
在现实环境中部署大数据分析、数据科学和机器学习应用,分析优化和模型训练仅占全部工作量的 25%,约 50%的工作用于准备适用于分析和开展机器学习的数据,其余 25%的工作是实现易于使用的模型推理和洞察分析。数据流水线将各个过程组织在一起,为机器学习这列重载而神奇的列车提供轨道。只有基于正确配置的流水线,方能确保项目的长期正常运行。
本文将从以下四个维度展开,阐释数据流水线及实现各步骤的可选组件:
需求愿景:切实了解用户的愿景,即可对症下药。此节将分析各种需求,阐释数据流水线需提供的相应工程特性。
流水线:此节从数据湖和数据仓库中数据流转的角度,从概念上阐释数据流水线的各个过程。
组件选取:此节阐释实现处理规模和速度权衡的 Lambda 架构,以及 Lambda 架构中关键组件在技术上的选取。此外,此节将概要给出 AWS、Azure 和 Google Cloud 提供的无服务器流水线。
生产环境:此节给出成功实现生产环境数据流水线的一些小提示。
需求愿景
图 1 需求愿景就是从最有利的角度给出观察
构建数据分析平台和机器学习应用的切实用户可归为三类,即数据科学家、工程人员和业务管理人员。
数据科学家的目标是针对给定的问题和可用的数据,给出鲁棒性最好且计算复杂度适中的模型。
工程人员的目标是为用户构建可信赖的产品。工作创新之处在于构建新产品,或是以新的运行方式运行现有的产品,实现无需人工干预的 7X24 不间断运行。
业务管理人员的目标是向用户交付有价值产品。这正是科学和工程所要达成的目标。
本文聚焦于工程人员,并兼顾其它两方面,特别是从处理机器学习应用所需海量数据的角度。由此,数据流水线所需的工程特征为:
可访问性:数据科学家易于访问数据,最好是能通过查询语言访问数据,以便开展假设评估和模型实验。
可伸缩性:随获数据量增加而弹性扩展的能力,同时维持较低的成本。
效率:在设定时间开销内给出数据和机器学习结果,满足业务目标的需求。
可观测性:对数据和流水线健康状态自动报警,满足主动反馈潜在业务风险的需求。
流水线
图 2 成功的机器学习必需具备运作润滑的数据流水线
数据只有在被转化为具备可操作性的洞察,进而洞察得到及时得交付使用,其价值方能体现出来。
数据流水线实现端到端的操作组,其中包括数据收集、洞察转换、模型训练,洞察交付和应用模型。无论何时何处,只要业务目标有需求,流水线就会立刻运转起来。
和新油田一样,数据虽然价值不斐,但未经加工则不能真正得以应用。必须深加工为天然气、塑料、化学制品等方式,才能创造出有利可图的有价实物。因此数据必须拆解分析后,才能体现出自身的价值。
——Clive Humby,英国数学家,乐购会员卡架构师
数据流水线主要包括五个过程,可分组为三个阶段:
数据工程:采集、获取和准备;(占总工作量的 50%)
分析/机器学习:计算;(占总工作量的 25%)
交付:结果展示。(占总工作量的 25%)
采集:移动应用、Web 网站、Web 应用、微服务和 IoT 设备等数据源设施,按指令采集相关数据。
获取:受控数据源将数据推送到各种设定的数据入口点,例如 HTTP、MQTT 和消息队列等。也有一些任务从 Google Analytics 等服务导入数据。数据具有两种形态,即 BLOB 和流数据。所有数据将汇总到同一数据湖中。
准备:数据通过 ETL(抽取、转化和加载)操作清洗、确证、塑形和转化,以 BLOB 和流数据在数据湖中分门别类管理。准备好机器学习可用的数据,并存储在数据仓库中。
计算:实现分析、数据科学和机器学习。计算可组合批处理和流处理。所得到的模型和洞察,无论是结构化数据还是流数据,继续存回数据仓库中。
结果展示:通过仪表面板、电子邮件、短信息、推送通知和微服务等方式展示所得到的洞察。机器学习模型推理将通过微服务提供接口。
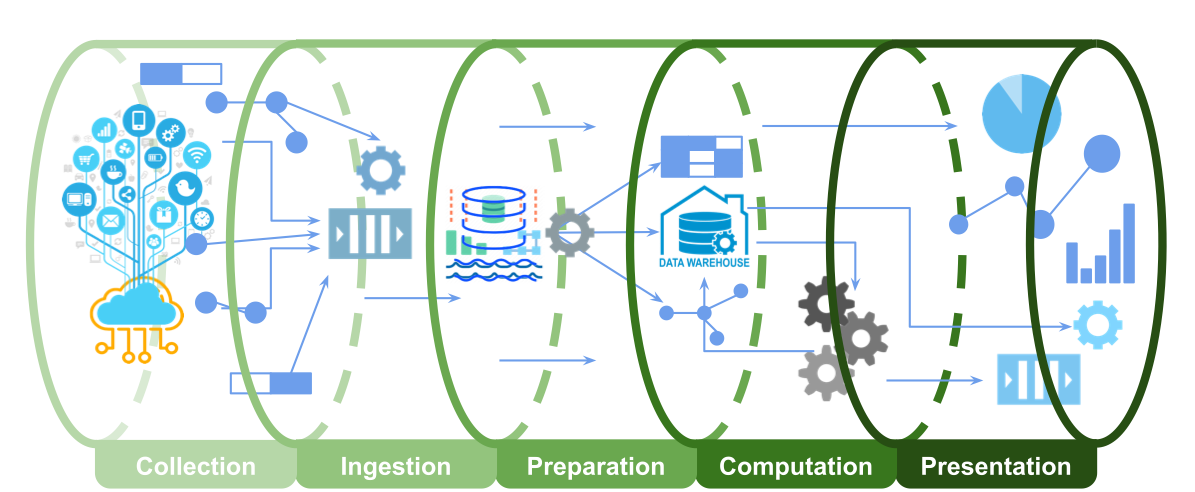
图 3 数据流水线各处理过程
数据湖和数据仓库
在数据湖中,数据以其原始格式或初始形态存在,即按接收到的 BLOB 或文件格式。而数据仓库存储经清洗和转换的数据,以及数据的目录和模式。数据湖和数据仓库中的数据以多种形态存在,包括结构化(即关系模式)、半结构化、二进制和实时事件流。
用户可以选择以不同的物理仓储分别维护数据湖和数据仓库,也可以通过Hive查询等数据湖接口物化数据仓库。具体如何选择,取决于用户在性能上的需求,以及成本约束等因素。
无论采取何种方式,重要的是保持好原始数据,以便于审计、测试和调试。
探索性数据分析(EDA,Exploratory Data Analysis)
EDA 的目的是分析并可视化数据集,进而形成假设。可能已收集的数据对于实现 EDA 尚存差距,因此需要做进一步的收集、实验和验证新数据。
这些操作可被视为一组聚焦于可能模型上的小规模机器学习实验,可用于对比整个数据集并实现调优。
维护具有目录、模式和可访问查询语言接口(无需编写程序)的数据仓库,有助于实现高性能的 EDA。
组件选取
图 4 体系架构需在性能和成本之间取得权衡
图中给出了六种三角型帐篷可选,从左上到右下所需的粘合剂成本依次降低。你会在实践中做出如何选取?请注意,三角形的底边要小于其它的边;浅蓝色部分是矩形,而不是正方形。
数据流水线、数据湖和数据仓库不是什么新概念。过去,数据分析使用批处理程序完成的,例如 SQL 乃至 Excel 工作表。现在不同之处在于,可用的大数据推进了机器学习,进而增加了对实时洞察的需求。
现已有多种体系结构可供选择,提供不同的性能和成本权衡。据我所知,从技术上考虑的最好选择,不一定是最适合生产环境的解决方案。用户必须仔细核对自身的需求:
是否需要实时洞察或模型更新?
对陈旧应用的忍耐程度如何?
成本约束如何?
基于对上述问题的回答,用户必须在Lambda架构中的批处理和流处理上做出权衡,以匹配对处理通量和延迟上的需求。Lambda 架构由如下层级组成:
批处理层:提供高通量、全面、经济的 MapReduce 批处理,但是延迟很高。
加速层:提供低延迟的实时流处理,但是在数据量很大时,实现代价可能会突破用户内存规模。
服务提供层:实现高吞吐量批处理输出(在准备就绪时)与流处理输出的合并,以预先计算的视图或即席查询的形式提供全面的结果。
Lambda 架构基于的假设是源数据模型是仅追加(append-only)的,即已获取的事件会打上时间戳并追加到现有事件中,而且永远不会被覆盖。
架构实例:云上技术栈的选取
下图给出了一种使用开源技术物化实现流水线各阶段的架构。为优化计算代价,通常会合并数据准备和计算阶段。
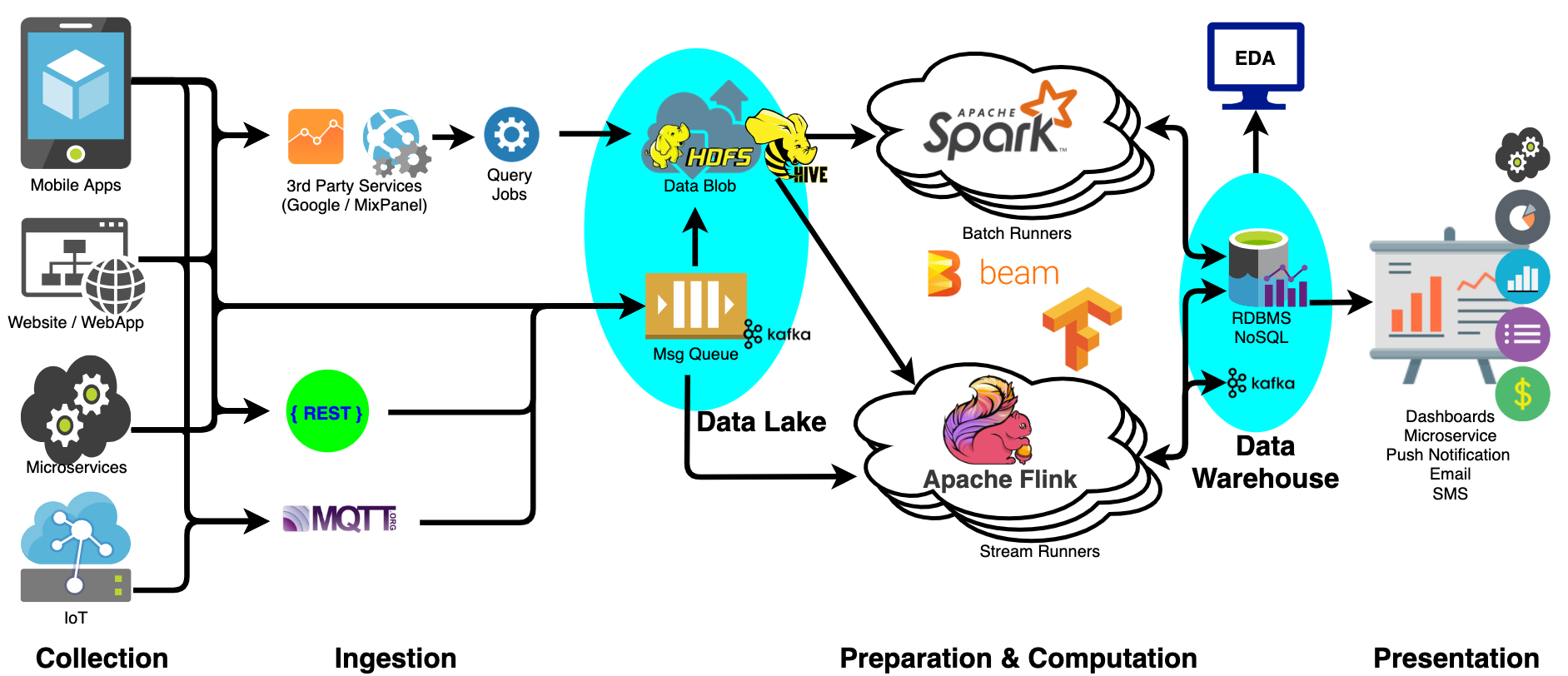
图 5 使用开源技术构建的数据处理流水线
架构中的主要组件和技术选择如下:
使用 HTTP/MQTT 终端节点获取数据,并提供结果。这里存在多种架构和技术可选。
使用发布/订阅消息队列获取海量流数据。Kafka目前是事实上的标准,其经实践考验,可扩展性满足高流量数据获取需求。
使用低成本高容量的数据仓储实现数据湖和数据仓库。可选技术包括Hadoop HDFS和AWS S3等 BLOB 存储云服务。
使用查询和目录基础设施,实现将数据湖转换为数据仓库。这里广泛选取的是Apache Hive。
使用 MapReduce 批处理引擎实现高通量处理,例如,Hadoop Map-Reduce、Apache Spark等。
使用流计算实现对低延迟性有要求的处理。例如,Apache Storm、Apache Flink。对于编写数据流计算,Apache Beam不失为一种新选项。它可以部署在 Spark 批处理和 Flink 流处理上。
使用机器学习框架实现数据科学和机器学习。例如,普遍使用的Scikit-Learn、TensorFlow和PyTorch等实现机器学习。
使用低延迟数据仓储实现结果的存储。数据仓储上存在有很多经实践考验的选项,可根据数据类型、性能需求、数据规模和实现代价等做出选取。
可使用部署编排工具。例如Hadoop YARN、Kubernetes/Kubeflow等。
规模和效率上的权衡,由以下杠杆调节:
吞吐量取决于数据获取(即 REST / MQTT 终端节点和消息队列)的弹性、数据湖的存储容量,以及 MapReduce 批处理。
延迟取决于消息队列、流计算和存储计算结果数据库的效率。
架构实例:无服务器
无服务器计算可避免在项目中引入 DevOps 代价,实现项目的快速启动。无服务器架构中的各种组件,可由选定的云服务提供商的无服务器组件替换。下图分别给出了 Amazon Web Services(AWS)、Microsoft Azure 和 Google Cloud 上典型的无服务器架构实现数据流水线。其中每个过程都能与上一节中阐释的通用架构紧密对应。用户以此为参考,可选取入围的技术。
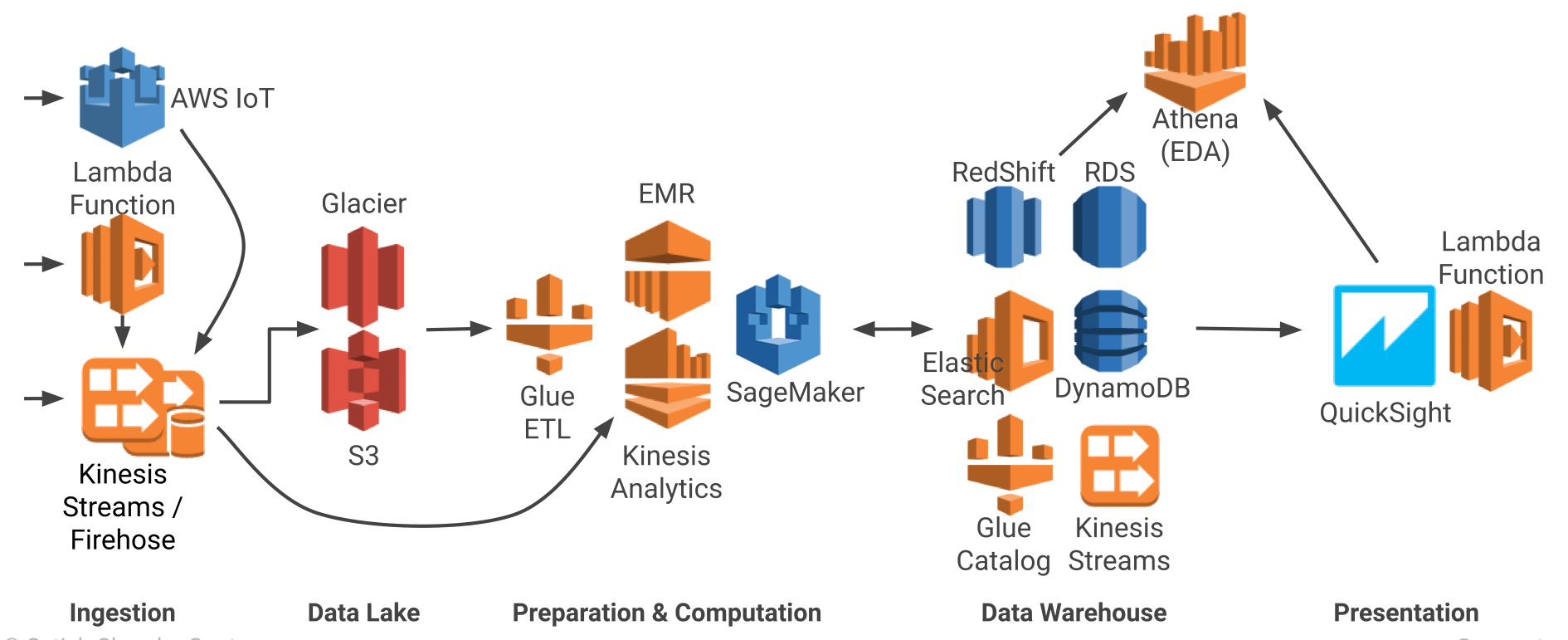
图 6 Amazon Web Services(AWS)的无服务器数据流水线架构
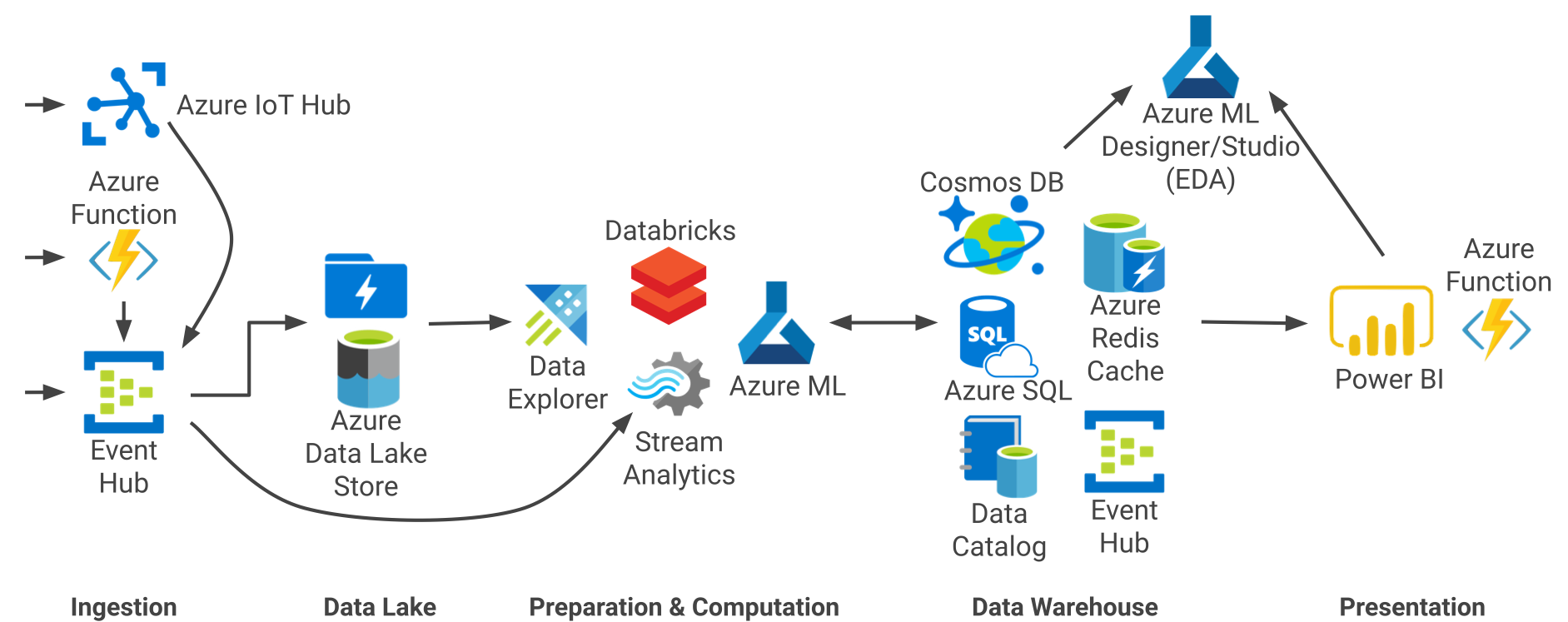
图 7 Microsoft Azure 的无服务器数据流水线架构
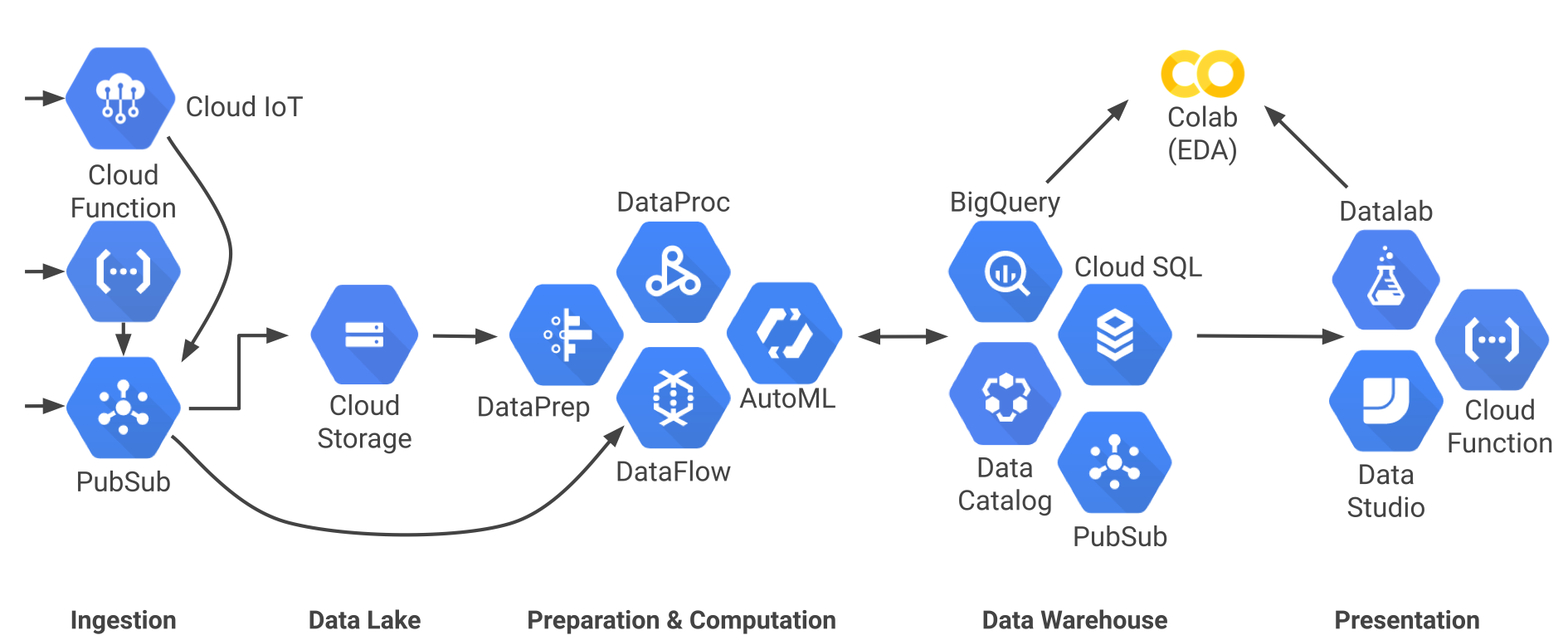
图 8 Google Cloud 的无服务器数据流水线架构
生产环境
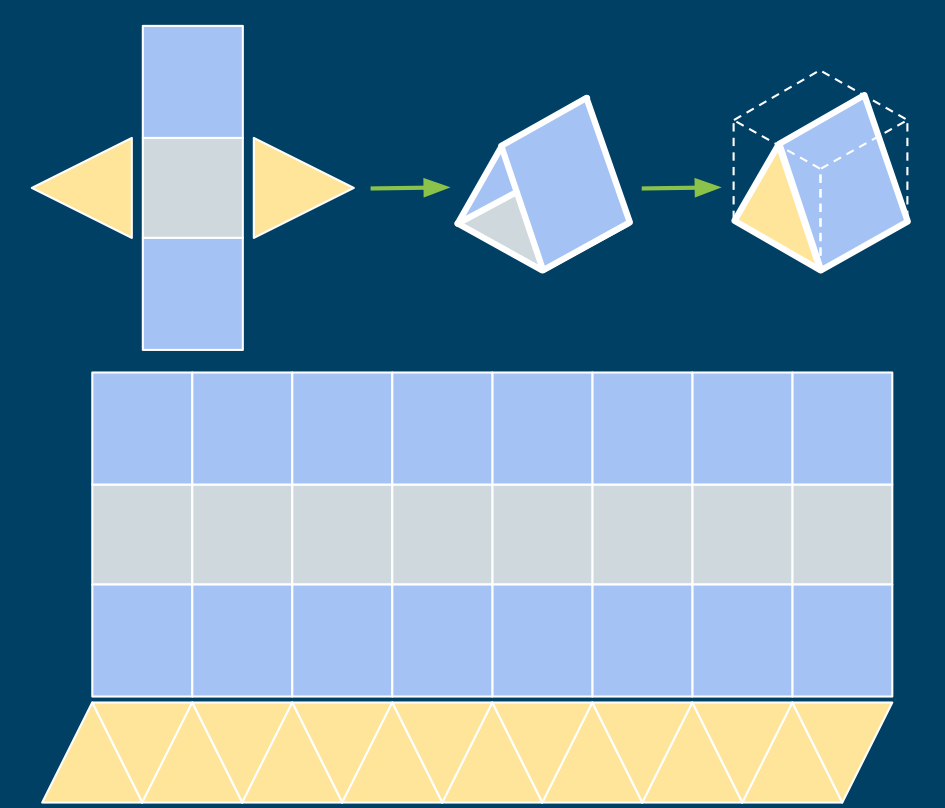
图 9 对于生产环境,简单性往往优于完美
请读者注意,图中选择的三角形帐篷形状,并非需要最少粘合剂的方式。对于降低潜在的错误,至关重要的是如何给出所需的部分,以及整体操作的简单性。
对于不具操作性的分析和机器学习,生产环境将成为它们的埋葬之地。如果用户未对 7x24 全天候监测流水线处理做出投资,使得在某些趋势阈值被突破时就发出警报,那么数据处理流水线可能会在没有引起任何人注意的情况下失效。
请注意,工程和运营支出并非唯一的成本。在决定架构时,还应考虑时间、机会和压力成本。
数据流水线的实操是一件非常棘手的事情。下面给出我历经波折获得的一些小经验:
在扩展数据科学团队之前,先扩展数据工程团队。数据科学这列货运列车必须先铺设铁轨,然后才能运行。
勤于清理的数据仓库。机器学习取决于数据的质量。要定义良好的数据采集模式,并做好目录。如果上述工作缺失,那么用户一定会惊讶地看到,以纯字节永久存储的数据浪费了大量的存储空间。
从简单之处开始。以无服务器架构为起步点地,尽可能降低管理成本。仅在达到合理的投资回报率的情况下,再迁移至功能完善的数据流水线,或用户自身进行部署。在计算阶段,逐步投入尽可能小规模的适量投资。通过调度 SQL 查询和云功能实现计算,甚至是实现为“无计算模式”。这样可以更快地准备好整个流水线,为用户专注于数据策略制定以及数据模式和目录提供充足的时间。
只有在经过仔细评估后,再着手构建。用户的业务目标是什么?必须使用哪些杠杆来调节业务产出?哪些洞察将是可行的?收集数据,并基于数据构建机器学习。
总结
本文的要点总结如下:
分析调优和机器学习模型仅是总工作量的 25%;
尽早投资于数据流水线,机器学习的优劣取决于数据的质量;
对于探索性任务,需确保数据易于访问;
从业务目标入手,寻求给出能落地的洞察。
希望本文对读者能有所帮助。读者在生产环境中建立可靠的数据流水线有哪些技巧?欢迎在评论中分享。
作者简介:
Satish Chandra Gupta 是Slang Labs的合伙创始人之一。Slang Labs 正在构建一个使程序开发者可以轻松快速地将多语言、多模式语音增强体验(VAX)添加到移动和 Web 应用中的平台。设想 Alexa 或 Siri 这样的助手,可以运行在用户的应用内部,并针对用户应用量身定制,听上去多么令人兴奋。
原文链接:
Architecture for High-Throughput Low-Latency Big Data Pipeline on Cloud

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论