

工业互联网和 5G 时代正逐步到来,万物智能网联、智能互联已成为一种趋势。目前物联网应用在很多场景下,如智慧制造、智慧城市、智慧农业等。本文以智慧城市为背景,介绍西安中服软件有限公司是如何利用大数据分析神兽 Apache Kylin,让物联网的传感器信息,通过云化的大数据物联网云平台,对感知的数据进行分析处理,进而满足智慧城市的建设需求。
业务背景
作为智慧城市的重要组成部分,智慧楼宇也以惊人的速度发展着,挖掘和处理楼宇数据,并以此来精准控制并降低楼宇能耗成为一个重要问题。以 IoT 设备完成能源网络搭建,并进行数据采集,然后推送到流处理工具,楼宇管理者可以通过常规的数据分析,根据不同的用能区域、能耗类型,对建筑能耗进行分时段计量和分项计量,分别计算指定时间范围内电、水、气等能源的使用量,并且对未来能耗使用进行一定程度的预测。管理者可通过梳理不同能源的使用情况,实现对能源的高效管理。
做一个单点的能源管理系统并不存在技术难点,但是在设备上云后,要将其做成一个 Saas 产品,我们就需要考虑很多问题,如性能问题等。 传统的做法,不同的租户将物联网设备在云端绑定后,系统自动为他们生成对应的数据库表,以此来做到资源隔离。这些物联设备的事实数据和维度数据都存放于 Oracle 中,但是使用关系型数据库存在一些问题:
无法支撑大数据量,当数据量达到一定程度时,需要进行倒库。
为了解决查询的性能问题,往往需要创建多张中间表,去存放按属性查询过的历史数据结果。
用户在修改设备的配置表时,涉及到多表联动修改。这种处理方法不仅可靠性低,并且对开发人员和数据分析人员来说都是极为复杂的。
因此,需要一个能支持快速查询且易维护的数据存储及分析引擎,来解决关系型数据库存在的这些瓶颈。
技术选型
我们团队在引入 Kylin 之前,曾经尝试过很多种解决方案。
第一种方法是将所有的数据都加载到 Hive 中,这种方式虽然能够支撑较大数据量,但查询时需要等待很长时间才能获取到结果,查询延时无法满足即时性要求。
我们尝试过使用 Druid。Druid 已经是目前市面上较为成熟的实时 OLAP 引擎,但是它只支持单表查询,而我们的能耗分析通常需要多表联查。此外,Druid 的原生查询语句是一种自定义的 json 格式,并非我们所熟悉的 SQL,这对于非专业人员来说上手存在一定的难度。
后来,我们使用 Kylin 进行能耗分析测试,在这过程中我们发现它有以下几大特点:百亿数据集支持、SQL 支持、准实时、亚秒级响应,对外提供 REST API 和 JDBC/ODBC 两种访问方式。Kylin 架构如下图所示。这些特点能够满足智慧楼宇能效查询的大部分场景,因此我们最终决定选用 Apache Kylin 作为中服楼宇能耗管理平台的存储引擎和查询引擎。
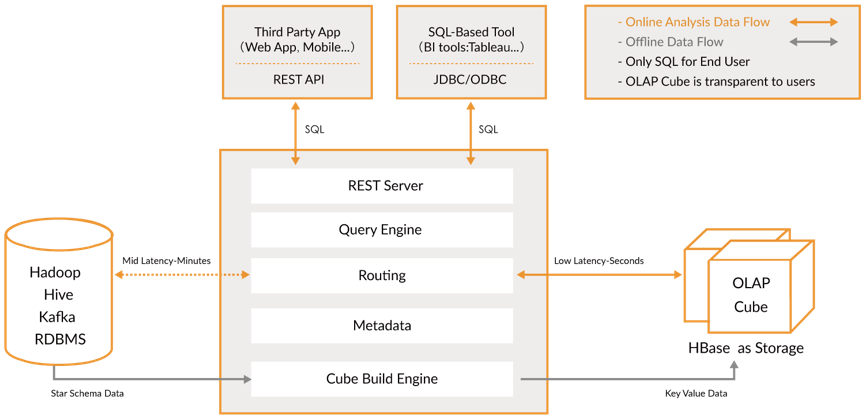
楼宇能耗 OLAP 架构
中服的楼宇能耗 OLAP 架构如下图所示,考虑到设备传感器采集到的数据并非每次都是完整的,因此需要流处理工具提前做适配、计算、校验以及转换成 json 格式,最终输入到 Kafka 指定的 topic 中。该架构中使用的 Kylin 版本为 2.6.2,此版本相对稳定,且修改了 Kafka 对接 Kylin 会出现 8 个小时时差的错误,保证了在几个衍生时间维度上的准确性。
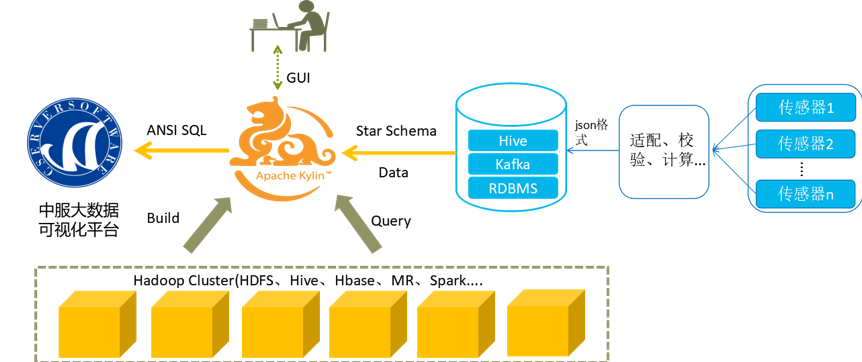
Kylin 的事实表是来自 Kafka topic 里的设备传感器的 json 数据(不同设备类型的数据通过流处理工具进入到不同的 topic 中),维度表是存放于 Hive 中用户定义的配置表,例如设备表、设备区域表等,事实表与维度表连接构成星型模型。数据分析工程师根据可能要查询到的场景来分析这些表中的维度和度量,以此来配置相应水、电、气的 Model 和 Cube,再依托于 MR 进行 Cube 的构建。
根据业务场景,整个流数据是源源不断的,需要每小时 build 一次 Cube,待 Cube 构建完成,对外提供两种方式查询能耗数据,一种采用 JDBC/REST API 的方式为前端能耗管理界面提供数据,另一种是采用 JDBC 的方式无缝对接 BI 工具,用以能耗的 Display 和 Dashboard 展示。
使用 Kylin 实现能源管理 SaaS 平台
我们的初衷是做一个能耗管理云平台,通过对实际需求进行详细的分析,在用户将物联网设备上云后,系统能够自动协助该设备绑定至特定类型的 Cube 中,比如能耗管理场景下某个区域的电表会自动绑定到 IoT_Electric_Cube 中。换句话说,用户只关心将自己的设备连上,再到可视化面板查看相关能耗使用情况,不需要知道背后的数据分析引擎具体是怎么操作的。因此,我们需要解决两个问题:Cube 的自动化创建以及多租户的问题。
1. Kylin 各模块的自动化创建
由于使用 Kylin 有一定的门槛,需要进行一些专业的分析和操作。而使用我们云平台的用户更多的只希望在完成设备绑定之后,就能查询到相关能耗信息,此外,从一定程度上来说,大部分用户并未掌握 Kylin 的使用方法,因此如果让用户根据绑定的设备在线去配置 Model、Cube,将会成为一个很大的难题。为了解决该问题,我们进行了下图的配置。
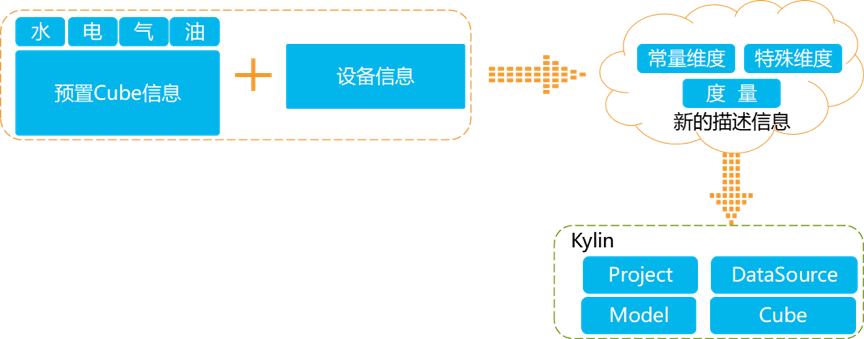
我们针对能效分析场景中的水、电、气、油等能耗类型,提前创建好一个预置的 Cube,后期用户在绑定设备后,系统会根据预置的 Cube 和新的设备维度,分析出常量维度、特殊维度以及度量,生成新的 Cube 描述信息,用以自动化创建 Model 以及 Cube。另外,针对于用户可能更改设备配置表的内容,我们对其提供了一个 API,可跟随配置表的内容动态更改 Kylin 维度表中的数据。
2. 平台多租户的资源隔离
针对于平台的多租户问题,由于 Kylin 目前对多租户的支持较为简单,只是简单将用户分成了几个角色,不同角色的用户对元数据及 Cube 有不同的操作权限,而我们平台的租户只需在查询时保证相互之间数据的独立性即可,因此我们只做资源数据的上层隔离,对下面的 HBase 存储来说还是统一的。我们的做法就是在 Project 层做处理,一个租户创建一个 Project,再根据 Project 对应绑定不同 DataSource、Model 以及 Cube,再由整个平台的管理者对所有 Project 进行管理。但如果租户量达到一定量时,此种方法并不可取,目前我们正积极针对多租户的问题做相应的优化。
此外,多租户机制下会产生大量的垃圾数据,包括 Kylin 在构建 Cube 过程中会在 HDFS 上生成中间数据,以及在执行 drop/purge/merge 等操作时,HBASE 的表可能不会及时地被 Kylin 清理,一直保留在 HBASE 中,久而久之对 HBASE 的运维查询都必将造成一定的压力。因此,我们做了一些调整,每隔一段时间执行一些清理工作,以保证各集群的正常工作。
Cube 维度优化
随着维度数目的增加,Cuboid 的数量成指数级增长。针对能效分析场景下水、电、气各个 Cube,以电为例,电表采集点有 A 相电流、B 相电流、C 相电流、AB 相电流等近 40 个维度,以及正向有功电度和、正向无功电度和等 4 个度量,这么庞大的维度指标如果不做维度优化,将会有 2^40 个 Cuboid,Kylin 会提示无法创建该 Cube。
为了缓解 Cube 的构建压力,Kylin 提供了 Cube 的高级设置。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierarchy Dimension)和强制维度(Mandatory Dimension)等。通过对电表设备的维度进行分析,最终确定了 2 个强制维度,电压、电流等多项常量维度组合成一组联合维度,year_start、month_start 等时间衍生维度组合成一组联合维度,正向有功电度等特殊维度不做处理。优化后的维度配置如下图所示。
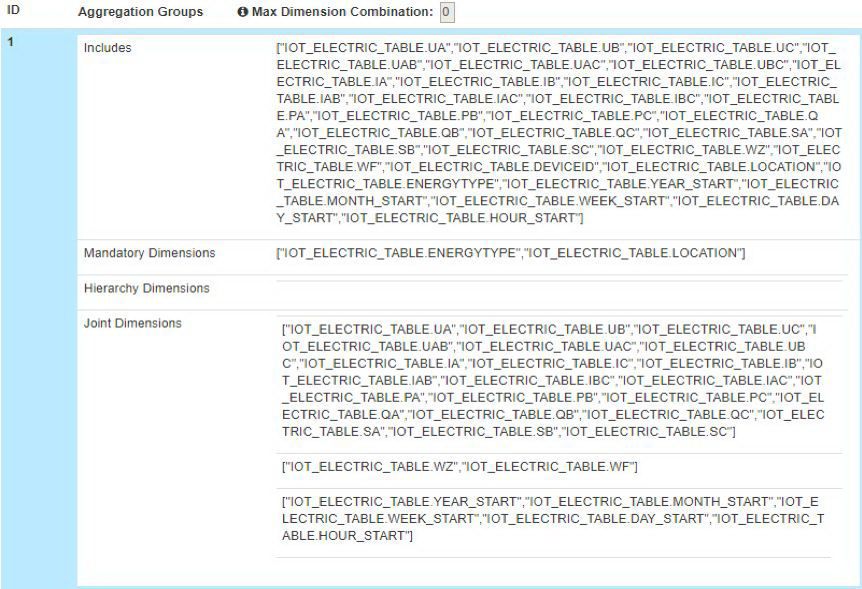
同时,我们也尝试过将常量维度和特殊维度拆分开,独立构建不同的 Cube 并对外提供查询,但考虑到多租户场景下要维护多个 Cube,因此放弃了这种做法。
对维度进行合理配置,可有效对 Cuboid 进行剪枝优化,减少不必要的资源浪费,筛选出真正需要的 Cuboid,有效降低构建时间,提高集群资源的利用效率。我们根据 Kylin 的高级配置对维度进行配置后,虽然牺牲了某些场景的查询性能,但是极大的优化了聚合的性能。以下是优化之后的性能指标(一个小时 Build):
运维监控
由于多租户情况下,存在并行的 Build Cube 操作,那么就可能存在 Cube 构建失败的情况,从而导致数据分析结果不准确。为了避免这种情况,我们做了两部分工作:在 Job 构建成功时会在系统日志中打印出相关信息;Job 构建失败时会及时给运维人员发送短信通知,哪个租户的哪个 Cube 构建时出现错误,以便运维人员能够快速的定位构建失败的 Job Name 并解决相关问题。
总结
针对 SaaS 平台下物联网的能耗管理问题,使用 Kylin 作为 OLAP 引擎,有诸多优势。
对开发人员来说,在协同开发时,Kylin 工程师只需定义好各模块的自动化创建 API,如创建 Project、绑定 Kafka DataSource、同步 Hive 维度表、创建 Model、创建 Cube等,其他部门按一定规则调用就可完成 SaaS 形式的系统创建。此外,开发人员不再需要担心库满而进行倒库操作。
数据分析师使用 Davinci 创建可视化面板时,以 Kylin 作为分析引擎,实现海量数据分析结果的实时展示。
对于用户而言,通过前端查看相关数据时,对比传统关系型数据库查询方式,Kylin 能够以更低的延时呈现出数据分析的结果。
这里仅仅展示的是 Kylin 赋能物联网的一个应用场景,我们后期将继续探索更多的应用可能。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论