

2020 年 7 月 9 日,以“智联世界 共同家园”为主题,以“高端化、国际化、专业化、市场化、智能化”为特色的世界人工智能大会云端峰会开幕。会议第三天,旷视在其举办的线上“深度学习框架与技术生态论坛”上,与业内专家、学者围绕旷视6月底发布的天元深度学习框架Beta版的技术升级与生态建设进行了探讨,带领广大开发者走近“天元”,深入了解这一国产深度学习框架的设计之道,探讨深度学习框架与技术生态的未来发展。
作为一款训练推理一体化、灵活高效的新型深度学习框架,天元能够帮助企业与开发者的产品从实验室原型到工业部署平均节省 90%的流程,真正实现小时级的转化能力。
旷视开源天元(MegEngine)这个在内部全员使用、工程实践超过 6 年的深度学习框架,为的是能够将自己的经验与成果同业界分享。通过开源社区的力量,帮助更多开发者把自己的精力地集中在算法的研发和业务场景中,从烦琐的流程,烦琐的性能优化和模型复现中解放出来,真正实现“深度学习开发,从未如此简单”。
据旷视研究院高级技术总监许欣然介绍,从 3 月份开源到 6 月底 Beta 版发布,天元共经历了 5 个版本的迭代,得到了旷视内部与外部开发者们的建议与支持。天元 Beta 版核心技术升级包括三大特性:

1.完善量化训练和量化推理功能
天元 Beta 版本提供了灵活的量化训练和高效的量化推理的能力,让开发者可以快速的完成高精度的量化训练并直接部署到推理侧,以最小的精度代价获得最高的推理性能。
2.添加对 ARM CPU 的支持
天元添加了对 ARM CPU 的支持,在 ARM、CUDA、X86 三个主流计算平台上都提供了经过深度优化的 kernel 实现,结合天元优异的计算图优化技术,在量化、浮点模型上均提供了业界领先的计算性能和内存显存占用。
3.优化推理功能
天元对推理功能做了一系列的功能优化,提供 Profile 工具、上手指南、性能优化教程等内容,帮助开发者快速上手,获得更高的推理性能,让开发者在推理的时候可以使用更方便,开发更高效。
另外,天元 Beta 版新增 10 余个 SOTA 模型,并正式提供中文版 API 文档,还新增了 Objects 365 Dataset 的 API 和多机训练参数打包等功能。
除了功能和性能上的改进之外,天元框架还与小米 MACE、OPEN AI LAB Tengine 等推理框架进行了深度集成。

以下是具体技术细节与性能对比。
模型量化——训练与推理
背景:在当前,提高神经网络推理性能的主流方法是在 GPU 和各类嵌入式设备上,对深度学习模型的推理过程进行量化,即使用 int8 乃至更低精度进行推理。
然而该方案的问题在于,若使用量化后的模型进行推理则可能会面临因量化带来的精度损失。另外,由于模型量化领域发展迅速,投入大规模使用仅两三年,大量开发者当前所使用的量化工具性能参差不齐,模型量化后精度损失较多;又加上种种量化细节不对齐,使得模型转换的步骤进一步加剧了精度上的问题。在这样的条件下,开发者不得不通过更大的量化模型来达成业务目标,使得量化带来的性能提升被抵消,难以充分发挥出设备的全部计算性能。
解决方案:基于天元训练推理一体化架构,同时站在训练和推理的全局视角上优化模型量化的体验和效果,让开发者可以在保持模型精度的同时,获得更大的性能提升。
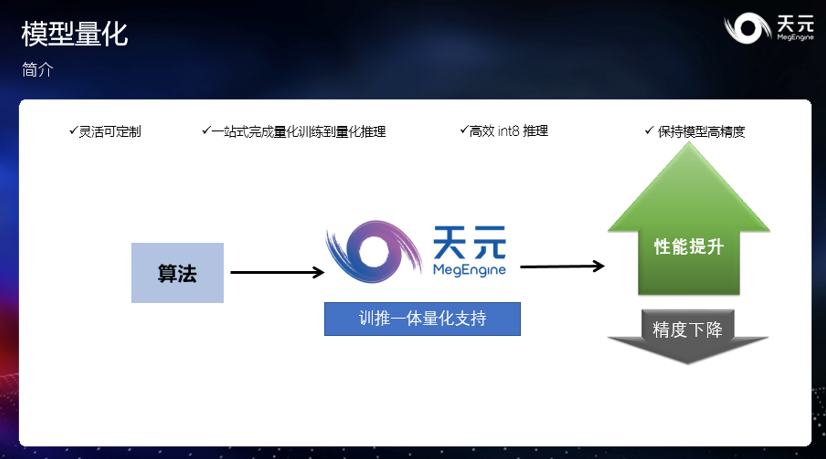
量化训练方式的选择
背景:关于神经网络模型量化,最关键问题是如何选取量化表示时的缩放系数(也被称之为 scale)。针对这一点有两种方案:后量化统计方法(Post Quantization)、量化感知训练(Quantization Aware Training)。

所谓后量化统计方法,即在模型正常训练结束后进行数值统计并量化。这种方法因流程简单而在当前应用广泛。其缺点在于,当模型较小的时候则精度偏低;同时该方法由于训练阶段与量化步骤分离,导致训练与推理阶段精度不一致,只有在完整训练之后才能知晓量化的具体精度下降程度。
量化感知训练则指的是在训练阶段就模拟量化推理过程,让模型对量化过程进行适配。此方法能让模型保持更高精度,且在训练阶段就能掌握推理的精度,其缺点在于流程较为复杂。

解决方案: 基于旷视内部学术研究与工程实践积累的大量经验,天元实现了方便快捷量化感知训练功能,让开发者可以只增加少量流程,就能利用上量化感知训练的能力。这使得旷视的研究人员与工程师在给定算力下,能够获得更高的推理精度,进而获得算法优势。另外,在训练阶段即可知晓最终推理精度,加快了模型迭代速度,让模型的开发过程更为高效、可控。
量化接口使用流程

具体而言,整个量化接口的使用分为五步。如上图,在正常模型训练的搭建网络、训练网络、生成序列化模型三步上,额外增加了量化参数配置、量化感知训练两个步骤。
一般来说,在默认的量化配置下,开发者就可以获得比较优良的精度,这对应于右侧黄色高亮的三条语句,操作简单、方便。
量化接口设计
量化接口的具体设计,分为浮点模块、伪量化(FQ) 模块和量化模块。三者分别执行浮点、模拟量化和真实量化工作。
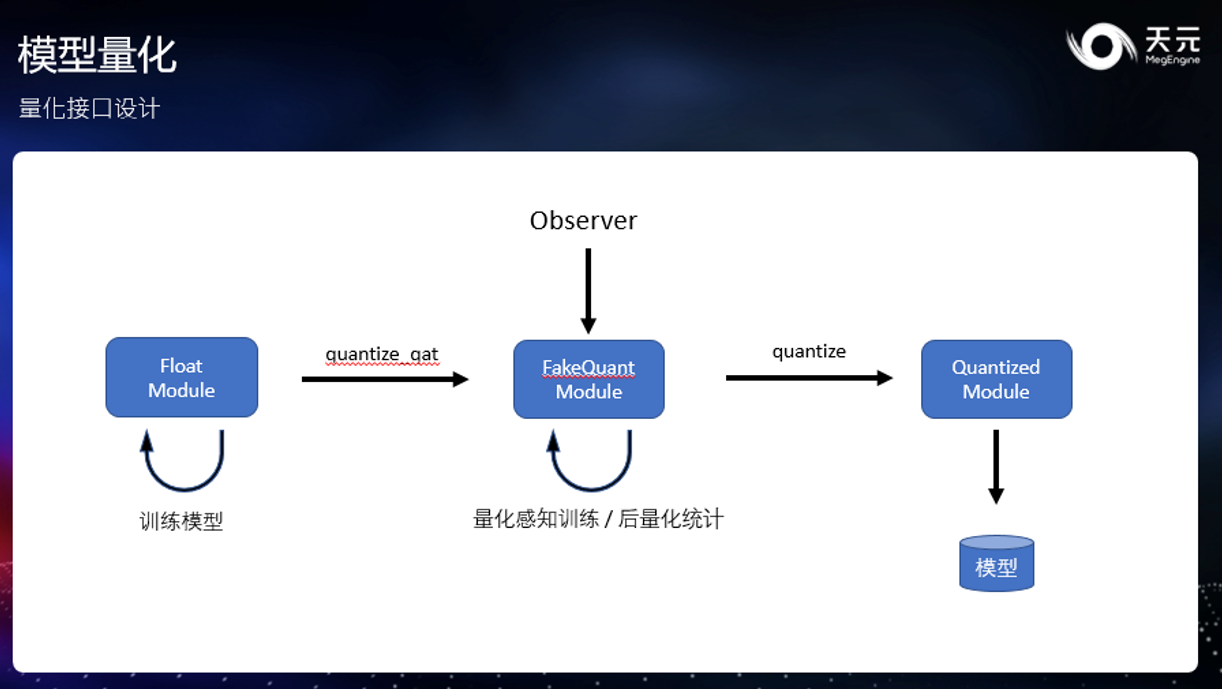
具体而言,开发者首先在普通模块上进行正常的模型训练工作;然后,可以转换至伪量化(FQ) 模块,通过配置不同的 Observer 来配置不同的量化参数 scale 获取方式,从而进行不同的量化感知训练或进行后量化统计。
在完成量化参数 scale 的统计后,开发者便可以再转换至量化模块,直接进行推理或者序列化存储生成模型。
天元的这套量化接口设计借鉴了 PyTorch 的方案,并在其基础上进行了一系列改进和优化,方便扩展。
训练:灵活多样的量化配置

天元 Beta 版提供的量化接口让开发者能够使用不同的 Scale 获取方法,多种基于统计或基于学习的方式,以及灵活配置量化策略、位宽。此外,由于量化方法在整体上仍处于发展当中,因此天元量化接口的设计宗旨是便于扩展。通过支持用户自行注册量化实现,便于兼容各类特殊硬件和新的量化方法。
训练:量化参考模型与操作文档

值得一提的是,天元 Beta 版除了提供量化功能外,还在模型仓库中提供了完整的模型复现。如上图所示,三个模型在全 int8 量化下准确率仅下降约 1%。此外,Beta 版本还提供了详尽的量化操作文档,帮助开发者们快速上手。
推理:多平台直接部署
模型量化的推理方面,在天元 Beta 版中,量化模型的推理方法与浮点模型完全一致,开发者仅需直接读取序列化模型执行,在各个平台上都可以直接载入并进行高效推理。

在训练阶段,开发者可以非常灵活地控制网络量化模块,混合使用各种量化策略;在推理部署阶段,系统会使用与训练相同的设置,无需额外配置,便能保证一致。
各个框架对 int8 量化的定义在细节上有诸多不同,对天元来说,训练后直接可用于推理,一份模型,全平台可推理,开发者不用对每个平台都学习不同的部署流程。这免除了模型转换可能带来的各类误差问题,也不用担心转换时算子不支持,转换后精度不对齐等问题。
推理:高效原生 int8 实现
作为框架的设计者同样也是使用者,天元团队深知对于开发人员而言,性能往往是在推理阶段最关注的指标,为了性能,即便麻烦也需要将模型转换到更快的推理框架上。
为此,天元在各主流计算平台上提供的高效 int8 实现,让开发者不再需要面对上述痛苦,保证开发者用天元框架训练后能够直接进行推理部署。
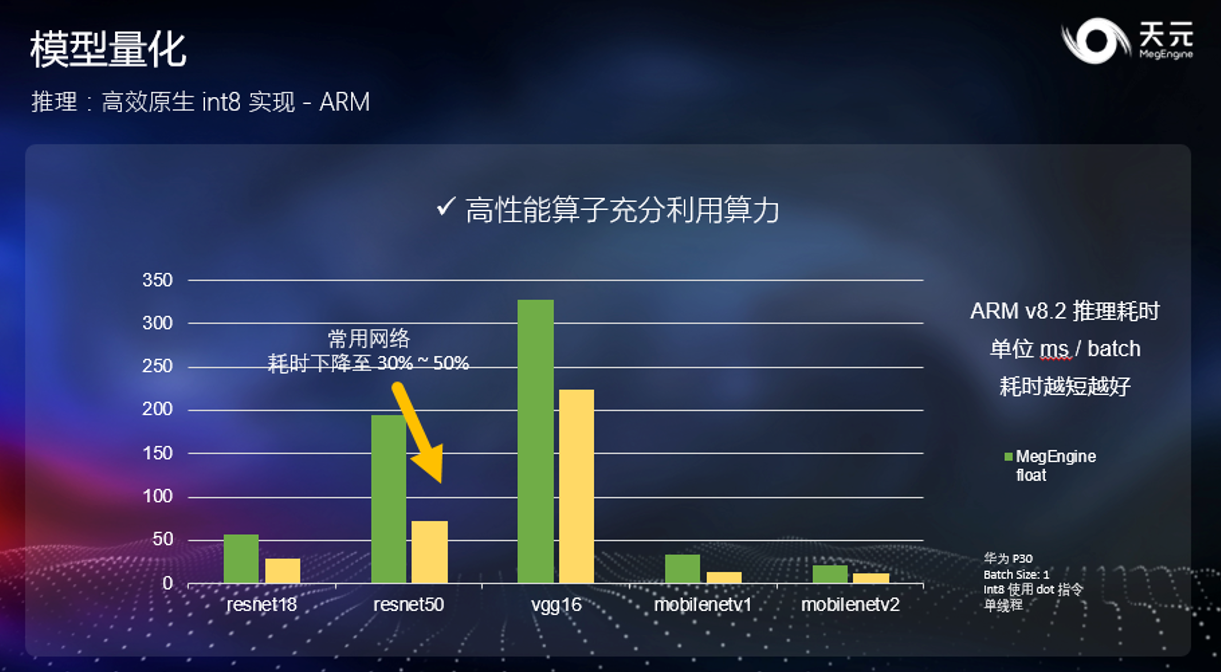
上图展示了 ARM 上的推理性能对比。可以发现,通过转换至 int8,天元使得常用网络获得了至多 3 倍的提速。此外,针对手机上常用的小模型,天元提供了更好的优化效果,加速效果更佳明显。
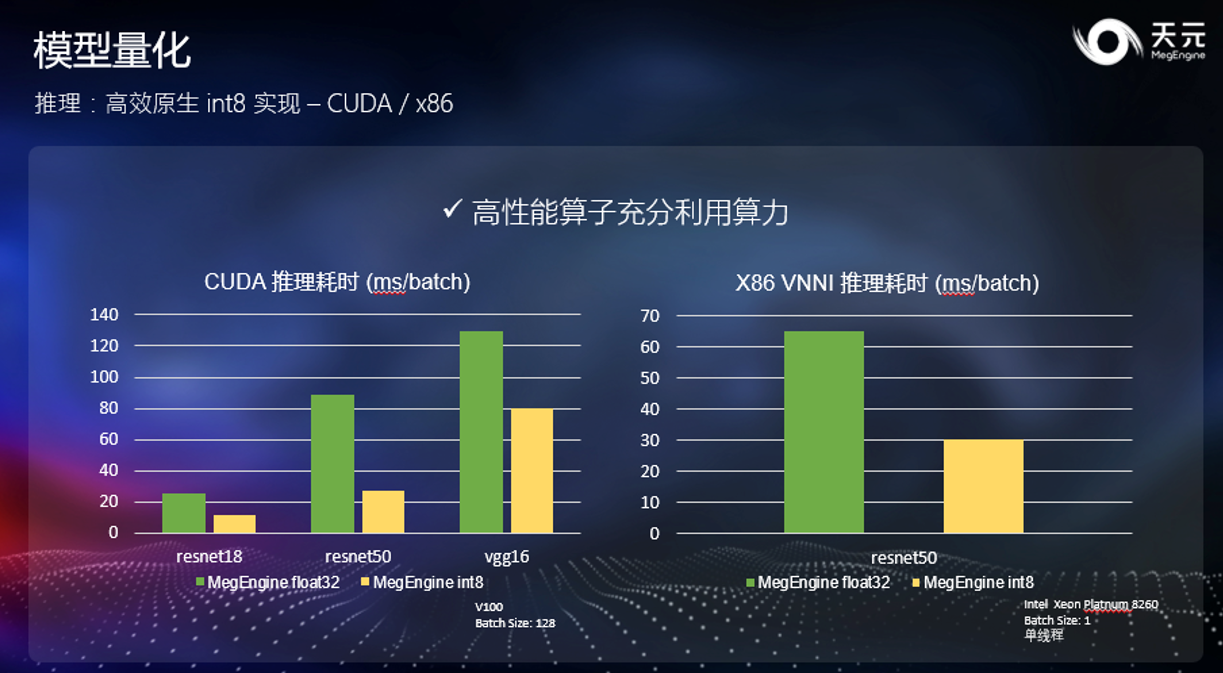
此外,天元在 CUDA 和 x86 上也提供相对于 float32 显著的提速效果。与 Arm 类似,int8 推理的耗时仅有 float 模型的 30%~50%。在 CUDA 上,天元可以充分发挥出 Tensor Core 的计算能力,榨干显卡的计算能力;而在 X86 上,由于 X86 指令集的原因,天元可以在支持 AVX512-VNNI 指令集的最新一代处理器上得到比较明显的 int8 提速。
综上,原生的 int8 高效推理性能,可以让开发者方便地进行模型推理部署,同时充分发挥出硬件的计算能力。
推理功能优化
优秀的原生 ARM 推理性能
除优秀的模型量化功能外,天元在 Beta 版本还提供性能高效的 ARM 算子实现。天元引入 NCHW44 layout,通过将张量的内存排布进行调整,进一步优化访存,并降低各种边界情况的判断,提升计算性能;同时软硬结合,在支持的设备上,使用最新的 ARM dotprod 指令,编写高质量的各类卷积算法实现,最终获得了高效的推理性能。
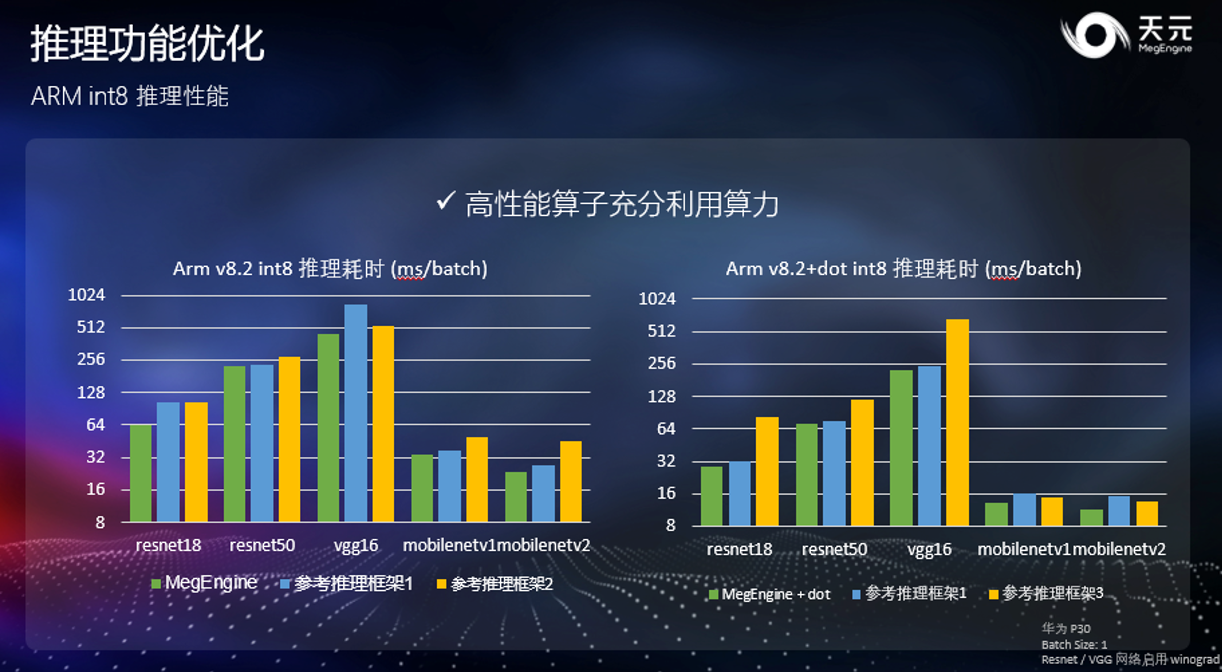
在 int8 推理时,天元依靠深度优化 im2col、winograd 和 direct conv 等算子,在各类网络上都达到了优秀的性能指标。上图分别展示的是不启用 dot 指令和启用 dot 指令的性能对比,可以发现,天元均提供了优异的性能表现。
另外,借助 ARM 的 dot 指令,天元 ARM 上的 int8 推理在 ResNet 上从 64ms 降低到了 30ms 以内,在一系列常用网络上都可以获得两倍以上的大幅度加速。因此如果手上有支持 dotprod 指令的设备,开发人员可以在天元的支持下获得巨大的性能提升。
值得一提的是,在一些不支持 dot 指令的设备上,通过使用 winograd 可以降低乘法指令个数,从而在 ResNet、VGG 这类网络上获得比较显著的加速。为了追求加速比,业界常见的做法是对 weight 进行限制,将表示精度限制在 6bit 内,从而避免累加结果溢出。然而这存在的问题在于,需要在模型训练时就进行特殊处理,导致一个模型难以在全平台部署;同时,这也降低了量化网络的推理精度,限制了使用场景。
天元作为一个训推一体的框架,追求训练与推理侧功能的精确对齐,针对上述问题,创新性地使用 float 作为中间计算格式,实现了 winograd 算法。这种方法的优点在于,对 weight 没有特殊要求,能够与训练时的设置精确对齐,确保精度没有损失;同时,这种算法还更充分地利用上了计算单元,提高计算性能,确保开发者可以随时启用获得性能提速,无需担忧精度问题。
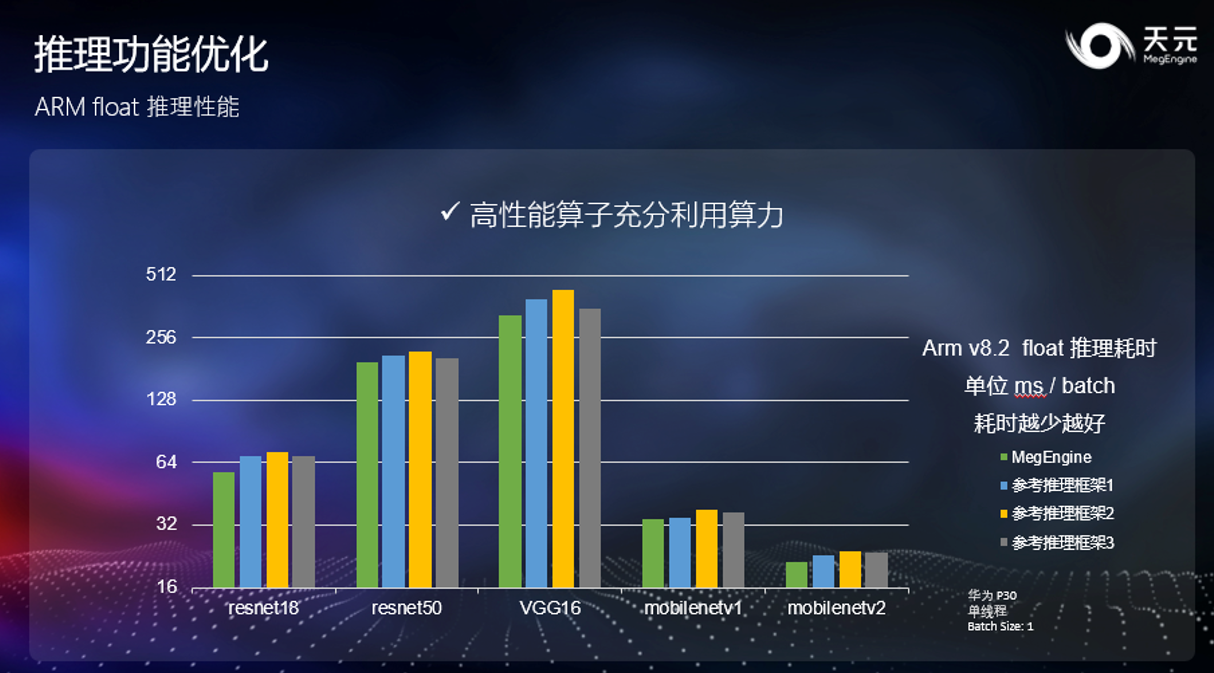
除了 int8 推理之外,考虑到仍有大量开发者在使用 float 模型进行推理工作。为了让这些开发者也可以得到最优的性能,天元在 float 算子上也进行了大量优化,使得各类常见的模型获得了业界领先的性能,开发者可以在不改动原有工作流程的情况下,获得性能上的提升。
ARM int8 内存占用
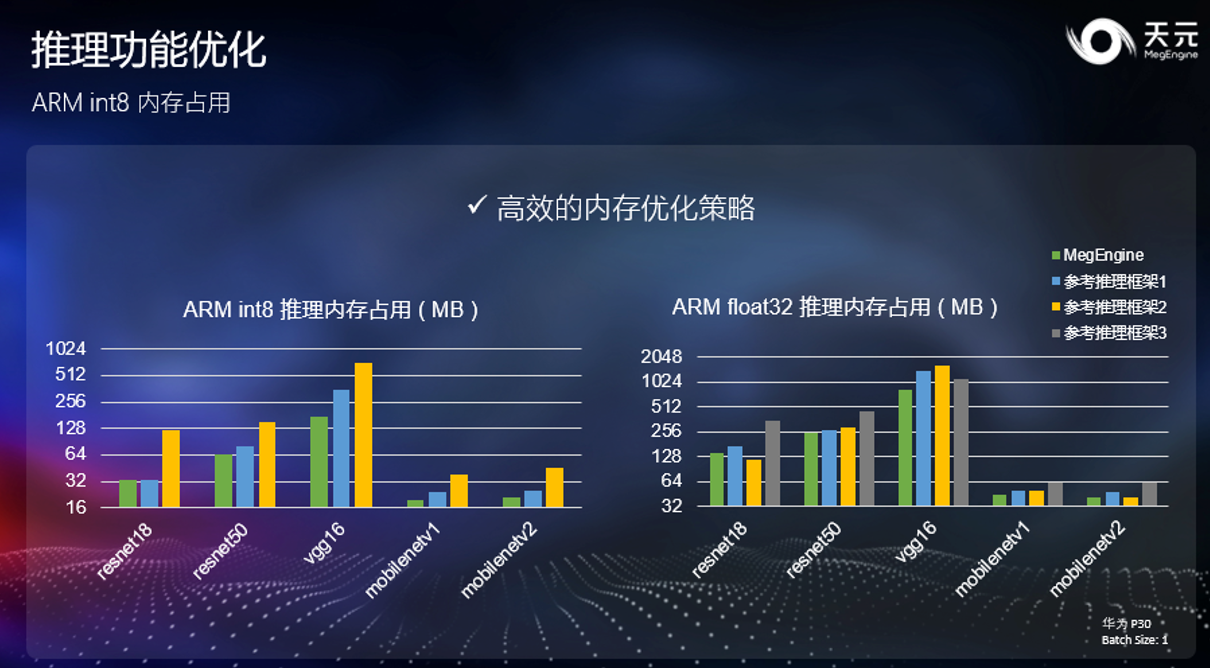
在深度学习的应用中,运行时内存占用也是一个重要的指标。天元对训练侧的自动内存优化策略进行了充分打磨,实现了内存占用和推理性能之间的良好平衡。上图展示了天元在内存占用上的优势。
天元仅依靠通用优化策略,便实现了对任意模型结构优良的优化表现,使得框架无需针对网络结构进行特殊优化。各领域开发者在使用自己的模型结构时也能有较低的内存占用。
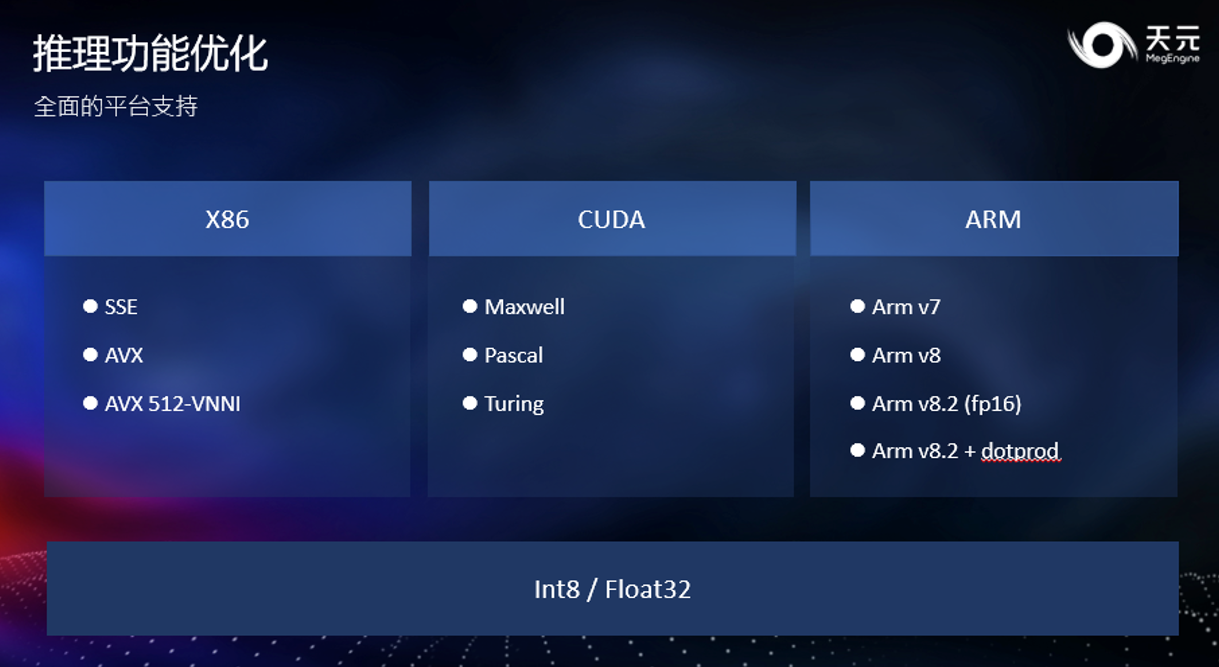
至此,天元获得了在各主流计算平台的高效推理能力。在 X86 / CUDA / ARM 的各种子架构上,均提供性能经过深度优化的算子,保证了推理时的高性能,让开发者可以实现训练-推理一体,免于模型转换。
推理工具与教程
配合本次 ARM 能力的放出,天元在官网上提供了完整的部署流程教程,帮助大家快速上手端侧推理的开发步骤。
另外,天元也进一步优化了推理方面的使用体验,提供性能分析工具和优化手册,方便开发者找到性能瓶颈,提高模型推理性能。
最后天元针对跨平台编译进行优化,开发者可以利用天元在 Linux / Windows /macOS / iOS / Android 上进行推理。
各平台内置常用图像处理算子

除了 NN 算子之外,在深度学习模型应用的场景中,各类 CV(也就是图像处理)算子往往也作为模型的预处理步骤存在,这些步骤的性能和精度会高度影响一个深度学习模型的落地效果。
天元内置了常用的 CV 算子,并进行了高度优化,它们可以作为模型的一部分存在,实现框架的统一优化。在推理时,解码后的结果可以直接输入框架,通过一次调用完成全部 CV 操作和 NN 算子,简单方便。
在深度学习模型的落地中,一个重要的步骤称为“对分”,它能确保模型训练与最终推理的行为完全一致。天元提供的 CV 算子在各平台间对齐精度,尽全力避免训练与推理的差异,降低其中的误差,从而显著降低对分的成本,助力模型快速落地。
新增复现模型与训练功能增强
除本次核心技术升级外,天元也一直在更新更多模型复现,助力开发者利用天元完成更多工作。
包括前文提到的量化模型 ResNet、ShuffleNet v1、MobileNet v2,至此天元的分类模型提供了主流 ResNet 系列、ShuffleNet 系列、MobileNet 系列的量化、非量化版本,并提供基于 ImageNet 的预训练权重。
检测模型的训练逻辑比较复杂,天元本次复现了 Faster R-CNN,并提供了 RetinaNet 的量化版本。

另外,本次还更新了两个生成对抗网络。在 CIFAR10 数据集上复现了 DCGAN 和 WGAN 两篇论文的工作,各项评估指标都达到复现的 SOTA 水平。

此外,天元本次提供了两个人体骨骼点复现模型,分别是经典的 Simple Baseline 和 MSPN 网络,MSPN 是旷视在 CVPR 2019 上提出的高效人体姿态估计网络。这两个模型都提供了基于 COCO 数据集的预训练权重,便于大家进行更多实验。
天元从 Beta 版本开始,正式提供中文版 API 文档,让更多开发者可以利用上天元的能力,加入深度学习的时代。此外,还新增了若干算子、Objects 365 Dataset 的 API 和多级训练时参数打包的功能。
开源生态合作
在开源生态的合作方面,天元相信社区的快速发展需要多放的协同努力,不断用创新的方法来解决不同场景下面临的难题。
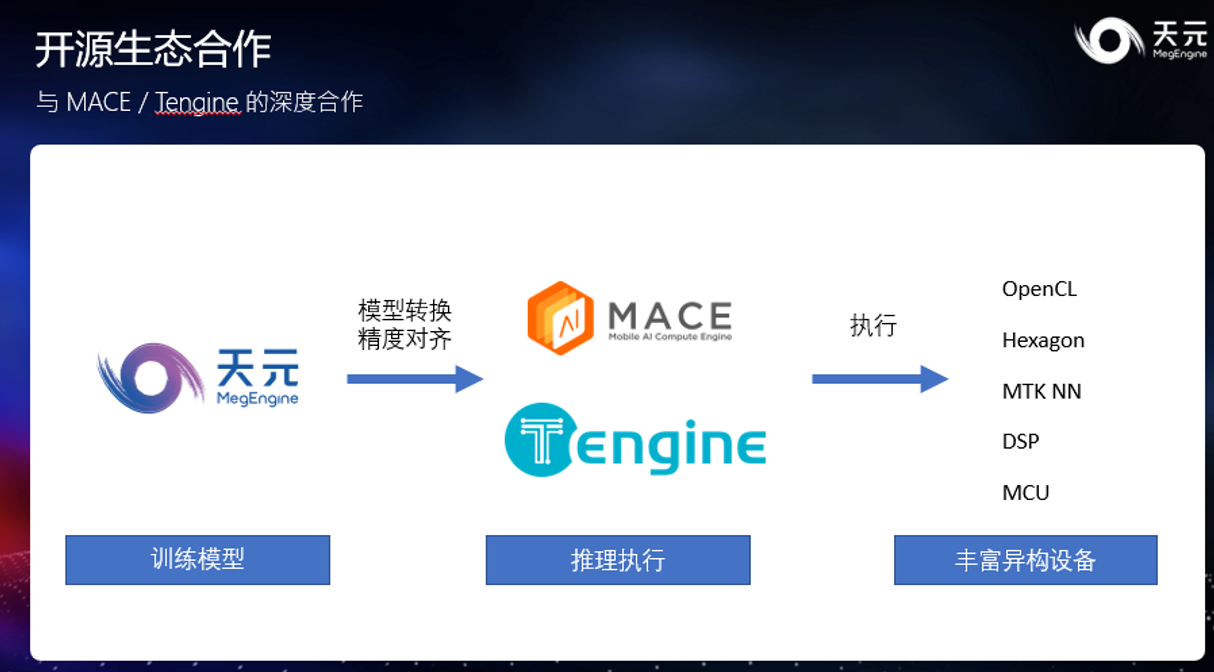
天元积极与各大开源项目展开合作。到目前为止,已与包括小米 MACE、Open AI Lab Tengine 等框架进行了深度集成,用户可以将天元的模型直接转换到 MACE 或 Tengine 中执行,从而获取在各类异构设备上执行深度学习模型的能力。
例如借助小米 MACE 推理引擎,开发人员甚至可以帮助天元模型运行在计算能力极低的微控制器上;而借助 Tengine,深度学习模型能够在多样的异构设备上高效执行。
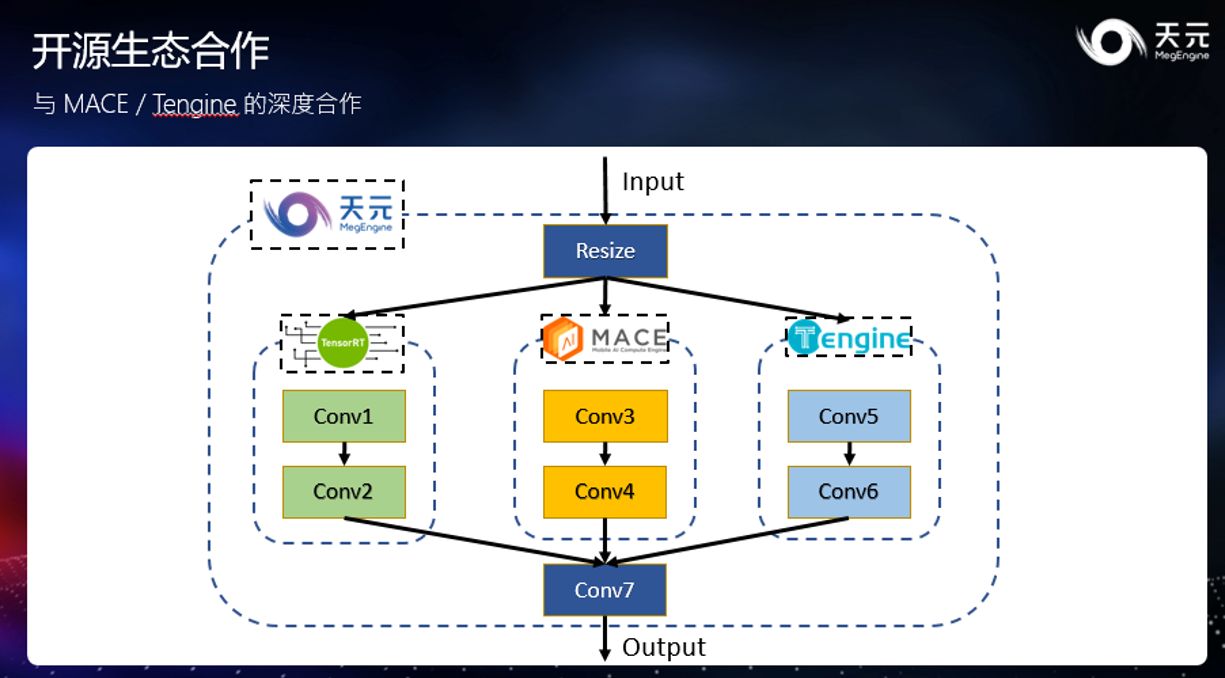
除了基本的模型转换方式之外,天元更是对多种框架进行了深度集成。如上图,天元可以把 MACE 、Tengine 以及 TensorRT 等推理框架作为一个大型的推理算子集成到更大的天元计算图中,从而通过混合使用各个框架,来获得不同框架所提供的特殊能力。
而像各种设备间的内存拷贝,计算的调度工作,则由天元来协助解决,无需用户费心。例如,我们可以结合天元提供的丰富的 CV 算子,高性能 kernel,MACE 和 T engine 的异构计算能力,以及 TensorRT 提供的高性能融合 kernel 等等,让开发者在做推理工作时,不再只能做单选题。这种深度的融合模式与模型转换模式共存,供开发者针对自己的使用场景自由选择使用。
天元发展规划
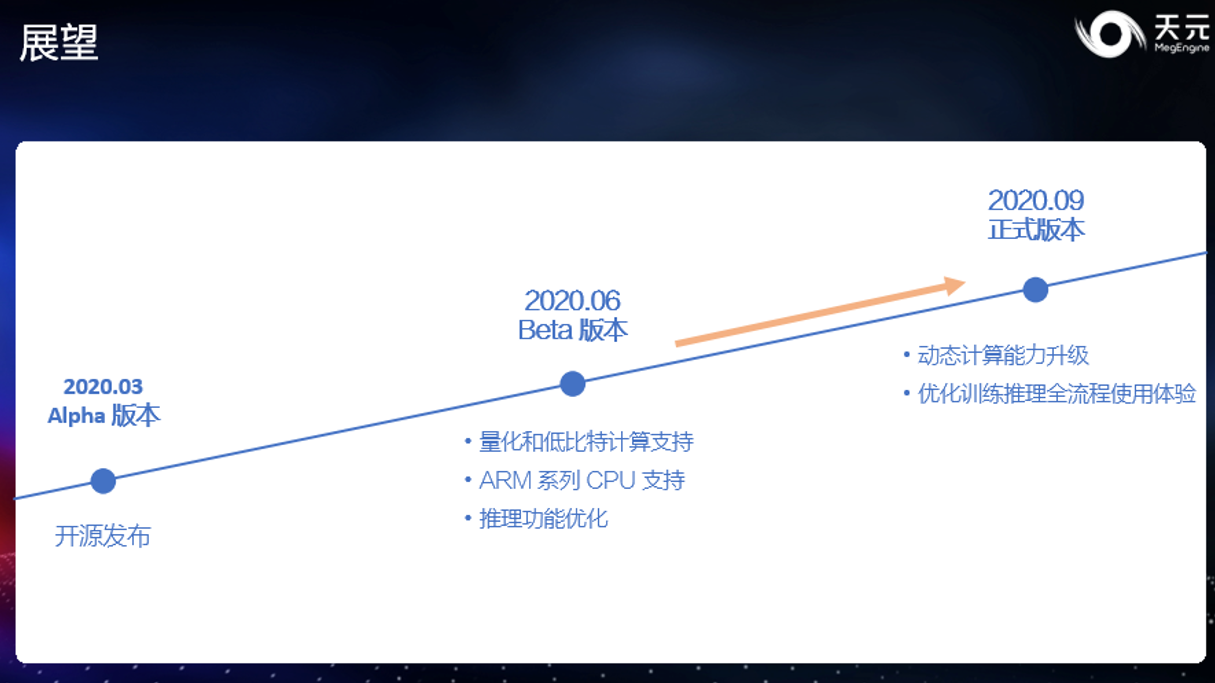
目前,天元团队正在为 9 月的正式版本进行开发,届时希望能够提供更完善的动态计算能力,让训练侧可以更加自由的表达计算形式。另外,天元会进一步优化训练和推理的全流程使用体验,让深度学习从算法到落地更加高效。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论