最少共同特性的模型;一 如既往地,总会有人的需求被忽略了。这并不是说 WS-* 技术栈不解决任何问题,只是它没有解决这个问题。
但同样,假定我们已经决定采取依赖于某种通用模型的战略。不可避免的是,我们需要与另外没有决定采取同样战略的合作伙伴进行集成。我们如何调整我们的元数 据呢?我们如何解释术语的含义呢?我们如何把我们的术语和关系与他们的术语和关系连接在一起呢?
最后,一旦我们决定超越元数据的范畴,实际数据如何去适应?我们是否要从头创建一个新的通用数据模型?我们如何把元数据与数据连接在一起?现在应该很清楚,过去二十年左右的很多技术方案根本就是进入了错误的战场。我们试图用不恰当的、僵硬的抽象对领域、流程、人和数据分别建模。我们忽略了有关信息是如何 生产和消费的现实。信息没有格式,很少具有边界。在数据和元数据之间没有明显的区别。或许最根本的是,我们没有,也通常不会同意一致的世界观。正如我们已 经一次又一次看到的,任何从上而下、试图一劳永逸地解决这个现实的 IT 行动,是注定要失败的。
我们需要另外一种策略,把由上而下的高效工作与从接近本质的底端向上所看到的现实结合在一起。我们需要一种数据模型,帮助我们免除特定模式、语言、对象模型、产品或世界观的束缚。我们必须鼓励人们愿意这样做,但也允许他们保留不同意见。我们需要让他们了解不同的事情,并在所有建模活动中充分支持他们。如果 我们不能在最核心的位置支持他们,我们必须在边缘位置满足他们的需求。这并不是说我们正在走向无秩序状态。如果我们需要验证和限制,我们当然可以那样做。
W3C 的语义网倡议由一系列帮助提供这些特性的技术组成。我们将在 以后的文章中逐步探讨该工作的宏大目标,但是现在,我们将关注于资源描述框架(RDF)和 SPARQL 描述、联系和查询资源元数据的能 力。
RDF
RDF 是一个构建块技术,它展示了一个可扩展的、支持开放世界假定的数据模 型。作为元数据模型,RDF 在描述信息资源方面非常有用。而且,正如我们将在后续文章中所看到的一样,它同时也提供了数据的表达机制。当我们构建一致的命 名方案(URI 和URL),以及由松散耦合的资源(可以通过协商成为不同形式)组成的网络体系结构,RDF 使得我们能够以强有效的方式连接这些资源并进行描述。
在基础层面,你可以想像一系列的事实都表达成了RDF。随着时间推移,我们可以从不同的来源积聚这些事实,形成一个由有向图支撑的模型。无论源数据是何种 格式,通常都可以被转换成RDF 关系,并加入到我们的知识库中。这样,我们解决了模式一致性的问题。
RDF 的“事实”表现为主体关联到值。主体要么是基于 URI 的资源,要么是未命名的空白节点。值可以是字面量(字符串、日期、数字),又或者是其它基于 URI 地址的节点。一项陈述的主体可能是另一项陈述的值。考虑一下我们想要表达的关于上述报表服务的事实。这个主体很简单 http://someserver.com/report/2010/01/05,日期值也 很简单:“2010-01-05”。如何把它们连接起来,则需要进一步思考。我们希望 指代该服务的发布日期。我们可以创造自己的术语,但这其实并不必要。业界已经存在一个广泛使用的元数据规范——被称为 Dublin Core(http://dublincore.org/),里面整理了关于出版物的元数 据。它是由一组对期刊、书籍、网络文章等出版物的标准术语感兴趣的图书管理员所开发出来的。我们不是必须使用这些术语,但没有理由不。
浏览Dublin Core网站 ,我们能发现一些有用的术语,如标题(title) 、 描述(description)和许可有用条款(license)。为了表示服务何时被发布, “日期(date)”这一术语似乎可以帮助我们。通过点击链接, 我们能看到该术语的介绍、使用方法,以及其设计意图。RDF 术语的集合被称为词汇。一个RDF 词汇通常是领域特定的(在本文中,出版物的元 数据)。每个术语都会被清晰描述,以便于双方的软件和人类应用。
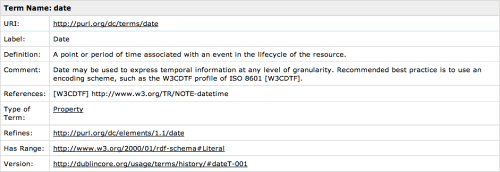
通过快速地浏览,我们能看到除了良好的描述,这个术语主要是基于一个URL: http://purl.org/dc/terms/date, 这是该术语全局唯一的名称。如果我们选择使用这个术语,即使其他人从来没有见过,他们也能确切理解该术语的含义。除了人类可读的描述,还同时存在另一个机 器可读的描述。借助于解析该术语的 URL,我们可以去探个究竟。点击前面的 URL,我们会被重定向到: http://dublincore.org/2008/01/14/dcterms.rdf#date 。重定向是 URI 的一个重要方面,但这一点将被放在后续的文章中;目前先明确这一点:简单地发布 RDF 词汇是远远不够的。
在解析 RDF 词汇的时候,我们取回的往往是 RDF 模型 RDF/XML 序 列化后的结果。这种情况下,RDF 被用来自我描述。暂且不要在解释复杂模型上抱有太大压力,但如果你对此好奇,它由一系列被编码成层次 XML 实体关系的事 实组成。
<rdf:RDF xmlns:skos="http://www.w3.org/2004/02/skos/core#" xmlns:dcam="http://purl.org/dc/dcam/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"> . . . <rdf:Description rdf:about="http://purl.org/dc/terms/date"> <rdfs:label xml:lang="en-US">Date</rdfs:label> <rdfs:comment xml:lang="en-US"> A point or period of time associated with an event in the lifecycle of the resource. </rdfs:comment> <dcterms:description xml:lang="en-US"> Date may be used to express temporal information at any level of granularity. Recommended best practice is to use an encoding scheme, such as the W3CDTF profile of ISO 8601 [W3CDTF]. </dcterms:description> <rdfs:isDefinedBy rdf:resource="http://purl.org/dc/terms/"/> <dcterms:issued>2008-01-14</dcterms:issued> <dcterms:modified>2008-01-14</dcterms:modified> <rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/> <dcterms:hasVersion rdf:resource="http://dublincore.org/usage/terms/history/#dateT-001"/> <rdfs:range rdf:resource="http://www.w3.org/2000/01/rdf-schema#Literal"/> <rdfs:subPropertyOf rdf:resource="http://purl.org/dc/elements/1.1/date"/> </rdf:Description> . . . </rdf:RDF>
术语关联到通过rdf:about或rdf:id属性引用的外部rdf:Description资 源。再次,我们将在以后更深入地探讨这些想法,但现在尝试简单解释如下。先找到刚才谈及的rdf:about(记住,rdf命名空间的完整形式是http://www.w3.org/1999/02/22-rdf-syntax-ns)。在这 里,它表明了 RDF 事实的主体。作为例子,我们可以展开讨论dc:date术语表达的关系:
<http://purl.org/dc/terms/date> <rdfs:label>“Date”.<http://purl.org/dc/terms/date> <rdfs:comment>“A point or period of time associated with an event in the lifecycle of the resource.”.- …
<http://purl.org/dc/terms/date> <dcterms:issued>“2008-01-14”.- …
现在,你可能认为这纯属矫枉过正,实现为数据库中一列的策略更为简单。话虽如此,但你选用那种方法会失去很多。数据库列在数据库之外就不具有任何含义;除 了 SQL 脚本或者对象 / 关系映射配置文件之外,你甚至不能指代数据库对象之间的关系。因为你不能指代关系,你无法将某条记录的某一方面连接到另一条记录, 或者电子表格中包含的信息、或者报表、或者 RSS 源、或者在线服务。现在信息的形式千变万化,我们根本无法依赖于关系数据库表作为处理所有集成工作的场 所。我们需要一种方法不依赖于任何特定的编程语言或者数据库技术,以统一的方式来捕获和表征信息如何被联系在一起。
另一个问题是,我们通常不能在数据库之外指代数据库中的记录。当然,我们有标识符,但一长串数字能代表什么?那是主键?全局的标识符?处于什么上下文之 中?URL 的主要价值之一是它可以成为全局的标识符。任何上下文中的引用可以连接到其他引用。你可能会认为这意味着我们需要使用相同的术语,但事实并非如 此。要做到这一点有很多行之有效的方法,但我们将在本系列的后续文章中学习如何解决这个问题。
幸运的是,我们并不建议你折腾你的关系数据库。它们已经被广泛接受,是普适的、拥有良好的工具支持,已经成为生活的一部分并且会持续下去。但即便如 此,RDF 模型仍然可以被使用。通过使用 RESTful URL,我们可以在逻辑上引用到记录。如果需要,我们可以把列名映射到 RDF 关系(或者只是让数据库不工作——这并不像听上去那么疯狂)。我们实现了—— 无论信息的形式如何,在其特定形式的上下文之外,有一种逻辑上的方法引用该信息。当我们得到了资源的引用,我们可以查询元数据存储库,查询更多的相关信 息,或者我们可以简单地解析该信息,看看返回的是什么。返回的 MIME 类型给了我们一个如何解析响应的指示。我们可以在响应中发现新的引用指向相关信息。 我们还可以发现可选的能以更方便格式获取信息的形式。魔鬼在于细节,但这只是该设想的基本概念。我们在拥抱着信息网络——公共的以及私有的。
现在对环境了解更多了,我们如何表达一个 RDF 事实呢?我们有若干种 RDF 序列化的格式可以使用。我们在前面已经见识了 RDF/XML,它是相当地冗长。 使用 Turtle 格式来表达事实貌似 很简单:
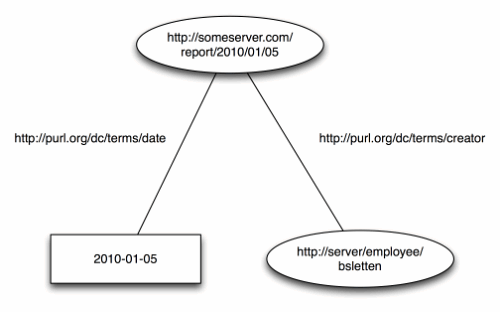
<http://someserver.com/report/2010/01/05> <http://purl.org/dc/terms/date> "2010-01-05" .
我们有一个主题,一个谓词和一个客体;一个三元组,或者单一的事实。请记住,RDF 是一个基于图的模型。序列化格式只是关于如何存储或传输信息。由上述三元组得到的图会转化成相应的模型,从概念上看起来如下所示:

现在我们使用关于所问资源的一些元数据扩展我们的知识库:
<http://someserver.com/report/2010/01/05> <http://purl.org/dc/terms/creator> <http://server/employee/bsletten> .
我们现在有两个三元组,结果我们的图形看起来就像:
以 RDF/XML 格式序列化上面的事实,结果看上去会像这样(是的,它有一些丑陋):
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"> <rdf:Description rdf:about="http://someserver.com/report/2010/01/05"> <creator xmlns="http://purl.org/dc/terms/" rdf:resource="http://server/employee/bsletten"/> <date xmlns="http://purl.org/dc/terms/">2010-01-05</date> </rdf:Description> </rdf:RDF><rdf xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"><description rdf:about="http://someserver.com/report/2010/01/05"></description></rdf>
这里要强调一点的是,RDF 数据可以令人难以置信的不拘形式。它可以以原生 RDF 的格式(如 RDF/XML)存在,或者在从另一个数据源实时生成。它也是 完全可以移植的。不管原生数据保存为什么形式,一旦转换成 RDF,它就可以很容易地从一个存储地点导出来,然后导进到另一个能识别 RDF 的存储地点。
让我们给知识库补充一些事实。
<http://server/employee/bsletten> <http://www.w3.org/1999/02/22-rdf-syntax-ns/type> <http://xmlns.com/foaf/0.1/Person> . <http://someserver.com/order/1234> <http://purl.org/dc/terms/creator> <http://server/dept/eng> . <http://server/employee/bsletten> <http://xmlns.com/foaf/0.1/mbox> "bsletten@example.com" .
在这里,我们指出“Brian Sletten”是一个人。我们从 Friend-of-a-Friend(FOAF)词汇( http://foaf-project.org )中选择了这个术语"人 (Person)"。这是另外一种被广泛使用的涉及社会网络、专业兴趣、教育背景等的术语集合。我们还指出,工程部门也创建了不同的服务。我们为“工程部 门”的例子虚构了 URL,从而为下文的查询例子提供了另一个非人类的 Dublin Core“creator”客体。我们还为 Brian 增加了一个(伪造的)电子邮件地址。最终的知识库如下面的 RDF/XML 序列化所示:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"> <rdf:Description rdf:about="http://server/employee/bsletten"> <type xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns/" rdf:resource="http://xmlns.com/foaf/0.1/Person"/> <mbox xmlns="http://xmlns.com/foaf/0.1/">bsletten@example.com</mbox> </rdf:Description> <rdf:Description rdf:about="http://someserver.com/order/1234"> <creator xmlns="http://purl.org/dc/terms/" rdf:resource="http://server/dept/eng"/> </rdf:Description> <rdf:Description rdf:about="http://someserver.com/report/2010/01/05"> <creator xmlns="http://purl.org/dc/terms/" rdf:resource="http://server/employee/bsletten"/> <date xmlns="http://purl.org/dc/terms/">2010-01-05</date> </rdf:Description> </rdf:RDF>
我们将把编程代码示例推迟到下一篇文章,但从编程上看,你可以载入三元组,转换成模型,然后查询。为了做到这一点,我们需要一种查询语言。幸运的是,SPARQL 是一个查询 RDF 图的 W3C 标准。
RDF 查询
SPARQL 是一个递归缩写,代表“SPARQL 协议与 RDF 查询语言[译注 2]”。我们将在本系列的第三部分中做更深入地探讨,但现在先引入一些基本的 概念,以帮助我们从知识库中抽取信息。对于我们的目的来说,SPARQL 允许人们表述模式与 RDF 图进行匹配。这可以是一个“默认图”(在查询之外指 定),也可以来自于一个或多个命名的图(在查询内部)。为了保持简单,我们将使用 Twinkle 的 SPARQLC 处理。如果你想继续,请下载 Twinkle ,这是一个查询 SPARQL 数据源的工具。
复制上文中最终得到的 RDF/XML 序列,并将其粘贴到一个文件,如 /Users/brian/facts.rdf。现在运行 Twinkle:
java -jar twinkle.jar
您应该看到一个 Swing 用户界面,上面显示一个默认的查询窗口。在此窗口中,选择文件按钮,浏览到您刚才保存的文件,选择该文件。这将基于文件中的数据 为我们的查询创建默认的图。如果您对 SQL 很熟悉,SPARQL 也将会(最终)同样让你觉得得心应手。我们将匹配模式,从图中选择结果。
下面演示了一个基本查询,列出图中所有的事实:
select ?s ?p ?o where { ?s ?p ?o . }
您的结果应类似于一下的内容:
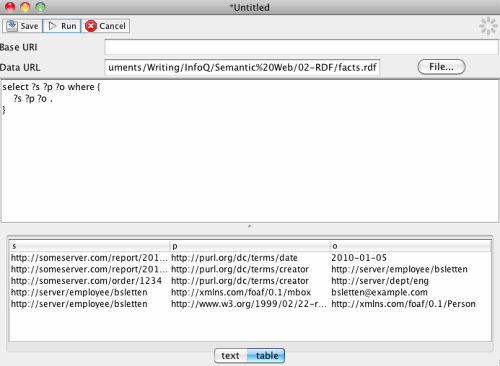
我们要求 SPARQL 找出未绑定变量中所有匹配模式的三元组。千万不要在大型图上这样做!上图显示的查询结果表详细列出了每一项三元组。我们使用名称 s、p 和 O 代表未绑定的变 量,我们希望基于这些变量在陈述中所处的位置:主体,谓词和对象进行匹配。查询引擎将对于图中的弧和节点匹配这些模式。变量的名称并不重要,重要的是它们 在模式中的位置。与往常一样,良好的变量名称使得查询更易于理解。带有更多约束条件的查询可能是这样的:
select ?service where { ?service <http://purl.org/dc/terms/creator> ?creator . }
在这种情况下,我们使用了不同的变量名字,并只选择其中的一个。在这个时候,我们并不关心创建者是谁,我们只想知道任何拥有创建者属性的服务。读者可以自 己尝试着修改查询,以同时得到服务名称和创建者,然后试试只得到创建者。你很快就会厌倦输入 URL。为了方便起见,SPARQL 支持前缀定义:
PREFIX dc: <http://purl.org/dc/terms/> select ?service where { ?service dc:creator ?creator . } {1}
现在我们要做的最后一个查询是向大家展示我们如何使用图完成更复杂的查询。我们在知识库中有两个创建者,一个是人类,另一个是非人类。准确地讲,我们不知 道非人类的创建者是什么,在本文中我们暂且认为它是工程部门。就所我们关心的事实而言,我们对该创建者一无所知。如果想请求某个人,同时又是服务创建者的 电子邮箱地址,我们可以使用:
PREFIX dc: <http://purl.org/dc/terms/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns/> select ?mbox where { ?s dc:creator ?c . ?c rdf:type foaf:Person . ?c foaf:mbox ?mbox . }
还有一些其他的语法能够简化上面的查询,但现在只是让大家先有这个印象(何时可以沿着图进行查询)。对于每一件拥有 dc:creator ?c 的事物(?s),如果事物(?c)是 foaf:Person,取得该事物(?c)的电子邮件地址。
也许你可以开始看到,我们可以探讨信息空间,通过查询信息资源如何连接:人们到出版物、到专题、到地理区域,延续不止。在这个过程中,我们会发现存在着什么样的关系,事物如何互相关联,如何使得人们能够加以利用,基于他们前所未闻的事物构建摩天大楼。
结论
本文只是涉及了这些概念的一些皮毛,但希望这些关于松散耦合的信息资源的想法让读者产生了一些兴趣。我们可以对信息继续保留其原生存储的形式,但根据需要 访问不同的形式。有关语义网的技术栈绝没有臻于完美。有关各方在最细微的细节上已经争论不休了很多年,即使到今天,这些分歧依然存在。但是,他们就如何能 够在各种不同的场景下灵活地命名和解析信息等等方面提出了一些非常重要的发现。这些最初的选择混合在一起,以创造一个充满活力的信息生态系统。我们可以解 决众多过去曾经阻碍 IT 系统的巨大障碍。在接下来的文章中,我们将深入兔子洞,探讨这些数据网的深层现实。
译注:
1. 此处“那”代指“联系创建者”
2. 英文原文为:SPARQL Protocol and RDF Query Language
阅读英文原文: Resource-Oriented Architecture: Resource Metadata 。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。

暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论