

前几天听老王分享,提到关于 DevOps 在国内外的发展问题,其中就说到早期腾讯做运维时,那个时候也没什么意识是 DevOps,其实就是在变态的业务体量下面一步步做出来的,后来国内 DevOps 的概念火起来了,才发现原来这个叫做 DevOps。
挺有意思的一个话题,听老王讲完,也很有感触,所以分享下我们自己的运维(DevOps)演进过程,有点长,但是会比较完整,看完或许有收获。
第一阶段,只有 Dev,没有 Ops,Dev 是全栈工程师

如何理解?最初的时候,产品和业务形态都处于摸索期,业务复杂度不高,访问量不大,软件能够尽快跑起来推向市场是最重要的,所以架构上不设计的很复杂,单体或分层架构足矣。如下面典型的 LNMP 架构:

服务器和网络设备数量也就是两位数规模,最最一开始个位数也有可能。所以几个开发同学在简单架构下,维护几十台服务器还是没问题的所以,这个时期确实不需要运维工程师(但是并不意味着没有运维的事情),这个逻辑同样适用于测试。
现在很多 startup 公司,直接在云上使用 docker 部署模式,对于基础设施就更不用投入太多精力去维护,所以这些公司都会讲我们的研发团队比较单一,只有开发,没有运维和测试,所有的事情开发都可以搞定。
第二个阶段,Dev+Ops,但不是 DevOps
一个业务发展良好的公司,第一个阶段肯定不会停留太久,毕竟业务在发展,甚至是高速发展,不然公司肯定就没什么前途了。
伴随着业务发展,业务复杂度升高,开发需要将更多的精力放到更多更快地需求实现上,也就是集中精力写代码;同时业务访问量增加,后端设备数量也增加起来(一定时期内堆机器还是可以解决不少问题的),达到几百上千这样的规模,维护的工作量也就上来了。
所以很自然的,这个时候就需要 Ops 这样的角色来管理和维护设备,同时对于 DB、缓存、Web 服务器、存储以及 CDN 这样的通用基础服务也适用这个逻辑。概括一点说,除了写代码,运维最好能把所有之前开发干的事情都干了。
这时 Ops 的主要职责:硬件维护、网络设备维护、DBA、基础服务维护等。
我也是在这样一个阶段进入到现在的公司,我觉得在这个阶段上,我们的意识还是比较好的,比我当时的意识要超前很多,运维团队已经具备工具开发能力,并有了类似机器资源管理、PHP 发布系统、监控等一些工具平台,以及一些非常高效的自动化脚本工具。所以,这个团队从一开始就崇尚能用技术解决问题就绝对不靠人的理念。
但是运维的注意力仍然聚焦在上面提到的基础设施和服务层面,而且运维开发在做的事情更多的是自给自足,也就是满足运维团队内部的工具需求,当然也有一部分原因是受限于当时的技术架构,规模和复杂度有限,运维能做的事情也有限。
所以这个时候是 Dev 是 Dev,Ops 是 Ops,还没有做到 Dev 和 Ops 的融合。
第三个阶段,仍然是 Dev+Ops,但是 Ops 开始组建运维开发团队
这里有个技术架构演进的背景,就是从单体+分层的架构,向服务化架构演进。随着业务复杂度的提升,所有代码和逻辑都放到一个工程里的结果就是下图:
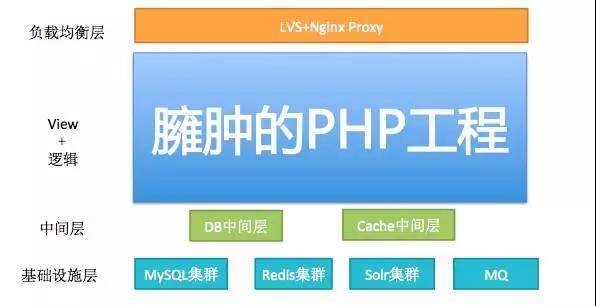
这时耦合严重,牵一发而动全身,开发效率日渐低下,所以要做的事情就是一个字,拆(专业说法:服务化拆分),如下图所示:
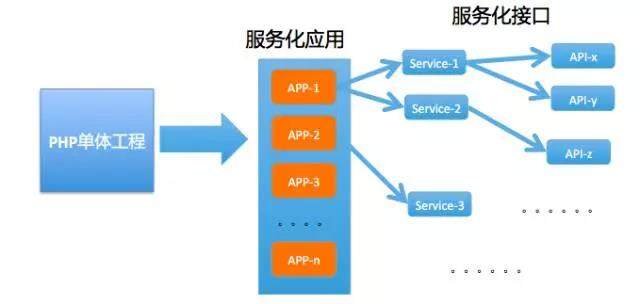
这时,大量的应用被拆分出来,对运维自动化、持续发布、稳定性的要求就随之而来,所以 Ops 开始正式组建运维开发团队来做有规划的、系统性的提升效率和稳定性方面的事情,这个时候的运维开发团队支撑的需求方有两个,一个是运维内部,一个是开发,因为运维会配合支持开发做很多事情,所以很多情况下运维的需求一定程度上就代表了开发的需求,但不是完全代表。
运维内部的需求主要是资源分配、扩缩容、应用管理、域名、VIP 等的管理需求,开发主要是持续交付的需求,两者共同的需求就是监控、容量管理、性能管理、链路跟踪等等。这些具体内容,之前有部分文章分享过,这里就不细说了。
还是说说这个阶段 DevOps 存在的一些问题:
第一个问题, 也是我们遇到的 最大的问题就是,运维开发是脱离实际运维工作的,这个团队的定位还是要从运维这里承接需求,然后开发实现,并不实际参与运维工作,再加上运维开发自身也会有一些独立的想法或者带着之前的经验在设计开发,所以对于现状下的运维工作理解是不够深入的。同时,运维同学自身也不是产品出身,一开始也很难按照产品化的思维模式表达清楚自己的需求,往往就是现实工作场景的口述,所以表达的更像是一个个功能点的堆砌,而不是系统化的建设思路。
所以这里始终就会有个 Gap。结果上,最直接的体现就是运维开发做出来的工具和平台没法很好的满足运维的需求,甚至过程中也会出现一些矛盾,比如运维抱怨运维开发没能很好地实现需求,做出来的东西不好用,甚至是没法用,运维开发也会抱怨运维需求没提清楚,或者说辛辛苦苦做出来的东西运维不用,辛苦都是白费。
所以你看,一个团队并不是有了运维开发和运维自动化就万事大吉了,还会涉及到一些团队管理和运作模式上的问题。
而且现实中,有很多公司的运维开发团队是独立的,运维和运维开发不是同一个主管,甚至不在同一个组织架构下,这样就很容易出现上面说的这个问题。
这里根本原因还是目标不一致,运维是需要一个平台能把自己的事都干了,但是运维开发更多的是考虑你给我提什么需求我做什么需求,目标是做完需求,而至于好不好用,不是最重要的事情。
稍好一点的运作模式,运维和运维开发在某个具体的项目上形成虚拟团队,这个团队的目标和考核方式一致,如果运维和开发的效率得不到提升,团队的整体绩效就会受到影响,至于考核方式和一些细节就不详细说了。记住一点,就是目标一致的情况下,大家才会朝一个方向使劲,事情做地才会更好。
最好的方式,吃自己的狗食,Eat your own dog food.
Ops 去做运维开发,运维开发去做 Ops,这样也就不存在需求传递的过程和 Gap 了,自己做出来的东西自己用,运维开发可以更深刻地理解运维工作,而不是天马行空地凭空 YY。
这样可以让彼此能够站在对方的角度去考虑问题,也就不会有什么抱怨和指责了。
我们当前模式是虚拟项目组模式,好在运维和运维开发团队都在统一团队中,这样可以省去大量沟通成本,目标也可以相对容易达成一致。同时,我在做的一个尝试就是上面说的,Ops 有一部分员工要去做运维开发的事情,运维开发要去做运维的事情,后续应该会把两个团队逐步融合。
总结下第一个问题,我们可以看到不光 Dev 和 Ops 之间会有协作问题,哪怕是运维团队内部的开发,在配合上也会存在问题,这是个细节问题,需要团队管理和项目运作上做一些优化。
第二个问题,就是运维开发和业务开发团队的协作问题,第一个问题可以通过内部沟通和协作的方式去改进,但是对外,只能强调服务意识,这里就一个判断原则,如果你做出来的东西,开发都不用或者意见很大,那只能说你的工作完成不到位,或者在合作协作上是有很大问题的。
第四个阶段,真正的 DevOps,Dev 和 Ops 融合
当 Ops 的能力沉淀到一个个产品平台之后,原来开发依赖运维的人去干的事情,就可以自助地依赖运维平台去做了,也就是日常运维由开发自己做,而不再依赖运维这个环节,真正实现 DevOps。
典型案例就是持续交付做好之后,开发完全可以自助发布,全程无需运维介入。

所以,判断一个团队是不是 DevOps 模式,有一个很简单的原则,上面也提到了,如果运维做出来的东西开发用不上,那就不要叫 DevOps,或许你做的只是运维自动化而已。
我们都可以用这个标准去对照下,答案不言而喻,不信可以试试:)
当然,我们自己也还有很多地方做的不够完善,只能算是这个阶段的过程中,还没有完全达到。后面我们会争取把所有目前运维在做的事情全部沉淀到平台上,让开发自助完成,甚至做到让开发做到开发-发布-再开发的模式,完全不用考虑后端的事情,当然路还很长,必然也会很曲折。
像阿里,做的就更极致,目前就已经不存在 PE(应用运维)团队了,原来的 PE 要么转型去做 DevOps 产品设计或开发,要么就面临一个很残酷的现实,被淘汰。可以预见,阿里未来应该也不再会招纯运维岗位,未来只有开发,可以提升研发效能的开发人才。
国外像 Netflix 和 Amazon 是压根就没有运维这样的角色,运维的事情都是由开发工程师来完成,所以他们也戏称 SDE 是 Someone Do Everything。
所以,运维转型不是一句吓唬人的话,真的已经在我们身边发生了。
最后,说一下我们真实的经历
在上面这些过程中,现在总结下来是一个 DevOps 演进过程,说实话,我们当时并没有 DevOps、持续交付或者 SRE 等等这些概念的意识,摆在我们面前的就是一个个很现实很实际的问题,当时的状态也是一脸懵逼,比如我们采用了 Java 的技术栈,做了服务化拆分之后,非常现实的问题就是你怎么做发布,开发整天盯在运维屁股后面,你们怎么能把发布效率提升上去,你们能不能快点,业务在后面催着上线呢,你们怎么解决我的分批发布不停服问题,你们怎么管理好我们的分支合并和版本管理问题,你们怎么管理好我们的二方包和三方包等等,再比如,出了故障,一群人堆到一起一点点排查,而且有时候找不到问题在哪儿,业务都恢复不了,压力山大到要崩溃,所以到底怎么能提升稳定性、提升排障的效率也是都是一个个非常非常现实的问题。
我们能做的就是从实际问题和业务场景出发,优先解决紧急的、棘手的问题,然后不断地通过业界的图书、社区文章、会议和大牛学习、交流和探讨,不断的完善,再就是招聘到有经验的人,这样可以少走很多弯路,最后也就这样一步步做成现在这个样子了,后来才发现,原来我们这个差不多也可以叫做 DevOps 了,虽然还有很多可以改进和提升的地方。
所以为什么一开始提到说听老王的分享很有感触,说完上面这些实际情况,我们会发现其实过程和经历都是相似的。
虽然这篇文章蹭了 DevOps 的热点,但是我通篇都没有讲或说 DevOps 理念或方法论的东西,所以最后,还是表达一下观点,技术发展和积累都是被业务给逼出来的,实实在在解决问题才是正道,从本质上说,我们没有什么特别之处,只是比较幸运,正在经历这样一个过程而已。
本文转载自成哥的世界公众号。
原文链接:https://mp.weixin.qq.com/s/-wRB4NdV_Ht2kBxrpNc4Fw

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论