

本文整理自2019QCon北京站田健的演讲。
今天为大家带来的分享主题是如何应对大规模架构的服务管理课题,分为服务治理和服务混部两部分。“大题”指的是我们面对的架构规模庞大且复杂,“小做”则是指通过高效的基础设施和架构工程,让复杂的业务更简单。
服务治理的范畴比较宽泛,包括了服务的部署、变更管理、质量管理、服务发现、流量调度、资源以及监控等,限于时间和篇幅,无法面面俱到。而针对大规模服务架构,尤其是像百度搜索这样超大规模服务集群,在服务治理上有哪些需要特别关注的地方,才是今天要为大家分享的内容。
应对不同的规模,需要有不同的解决方案,这是一个基本原则。拿“数钱”这个大多数人常见的情景举例说明,当我们需要计算一沓纸币的总额,若数量较少,一般手数即可;数量偏多(数十万总数),只能依赖点钞机;而应对超大规模(数千万甚至上亿),则需要用到大型清分机。不同规模的同类问题,适用的解决方案也绝对不一样,不能轻易互相套用。
服务治理角度来看,应对大规模服务架构的首要问题是如何解决服务的快速、稳定的部署。我们都很清楚,对于一定规模的正式服务,需要通过分级发布流程来控制部署频率,保证服务整体稳定性和高可用。
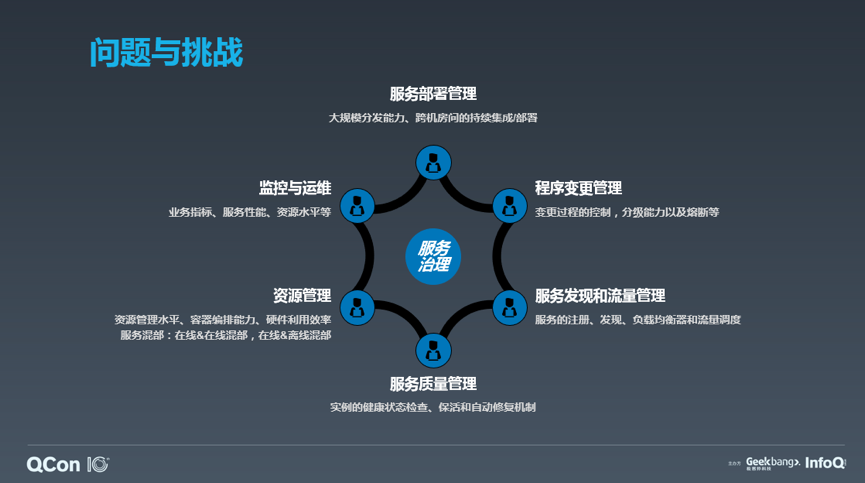
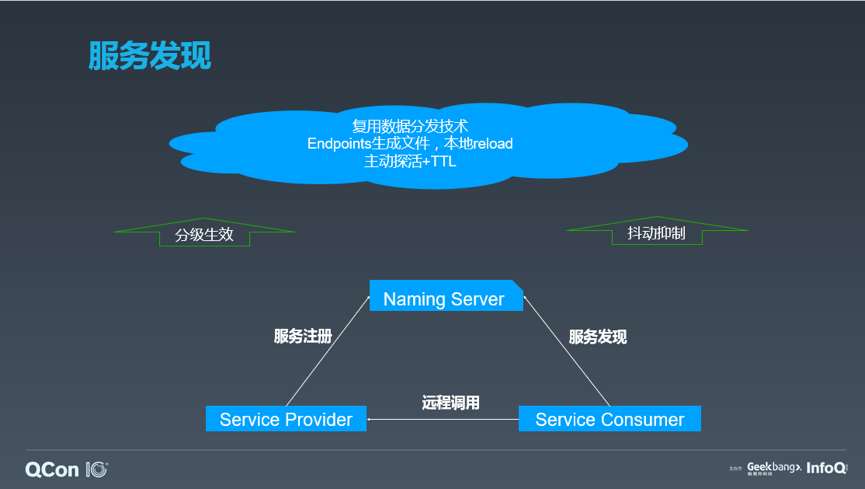
另一方面,需要全网分发的数据能力。当部署规模很小的时候,可以通过简单的 wget、curl、scp 等命令实现远程数据拉取,并且通常源文件部署在单机系统上。而应对超大规模的数据分发过程,单机的网络、磁盘 I/O 等性能会出现瓶颈,稳定性也存在疑虑,导致整个分发系统失效。因此,源文件至少要保存在分布式文件系统来支撑更高的读取并发、提供更高的可用性,另一方面,则要借助 p2p 协议的快速分发能力,实现数据的全网高并发和高效传输。
而前面谈到的,一方面我们希望服务是分级发布的,另一方面又需要全网快速分发,这里存在一个速度和风险的悖论。因此还需要额外多考虑一点,就是将数据的分发和数据的生效逻辑拆开来做。因为在服务部署过程中,数据分发占用的时间要远远大于数据的生效时间。这样一来,全部服务可以通过 p2p 的传输实现快速的数据分发,同时又可以根据需求指定生效的分级流程,实现风险和速度的折衷。
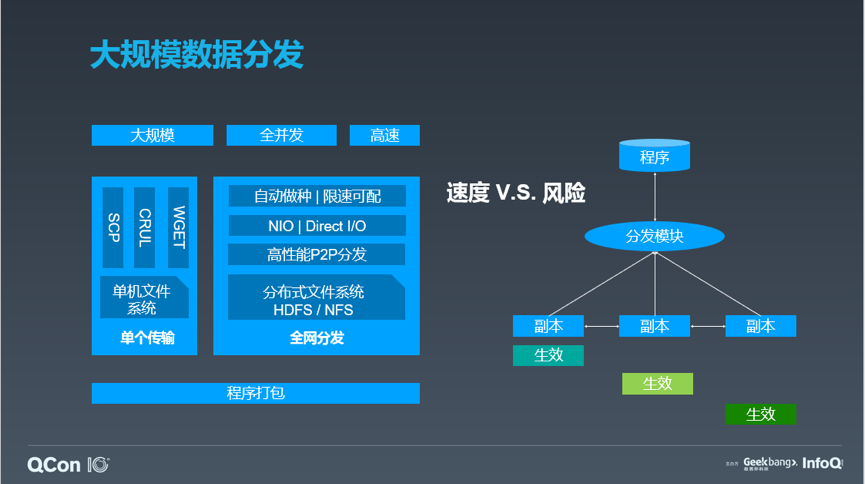
解决了数据分发的过程,我们还需要关注数据分发的结果。一方面,各分发节点需要做数据校验,保证数据正确,另一方面,针对大规模数据分发,我们更关注数据如何保证一致性。传统的分发流程中,通过分发模块直接做数据的分发给各个实例,这就带来两个问题:
全部的分发流程由分发总控模块统一负责,容易出现性能瓶颈;
每一次分发过程都要进行过程跟踪,并跟进异常处理,这在高频次、大规模的分发场景下会耗费巨大人力。
因此,我们需要把面向过程的分发改造为面向结果的分发流程。在面向结果的分发流程中,我们设计了一个服务的 handler,它持有服务当前的数据和版本描述,并且接收来自分发总控的预期数据描述,并根据两者描述的 diff 点,不断的执行相应的数据传输动作。
好处是:
分发模块仅分发数据描述,而不是数据文件,描述文件体量很小,拥有着极高的成功率;
一旦 handler 接收到了预期数据描述,便会自驱的让服务的数据向预期状态靠拢,持续的进行数据的获取直到描述成功,则不需要人为干预——包括故障重传和异常处理,即可实现数据的最终一致。
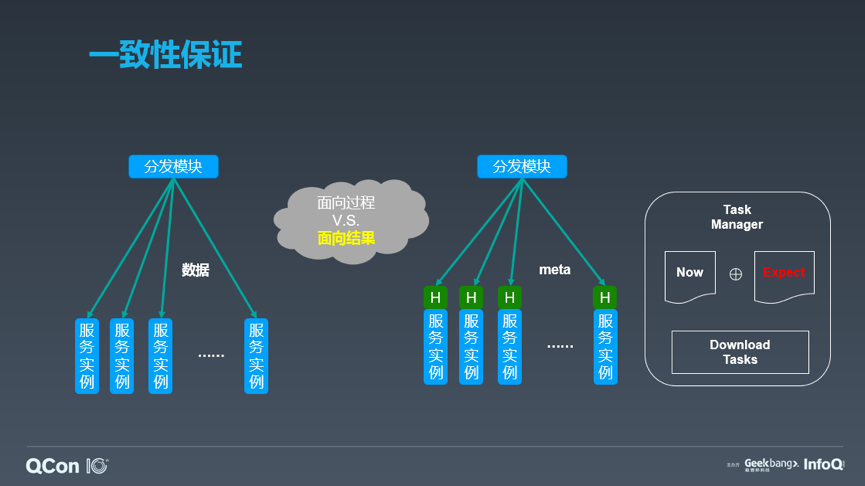
回滚的流程设计是服务部署的又一大痛点。针对大规模服务部署流程,需要一套快速的回滚流程,才能保证风险可控、损失最低。前面说到过,数据的分发是服务部署过程中耗时最长的一块,因此首先就要考虑如何避免重复的下载。一个合理的想法是保留多个版本,一般来讲,为了支持快速回滚,保留两个版本即可,这样的大家是磁盘占用空间翻倍。好在对于服务器的成本组成而言,冷备磁盘的开销是极低的,因此用空间换时间是可行的。但是仅保留多个版本是不够的,还需要有数据切换的流程设计。如果采用的是 cp 或者 mv 的方式,很容易出现长尾(文件系统故障导致的迁移异常,或者是跨盘出现的真实数据读写),因此更好的办法是通过软链来实现,我们的系统目前也是这样做的。更长远的,可以考虑采用共享文件系统来实现这个功能——考虑我们大部分服务的数据仅在启动过程中加载,之后就不再使用,通过共享存储把这部分数据按需 mount,按需加载,加载完成后释放,则备份的成本就大大的降低,且生效速度不变。
大规模服务部署的问题就简单阐述到这里,接下来重点关注下对于服务质量的控制。服务质量对于大规模服务架构的重要性是不言而喻的,服务只有足够稳定才能吸引用户使用、留存,进而转化出更丰富的应用场景。我知道身边很多的人,在诊断网络故障的时候,第一件事情就是输入百度首页判断网络是否有问题,可以证明百度搜索的服务质量已经被高度认可。这里离不开两件事:一是如何在入口保证;二是如何在底部拦截。
保证入口可用的稳定机制,一方面是容灾 cache 的建设,另一方面就是流量的自动管理,包括内网加外网的混合流量调度。流量调度会综合考虑后端服务可用性、后端服务容量、机房间冗余情况、全网故障等因素,实现动态调度能力。同时,对于大规模服务的流量调度,依然离不开分级发布的老话题,而另一点要关注的是对于错误的容忍和处理能力。当机房故障、出口带宽不足、运营商基础设施异常,我们要能第一时间切走流量;对于内部上下游依赖,需要有容量的识别和弹性伸缩的能力,这都依赖于治理平台的基础能力。
这里说的兜底机制,或者说容错处理,是服务治理平台对于服务质量管理的最后一道关卡。说起这个问题,我个人也很有感触——刚刚自己就遇到一个 case,在我使用 MS onedrive 云盘时,误操作清空了本地目录,如果按正常逻辑,onedrive 会把本地操作同步到云上,对所有文件进行擦除,但是系统却先征询了我的意见,才让我意识到自己的误操作。所以容错和兜底的设计,虽然不会被经常用到,但是却意义非凡,价值巨大。
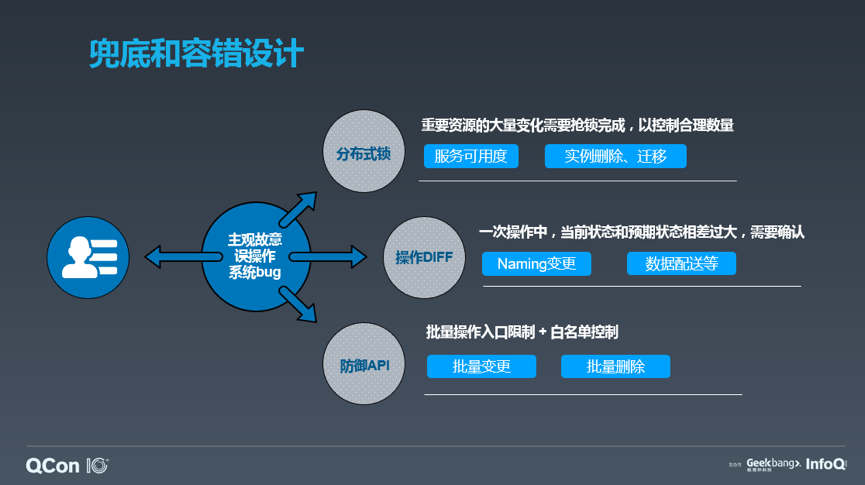
我们设计任何一套系统的时候,都有可能面对:来自用户的恶意使用、误操作、以及系统 bug 的威胁,那么相应的,我们也整理并归纳了三种通用的处理方式:
一是分布式锁,针对重要资源的变更操作,应该有兜底的锁机制,均需要抢锁才能执行,这样一来,可以通过合理设置锁的数目,确保不会有大量的重要资源被恶意操作;
二是操作 diff 比对,我们认为在一套稳定的系统中,操作前后的状态不会相差特别巨大,如果相差较多,需要确认,就比如我遇到这个问题,如果是单一文件的删除,onedrive 就会认为是一个合理的操作,自动执行,而当我一次删除了大量文件,它会认为这可能属于误操作,需要我来确认,避免了损失;
三是防御性的入口,比如 API 的设计,类似于批量删除这种高危的 API 应该被“双规”——规定角色、规定入口才能够被执行,比如设置了白名单的机器,以及通过单次上线单授权的角色来操作。
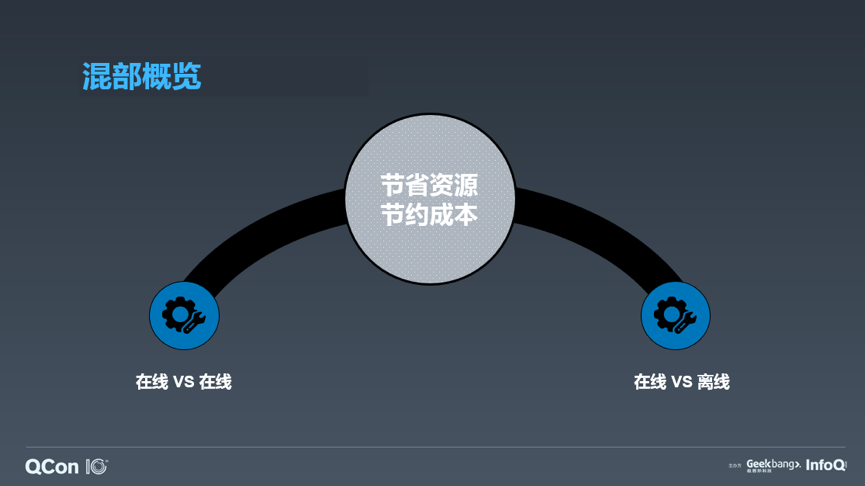
最后我们来谈一谈服务的混部,这也一定是架构发展到一定规模的必由之路。“规模不大,就不值得”是我对混部的态度。人一定比机器之前,所以小规模下耗费人力、精力做混部未见有什么收益。但是当规模增长起来,混部的边际成本就会下降,而边际收益会大大提高。所以我们谈混部,重点是谈成本解决。混部从业务范畴来看,分为在线与在线混部,以及在线与离线混部这两类。在线重延时,离线重吞吐。所以在线服务在资源表现上需要立刻满足,无法压缩,体现出刚性的特质;离线服务的资源则可以延迟满足,通常可以压缩,体现出弹性的特质。所以针对两类服务的混部处理模式也截然不同。
针对在线与在线的服务混部,需要解决三类问题:
随处运行;
避免资源竞争;
重调度。
可以想见,在混部的集群中是不存在着隔离的机器池的,而在线服务依赖的多种多样的基础环境,很可能无法提前获得满足,因此需要将运行的依赖和基础工具打包在一起,这也是 docker 为什么会火的主要原因之一。
另一方面,企业级生产环境会面临更复杂的一些依赖内容,比如网络服务质量。网络服务质量一般是通过 iptables 进行设置,这是绑定机器和端口的设置模式,不适用与混部情况。因此我们基于 cgroups 研发了 TOS 内核模块,实现了 qos 跟随容器的特性,解耦了对机器的具体依赖。类似的问题还有 crontab,core-pattern 等等。

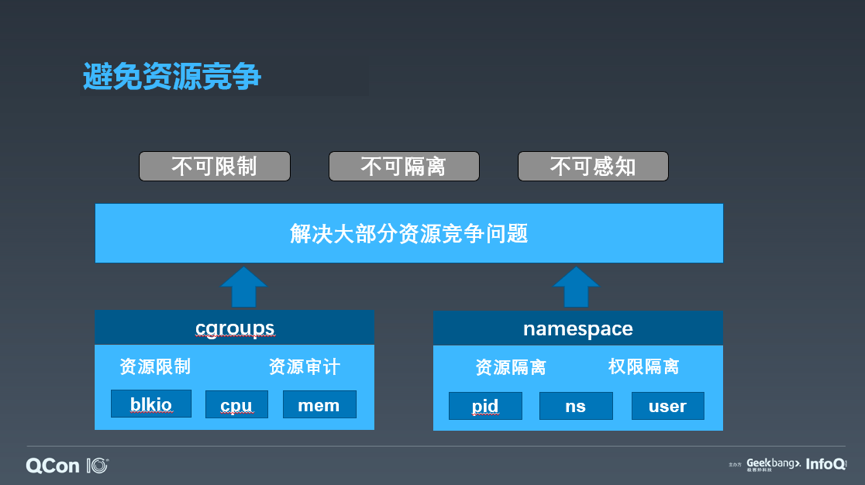
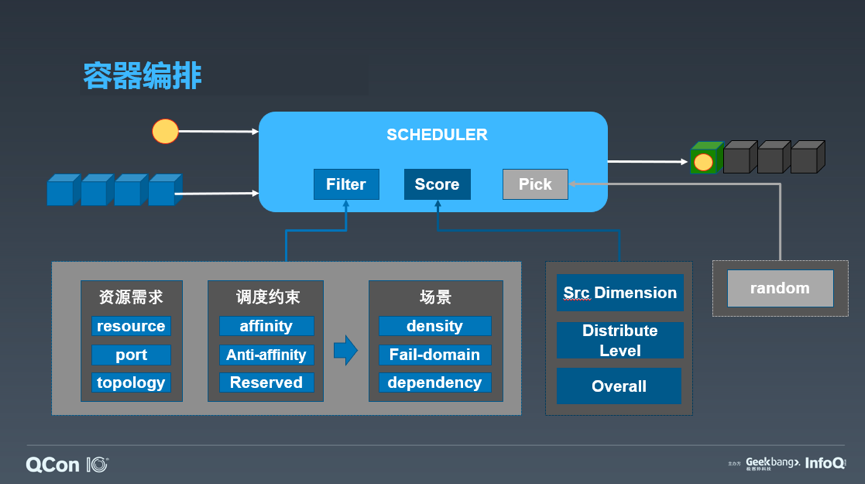
第二点显而易见的问题,是如何避免混部带来的资源竞争。单机上出现资源竞争,可能会影响服务的表现,尤其是响应延时和长尾率,这对在线服务来讲不可接受。一个基础的技术是通过容器技术来实现资源的限制和隔离,比如 cgroups 实现资源的限制和使用审计,通过设置不同的 namespace 实现资源和权限的隔离。但是业务场景往往更复杂,存在一些需要特殊处理的场景,比如类似于机械磁盘,其 I/O 无法做到真正限制和隔离,还有一类受限于当前的技术,出现了资源竞争甚至无法感知,而仅能从测试的表现中反应得到。这就需要借助容器编排的手段,通过人为控制调度逻辑,尽量避免可能出现的竞争场景。调度器包括过滤、打分和挑选三个主要步骤。过滤是筛选出满足符合容器要求硬性条件的候选机器,包括各维度资源是否满足,以及约束条件的表达。我们通过服务和节点的亲和/反亲和的描述方式,来统一表达约束条件,可以满足常见的服务间互斥、服务对硬件的依赖等调度需求。打分则是为了在候选机器中挑选出最合适的机器,这个规则针对不同的场景有所不同,一般会根据均衡的原则,或者让整体资源维持一定分布的原则进行打分。挑选过程是为了保证调度器鲁棒性而引入一些随机性的设计,就不再赘述了。
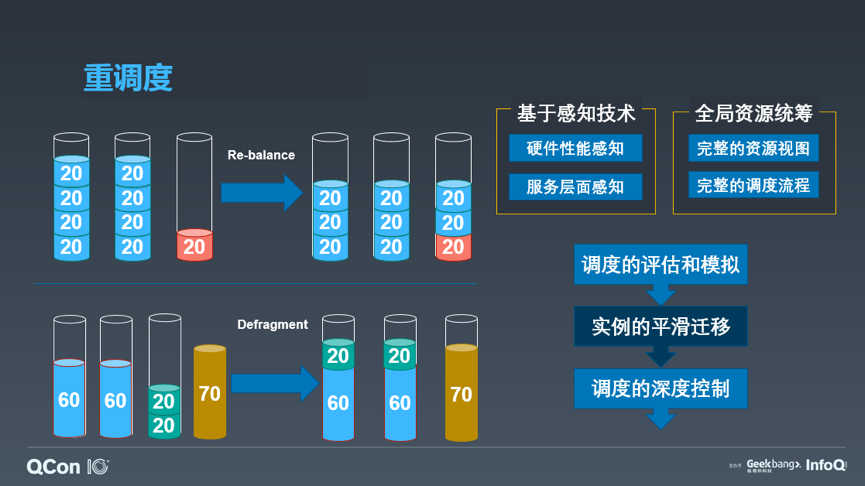
在线服务一般而言属于 long running service,一次部署后可能持续的运行数周、数月的时间,而随着时间的推移,机器的负载情况、服务的热点情况以及集群的资源分布都会发生极大的变化,而想要随着资源变化而维持合理的使用情况,保证服务的亲和关系不被打破,就需要引入 LRS 的重调度逻辑。
重调度就是将在线服务重新调度,从而满足资源的某种需求,常见的有两类:
一类是负载均衡型,希望通过将服务打散获得更优异的性能和可用性;
第二类是碎片整理型,希望从集群资源中通过整合碎片的方式来满足大规格容器的部署需求。
重调度的逻辑需要综合采用服务的热点感知技术、服务指标的采集,配合集群资源的使用情况进行模拟和评估,并且需要控制在线服务能够平滑迁移(流量无损,一般来讲需要双倍 buffer)。
在线与离线的服务混部技术与上面所讲有很大不同,重点是资源视图的组成不一样、资源隔离和抢占的维度也存在较大差异。受限于时间和篇幅的关系,这里就不展开了。
前面讨论的服务管理方面的问题,是针对当前搜索业务特性架构的一些方案和经验,随着架构的演进,治理和管理的思路也会有所调整,传统架构的治理模式也会越来越向着微服务架构的模式转变。我们坚信,只有积极思考、面向未来,搭建领先高效的基础设施服务,才能让复杂业务变得简单。
作者简介
田健,2012 年毕业于东北大学取得计算机硕士学位,后加入百度。先后负责百度搜索调研架构、服务治理、在线业务混部等方向,主持设计了搜索业务新一代 PaaS 系统,承载数万台服务器和五十余万实例,主导并实施了大规模在线业务混部项目,节省数千台服务器资源。目前专注于分布式架构、虚拟化和容器技术、服务混部等方向。
另外,QCon 广州 2019 即将于 5 月 27-28 日举行,汇集国内外大厂一线技术专家,细说微服务、架构、运维、大数据、AI、移动、前端、编程语言、工程效率等热门领域的落地实践案例。会议期间还设置了精彩晚场和多种社交活动,是听大咖的闪电秀,还是撸串、烧烤、KTV,任你选择!

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论