

Original URL: https://aws.amazon.com/cn/blogs/big-data/best-practices-from-delhivery-on-migrating-from-apache-kafka-to-amazon-msk/
本文为 Delhivery 公司的客座文章。
在本文中,我们将了解 Delhivery 公司将运行在Amazon Elastic Compute Cloud (Amazon EC2)上的自建 Apache Kafka 迁移至Amazon Managed Streaming for Apache Kafka (Amazon MSK)的整个流程与相关操作步骤。Delhivery 公司高级技术架构师 Akash Deep Verma 表示,“这套新架构已经投入生产一年有余,我们在 Amazon MSK 上运行着超过 350 款应用程序,它们每一天、每一秒都在产生并消费数据。总体而言,与 Amazon MSK 合作给我们带来了愉悦的体验!”
Delhivery 公司是印度领先的数字商务执行平台。凭借其遍布 2500 座城市、18000 多个行政管辖区域的全国网络,该公司提供一整套涵盖快递包裹运输、短途/长途货运、反向物流、跨境、B2B 与 B2C 仓储以及技术服务的全套物流服务体系。
Verma 指出,“我们的愿景是通过世界一流的基础设施、最高质量的物流运营以及尖端工程技术能力的结合,成为印度商务经济的「操作系统」。我们的团队已经成功为印度超过 1.2 亿个家庭完成了 6.5 亿份订单。我们运营有 24 处自动分类中心、75 处执行中心、70 处物流枢纽、超过 2500 个直接配送中心、超过 8000 处合作伙伴中心以及 14000 多辆货运车辆。超过 40000 名团队成员每年 365 年、每周 7 天、每天 24 小时为客户服务,正是这一切,让日均百万个包裹的交付配送成为可能。”
自托管 Apache Kafka 的难题
我们每天需要处理近 1 TB 数据,借此实现各类分析功能。这些数据来自货运跟踪、订单跟踪、GPS、生物识别、手持设备、分类器、重量、客户以及设施等各类来源,并通过多条实时与批处理管理在各类系统与服务之间往来移动。数据在经过处理与充实之后,即可服务于多种业务及技术场景。考虑到我们业务的基本性质,Apache Kafka 上的传入消息与事件主要以稳定常规流量与间歇峰值流量组成,这两类情况的流量区间分别为每秒 10000 到 12000 条消息、以及每秒 50000 到 55000 条消息。
Apache Kafka 则作为这些依赖系统与服务之间的核心消息与事件主干。
我们之前在 Amazon Elastic Compute Cloud (Amazon EC2)实例上对 Apache Kafka 代理及其相关组件(例如 Apache Zookeeper)进行自建。
随着业务规模的不断增长,管理这些组件并保证正常运行时间已经成为一项重要的资源密集操作。我们需要专门指派两名开发人员管理我们的 Apache Kafka 基础设施并维持其正常运作。由于这些开发人员无法继续为业务功能的开发做出有效贡献,这种无差别的繁重工作已经在事实上导致生产力下降。
Verma 表示,“我们想要一项托管形式的 Apache Kafka 服务,借以降低基础设施管理所占用的时间与资源。这样一来,我们就能重新分配技术团队的事务优先级,保证各位成员专注于开发能够实际增加业务价值的功能。”
迁移至 Amazon MSK 以节约时间
我们研究了几种选项,考量借此替换 EC2 实例上的自托管 Apache Kafka,最终的答案正是 Amazon MSK。借助 Amazon MSK,我们可以继续使用原生 Apache Kafka API,并在不更改任何代码的前提下在 AWS 上运行我们的现有应用程序。它还能为我们提供、配置并维护 Apache Kafka 集群与 Apache Zookeeper 节点。以此为基础,我们能够将开发人员从基础设施管理当中解放出来,为我们的业务编写更多创新应用。
根据 AWS 团队的建议,我们采取了以下步骤:
调整 MSK 集群大小。
将各 Apache Kafka 主题迁移至 Amazon MSK。
监控 Amazon MSK 运行状态。
调整 MSK 集群大小
为了适当调整 MSK 集群的大小,我们需要了解当前工作负载的基本动态。我们从当前基于 Amazon EC2 的 Apache Kafka 集群中检索出以下指标:
生产者的写入效率——我们考虑监控 broker 上的指标
BytesInPerSec,选择各代理的平均值,并汇总了集群中全部代理的值以估算净摄取率(请与ReplicationBytesInPerSec指标区分开来,ReplicationBytesInPerSec代表的是与其他代理间的摄取率)。消费者的消费速率——我们还在 broker 上监控指标
BytesOutPerSec,选择单一代理的平均值,而后将集群中所有代理的值进行汇总,借此估算集群的净消费率(请与ReplicationBytesOutPerSec指标区分开来,ReplicationBytesOutPerSec代表的是指向其他代理的消费率。数据复制策略——我们通过集群全局参数
default.replication.factor以及为每个主题设定的独立参数之间进行了评估,并借此确定了复制因子的最大值。数据保留策略与磁盘利用率的目标百分比——我们通过集群全局参数
log.retention.hours以及为每个主题设定的独立参数之间进行了评估确定了数据保留的最高保留值。我们还指定了已用存储空间的百分比,并估算满足用例所需要的净空间。
AWS 为我们提供一份Amazon MSK规模调整与费率标准表格,帮助我们快速估算 MSK 集群中所需要的代理数量。接下来,我们在业务环境当中进行概念验证,并从电子表格中找到了推荐的具体集群大小。这份电子表格还帮助我们轻松估算了集群使用成本。关于更多详细信息,请参阅每集群代理数量。
将各 Apache Kafka 主题迁移至 Amazon MSK
我们整理了将各主题迁移至 Amazon MSK 的几种可行选择:
MirrorMaker 1.0,这是 Apache Kafka 中随附的一款独立工具,能够以最低停机时间将数据从自托管 Apache Kafka 集群迁移至 Amazon MSK。
使用消费者从自托管 Apache Kafka 集群读取数据,而后将数据写入至 Amazon MSK。这种迁移方法需要一定的停机时间。
我们以往经常使用过的其他复制工具。
在实践操作中,我们将前两种方法结合起来进行迁移。对于无法容忍长时间停机的主题,我们使用 MirroMaker 1.0 将数据迁移至 Amazon MSK。对于能够承受一定停机的主题,我们的内部 SLA 允许通过应用程序流量将数据从自托管 Apache Kafka 集群重新定向至 Amazon MSK。
在 MirrorMaker 方案中,我们需要在自托管 EC2 实例上设置 MirrorMaker 1.0 守护程序以使用来自源集群的消息,而后将其重新发布至目标 MSK 集群。每个 MirrorMaker 1.0 线程都配备一个单独的消费程序实例,且共享同一通用生产程序。整个流程如下:
MirrorMaker 1.0 实例产生一个消费者进程,该进程与 Apache Zookeeper 整体交互,以支持源 Apache Kafka 集群进行主题发现。
消费者进程从相关主题中读取消息。
MirrorMaker 1.0 生成一个生产者进程,该进程通过 Apache Zookeeper 端点与 Amazon MSK 上托管的 Apache Zookeeper fleet 进行交互。
该生产程序进程通过代理端点将消费程序进程检索到的消息,转发至 Amazon MSK 的相应主题。
下图所示,为我们的整个迁移拓扑结构。
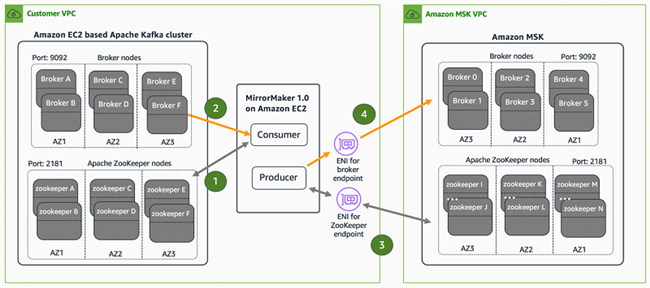
MSK 集群创建流程需要将子网 ID 作为输入,以便代理与 Pache ZooKeeper 节点能够正确映射至客户 VPC。通过在具有主专用 IPv4 地址的各子网 ID 中创建 ENI,我们能够轻松实现这一映射。MSK 集群中随附的代理与 Apache ZooKeeper 端点将实际解析这些专用 IPv4 地址。
我们使用以下命令,将所有主题从基于 Amazon EC2 的源集群以镜像形式保存至 Amazon MSK:
上述命令包含以下细节:
其中的kafka-mirror-maker.sh shell 脚本用于创建一个 tools.MirrorMaker类实例。
在
mirrormaker-consumer.properties文件中的bootstrap.servers、group.id等由换行符分隔的键/值对下,包含有消费者配置参数。其中
mirrormaker-producer.propertiesfile在bootstrap.servers、acks等由换行符分隔的键值对下,包含有生产者配置参数。--whitelist选项允许大家使用 Java 样式的正则表达式,保证我们可以仅对特定主题进行镜像复制,例如使用--whitelist 'A|B'镜像复制 A 与 B 主题。
随着 KIP-382 的引入,现在 Amazon MSK 已经能够支持 MirroMaker 2.0 并发挥由新版本带来的更多优势。关于使用 MirroMaker 2.0 将自托管 Apache Kafka 集群迁移至 MSK 集群的操作说明、配置文件、示例代码以及相关实验,请参阅 MirrorMaker2 on Amazon EC2研讨资料。
大家也可以使用 Amazon Kinesis Data Analytics(一项面向 Apache Flink 的全托管服务)将现有 Apache Kafka 集群迁移至 Amazon MSK。如此一来,您可以使用全托管 Apache Flink 应用程序处理 Amazon MSK 中存储的流式数据。关于将 Amazon Kinesis Data Analytics 与 Amazon MSK 配合使用的更多详细信息,请参阅教程:使用Kinesis Data Analytics应用程序在同一VPC内实现不同MSK集群间的数据复制以及点击流实验室。
在稳定状态下,我们生产环境中的 MSK 集群使用以下配置:
broker 节点——6 x m5.4xlarge
复制因子——3
生产者数量——110 个以上
消费者数量——300 个以上
主题——500 个以上
broker 上运行的 Kstreams——55 个以上
监控 Amazon MSK 运行状态
Amazon MSK 以三种粒度级别提供多项 Amazon CloudWatch 监控指标:
DEFAULTPER_BROKERPER_TOPIC_PER_BROKER
在我们的用例中,我们使用最精细的PER_TOPIC_PER_BROKER粒度以实现最佳系统运行可见性。为了自动检测各类运营问题,我们还使用以下指标开发出自定义 CloudWatch 警报。
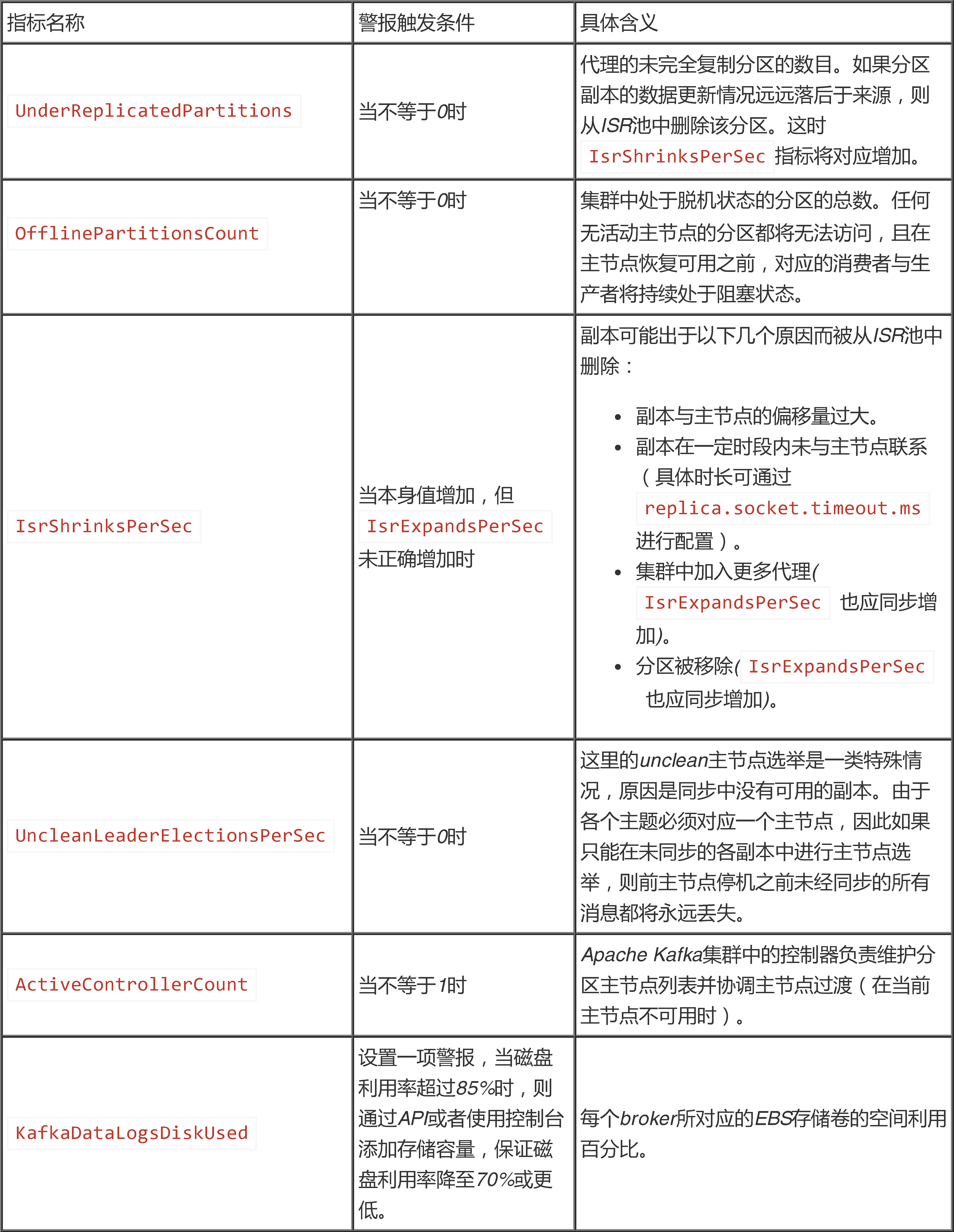
Amazon MSK 还支持通过端口 11001(面向 JMX Exporter)与端口 11002(面向 Node Exporter)使用 Prometheus 等监控工具与 Prometheus 格式的指标(例如 Datadog、New Relic 以及 SumoLogic 等)捕捉公开指标。关于更多详细信息,请参阅使用Prometheus实现公开监控。关于配置公开监控的更多操作说明,请参阅 Open Monitoring 实验室。
总结
在使用自建 Apache Kafka 代理时,我们需要保证 Apache ZooKeeper 始终发挥仲裁作用、监控代理之间的网络连接,同时监控 LogCleaner 等不同 Apache Kafka 辅助进程。一旦某个要素发生故障,我们还需要通过基础设施管理与监控等方式解决问题。这部分被耗费在 Apache Kafka 运营层面的精力与时间,本应被用于更好地实现实际业务价值。
Amazon MSK 能够降低基础设施的维护强度,简化问题的识别与解决,缩短代理维护时间,最终将生产力提升至新的层面。它在后台承担起 Apache Kafka 的维护工作,结合实际需求为我们提供监控级别选择,让我们的团队能够腾出更多精力改善业务应用程序并为客户提供价值回报。
作者介绍:
Delhivery 公司高级技术架构师。Akash 于 2016 年加入 Delhivery,从事与大数据及分析相关的多个项目。最近,他开始领导一项与数据大众化相关的架构设计项目。在业余时间,他喜欢打乒乓球和观看烧脑电影。
AWS 公司企业级解决方案架构师。Dipta 于 2018 年加入 AWS,他主要负责与大型初创企业客户合作,在 AWS 上设计并开发业务架构以支持云探索之旅。
AWS 公司解决方案架构师。他于 2016 年加入 AWS,致力于构建及支持各类数据流解决方案,帮助客户分析数据并从中获取价值。在业余时间,他喜欢使用 3D 打印技术解决日常问题。
本文转载自亚马逊 AWS 官方博客。
原文链接:
Delhivery 公司最佳实践剖析:从 Apache Kafka 迁移至 Amazon MSK

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论