

大家好,我是本次直播的讲师 Pick。非常高兴有机会和大家在这里交流 Redis5.0 之 Stream 应用。今天的分享更多的是一个抛砖引玉,欢迎大家提出更多关于 Redis 的思考。
我们来个假设,这里有个杯子,这个杯子是去年我老婆送的,送的原因是我以前的杯子保温性能太好,导致我很少能喝上水,而这样敞口的杯子能促使我多喝水。虽然这杯子在商家的货架上只是千千万万只杯子中的一只,但是它对我来说仍然是不同的。不同的是过往,是记忆。这记忆说起来是数据的一类,这类数据也让我们生活更美好。

这种数据的特点是什么呢?产生是一次产生的,但是我们会希望经常看到,希望将这种美好填充到各种东西中。而杯子本身也可以说是一个生产-消费模型:数据出现,然后被各种消费。
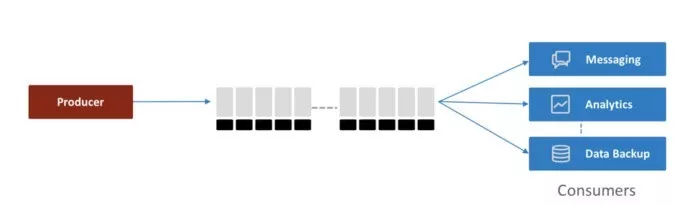
消费的一种情况
因此,杯子不仅仅是一个杯子,实际上背后的可挖掘的东西非常多。意义越多,连接越多,关系越复杂,我们数据量也越大,所以,希望价值最大化的我们,就产生了大量希望被高速处理的数据,这数据体现在系统上,往往就成了数据洪峰,成了系统难以承受之重。
在很多情况下,我们采集端所包含的信息可能远远超出这个数值。例如,雾霾天里,我们的房间,我们的位置,它的空气质量是怎样的,各项污染物参数是多少?我们这个办公区,这栋楼,这个房间的空气质量又是怎样的,电力消耗是怎样的,行人状况,车辆数据,等等。上亿的数据,涉及互联互通,需要保证高并发可靠传输。同时数据收集上来后要进行处理和存储、分析,对系统的挑战都是巨大的。
巨大的、网状的互联互通,需要带宽巨大、顺畅的管道;这么多的数据,会形成巨大的数据洪流,采集完成后在云端进行分析,也可以产生巨大的用户价值。
区域检测监控
这些数据虽然形式各不相同,但是也有共同的特点,就是和时间有关。例如,一户人家,从主卧到书房,从客厅到餐厅,不同的房间不同的位置放置一些空气监测仪,监测仪里面的化学药剂接触空气中的各种成分,随时间缓慢变化,变化过程中产生信号,这些信号经过初步整理计算,形成一个平面的空气质量数据;从清晨到傍晚,从春到秋,不同的时间点,甲醛、TVOC 等各种污染物成分的数值也不一样,因此平面的数据在这里形成了时序数据。
凑巧的是,Redis 的流就是专门为时序数据设计的。我们回顾一下 Redis 的流的存储设计:主线是一个消息链表,将所有消息按照顺序串起来。因此 Redis 的流在这方面支持度是非常不错的,我们可以将平面内的数据按照时间序列加入到 Redis 流里面。当然这些数据我们可能需要初步处理,因此我们也可以使用 Redis 的其它数据结构,例如 list,再凭借 Redis 对 Lua 脚本的支持,用很少的外部应用逻辑驱动它完成处理。这处理因为是在 Redis 内部完成,所以整体上来说,计算消耗是比较低的。Redis 原本凭借它原生 C 的优势,还有内存实现和数据结构的优化,内存占用就比较小,CPU 要求也低,使它在小型设备上高效率的运行成为可能。未来可能会有万亿级的智能设备基于 ARM 平台,前景还是非常广阔的。
所以从设备端,我们已经可以使用 Redis 来完成数据的临时存储和基本的处理,加入 Redis 流后,再使用 MQTT、TCP、808 等协议,通过网络上传数据。通常我们需要采集的区域会比较广,设备数量很多,因此数据也比较多,那数据可能还需要在局部,进行初步的汇总处理。这里数据洪峰往往就开始显露了。如果我们期望保存进 mysql 等数据库,通常是顶不住压力的。因为数据库的原子性、一致性、隔离性、持久性等,对性能的损耗是比较大的。所以这里我们可以使用 Redis 来接收洪峰监测数据,然后分发给存储服务、处理服务、展示服务,等等。在分发处理完成前,Redis 本身作为高速内存存储,流里面的数据也是可以作为普通的缓存数据,被反复访问的,所以也在一定程度上,对消息消费前的空档期,做了补充,也给予了后台更宽裕一些的处理时间。
我们来回顾一下其中 Redis 的使用:快,Redis 的性能很高;小,轻便简洁,对内存和 CPU 要求小;丰富,数据结构丰富,用法多样;时序,流是为时序应用设计的;支持 Lua 脚本,能自定义逻辑。
饭要一口一口吃,路得一步一步走。让我们回到技术本身,从巨大的洪流里截取出一部分和 Redis 有关的,还原成基本的工作流程。
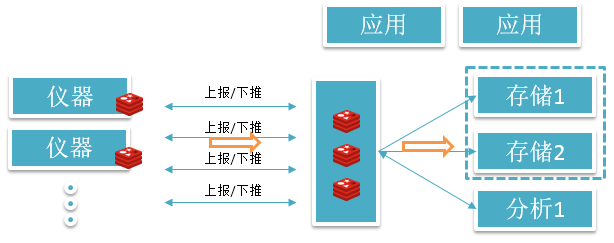
我这里截取的是空气监测的存储和处理。我们来看一下示意图,仪器上报数据,Redis 接收数据流,并且提供给存储、分析消费,同时供应用使用。

检测数据产生,组别建立
首先来了一条空气数据,检测数据产生,存储、分析消费组也建立起来了。空气数据包含了 hcho 和 tvoc 污染物值。我们看看命令,这里有个 maxlen,这是为了避免队列过长,所以设置的最大长度。为什么需要这么设置呢?因为 Redis 的流顺序消费后,甚至 xdel 后,数据并不会被清理,队列会越来越长,所以这里我们设置个最大长度,避免溢出。
这里有两个存储服务。假设存储相对比较慢,为了能及时处理,我们构建了更多的存储服务。
我们看看存储和分析服务消费数据的过程。这里两个存储服务都尝试获取数据,但是很明显,只有一个获取到了数据进行处理。分析在这时尝试取 3 条数据加入分析处理,但是因为 stream 里只有 1 条,所以这里只取到 1 条。
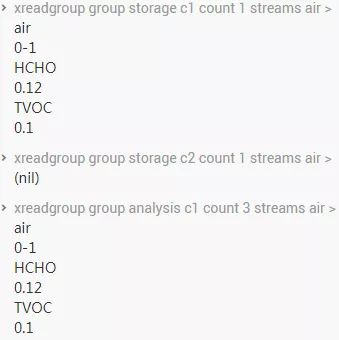
存储、分析服务消费数据
分析服务率先完成了数据的消费,所以在分析服务里马上答复了一个 ack 给 stream,告诉它,已经消费完成了。随后存储服务也完成了存储,存储服务也发送了个 ack 给 stream。

消费完成,答复 ACK
分析服务刚刚答复完 ack,因为某些原因,重启了。分析服务启动的时候,不清楚消费到哪里了,所以尝试从初始位置开始消费。这里因为前面已经消费过并且返回了 ack,所以没有取到任何可消费的数据。如果有数据没消费完成的,通过这种方式可以进行再次消费,所以服务在消费时需要能够处理重入。

分析服务重启,开头消费起
在这里我们看到,检测数据也在不停地到来,存储和分析服务同样按照前面的规则消费。分析服务按照自己的能力,依然尝试一次取用 3 条,根据结果我们可以看到,这次分析服务取到了两条消费数据。
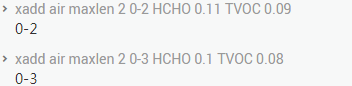
新检测数据
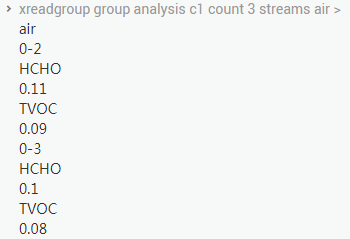
分析服务消费数据
存储服务呢?两个存储服务也都取到了数据进行消费。
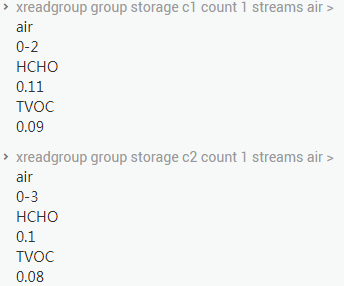
存储服务消费数据
这时候用户开始访问应用了,他打算看下污染情况是怎样的。我们都能理解,刚刚购买一件新东西的时候,我们会更倾向于马上看看,所以这里用户肯定是期望看到污染物情况的。但是这时数据既没有分析完毕,也没有存储完毕,我们需要怎么处理呢?
应用服务可以先检测状态,发现需要的数据还没有处理完成,因此从常规缓存里面获取明显是获取不到的。所以应用直接从 stream 里获取了,我们可以看到,用户顺利地秒看到了监测数值,对身边的状况马上有了一个了解。用户想看看还有没有新数据,所以在应用上点了下刷新,我们看到,这次仍然能从 stream 中获取到需要的数据。当然,如果用户想针对性地看看情况,应用中也可以指定 ID 读取。那还有没有其它方式呢?xrange 也是批量取出需要消息的一种方法。
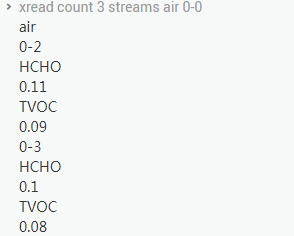
应用使用 xread 方式读取数据

应用使用 xrange 方式截取数据
从这里可以感受到,虽然我们的日子,在时间的流里面一往无前,一去不返了,但幸运的是,在 Redis 的流里面,我们仍然可以从过往里截取出任意一段,重新品尝,温故知新。
回到例子。用户刷完两次后,存储和分析服务处理好数据了,所以存储和分析服务再次向 stream 发送 ack 消息,示意已经处理完成。

消费完毕,返回 ack
当然,这些 Redis 里面的处理,都是一如既往地高性能、高效的。
这里只是一个简单的截面,一个示意。实际上,Redis 原本的使用场景就非常丰富,例如,作为会话缓存,作为页面的全页缓存,手机或者网页的验证码,服务访问的频率限制,密码防暴力破解,竞技场、吃鸡、短视频女神榜等各种排行榜,点赞、阅读数等计数器和排行,关注某个标签、或者某个明星的人,限时优惠活动,证券的实时指标计算,号码发放器,甚至还有 geo 地理信息,基于 LUA 的自定义逻辑,还有订阅发布,等等,非常丰富。这些都是基于 Redis 丰富的数据结构,开发出来的使用方式。
罗胖在时间的朋友演讲说,大趋势往往不是一个小趋势逐步成长起来的,而是趋势撞击趋势,改变带来改变,逐渐滚动、交织变大的。那么 Redis 的流,能在这些已经存在的应用场景里,提供怎样的碰撞?又能在新的领域里,带来怎样的趋势?欢迎大家前来共同讨论。
也欢迎大家到华为云分布式缓存免费领取 Redis 5.0。现在 Redis 5.0 是公测阶段,可以免费体验。领取也非常简单,申请公测,然后花费几秒创建 Redis 5.0 实例,就可以了。
更多不一样的用法,欢迎大家在下方留言与我一起探讨。
本文转载自公众号中间件小哥(ID:huawei_kevin)。
原文链接:
https://mp.weixin.qq.com/s/7YZXS6XB_nMcGtlu-p37eg

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论