

摘要:本文简单介绍了 NAS 的发展现况和在语义分割中的应用,并且详细解读了两篇流行的 work:DARTS 和 Auto-DeepLab。
自动网络搜索
多数神经网络结构都是基于一些成熟的 backbone,如 ResNet, MobileNet,稍作改进构建而成来完成不同任务。正因如此,深度神经网络总被诟病为 black-box,因为 hyparameter 是基于实验求得而并非通过严谨的数学推导。所以,很多 DNN 研究人员将大量时间花在修改模型和实验“调参”上面,而忽略 novelty 本身。许多教授戏称这种现象为“graduate student descent”。近两年,学术界兴起了“自动网络搜索”取代人工设计网络结构。2016 年,Google Brain 公开了他们的研究成果 NASNet【1】,这是第一个用自动网络搜索 Neural Architecture Seach (NAS)完成的神经网络,为深度学习打开了新局面。NASNet 是由一系列 operation(如 depth separable conv, max pooling 等)叠加而成。至于怎样选择 operation,作者用强化学习(RL)的方法,用一个 controller 网络随机组合 operations 生成模块,通过评估选择最优模块组成网络结构。Google 提供的云上服务 Cloud AutoML 正是基于 NAS 方法,根据用户上传的数据自动搜索神经网络再将结果输出。迄今为止,国内外很多工业界和学术界的 AI Lab 都有 NAS 相关工作:Google Brain 提出了 NasNet, MNasNet 和 Nas-FPN,Google 提出 MobileNetv3,Auto-DeepLab 和 Dense Prediction Cell(DPC);MIT Han Song 团队提出 ProxylessNet;Facebook 提出 FbNet;Baidu 提出 SETN;腾讯提出 FPNAS;小米提出 FairNAS;京东 AI 提出 CAS;华为诺亚有提出 P-DARTS 等。通过各大实验室对 NAS 的研究成果,似乎可以看出自动网络搜索将会成为趋势。
接下来我们简单介绍一下 NAS 的流程,详细内容可参考【2】。NAS 的架构主要包含三部分:搜索空间 Search Space,搜索策略 Search Strategy 和评估机制 Performance Estimation(如下图)。
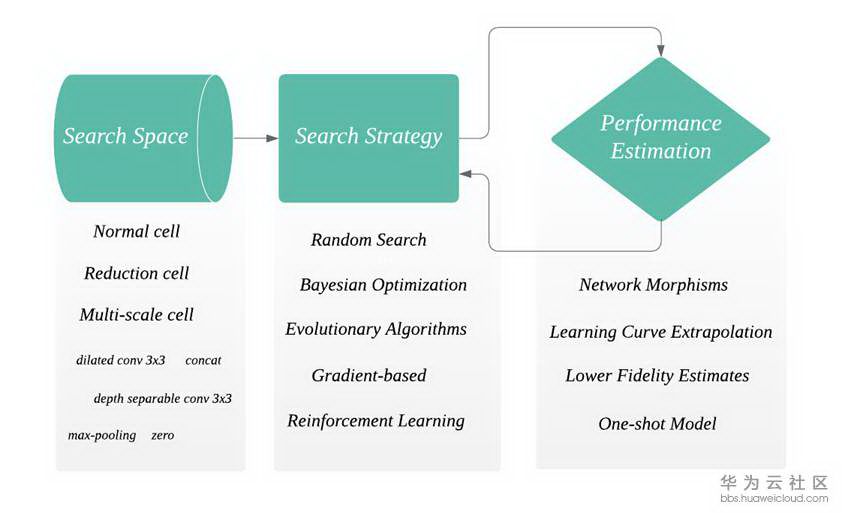
首先搜索空间会定义一些模块(cell),operations(例如 dilated conv 3x3),和宏观网络结构。cell 是由若干个 operation 组合而成。通常来说,NAS 会自动搜索出一些可以重复的 cell,将 cell 按照设定的宏观网络结构堆叠起来形成 network。Zoph et al.提出了两种 cell,normal cell 和 reduction cell【3】。Reduction cell 有改变 spatial resolution 的功能。这两种 cell 在现有的算法中最为常见。此外还有来自 CAS 网络【4】的 multi-scale cell,作用和 ASPP 类似可用作 decoder。至于对宏观网络结构的设定,早期的工作会采用 chained-structured,或者带分支结构 multi-branch 例如 ResNet 和 DenseNet 带有 skip 和 shortcut。
搜索策略在 NAS 中至关重要,因为它决定了下一步要选择哪一个 cell 或者 operation 组成网络结构。搜索的目的就是让现有的网络结构在 unseen data 上得到最好的效果。如前文提到,第一篇工作 NASNet 中用到了强化学习作为搜索策略。虽然实验结果尚可,但强化学习耗时过长并且需要大量 GPU 资源。NASNet 就是用几百个 GPU 搜索了几天才完成,这对于资源少的研究人员来说不可能完成。继 NASNet 之后早期的工作多是基于 RL 完成搜索。随着其他方法的研究,如 random search, Bayesian optimization, Gradient-based, evolution algorithms,搜索时间在下降并且 GPU 使用量也在减少,使得 NAS 得以普及。感谢https://github.com/D-X-Y/Awesome-NAS 提供了搜索策略的调研。
由于一个神经网络通常有几十甚至上百层,结构也很复杂,一个及时并有效的反馈对于减少搜索时间很有帮助。最简单的方法是把训练数据分成两部分,train data 用来训练网络结构,validation data 用来评估当前搜索到的网络结构。一般来说,一个好的评估机制要兼具速度和准确度,举个例子,train data 少则网络结构训练不到位,train data 多则搜索时间过长。来自 Freiburg 大学的 Elsken 团队发表了关于 NAS 的调研,里面对于评估方法讲的很详细,请挪步【2】。
自动网络搜索在语义分割上的应用
相比于目标检测,语义分割可以更好的解析图像,因为图像上的每一个 pixel 都会被分类。所以语义分割可以完成目标检测无法完成的任务,如自动驾驶的全景分割,医疗图像诊断,卫星图分割,背景抠图和 AR 换装等。过去的五年继 FCN 之后,很多神经网络在公开数据集上都有不错的成绩。随着 AI 产品落地,对神经网络性能的要求更为严格:在保证 accuracy 的前提下,在有限制的硬件资源运行并且提升 inference 速度。这为设计神经网络增加了很大难度。所以 NAS 是一个很好的选择,它可以避免通过大量调参实验来决定最优网络结构。在语义分割之前,NAS 在图像分类和目标检测上均有成功的应用。我们总结了近两年比较流行的 NAS 在语义分割上的工作。多数的语义分割的网络都是 encoder-decoder 结构,在这里我们对比了实际搜索的部分,搜索性能耗时和方法。由于每一个 work 都在不同实验环境下进行,所以实验结果没有直接进行对比。
(1)第一篇将 NAS 应用于语义分割的工作来自 Google DeepLab 团队,作者是 Liang-Chieh Chen 等一众大佬。DeepLabv3+的准确度已经达到一定高度,继而 DeepLab 团队将研究方向转移到了 NAS 上面。基于和 DeepLab 同样的 encoder-decoder 结构, 在【5】工作中,作者将 encoder 结构固定,试图搜索出一个更小的 ASPP,用到的搜索策略是 random search。在 Cityscapes 达到 82.7% mIoU,在 PASCAL VOC 12 上达到 87.9%,结果尚可但搜索时间过慢,用 370 个 GPU 搜索一周才得到网络,这也限制了该方法的普及。
(2)同样来自 DeepLab 团队,Auto-DeepLab【6】相比之前的工作在搜索效率上有显著的提升。这都归功于它 gradient-based 的搜索策略 DARTS【9】。与上一篇相反,Auto-DeepLab 的目标是搜索 encoder,而 decoder 则采用 ASPP。从实验结果来看,Auto-DeepLab 的准确度和 DeepLabv3+相差不多,但是 FLOPs 和参数数量却是 DeepLabv3+的一半。后文我们会具体介绍 DARTS 和 Auto-DeepLab。
(3)Customizable Architecture Search (CAS)【4】是来自京东 AI Lab 的工作。在搜索空间定义了三种 cell,分别是 normal cell,reduction cell 和新提出的 multi-scale cell。其中 multi-scale cell 是 ASPP 的功能类似,所以 CAS 的搜索区间是针对全部网络。在搜索策略上依然采用 DARTS。值得一提的是,在搜索网络的时候,CAS 不仅考虑 accuracy,还考虑了每个模块的 GPU time,CPU time,FLOPs 和参数数量。这些属性对于实时任务至关重要。所以 CAS 在 Cityscapes 上的准确度是 72.3%,虽然没有很高,但是在 TitanXP GPU 的速度 fps 达到 108。
(4)来自 Adeleide 大学的 Vladimir Nekrasov 团队在 light weight 模型上面做了大量工作,而最近也将研究重心转到了 NAS 上面。在【7】中,作者采用 RL 的搜索策略搜索 decoder。众所周知 RL 非常耗时,所以作者采用知识蒸馏策略和 Polyak Averaging 方法结合提升搜索速度,而这正是本文的 major contribution。
(5)最后一篇来自商汤发布在 Artix 的文章,采用图神经网络 GCN 作为搜索策略,试图寻找 cell 之间最优的连接方式【8】。和 CAS 类似,在本文中每个模块的性能如 latency 也在搜索评估时考虑进去。在 Cityscape 上 GAS 达到 73.3%mIoU,在 TitanXP GPU 的速度是 102fps。
简单总结一下上述工作,我们可以发现 NAS 在语义分割上的应用还算成功,并且很多团队已经在 NAS 上进行研究探索。尤其在 DARTS 类似的高效搜索策略提出后,个人研究者和小团队也可以构建自己的 NAS 网络,而不受制于 GPU 资源。
DARTS: Differentiable Architecture Search
通常来说搜索空间是一个离散的空间,在 DARTS 中【9】,作者将搜索空间定义成一个连续空间,这样一来搜索到的每一个 cell 都是可导的,可以用 stochastic gradient descent 来优化。所以 DARTS 相比 RL 并不需要大量 GPU 资源和搜索时间。在实验中,DARTS 成功用在了 CNN 模型的图像分类和 RNN 模型的 language modelling 任务上。感恩作者提供了源代码 https://github.com/quark0/darts,它可以为我们搭建自己 NAS 模型提供很好的基础。
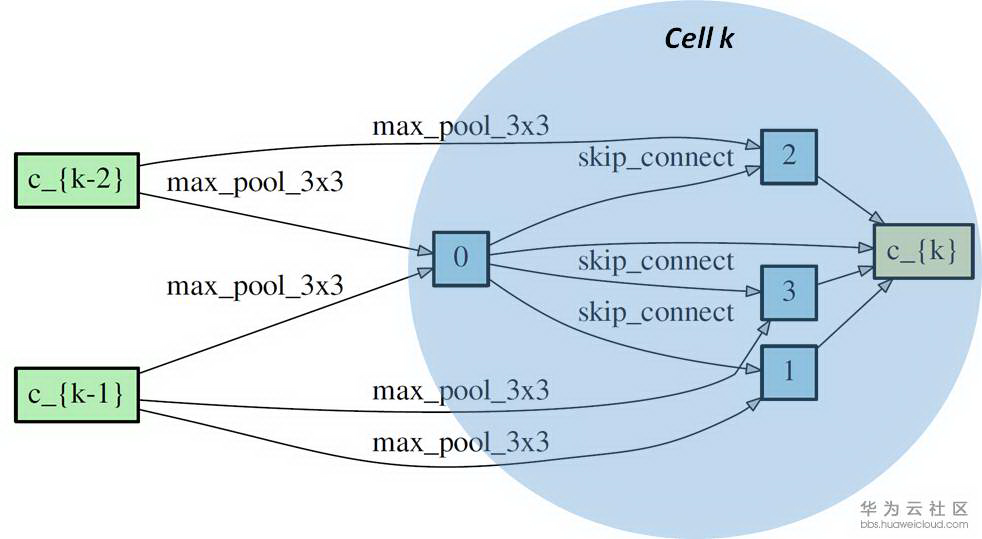
正如前文中提到,多数的 NAS 网络会搜索不同类型的可重复的 cell,然后将 cell 连接起来构成神经网络。这个 cell 通常用 directed acyclic graph(DAG)表示。一个 DAG cell 包含 N 个有顺序的 node,每一个 node 可以看成在它前面所有 node 的结合(就像 feature map 一样是一个 latent representation)。从 node i 到 node j 的连接是某一种 operation 记作 o(i,j). 每一个 cell 都有两个 input node 和一个 output node。下图中是一个 DARTS 展示的 reduction cell。我们可以看到 cell k 有两个 input nodes 分别是 c_{k-1}和 c_{k-2} (来自 cell k-1 和 cell k-2 的 output node),cell k 包含了 4 个 immediate nodes 和一个 output node c_{k} 。o(i,j)是边缘上的 max_pool_3x3,max_pool 等。理论上从一个 node 到相邻的 node 可以有很多种 operation,所以搜索最优网络结构也可以看成是选择每一个边上最佳的 operation。
DARTS 将每对 node 之间的每一个 operation 都赋予一个 weight,最优解可以用 softmax 求得,也就是说有最大 probability 的 path 代表最优 operation,这也是 DARTS 的核心部分。DARTS 在搜索空间中定义了两种 cell,reduction cell 和 normal cell。宏观网络结构是固定的,作者采用了简单的 chained-structured,将 reduction cell 放在了网络结构的 1/3 和 2/3 处。所以说在搜索的过程中,cell 内部不断更新而宏观结构没有变化。我们定义 operation 的参数为 W,将 cell 中 operation 的 weight 记为 Alpha。根据论文和 source code,我们总结了 DARTS 的搜索流程如下图。
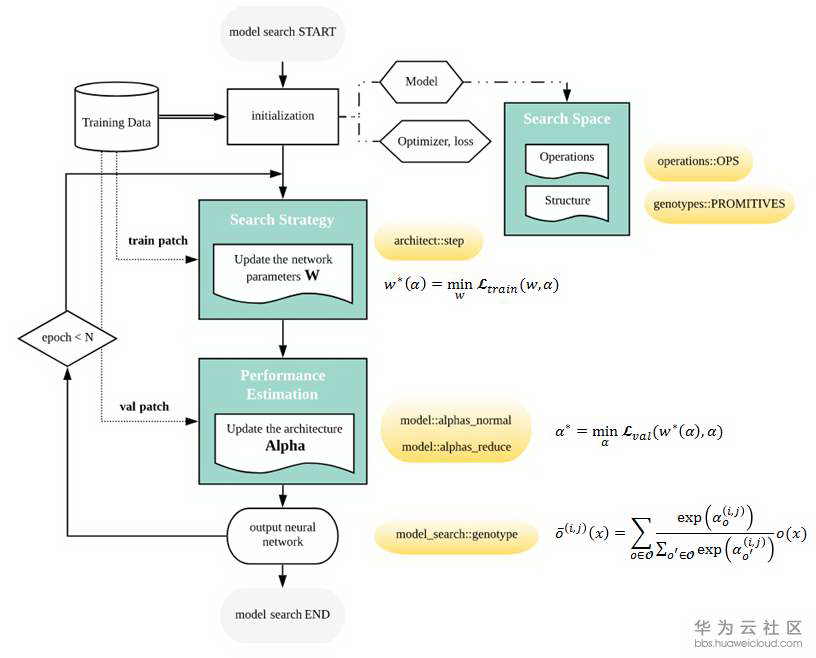
网络搜索的第一步是对模型结构,optimizer,loss 进行初始化。文中定义了几种 operation,代码中的定义在 operation.OPS, 两种 cell 在代码中的定义是 genotypes.PROMITIVES. 参数 Alpha 在代码中定义为 arch_parameters()={alphas.normal, alphas.reduce}. 在搜索过程中,train data 被分成两部分,train patch 用来训练网络参数 W 而 validation patch 用来评估搜索到的网络结构。在代码中,搜索过程的核心部分在 architect.step()。网络搜索的目标函数就是让 validation 在现有网络的 loss 最小,文章中公式(3)给出了 objective:
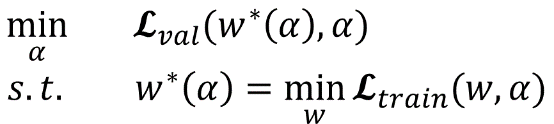
为了减少搜索时间,每一轮只用一个 training patch 去更新参数 W 计算 train loss。在计算 Alpha 的时候涉及到二阶求导,稍微复杂一点,但是论文和代码都给了详细解释,这里不赘述,代码中 architect._hession_vector_product 是求二阶导的实现。在更新 W 和 Alpha 之后,最优 operation 通过 softmax 来计算。文中保留了 top-k probability 的 operation。W 和 Alpha 不断计算更新直到搜索过程结束。
文中进行了大量实验,我们这里只介绍一下在 CIFAR-10 数据上面进行的图像分类任务。作者将 DARTS 与传统人工设计的网络 DenseNet,和几个其他常见的 NAS 网络进行对比,如 AmoeNet 和 ENet 都是常被提及的。DARTS 在准确度上优于其他所有算法,并且在搜索速度上明显比 RL 快很多。由于结构简单效果好,而且不需要大量 GPU 和搜索时间,DARTS 已经被大量引用。
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
基于 DARTS 的结构,Google DeepLab 团队提出了 Auto-DeepLab 并发表在 2019 年 CVPR 上。在 tensorflow deeplab 官网上公布了 nas backbone 并且给出了可以训练的模型结构,但是搜索过程并没有公开。于是我们训练了给出的 nas 网络结构,在没有任何 pre-training 的情况下与 deeplab v3+进行对比。代码参考 https://github.com/tensorflow/models/tree/master/research/deeplab。
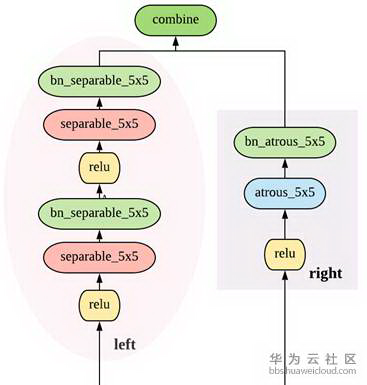
在 DARTS 中,宏观网络结构是提前定义的,而在 Auto-DeepLab 中宏观网络结构也是搜索的一部分。继承自 DeepLab v3+的 encoder-decoder 结构,Auto-DeepLab 的目的是搜索 Encoder 代替现有的 xception65,MobileNet 等 backbone,decoder 采用 ASPP。在搜索空间中定义了 reduction cell,normal cell 和一些 operation。Reduction cell 用来改变 spatial resolution,使其变大两倍,或不变,或变小两倍。为了保证 feature map 的精度,Auto-DeepLab 规定最多 downsampling 32 倍 (s=32)。下图定义了宏观网络结构(左)和 cell 内部的结构(右)。
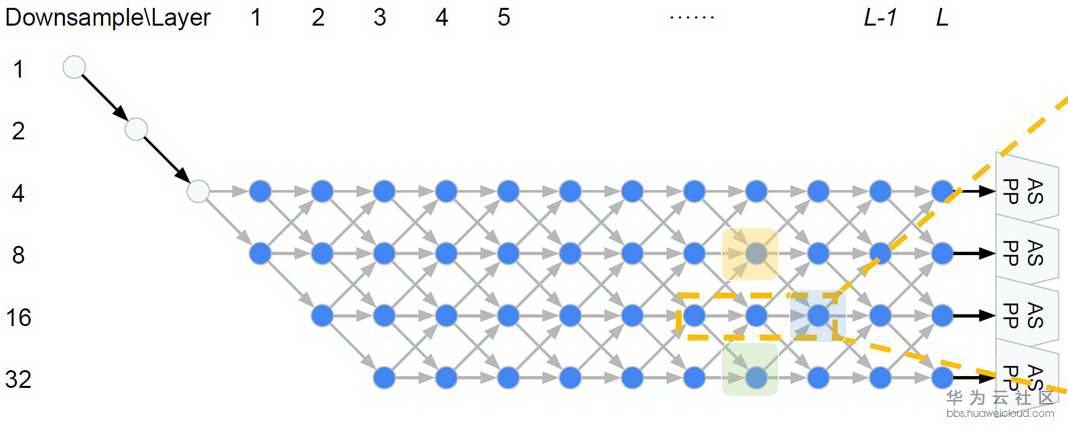
Auto-DeepLab 定义了 12 个 cell,而上图(左)中前面两个白色的 node 是固定的两层为了缩小 spatial resolution。如图左灰色箭头所示,正式搜索之后,每一个 cell 的位置都有多种 cell 类型可以选择:可以来自于当前 cell 相同的 spatial resolution 的 cell,也可以是比当前 cell 的 spatial resolution 大一倍或小一倍的 cell。作者将这些空间路径(灰色箭头表示的路径)也赋予一个 weight,记作 Beta。如图右,每一个 cell 的输出都是由相邻 spatial resolution 的 cell 结合而成,而 Beta 的值可以理解成不同路径的 probability。为了更直观,我们把图右的三个 cell 分别用蓝色,黄色和绿色标注,对应图左的三个 cell。与 DARTS 类似,我们将 operation 的 parameters 记作 W,将 cell 内部 operation 的权重记作 Alpha。所以搜索最优网络结构,即迭代计算并更新 W,Alpha 和 Beta。文中给出每一个 cell 的实际输出为:
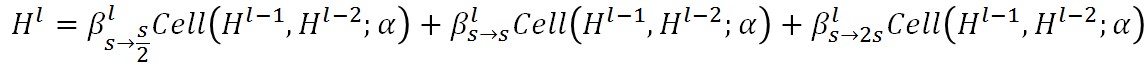
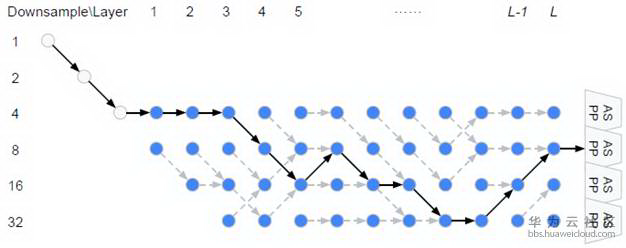
从上面公式可以看出,W 和{Alpha,Beta}要分别计算和更新。所有的 weight 都是非负数。Alpha 的计算方式依然是 ArgMax,而计算 Beta 用了经典的贪心算法 Viterbi 算法。下图给出的宏观网络结构是基于 Cityscapes 搜索到的结果,对应代码中的 backbone 是[0,0,0,1,2,1,2,2,3,3,2,1], 数字代表 downsample 倍数。在模型中,每一个 cell 中的 node 由两个路径组成,如图右。
文中用了三组开源数据 PASCAL VOC 12, Cityscapes 和 ADE20k 做了对比实验。具体实验参数设置和对比算法在论文中有详细说明,这里只对比和 Deeplab v3+。Cityscapes 训练数据尺寸是[769x769],而 PASCAL VOC 12 和 ADE20k 训练数据尺寸是[513x513]。一般来说,Auto-DeepLab 和 DeepLabv3+准确度相差无几,但是速度上要快 2.33 倍,并且 Auto-DeepLab 可以从零开始训练。

除了文中给出的实验结果以外,我们在 PASCAL VOC 12 数据上从零开始训练了 Auto-DeepLab,用代码中给出的模型结构,并且与 DeepLabv3+(xception65)进行结果对比。但是并不是所有结果都能复现,分析原因大概是这样:首先,上文中给出的模型结构是用 Cityscapes 数据集搜索得到,也许在 PASCAL VOC 12 上并不是最优解;其次没有用 ImageNet 做 pre-training,训练环境也不同。我们在下面表格中对比了 FLOPs, 参数数量, 在 K80 GPU 上面的 fps 和 mIoU。

下图中直观对比了 ground truth(第二列),deeplabv3+(第三列)和 Auto-DeepLab-S(第四列)的分割结果。与上面的 mIoU 一致,DeepLabv3+的分割结果要比 Auto-DeepLab 更精准一些,尤其是在边缘。对于简单的图像案例,两者分割结果相差无几,但是在较难的情况下,Auto-DeepLab 会有很大误差(在第三个案例中,Auto-DeepLab 将女孩识别成狗)。

总结
本文简单介绍了 NAS 的发展现况和在语义分割中的应用,并且详细解读了两篇流行的 work:DARTS 和 Auto-DeepLab。从整体实验结果来看,还不能看出 NAS 的方法比传统的模型有压倒性优势,尤其在准确度上。但是 NAS 给深度学习注入了新鲜的血液,为研究者提供了一种新的思路,并且还有很大的提升空间和待开发领域。也许人工设计网络结构将会被自动网络搜索取代。
翻译或有误差,请参考原文https://medium.com/@majingting2014/neural-architecture-search-on-semantic-segmentation-1801ee48d6c4
References
[1] Zoph, Barret, and Quoc V. Le. "Neural architecture search with reinforcement learning."The International Conference on Learning Representations (ICLR) (2017)
[2] Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. "Neural Architecture Search: A Survey."Journal of Machine Learning Research 20.55 (2019): 1-21.
[3] Zoph, Barret, et al. "Learning transferable architectures for scalable image recognition."Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2018.
[4] Zhang, Yiheng, et al. "Customizable Architecture Search for Semantic Segmentation."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[5] Chen, Liang-Chieh, et al. "Searching for efficient multi-scale architectures for dense image prediction."Advances in Neural Information Processing Systems (NIPS). 2018.
[6] Liu, Chenxi, et al. "Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[7] Nekrasov, Vladimir, et al. "Fast neural architecture search of compact semantic segmentation models via auxiliary cells."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[8] Lin, Peiwen, et al. "Graph-guided Architecture Search for Real-time Semantic Segmentation."arXiv preprint arXiv:1909.06793 (2019).
[9] Liu, Hanxiao, Karen Simonyan, and Yiming Yang. "Darts: Differentiable architecture search."The International Conference on Learning Representations (ICLR)(2019).

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论