

本文最初发表于 Towards Data Science 博客,经原作者 Logesh Kumar Umapathi 授权,InfoQ 中文站翻译并分享。
如果说机器学习项目是冰山的话,那么位于水下的部分就是项目中的标签和其他数据工作。好消息是,像迁移学习和主动学习(Active Learning)这样的技术可以帮助减少工作量。
主动学习已经成为机器学习行业从业者的工具箱的一部分,但在任何数据科学/机器学习课程中,却很少涉及。在阅读Robert Munro写的书《Human-in-the-Loop Machine Learning》(译注:目前尚无中文版)后,帮助我正式形成了一些(并帮助我学习了很多)主动学习的概念,而这些概念我一直在机器学习项目中凭直觉使用。
本文写作目的是向你介绍一种简单的主动学习方法,称为“基于熵的不确定采样”(Uncertainty sampling with entropy),并通过实例证明其有效性。在演示中,我使用了主动学习,仅利用了 23% 的实际训练数据集(ATIS 意向分类数据集)来实现与 100% 数据集训练相同的结果。
是不是迫不及待了?请直接跳到「演示」一节。想了解它是如何工作的?那就继续读下去。
什么是主动学习?
主动学习是指训练我们的模型时,优先考虑那些能给我们带来最大收益的有标签样本,而不是那些“学习信号”很少的样本。利用模型的反馈,对一个实例的学习信号进行估计。
这就好比老师问学生她不太清楚的概念,然后优先考虑讲解这些概念,而不是教授所有的课程。
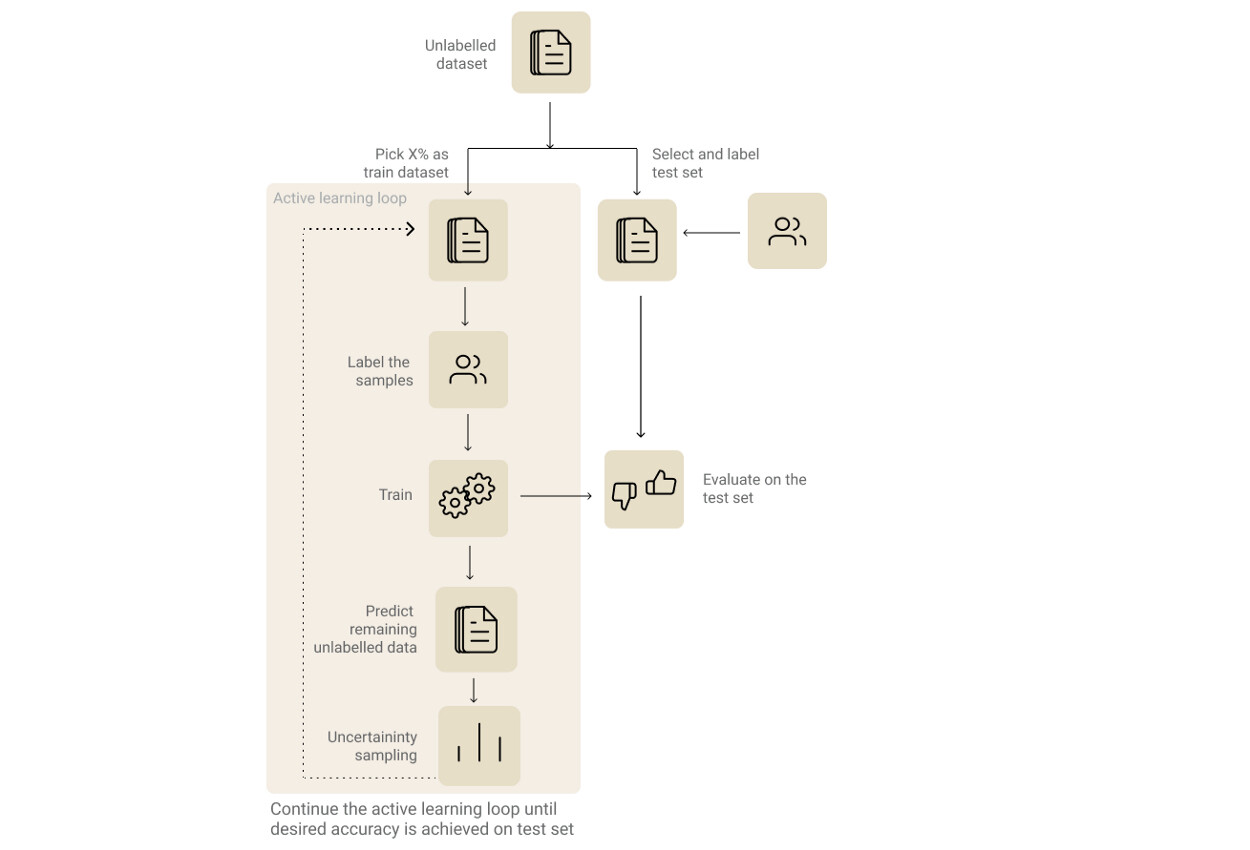
因为主动学习是一个迭代的过程,你必须经历多轮训练。主动学习涉及的步骤包括:
步骤 1:识别并标记评估数据集
毋庸讳言,在任何机器学习过程中,选择评估集都是最重要的一步。当涉及到主动学习时,这一点变得更为关键,因为这将是我们在迭代标记过程中衡量模型性能改进程度的标准。此外,它还帮助我们决定何时停止迭代。
最直接的方法是随机拆分未标记的数据集,并从拆分的数据集中选择评估集。但基于复杂性或业务需要,最好拥有多个评估集。例如,如果你的业务需求要求情感分析模型能够很好地处理讽刺言论,则可以有两个独立的评估集:一个用于一般情感分析,另一个用于特定于讽刺的样本。
步骤 2:识别并标记初始训练数据集
现在选择未标记数据集的 X% 作为初始训练数据集。X 的值可以根据模型和方法的复杂程度而有所不同。选择一个足够快的值进行多次迭代,并且要足够大,可以让你的模型在初始阶段进行训练。如果你使用迁移学习方法,并且数据集的分布接近基本模型的预训练数据集,那么较低的 X 值就足以启动该过程。
这也是一个很好的做法,在初始训练数据集中可以避免出现类不平衡的现象。如果这是一个自然语言处理问题,你可以考虑使用基于关键字的搜索,从特定的类中找出样本进行标记,并维持类平衡。
步骤 3:训练迭代
现在我们已经有了初始的训练和评估数据集,我们可以继续进行第一次训练迭代。通常,人们并不能通过评估第一个模型来作出太多推断。但是这个步骤的结果可以帮助我们看到预测是如何随着迭代而改进的。使用该模型预测剩余未标记样本的标签。
步骤 4:从上一步选择要标记的样本子集
这是至关重要的一步,你可以选择标记过程中学习信号最多的样本。有几种方法可以做到这一点(如书中所述)。为简洁起见,我们将看到我认为最为直观的方法:基于熵的不确定采样。
基于熵的不确定采样:
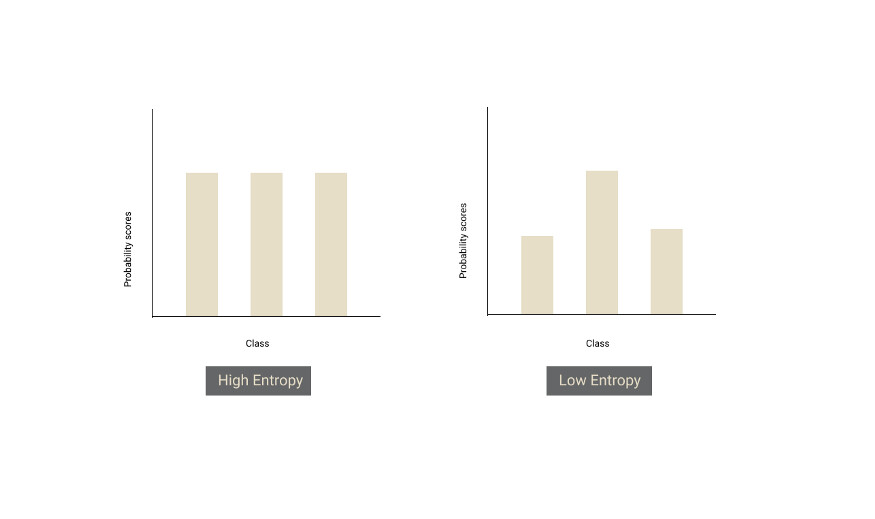
不确定采样是一种选择模型最不确定/最困惑的样本的策略。计算不确定度有几种方法。最常用的方法是利用神经网络最后一层的分类概率(SoftMax)值。
如果没有明确的赢家(即所有概率几乎相同),这意味着模型对样本是不确定的。熵恰好给了我们一个度量标准。如果所有类别之间存在相关性,则分布的熵值将会较高,如果类别之间存在明显的赢家,则分布的熵值较低。
根据模型对未标记数据集的预测,我们应该按照熵值的递减顺序对样本进行排序,并从中选择 Y% 的顶部样本进行注释。
步骤 5:数据清洗与重复
我们需要在这次迭代的训练数据集附加新的标签样本,并重复步骤 3 中的过程,直到我们在评估集上达到预期的性能或评估性能停滞。
演示
出于实验和演示目的,我们将使用ATIS 意向分类数据集。让我们将训练数据集视为未标记的。我们从随机抽取 5% 的标记训练数据集作为第一次迭代。在每次迭代结束时,我们使用基于熵的不确定采样来选择前 10% 的样本,并使用它们的标签(模拟现实世界中的注视过程)在下一次迭代中进行训练。
为了在主动学习的每次迭代期间评估我们的模型,我们还从数据集中获取测试集,因为测试集中的数据已经被标记。
演示和代码可以在下面的 Notebook 中找到:
https://colab.research.google.com/drive/1BsTuFK8HcXS5WWlOCS1QHgvHRf2FK6aD?usp=sharing
参考文献
《一种训练文本分类器的顺序算法》(A Sequential Algorithm for Training Text Classifiers.),David D. Lewis、William A. Gale,1994 年,SIGIR’94
《Human in the loop machine learning》,Robert Munro。
作者介绍:
Logesh Kumar Umapathi,居住在印度泰米尔纳德邦,专注于机器学习、自然语言处理的高级顾问,供职于 Saama。对自然语言处理和深度学习充满热情。
原文链接:
https://towardsdatascience.com/how-to-do-more-with-less-data-active-learning-240ffe1f7cb9
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ高级技术编辑

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论