

本文由 dbaplus 社群授权转载。
DevOps 的作用
传统企业级 IT 产品具有规模大、开发人数多、技术水平相对落后的缺点,每一代产品从源代码构建、测试到发布的过程都会跨越组织内部多个相对分离的领域,且产品开发完全外包,对产品迭代速度、交付质量有较大影响。因此,需要一种方法和技术:
能够有效缩短提交代码到正式部署上线的时间,降低风险;
能够自动地、快速地提供反馈,以便及时发现和修复缺陷;
能够让整个交付过程变得可靠、可预期、可视化。
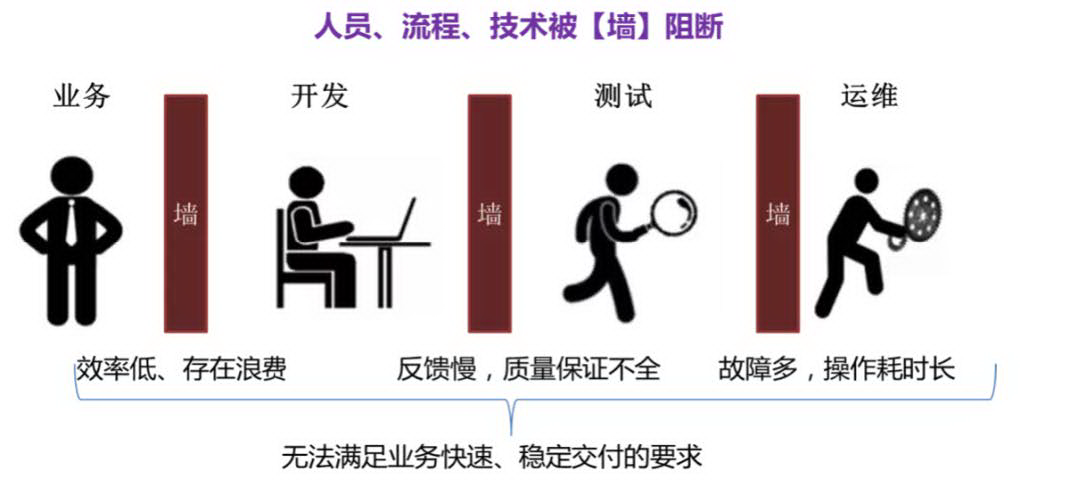
企业引入 DevOps 理念,努力将支撑系统传统开发模式和系统运营方式向以业务价值为导向的开发运营融合模式转型。以平台形式固化开发运营一体化框架体系的流程,打通从敏捷需求管理、配置管理、个人构建、版本构建、系统测试、上线发布及产品运营的产品全生命周期,实现了产品全流程可视化、评价指标规范化、产品运营可持续化。
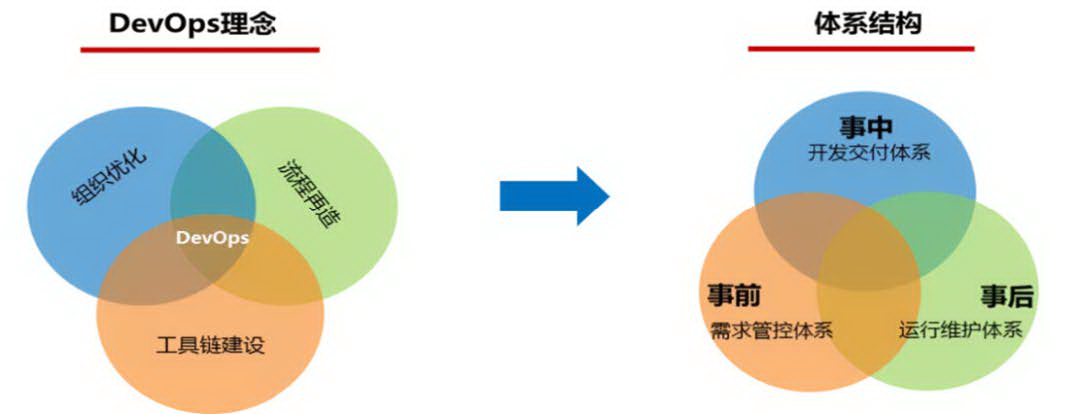
提供软件开发全生命周期管理和流程自动化,逐步解决研发、QA、运维三者之间的矛盾,促进产品需求快速响应、版本快速迭代、流程更清晰、管理可视可控等。
以上简单交代了 DevOps 的作用,下面详细讲述一个笔者经历过的 DevOps 实践案例。
DevOps 持续交付实践
客户背景
以一家金融企业为背景的案例,该企业有各类项目 500+,开发人员 1000+。技术栈百花齐放,有 JAVA、NPM、Python、Scala、GO 等。以 JAVA 技术为例,有 MAVEN、ANT 编译、容器,有微服务、父子工程、传统技术架构,有配置分离与不分离的差别等。
由于历史原因,环境也存在差异,部分项目有 SIT、UAT,部分项目只有 SIT。制品提交生产的过程由各个项目组负责,不统一、标准化难落地。可以说国内大多数大中型企业都有类似情况。
综上所述,在集中、统一管理的前提下,如何快速、有效、稳定地给生产提供制品成为了首要目标。
实施效果
先对比一下持续交付实施前后的情况,按客户要求,一次完整的制品交付应该包括:
拉取代码>>编译打包>>部署 SIT>>通知 SIT 测试>>部署 UAT>>通知 UAT 测试 >>提升生产
实施前: 每个项目需要一个专人,一次交付大约需要 3 小时,如果出现错误,大约 0.5-1 天不等,人为误操作无法避免,规范、标准难落地。
实施后: 一键触发无需专人,一次交付大约需要 30 分钟,不会有人为误操作,标准化流水线。单次交付时间能够减少 2.5 小时左右,交付效率大约提高 6 倍。
接入各类变更频繁的项目 150+,工程数量 800+,管理 10000+制品,持续交付流水线已运行 70000+次,月均运行超过 10000+次,基本实现了快速、有效、稳定地给生产提供制品的目标,当然,我们还在不断改善中……
DevOps 是一个较大的概念,持续交付只是一个组成部分。
关注持续交付,不同的企业、不同的团队站在不同的角度存在不同的定义。本文只是从软件研发的技术角度进行定义:
持续交付(Continuous delivery)指的是,频繁地将软件的新版本,交付给质量团队或者用户,以供评审。如果评审通过,制品(也就是常说的程序包)就进入生产阶段。
看下图胜过千言万语:
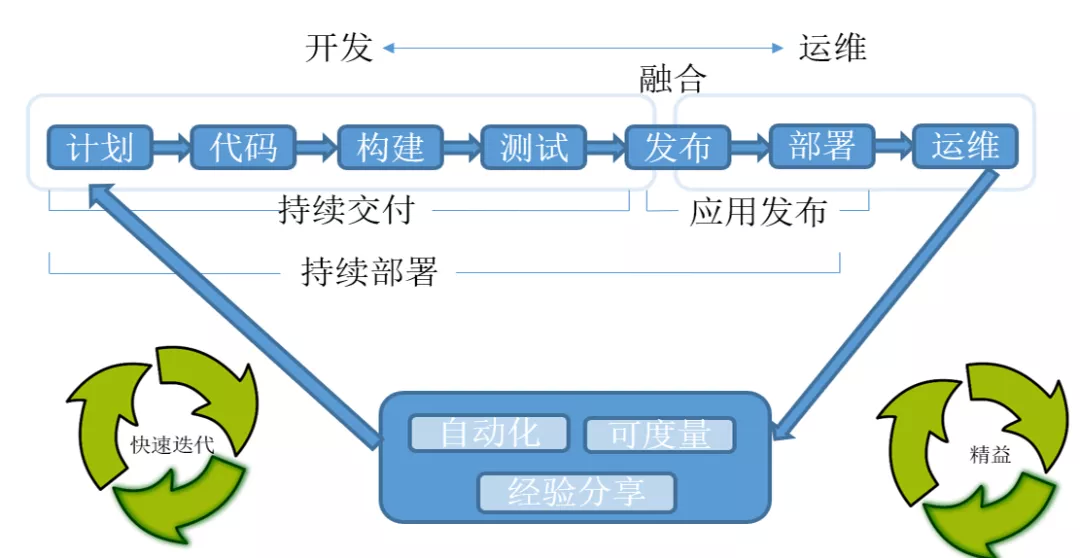
实施持续交付前的问题
客户在做持续交付前遇到的主要问题如下:
缺乏统一标准,各个项目组自行交付,需要熟悉本项目情况的专人负责,专人不在就影响交付;
交付规范难落地、难监管,例如程序包变更不通过编译打包,而是手工替换变更文件;变更后不再经过测试评审等等,常有发生;
测试程序包与生产程序包代码来源不一致,导致问题流向生产;
程序包没有按照标准目录存放,或者版本号错误,导致生产拿错了程序包;
跨团队交互效率低,例如开发团队、测试团队、验收团队相互通知不及时等。
当然还有其他问题,篇幅原因就不一一罗列了。
持续交付建设思路
面对各种各样的问题,在这里跟大家分享几个主要的持续交付建设思路:
一、一次构建打包(Automaktic Delivery):在测试、UAT、生产等环境的流转过程中,只打包一次,软件包按顺序交付到各个环境,最终发布生产
为了让交付标准能够落地,不再只是一个 Word 文档,我们先控制了交付流水线的源头,不再像使用开源 Jenkins 一样,可以自由创建。对于纳入交付标准的交付方式,都会为其创建对应的模板,项目接入后,可以根据自己的情况,选择不同的模板使用,交付过程只需要一键触发,不再依赖专人实施。
基于可选模板的流水线创建的实现技术逻辑如下:
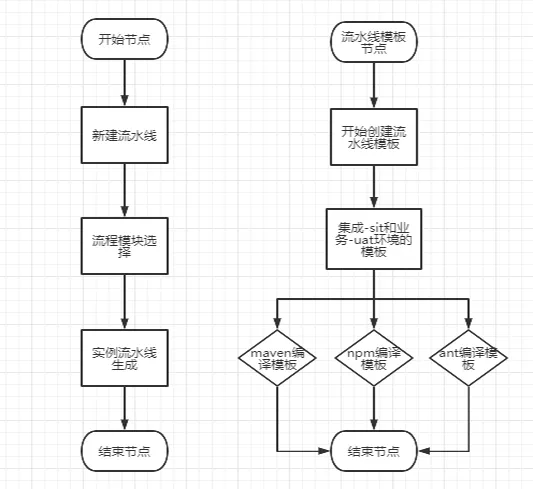
创建流水线模板时,会根据环境来定义出模板的归属:如 sit 集成测试环境、uat 业务测试环境、sit 和 uat 的联合测试环境。
流水线模板以项目工程的编译构建工具的类型来区分属性,如 maven 属性模板、ant 属性模板。
用户可根据实际的软件上线的场景,定义自己所需的流水线常用节点阶段。
创建流水线时,可以根据环境属性和构建类型来选择对应的模板,节省了重复配置流水线的时间。
在创建流水线时,如果工程的属性是单制品,生成会是一条流水线;如果工程的属性是多制品,生成会是两条流水线;如果工程属性是应用配置未分离,生成的流水线会是多个编译命令的场景;如果工程属性是应用配置分离,生成的流水线会是一个编译命令的场景。
二、制品存放、流转规则对操作人员透明
持续交付会频繁地产出制品,但并不是每一个制品都能推给生产,面对成千上万的制品如何存放才不会导致混乱,如何确保制品从开发到测试、从测试到验收,最后推给生产的过程是正确的,是需要有一套完备、细致的规则进行约束的。由于这一块工作繁重且容易出错,人力管理很难满足要求,所以在这里分享一下我们的做法。
首先是制品存放,从如下四个部分考虑存放规则:
team:产品或团队、组织结构名称作为项目的主要标识符;
technology:使用的技术,工具或包的类型,例如 maven、npm 等;
maturity:软件包生命周期,例如开发、测试和发布阶段等;
version:版本。
例如:研发中心运维项目组—NPM 技术—SIT 测试—V1.0
那么这样的存放方式可以方便从不同角度快速定位需要的制品。
其次,为了保证软件上线部署准确性,每一个业务版本对应的是正确的制品包,一套自动化制品生命周期管理方法尤为重要,参考下图:
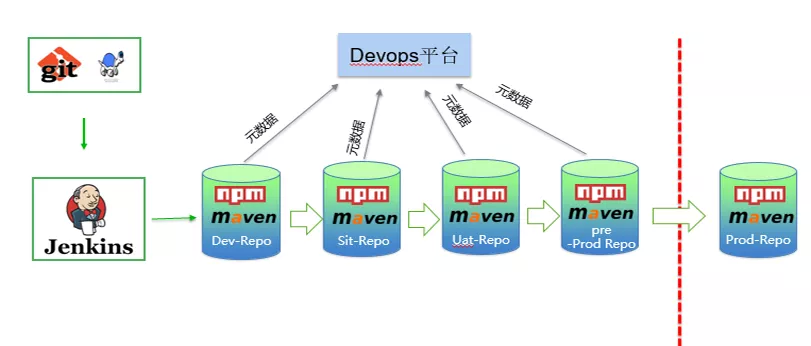
在研发阶段,代码检出时,根据工程的属性,如是应用配置未分离的情况,每次编译构建的时候,会出来各个环境制品,有多少个环境就有多少个制品,例如:dev(开发环境)的制品、sit(集成测试环境)的制品、uat(业务测试环境)的制品、pre(预生产环境)的制品,这些制品会存放在开发阶段的指定制品仓库中,当开发人员测试通过后,流水线会自动将在开发阶段仓库里的 sit 制品提升至 sit 测试的制品仓库里;当测试人员测试通过后,会将开发阶段仓库里的 uat 制品提升到 uat 制品仓库里;当业务测试人员测试通过后,会将开发阶段仓库里的 pre 制品提升到预发布库。
如是配置应用已分离的情况,只会编译出来一个制品,流水线的制品整体生命周期就只会针对该制品进行流转,当开发人员、测试人员完成之后,制品会相应提升至预发布库。
制品在提升到预发库时,项目经理会针对这次上线进行质量关卡的把关,同时会将此次制品全生命周期涉及到部署次数、构建信息、测试信息、质量代码等信息,收集到一起,作为上线发布的依据,如果项目经理担心制品流转出错,还可以通过 MD5 进行比对,按照如下流程:
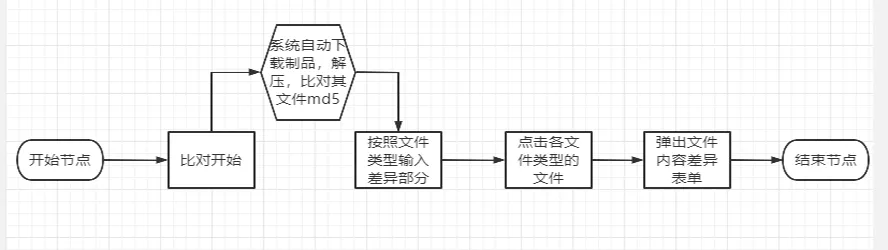
例如用 sit 制品与提交生产的 prod 制品比对,对比文件差异如下图:
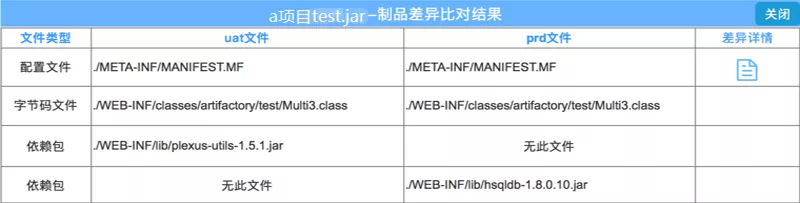
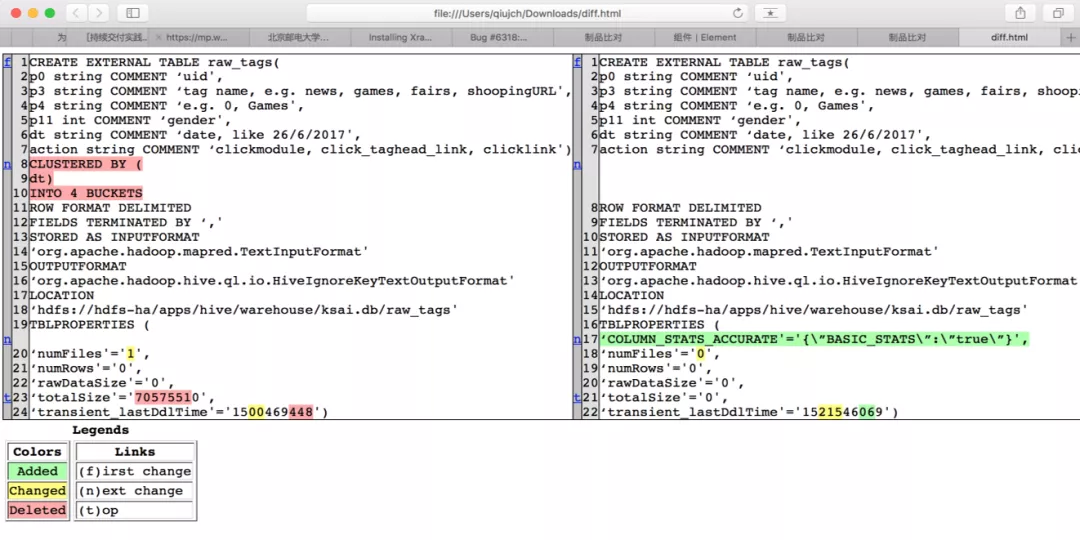
查看详细的差异:
三、线上跨团队交互,记录交互节点信息
如下图,先看看跨团交互节点:
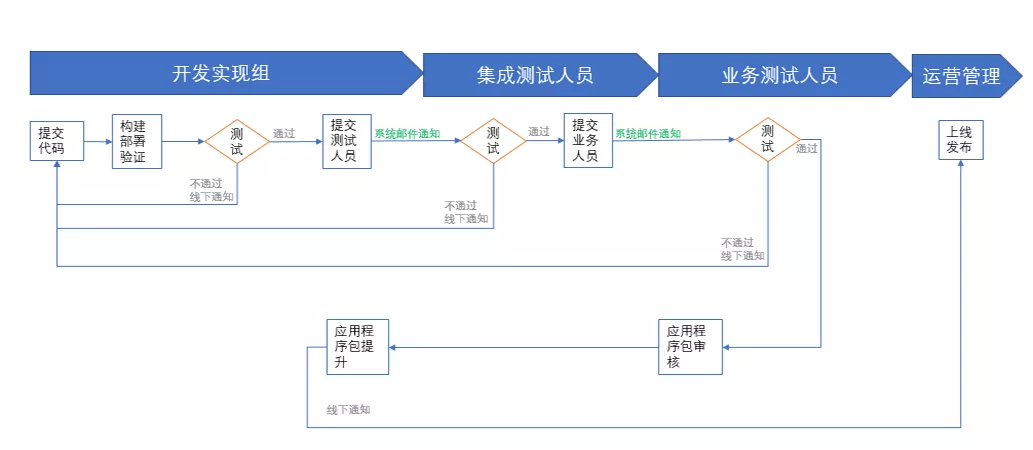
没错了,这里交互的节点就是提交测试人员、应用程序包审核、应用程序包提升,以提交测试人员为例,简单功能描述如下:
开发者提交测试人员:开发人员在完成代码提交、编译部署流程后,使用提测功能供邮件通知提交测试人员进行测试。
开发人员——>提交测试人员——>测试人员
测试者提交业务人员:测试人员完成测试后,如果不通过,则线下通知开发人员修复;如果通过,则使用提测功能邮件通知业务人员进行验收测试。
测试人员——>提交业务人员——>业务人员
大家可能会想,这就是一个简单的通知功能,能有多大作用?别小看了,效果有两个:
通知的内容涉及需求版本、有多少个制品、测试是否达标等专业信息,自动通知只需要填写收件人的信息即可,大大降低了对操作人员专业技能的要求;
大大缩短了跨团队协作的碎片等待时间,效率得到提升。
以上是我们持续交付的经验分享,持续交付方式多种多样,能解决客户痛点,提升效率与质量,减少交互过程中的等待时间就是好办法。
作者介绍:
符强,新炬网络 DevOps 专家,从事 IT 行业 10 余年,拥有丰富的开发、测试、运维工作经验。现致力于 DevOps 相关建设与实施推广的研究,具有多个大型电信、金融企业 DevOps 项目经验。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论