

在深度学习大潮之后,搜索推荐等领域模型该如何升级迭代呢?强化学习在游戏等领域大放异彩,那是否可将强化学习应用到搜索推荐领域呢?推荐搜索问题往往也可看作是序列决策的问题,引入强化学习的思想来实现长期回报最大的想法也是很自然的,事实上在工业界已有相关探索。因此后面将会写一个系列来介绍近期强化学习在搜索推荐业务上的应用。
本次将介绍两篇解决强化学习中大规模离散动作空间的论文。
第一篇是 DeepMind 在 2015 年发表的,题目为:
Deep Reinforcement Learning in Large Discrete Action Space
链接为:
https://arxiv.org/abs/1512.07679
适合精读;
第二篇是发表在 AAAI2019 上,题目为 :
Large-scale Interactive Recommendation with Tree-structured Policy Gradient
链接为:
https://arxiv.org/abs/1811.05869
适合泛读。
一、Introduction
传统的推荐模型在建模时只考虑单次推荐,那是否可以考虑连续推荐形成的序列来改善推荐策略呢?事实上已经有一些工作引入强化学习来对推荐过程进行建模。但有个问题就是推荐场景涉及的 item 数目往往非常高,大规模离散动作空间会使得一些 RL 方法无法有效应用。比如基于 DQN 的方法在学习策略时使用:
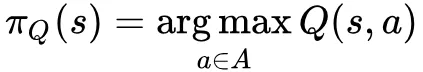
其中 A 表示 item 集合,对 A 中所有 item 均要计算一次 Q 函数。如果 |A| 非常大的话从时间开销上来讲无法接受。但这个方法有个优点就是 Q 函数往往在动作上有较好的泛化性。而基于 actor-critic 的方法中 actor 网络往往类似一个分类器,输出经过 softmax 后是动作上的概率分布,所以就避免了 DQN 类方法中的性能问题,但是这类方法缺点就是对未出现过的 action 泛化能力并不好。所以就需要寻找一种针对动作空间来说复杂度为次线性而且在动作空间上能较好泛化的方法。
二、Wolpertinger Architecture
该算法是第一篇论文提出来的,整体流程如下。

整个算法基于 actor-critic 框架,通过 DDPG 来训练参数,这里只介绍文章的重点部分即 action 的选择。算法先经过 得到 proto-action ,但 可能并不是一个有效的 action ,也就是说 。然后从 A 中找到 k 个和 最相似的 action ,表示为:
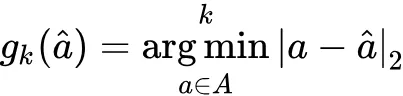
该步可在对数时间内得到近似解,属于次线性复杂度,避免了时间复杂度过高的问题。但是有些 Q 值低的 action 可能也恰好出现在 的周围,所以直接选择一个和 最接近的 action 并不是很理想的做法。为了避免选出异常的 action ,需要通过 action 对应的 Q 值再进行一次修正,表示为:
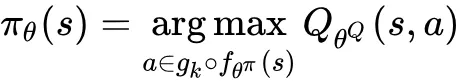
其中涉及的参数 包括 action 产生过程的 和 critic 网络的 。通过 Q 值的筛选可使得算法在 action 选择上更加鲁棒。
三、TPGR 模型
该算法是第二篇论文提出来的,主要思路是对 item 集合先预处理聚类从而解决效率问题,模型框架图如下。左半部分展示了一个平衡的树结构,整颗树对应着将 item 全集进行层次聚类的结果,每个根节点对应一个具体的 item 。右半部分展示了如何基于树结构进行决策,具体来说每个非叶节点对应一个策略网络,从根节点到叶子节点的路径中使用多个策略网络分别进行决策。TPGR 模型可使决策的复杂度从 降低到 ,其中 d 表示树的深度。下面分别介绍下左右两部分。
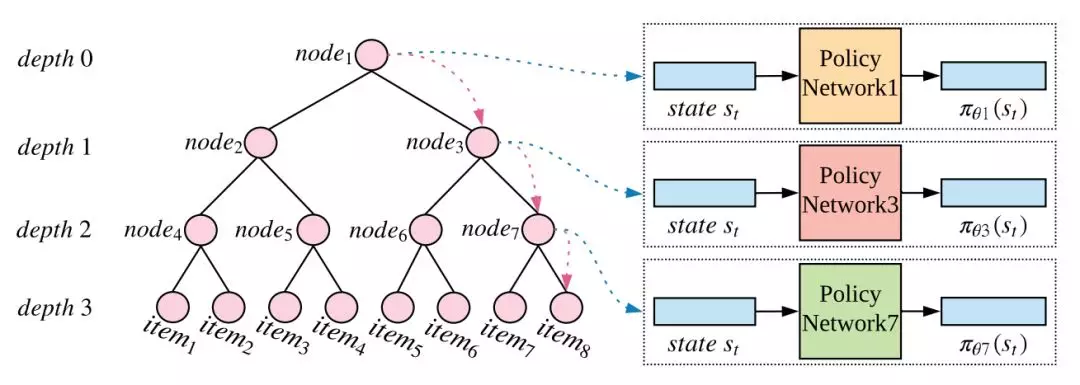
TPGR 模型框架图
平衡的层次聚类
这步目的是将 item 全集进行层次聚类,聚类结果可通过树结构进行表示。文中强调这里是平衡的树结构,也就是说子树高度差小于等于 1,而且子树均符合平衡性质。设树的深度为 d ,除去叶子节点的父节点外其他中间节点的子树数均为 c ,可以得到 d 、c 和 item 数目 |A| 的关系如下:
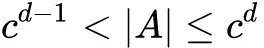
涉及如何表示 item 和如何进行聚类两个问题。第一个问题,可以使用评分矩阵、基于矩阵分解方法得到的隐向量等方法作为 item 的表示。而第二个问题,文章提出了两种方法。篇幅有限,只介绍基于 Kmeans 改进的方法,具体来说:先进行正常的 Kmeans 聚类得到的簇中心 ( c 个 ) ,然后遍历所有簇,以欧几里得距离作为相似度指标将和簇中心最近的 item 加到当前簇中,遍历所有簇一遍后继续循环遍历所有簇,直到将所有 item 都进行了分配为止。通过这种分配的方式可使得最后每个簇的 item 数目基本一致,也就达到了平衡的要求。
基于树结构的策略网络
之前提到,每个非叶节点均对应一个策略网络。其输入是当前节点对应的状态,输出则是每个子节点上的概率分布,也就是移动到每个子节点的概率。在上面的框架图中,根节点为 ,根据其策略网络输出的概率移动到 ,以此类推,最后到 ,将 推荐给 user 。策略网络具体采用 REINFORCE 算法,梯度更新公式为:
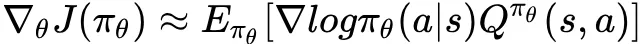
其中 表示 策略下状态 s 采取动作 a 的期望累积回报,可通过采用抽样来进行估计。
四、总结
一般推荐系统中会有召回步骤将候选的 item 范围缩小到几十到几百量级,所以从这个角度来看处理大规模离散动作的必要性就不那么大了。
TPGR 模型中平衡树和子树数目限制只是为了使时间复杂度保证是对数量级,也就是解决大规模离散动作空间的前提。而 item 分布都会有倾斜的情况,所以实际情况下将所有 item 集合聚类成数目基本一致的多个簇在实际情况下并不合理。这点肯定会影响到模型效果,所以树的构建可能还需要更多的探索和尝试。
作者介绍
杨镒铭,滴滴出行高级算法工程师,硕士毕业于中国科学技术大学,知乎「记录广告、推荐等方面的模型积累」专栏作者。
本文来自 DataFun 社区
原文链接:
https://mp.weixin.qq.com/s/tX8l94v6bnBJB9uhDL25XA

中国开源发展研究分析 2022
本次报告为开发者,技术管理者,开源社区运营、市场,开源办公室工作人员带来信息上的增量以及对开源趋势、...










评论