1.3.2 Spark 基于 Structured Streaming 的实现
Spark 发送数据到 Kafka,及最后的执行分析计划,与 Flink 无区别,不再展开。下面简述差异点。
1. 编写 Spark 任务分析代码
(1)构建 SparkSession
如果需要使用 Spark 的 Structured Streaming 组件,首先需要创建 SparkSession 实例,代码如下所示:
val sparkConf = new SparkConf() .setAppName("StreamingAnalysis") .set("spark.local.dir", "F:\\temp") .set("spark.default.parallelism", "3") .set("spark.sql.shuffle.partitions", "3") .set("spark.executor.instances", "3")
val spark = SparkSession .builder .config(sparkConf) .getOrCreate()
复制代码
(2)从 Kafka 读取答题数据
接下来,从 Kafka 中实时读取答题数,并生成 streaming-DataSet 实例,代码如下所示:
val inputDataFrame1 = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092") .option("subscribe", "test_topic_learning_1") .load()
复制代码
(3)进行 JSON 解析
从 Kafka 读取到数据后,进行 JSON 解析,并封装到 Answer 实例中,代码如下所示:
val keyValueDataset1 = inputDataFrame1.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").as[(String, String)]
val answerDS = keyValueDataset1.map(t => { val gson = new Gson() val answer = gson.fromJson(t._2, classOf[Answer]) answer})
复制代码
其中 Answer 为 Scala 样例类,代码结构如下所示:
case class Answer(student_id: String, textbook_id: String, grade_id: String, subject_id: String, chapter_id: String, question_id: String, score: Int, answer_time: String, ts: Timestamp) extends Serializable
复制代码
(4)创建临时视图
创建临时视图代码如下所示:
answerDS.createTempView("t_answer")
复制代码
(5)进行任务分析
仅以需求 1(统计题目被作答频次)为例,编写代码如下所示:
//实时:统计题目被作答频次val result1 = spark.sql( """SELECT | question_id, COUNT(1) AS frequency |FROM | t_answer |GROUP BY | question_id """.stripMargin).toJSON
复制代码
(6)实时输出分析结果
仅以需求 1 为例,输出到 Kafka 的代码如下所示:
result1.writeStream .outputMode("update") .trigger(Trigger.ProcessingTime(0)) .format("kafka") .option("kafka.bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092") .option("topic", "test_topic_learning_2") .option("checkpointLocation", "./checkpoint_chapter11_1") .start()
复制代码
1.3.3 使用 UFlink SQL 加速开发
通过上文可以发现,无论基于 Flink 还是 Spark 通过编写代码实现数据分析任务时,都需要编写大量的代码,并且在生产集群上运行时,需要打包程序,然后提交打包后生成的 Jar 文件到集群上运行。
为了简化开发者的工作量,不少开发者开始致力于 SQL 模块的封装,希望能够实现只写 SQL 语句,就完成类似上述的需求。UFlink SQL 即是 UCloud 为简化计算模型、降低用户使用实时计算 UFlink 产品门槛而推出的一套符合 SQL 语义的开发套件。通过 UFlink SQL 模块可以快速完成这一工作,实践如下。
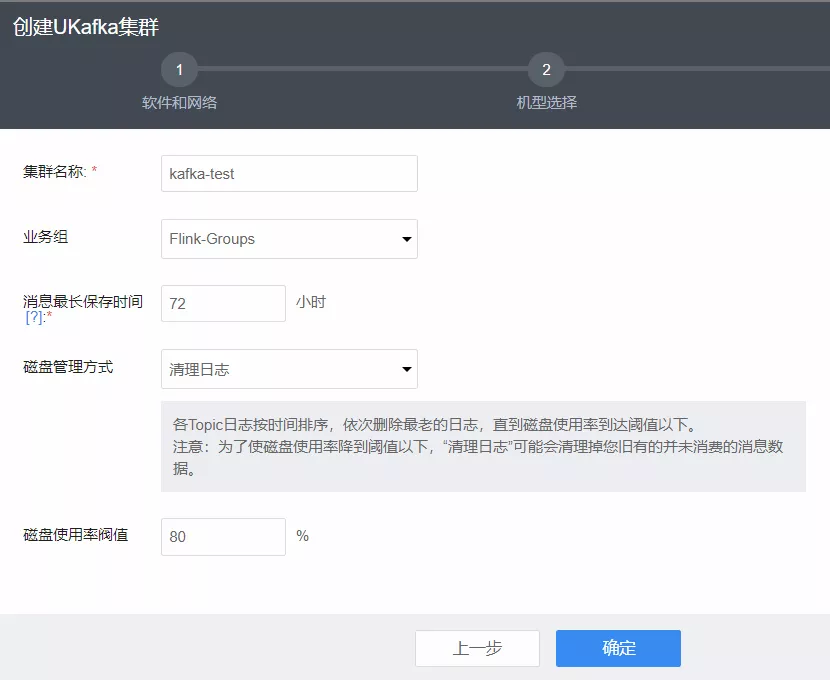
1. 创建 UKafka 集群
在 UCloud 控制台 UKafka 创建页,选择配置并设置相关阈值,创建 UKafka 集群。
提示:此处暂且忽略在 Kafka 集群中创建 Topic 的操作。
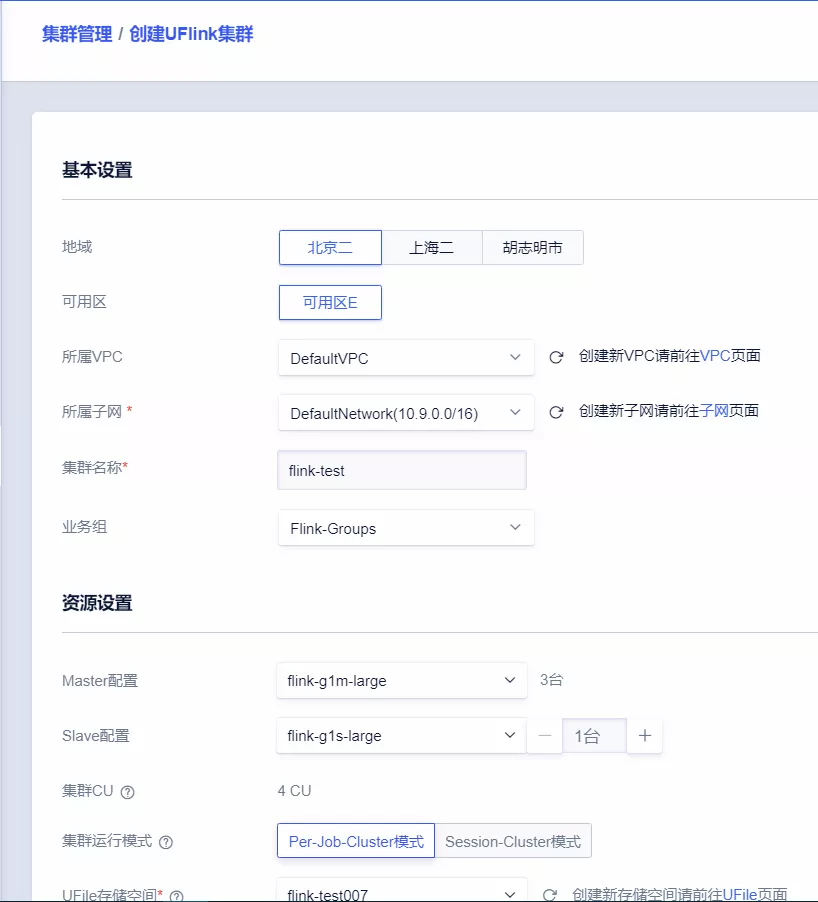
2. 创建 UFlink 集群
3. 编写 SQL 语句
完成之后,只需要在工作空间中创建如下形式的 SQL 语句,即可完成上述 3 个需求分析任务。
(1)创建数据源表
创建数据源表,本质上就是为 Flink 当前上下文环境执行 addSource 操作,SQL 语句如下:
CREATE TABLE t_answer( student_id VARCHAR, textbook_id VARCHAR, grade_id VARCHAR, subject_id VARCHAR, chapter_id VARCHAR, question_id VARCHAR, score INT, answer_time VARCHAR, ts TIMESTAMP )WITH( type ='kafka11', bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092', zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka', topic ='test_topic_learning_1', groupId = 'group_consumer_learning_test01', parallelism ='3' );
复制代码
(2)创建结果表
创建结果表,本质上就是为 Flink 当前上下文环境执行 addSink 操作,SQL 语句如下:
CREATE TABLE t_result1( question_id VARCHAR, frequency INT)WITH( type ='kafka11', bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092', zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka', topic ='test_topic_learning_2', parallelism ='3');
CREATE TABLE t_result2( grade_id VARCHAR, frequency INT)WITH( type ='kafka11', bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092', zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka', topic ='test_topic_learning_3', parallelism ='3');
CREATE TABLE t_result3( subject_id VARCHAR, question_id VARCHAR, frequency INT)WITH( type ='kafka11', bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092', zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka', topic ='test_topic_learning_4', parallelism ='3');
复制代码
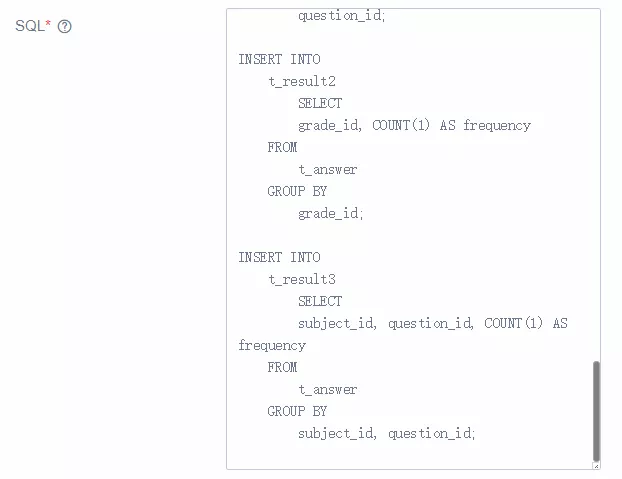
(3)执行查询计划
最后,执行查询计划,并向结果表中插入查询结果,SQL 语句形式如下:
INSERT INTO t_result1 SELECT question_id, COUNT(1) AS frequency FROM t_answer GROUP BY question_id;
INSERT INTO t_result2 SELECT grade_id, COUNT(1) AS frequency FROM t_answer GROUP BY grade_id;
INSERT INTO t_result3 SELECT subject_id, question_id, COUNT(1) AS frequency FROM t_answer GROUP BY subject_id, question_id;
复制代码
SQL 语句编写完毕后,将其直接粘贴到 UFlink 前端页面对话框中,并提交任务,即可快速完成上述 3 个需求。如下图所示:
1.3.4. UFlink SQL 支持多流 JOIN
Flink、Spark 目前都支持多流 JOIN,即 stream-stream join,并且也都支持 Watermark 处理延迟数据,以上特性均可以在 SQL 中体现,得益于此,UFlink SQL 也同样支持纯 SQL 环境下进行 JOIN 操作、维表 JOIN 操作、自定义函数操作、JSON 数组解析、嵌套 JSON 解析等。更多细节欢迎大家参考 UFlink SQL 相关案例展示https://docs.ucloud.cn/analysis/uflink/dev/sql
1.4 总结
UFlink 基于 Apache Flink 构建,除 100%兼容开源外,也在不断推出 UFlink SQL 等模块,从而提高开发效率,降低使用门槛,在性能、可靠性、易用性上为用户创造价值。 今年 8 月新推出的 Flink 1.9.0,大规模变更了 Flink 架构,能够更好地处理批、流任务,同时引入全新的 SQL 类型系统和更强大的 SQL 式任务编程。UFlink 预计将于 10 月底支持 Flink 1.9.0,敬请期待。
本文转载自公众号 UCloud 技术(ID:ucloud_tech)。
原文链接:
https://mp.weixin.qq.com/s/JFcANUK_Vfa7ZMXnn7sruQ











评论