又是一年双十一,亿万用户都会在这一天打开手机淘宝,高兴地在会场页面不断浏览,面对琳琅满目的商品图片,抢着添加购物车,下单付款。为了让用户更顺畅更方便地实现这一切,做到“如丝般顺滑”,双十一前夕手机淘宝成立了“521”(我爱你)性能优化项目,在日常优化基础之上进行三个方面的专项优化攻关,分别是 1)H5 页面的一秒法则;2) 启动时间和页面帧率提升 20%;3)Android 内存占用降低 50%。优化过程中遇到的困难,思考后找寻的方案,实施后提取的经验都会在下面详细地介绍给读者。
第一章 一秒法则的实现
“1S 法则”是面向 Web 侧,H5 链路上加载性能和体验方向上的一个指标,具体指:1)“强网”(4G/WIFI)下,1 秒完全完成页面加载,包括首屏资源,可看亦可用 ;2)3G 下 1 秒完成首包的返回 ;3)2G 下 1 秒完成建连。
在移动网络环境下,http 请求和资源加载与有线网络或者 PC 时代相比有着本质区别,尤其是在 2G/3G 网络下,往往一个资源请求建连的时间都会是整个 Request-Response 流程里面的大头,一些小资源上拖累效应尤其明显。例如一个 1k 的图片,即使在 10k/s 的极慢网速下,理论上 0.1 秒可下载完毕,但由于建立连接的巨大消耗,这样一个请求会要耗上好几秒。
仅仅“建连”这一个点,就能说明移动时代的 Web 侧性能优化和 PC 时代目标和方式都相去甚远,要求我们必须从更底层,更细致的去抓,才能取得看起来相对有效的结果。
15 年初的性能情况
平均 ****LoadTime-WIFI
平均 ****LoadTime - 4G
平均 ****LoadTime - 2G
3.35s
3.84s
14.34s
可以看到优化前, 平均时间很难接近 1 秒。为了实现优化目标,在技术和实施抓手层面,由底层往上,做了四方面事情:
- 网络节点:HttpDNS 优化
- 建连复用:SSL 化,SPDY 建连高复用
- 容器层面:离线化和预加载方案
- 前端组件:请求控制,域名收敛,图片库,前端性能 CheckList
网络节点:HttpDNS 优化
DNS 解析想必大家都知道,在传统 PC 时代 DNS Lookup 基本在几十 ms 内。而我们通过大量的数据采集和真实网络抓包分析(存在 DNS 解析的请求),DNS 的消耗相当可观,2G 网络大量 5-10s,3G 网络平均也要 3-5s。
针对这种情况,手淘开发了一套 HttpDNS-面向无线端的域名解析服务,与传统走 UDP 协议的 DNS 不同,HttpDNS 基于 HTTP 协议。基于 HTTP 的域名解析,减少域名解析部分的时间并解决 DNS 劫持的问题。
手淘 HttpDNS 服务在启动的时候就会对白名单的域名进行域名解析, 返回对应服务的最近 IP(各运营商), 端口号, 协议类型, 心跳等信息。
优点
1) 防止域名劫持
传统 DNS 由 Local DNS 解析域名,不同运营商的 Local DNS 有不同的策略,某些 Local DNS 可能会劫持特定的域名。采用 HttpDNS 能够绕过 Local DNS,避免被劫持;另外,HttpDNS 的解析结果包含 HMAC 校验,也能够防止解析结果被中间网络设备篡改。
2) 更精准的调度
对域名解析而言,尤其是 CDN 域名,解析得到的 IP 应该更靠近客户端的地区和运营商,这样才能有更快的网络访问速度。然而,由于运营商策略的多样性,其推送的 Local DNS 可能和客户端不在同一个地区,这时得到的解析结果可能不是最优的。HttpDNS 能够得到客户端的出口网关 IP,从而能够更准确地判断客户端的地区和运营商,得到更精准的解析结果。
3) 更小的解析延迟和波动
在 2G/3G 这种移动网络下,DNS 解析的延迟和波动都比较大。就单次解析请求而言,HttpDNS 不会比传统的 DNS 更快,但通过 HttpDNS 客户端 SDK 的配合,总体而言,能够显著降低解析延迟和波动。HttpDNS 客户端 SDK 有几个特性:预解析、多域名解析、TTL 缓存和异步请求。
4) 额外的域名相关信息
传统 DNS 的解析结果只有 ip,HttpDNS 的解析结果采用 JSON 格式,除了 ip 外,还支持其它域名相关的信息,比如端口、spdy 协议等。利用这些额外的信息,APP 可以启用或停止某个功能,甚至利用 HttpDNS 来做灰度发布,通过 HttpDNS 控制灰度的比例。
建连复用:SSL 化,SPDY 建连高复用
出于安全目的,淘宝实现了全站 SSL 化。本身和 H5 链路性能优化没有直接的关系,但是从数据层面看,SSL 化之后的资源加载耗时都会略优于普通的 Http 连接。
有读者会有疑惑,SSL 化之后每个域名首次请求会额外增加一个“SSL 握手”的时间,DNS 建连也会比 http 的状态下要长,这是不可避免的,但是为什么一次完整的 RequestRespone 流程耗时会比 http 状态下短呢?
合理的解释是:SSL 化之后,SPDY 可以默认开启,SPDY 协议下的传输效率和建连复用效益将最大化。SPDY 协议下,资源并发请求数将不再受浏览器 webview 的并发请求数量限制,并发 100+ 都是可能的。
同时,在保证了域名收敛之后,同样域名下的资源请求将可以完全复用第一次的 DNS 建连和 SSL 握手,所以,仅在第一次消耗的时间完全可以被 SPDY 后续带来的资源传输效率,并发能力,以及连接复用度带来的收益补回来。甚至理论上,越复杂的页面,资源越多的情况,SSL 化 +SPDY 之后在性能上带来的收益越大。
容器层面:离线化和预加载方案
收益最明显,实现中遇到困难最多的就是离线化或者说资源预加载的方案。预加载方案是为了在用户访问 H5 之前,将页面静态资源(HTML/JS/CSS/IMG…)打包预加载到客户端;用户访问 H5 时,将网络 IO 拦截并替换为本地文件 IO;从而实现 H5 加载性能的大幅度提升。
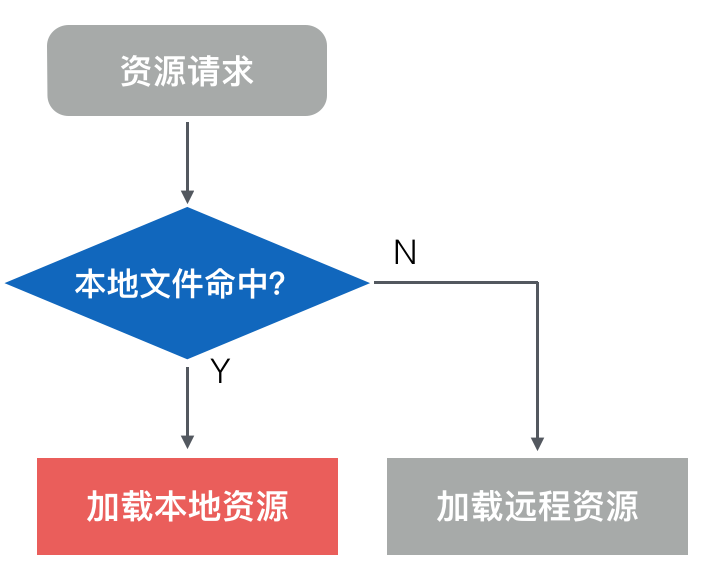
手淘实现要比上面的通用示意图复杂:因为 Android 和 iOS 安装包已经很大,所以预加载 Zip 包(以下简称“包”)都是从服务器端下载到客户端;本地需要记录整体包状态,并在合适的时机与服务器通信并交换状态信息。在包发布更新的过程中要注意,本地版本和服务端最新包之间的差量同步,必要的网络判断,WiFi 下才下载等。
面对亿级 UV,并且在服务器资源很有限的情况下搞定这个流程,需要借助 CDN 来扛住压力,实际上 CDN 扛住了约 98% 的流量。
需要注意的是预加载实际上也是一种缓存,更新比 H5 稍慢一些,主要受几个因素影响:推送到达率(用户是否在线,用户所在网络质量),总控,服务端策略等,所以需要通过推拉结合的触发策略并优化下载包的体积(增量包)来提升到达率。
除了优化到达率,手淘还做了 url 解 CDN Combo 后再映射的优化工作,若 URL 是 Combo URL,那么会对 URL 解 Combo,解析出其中包含的资源。然后尝试从本地读取包含的资源,如果所有资源都在本地存在,那么将本地文件内容拼装为一份完整文件并返回;否则 URL 直接走线上,不做任何操作。
提升到达率和解 CDN Combo 再映射,这两个容器侧对于离线化方案的优化对于本次 H5 链路上整体性能的提升有着至关重要的意义。
前端组件:请求控制,域名收敛,图片库,前端性能 CheckList
严格执行性能方面的 CheckList,主要有三个点:
1) 图片资源域名全部收敛到 gw.alicdn.com;
2) 前端图片库根据强弱网和设备分辨率做适配 ;
3) 首屏数据合并请求为一个。
在执行中,性能的检查和校验一定要纳入到发布阶段,否则就不是一个合理的流程。性能的工具和校验一定应该是工程化,研发流程里面的一部分,才能够保障性能自动化,低成本,不退化。
通过以上优化方案,H5 页面的平均 Loadtime 在 Wifi,4G 下均如期进入 1 秒,3G 和 2G 也有 80%多达成 1s 法则的目标。
第二章 启动时间和页面帧率 20% 的提升
很多 App 都会遇到以下几个常见的性能问题:启动速度慢;界面跳转慢;事件响应慢;滑动和动画卡顿。
手机淘宝也不例外。我们分为两部分来做,第一部分是启动阶段优化,目的解决启动任务繁多,缺乏管控的问题,减少启动和首页响应时间。第二部分是针对各个界面做优化,提升界面跳转时间和滑动帧率,解决卡顿问题。双十一性能优化目标之一就是将启动时间和页面帧率在原有基础上继续优化提升 20%,接下来就从这两部分的优化过程来做一一介绍。
一. 启动阶段的优化
手机淘宝作为阿里无线的航母,接入的业务 Bundle 超过 100 个,启动初始化任务超过 30 个,这些任务缺少管控和性能监控。
那么首要任务就是:
建立任务管理机制
所有的初始化任务可以用两个维度来区分:
1)任务必要性:有些任务是应用启动所必需的,比如网络、主容器;有些任务则不是必需的,仅仅实现单个业务功能,甚至是为了业务自身体验和性能而考虑在启动阶段提前执行,其合理性值得推敲。
2)任务独立性:将应用的架构简单分成基础库、中间件、业务三层,这三层中业务层最为庞大,其初始化任务也最多。对于中间件来说,其初始化可能依赖于另外一个中间件。但对于一个独立的业务模块来说,其初始化任务应该也具有独立性,不存在跟其他业务模块依赖关系。
启动阶段任务管理机制包含了如下几方面的内容
1)任务可并行
既然很多初始化任务是独立的,那么并行执行可以提高启动效率。
2)任务可串行
虽然我们期望所有初始化任务都相互独立,但是在实际中不可避免会存在相互依赖的初始化任务。为了支持这种情况,我们设计任务的异步串行机制,这里主要借鉴了前端的 Promise 思想实现。
3)任务可插拔
面对这么多不同优先级的初始化任务,任何一个出现异常都会导致应用不能启动,给稳定性带来严重挑战。因此我们设计了可插拔机制,当某一项初始化任务出现问题时能够跳过该任务,从而不影响整个应用的启动使用。这里我们根据初始化任务的必要性做了区分,只有非必要的初始化任务才会应用可插拔的特性,这也是为了防止出现不执行一个必要的初始化任务导致应用启动使用出现问题。
4)任务可配置
在 ios 上通过 plist 指定每一项启动任务, 其中字段 optional 表示该项是否是必需的,当之前运行出现 crash 或者异常时,若值为 YES 则可以不执行该项。
有了任务管理机制,并引入懒加载的理念,可以持续地合理有效管控启动阶段的各项初始化任务,是大型 app 必不可少的环节。
检测超时方法,优化主线程
性能优化前,初始化代码都在主线程中执行,为了启动性能已将部分初始化任务放入后台线程或者异步执行。但是随着手淘业务发展和人员变更,还是出现了在主线程中执行很重的初始化任务。为此,在 ios 实现了一套应用运行时方法耗时检测机制,能够对应用中所有类的方法调用做耗时统计。方便的找到超时的方法调用之后,就可以有针对性的做出修改,或删除或异步化。这种方法调用耗时检测机制同样适用于 APP 运行过程中,从而找到导致应用卡顿的根本原因,最后做出对应修改。
多线程治理
分析各个模块的线程数量,检查线程池的合理性。通过去掉不必要的线程和线程池,再控制线程池的并发数和优先级。进一步通过框架层的线程池来接管业务方的线程使用,以减少线程太多的问题。
减少 IO 读写
从自身业务出发,去除若干初始化阶段不必要的文件操作,以及将若干非实时性要求的文件操作延后处理。Android 上对于频繁读写数据库和 SharedPreference 以及文件的模块,通过增加缓存和降低采样率等手段减少对 IO 的读写。对于 SharedPreference 进行了专门的优化,减少单个文件的大小,将毫无联系的存储键值分开到不同文件中,并且防止将大数据块存储到 SharedPreference 中,这样既不利于性能也不利于内存,因为 SharedPreference 会有额外的一份缓存长期存在。
降级部分功能
例如摇一摇功能,测试发现应用场景不频密,但业务使用了高频率的游戏模式,会耗电及占用主线程时间。对该功能做了降级处理,降低检测频率。同理,对于其他非必须使用但又占据较多资源的模块也都做了适当的降级处理。
热启动时间的缩短
在安卓手机上我们把启动分为两类进行检测和优化:冷启动和热启动。冷启动是程序进程不存在的情况下启动,热启动是指用户将程序切换到后台或者不断按 Back 键退出程序,实际进程还存在的情况下点击图标运行。
之前安卓手淘在按 Back 键退出时整个首页 Activity 销毁了,热启动会经过一个比较长的过程。优化后首页在退出的时候并不销毁 Activity,但是会释放图片等主要资源,在下次热启动时就能更快的进入。另外,将手淘欢迎页的界面从其它 bundle 转移到首页的模块,在进入欢迎页时就开始初始化首页资源,做到更快展示。
在经过一系列的优化后,启动方面已经有了明显的改善,在进入首页的时候不会卡顿,GC 次数也减少了一半以上。
二. 各个界面的优化
各界面优化我们也是围绕着提高帧率和加快展现而展开的,手淘的几个主链路界面,都是相对比较复杂的,既使用多图,也使用了动态模板的技术。功能越复杂,也越容易产生性能问题,所以常遇到布局复杂、过渡绘制多、Activity 主要函数耗时、内容展示慢、界面重新布局(Layout)、GC 次数多等问题。
优化 GPU 的过渡绘制
通过开发者选项的 GPU 过渡绘制选项检查界面的过渡绘制情况。该优化并不复杂,通过去掉层叠布局中多余的背景设置、图片控件有前景内容的时候不显示背景、界面背景定义到 Activity 的主题中、减少 Drawable 的复杂 Shape 使用等手段就可以基本消除过渡绘制,减少对 GPU 和 CPU 的浪费。
优化层级和布局
层级越多,测量和布局的时间就会相应增加,创建硬件列表的时间也会相应增加。有时我们会嵌套很多布局来实现原本只要简单布局就可以实现的功能,有时还会添加一些测试阶段才会使用的布局。通过删除无用的层级,使用 Merge 标签或者 ViewStub 标签来优化整个布局性能。比如一些显示错误界面、加载提示框界面等,不是必须显示的这些布局可以使用 ViewStub 标签来提升性能。
另外要灵活使用布局,并不是层级越多就会性能越差,有时候 1 层的 RelativeLayout 会比 3 层嵌套的 LinearLayout 实现的性能更糟糕。
除了灵活使用布局,另外我们还通过提前 inflate 以及在线程中做一些必要的 inflate 等来提前初始化布局,减少实际显示时候的耗时。对于一些复杂的布局,我们还会自己做复用池,减少 inflate 带来的性能损耗,特别是在列表中。
加快界面显示
1)可以通过 TraceView 工具找出主线程的耗时操作和其他耗时的线程并作优化。另外减少主线程的 GC 停顿,因为即使并行 GC,也会对 heap 加锁,如果主线程请求分配内存的话,也会被挂起,所以尽量避免在主线程分配较多对象和较大的对象,特别是在 onDraw 等函数中,以减少被挂起的时间。另外可以通过去掉 ListView ,ScrollView 等控件的 EdgeEffect 效果,来减少内存分配和加快控件的创建时间。
2)利用本地缓存,主要界面缓存上次的数据,并且配合增量的更新和删除,可以做到数据和服务端同步,这样可以直接展示本地数据,不用等到网络返回数据。
3)减少不必要的数据协议字段,减少名字长度等,并作压缩。还可以通过分页加载数据来加快传输解析时间。因为 JSON 越大,传输和解析时间也会越久,引发的内存对象分配也会越多。
4)注意线程的优先级,对于占用 CPU 较多时间的函数,也要判断线程的优先级。
优化动画细节
通过 TraceView 工具发现,一些 Banner 轮播广告和文字动画在移出可视区域后,仍然存在定时刷新,不仅耗电也影响帧率。优化措施是在移出可视区域后停止动画轮播。
阻断多余 requestLayout
在 ListView 滑动,广告动画变化等过程中,图片和文字有变化,经常会发现整个界面被重新布局,影响了性能。尤其布局复杂时,测量过程很费时导致明显卡顿。对于大小基本固定的控件和布局例如 TextView,ImageView 来说,这是多余的损耗。我们可以用自定义控件来阻断,重写方法 requestLayout、onSizeChanged,如果大小没有变化就阻断这次请求。对于 ViewPager 等广告条,可以设置缓存子 view 的数量为广告的数量。
优化中间件
中间件的代码被上层业务方调用的比较频繁,容易有较多的高频率函数,也容易产生细节上的问题。除了频繁分配对象外,例如类初始化性能,同步锁的额外开销,接口的调用时间,枚举的使用等等都是不能忽视的问题。
减少 GC 次数
安卓上的 GC 会引起性能卡顿,必须重点优化。除了第三章会详细介绍对于图片内存引起 GC 的优化,我们还做了如下工作:
1)减少对象分配,找出不必要的对象分配,如可以使用非包装类型的时候,使用了包装类型;字符串的 + 号和扩容;Handler.post(Runnable r) 等频繁使用。
2)对象的复用,对于频繁分配的对象需要使用复用池。
3)尽早释放无用对象的引用,特别是大对象和集合对象,通过置为 NULL,及时回收。
4)防止泄露,除了最基本的文件、流、数据库、网络访问等都要记得关闭以及 unRegister 自己注册的一些事件外,还要尽量少的使用静态变量和单例。
5)控制 finalize 方法的使用,在高频率函数中使用重写了 finalize 的类,会加重 GC 负担,使得性能上有几倍的差别。
6)合理选择容器,在性能上优先考虑数组,即使我们现在习惯了使用容器,也要注意频繁使用容器在性能上的隐患点:首先是扩容开销, HashMap 扩容时重新 Hash 的开销较大。其次是内存开销,HashMap 需要额外的 Map.Entry 对象分配 , 需要额外内存,也容易产生更多的内存碎片。SparseArray 和 ArrayList 等在内存方面更有优势。再次是遍历,对于实现了 RandomAccess 接口的容器如 ArryList 的遍历,不应该使用 foreach 循环。
7)用工具监控和精雕细琢:在页面滑动过程中,通过 Memory Monitor 查看内存波动和 GC 情况,还可通过 AlloCation Tracker 工具观察内存的分配,发现很多小对象的分配问题。
8)利用 Trace For OpenGL 工具找出界面上导致硬件加速耗时的点,例如一些圆角图片的处理等。
通过多种工具和手段配合,手淘各个界面性能上有了较大的提高,平均帧率提高了 20%,那么内存节省 50% 又是如何实现的哩,请看下文。
第三章 Android 手机内存节省 50%
Android 上应用出现卡顿的核心原因之一是主线程完成绘制的周期过长引起丢帧。而影响主线程完成绘制时间的主要有两方面,一方面是主线程处于运行状态时需要做的任务太多但 CPU 资源有限,另外一方面是 GC 时 Suspend 时直接挂起了所有线程包括主线程。GC 对总体性能的影响在 4.x 的系统上尤为突出,一部分是单次 GC pause 总时长,一部分是用户操作过程中 GC 发生的次数。而决定这两部分的因素就是 Dalvik 内存分配。那么在手淘这样的大型应用中到底是谁占用了内存大头呢?
谁占用了内存
基于双 11 前的手淘 Android 版本,我们在魅蓝 note1(4.4 OS)上滑动完首页后,dump 出其 Dalvik Heap,整体内存占用的分布情况如下图。可以看出,byte 数组(a)占用空间最大,绝大多数是用来存放 Bitmap 的像素数据(Pixel Data)。另外(c)与(d)一起占用了 18.4%, byte 数组加上 Bitmap、BitmapDrawable 总共占用了 64.4%,成为内存占用的主体。这也从侧面说明了手淘是以图片为浏览主体内容的大型应用。而往往图片需要较大的内存块,在分配时引起 GC 的可能性也往往最大。那我们能不能将图片这部分需要的内存移走而不在 Dalvik Heap 分配呢?如果能,那么不单 GC 会明显减少,同时 Dalvik Heap 总大小也会下降 50% 左右,对整体性能会有显著的提升。
(点击放大图像)

何处安放的Pixel Data
Ashmem 即匿名共享内存,使用的核心过程是创建一个 /dev/ashmem 设备文件,控制反转设置文件的名字和大小,最终把设备符交给 mmap 就得到了共享内存。在 Android 系统中 Binder 进程间通信的实现就是依赖 Ashmem 完成不同进程间的内存共享。但此处并不利用其共享特性,而是使用它在 Native Heap 完成内存分配。图片空间如何才能使用 Ashmem,答案在 Facebook 推出的 Fresco 中已有提及,那就是解码时的 purgeable 标记,这样在系统底层解码位图时会走 Ashmem 空间分配,而非 Dalvik Heap 空间。这样就解决了像素数据存放由 Dalvik 到 Native 的问题了吗?
BitmapFactory.Options options = new BitmapFactory.Options();
/*
* inPurgeable can help avoid big Dalvik heap allocations (from API level 11 onward)
*/
options.inPurgeable = true;
Bitmap bitmap = BitmapFactory.decodeByteArray(inputByteArray, 0, inputLength, options);
小心 Bitmap 空包弹
事实并非那么简单,最后实际解出来 Bitmap 没有像素数据(没有到 Ashmem 分配任何空间),根本没有去完成 jpeg 或者 png 解码。此时的 Bitmap 是个空包弹!它所做的只是把输入的解码前数据拷贝到了 native 内存,如果把这个 Bitmap 交给 ImageView 渲染就糟了,在 View.draw() 时 Bitmap 会在主线程进行图片解码。
而且不要天真的以为 Bitmap 解码一次之后再多次使用都不会引起二次解码,在系统内存紧张时底层可能回收 Ashmem 里这部分内存。回收后该 Bitmap 再次渲染时又将在主线程完成一次解码。如果就这样直接使用该机制,性能上无疑雪上加霜。
那么怎样才能避免这个隐形炸弹呢?还好 SDK 预留了一个 C 层方法 AndroidBitmap_lockPixels。而 lockPixels 底层完成的工作大致如下图所示。第一步是 prepareBitmap 完成真正的数据解码,在工作线程调用 AndroidBitmap_lockPixels 避免了在主线程进行数据解码;第二步是完成对分配出来的 Ashmem 空间的锁定,这样即使在系统内存紧张时,也不会回收 Bitmap 像素数据,避免多次解码。
(点击放大图像)

貌似解决了Bitmap 渲染的所有问题,但在手淘中则不然。为了兼容低版本系统以及提升webp 解码性能,我们使用了自己的解码库libwebp.so,怎样把它解码出来的数据也存放到Ashmem 呢?
libwebp 借鸡生蛋
如果自有解码库 libwebp.so 要解码到 Ashmem,通过 SkBitmap、ashmem_create_region 实现一套类似的机制是不太现实的。一方面 Skia 库的源码编译兼容会存在很大问题,另一方面很多系统层面的核心接口并没有对外。所以实现这点的关键还是要借助系统已经提供的 purgeable 到 Ashmem 的机制,借鸡生蛋,稳定性和成本上都能得到保证:
- 依据图片宽高生成空 JPEG。
- 走系统解码接口完成 Ashmem Bitmap 生成。
- 覆写 Pixel Data 地址在 libwebp
完成解码。
更进一步,迁移解码前数据
上面谈到的内存迁移都是针对 Decoded 像素数据的,而 Encoded 图像数据在解码时会在 Dalvik Heap 保存一份,解码完成后再释放;Ashmem 方式解码时在底层又会拷贝一份到 Native 内存,这份数据直到整个 Bitmap 回收时才释放。那能否直接将网络下载的 Encoded 数据存放到 Native 内存,省去 Dalvik Heap 上的开销以及解码时的内存拷贝呢?的确可以,将网络流数据直接转移到MemoryFile可实现,但遗憾的是真机测试中发现,小米及其他国产“神机”(自改 ROM),多线程使用 MemoryFile 获取 fd 到 BitmapFactory 解码,会出现系统死机,怀疑是在并发情况下系统代码级别的死锁造成。手机淘宝放弃了这种方案,改用 ByteArrayPool 复用池技术来减少 Dalvik Heap 针对 Encoded Image 的内存分配,效果也不错。如果应用能接受单线程解码,还是 MemoryFile 方案更具优势。
是放手的时候了
上文提到 Bitmap 像素数据存放到 Ashmem,有读者可能担心数据回收问题,其实还是由 GC 来触发 Ashmem 内存的回收。在 Dalvik 层如果一个 Bitmap 已经不被任何地方引用,那么在下一次 GC 时该 Bitmap 就会从 Ashmem 中回收,大致流程示意如下图。
(点击放大图像)

再看内存占用
我们再次在魅蓝note1 中dump 出首页滑动后的内存,如下图可以看出,原来byte 数组(k)大量占用已经不存在了,Bitmap(c)与BitmapDrawable(已不在前14 名当中)的占用也急骤下降。应用的总体内存下降近60%。
(点击放大图像)

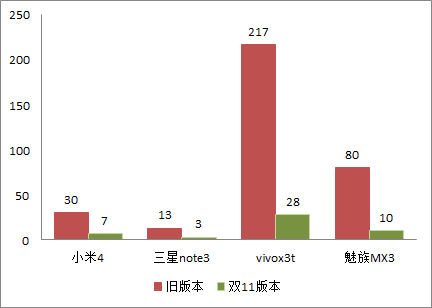
在双11 版本上,针对一些热门机型在搜索结果页不断滚动使用,进行了不同版本的内存占用对比分析,如下图。可以看出,除华为3c 和vivo 这类系统内存偏小使用上一直受到控制、内存较为紧张的外,大部分机型内存的下降幅度都达到45% 以上。
(点击放大图像)

挠走GC 之痒
内存下降不是最终目的,最终要将GC 对性能的影响降到最低。仍然以魅蓝note1 打开首页后滑动到底的内存堆积图来做对比。可以看到旧版本内存占用上升趋势相当明显,一路带有各式“毛刺”直奔70MB,每形成一个毛刺就意味一次GC。而双11 版本中,内存只在初期有上升,而后很快下降到21MB 左右,后期也显得平滑得多,没有那么多的“毛刺”,就意味着GC 发生的次数在明显减少。
(点击放大图像)

旧版本
(点击放大图像)

双11 版本
同时使用一些热门机型,针对双十一版本在首页不断滑动,进行前后版本的GC_FOR_ALLOC 次数对比。热门机型GC 次数下降了4~8 倍,效果非常明显。
通过上文描述的各个优化方案,手机淘宝于双十一前在大部分机型上达到了521 目标-Android 手机内存节省50%,启动时间和页面帧率提升20%,H5 页面实现1s 法则。
从持续不断的优化中,我们也得到了一套优化的经验闭环,由观察问题现象到分析原因,建立监控,定下量化目标,执行优化方案,验证结果数据再回到观察新问题。每一次闭环只能解决部分问题,只有不断抓住细微的优化点“啃”下去,才能得到螺旋上升的良好结果。
当然,随着手机机型的日益碎片化,程序功能的复杂化多样化,性能调优是没有止境的,在部分低端机和低内存手机上手淘性能问题依然不容乐观。欲穷千里目,还需更上一层楼,接下来我们还会努力通过更多更细致的优化方案来达到“如丝般顺滑”。
手机淘宝技术团队陈虹如(岑安)、倪天雪(晓田)、徐凯(鬼道)、王曜东 (雪鹭)、吕承飞(吕行)、赵密(正凡)、黎明(雷曼)等同学参与本文创作。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




