
引言
很多人在使用搜索引擎的时候,会出于各种原因,拼错想要搜索的关键字,比如键盘有问题(某个按键坏了)、不熟悉国际名称(弗洛伊德的全名 Sigmund Freud)、不小心写错字母(Sinpsons)或多写了一个字母(Frusciaante)。许多用户都很熟悉 Google 搜索引擎携带的“您是不是要找”功能。这个功能在检测到搜索关键字有可能拼写错了的时候会提供一些备选建议。
文本搜索在电子商务网站等各类应用中都很常见。电子商务网站通常提供文本搜索功能,用户因此可以自行查找符合关键字的产品目录。一旦用户拼错关键字,很可能就直接导致销售损失。举例来说,假如你运营一个销售 DVD 的在线商店。阿诺德·施瓦辛格(Arnold Schwarzenegger)的影迷想在你的网店购买施瓦辛格主演的所有 DVD。他首先做的就是在搜索栏键入施瓦辛格的名字,可是如果他把名字拼错了,拼成了“Arnold Swuazeneger”,假如你的网店没有返回任何相关的结果,那他就会去另一家网店购买。
解决这个问题的其中一个方案就是利用内置的领域知识来实现“您是不是要找”的功能,向用户提供“您是不是要找 Arnold Schwarzenegger”的建议。本文将要探讨的就是如何用 Java 来实现这个功能。
编辑距离算法
在信息论和计算机科学领域,两个字符串之间的编辑距离是指将其中一个字符串用另一个字符来替换所需要的操作次数。定义编辑距离的方式有好几种,使用这些定 义计算编辑距离值的算法也有很多。主要的算法有 Levenshtein、Jaro-Winkler 和 n-gram。 Jaro-Winkler 是 Jaro 距离度量的一个延伸,主要应用于记录连接领域(重复检测)。 Levenshtein 算法中,两个字符串之间的距离定 义为将一个字符串转换为另一字符串所需的最少编辑次数,允许的编辑操作有插入、删除、单个字符的替换。该算法由 Vladimir Levenshtein 在 1965 年提出,并以作者名来命名。 n-gram 是一个概率模型,按顺序预测下一个编辑项,这一模型广泛用于统计自然 语言处理和基因序列分析的各个领域。
本文并非要研究如何从头实现这些算法,我们要关注的是如何借助 Apache Lucene 中已有的实现——SpellChecker 项目来应用这些算法。
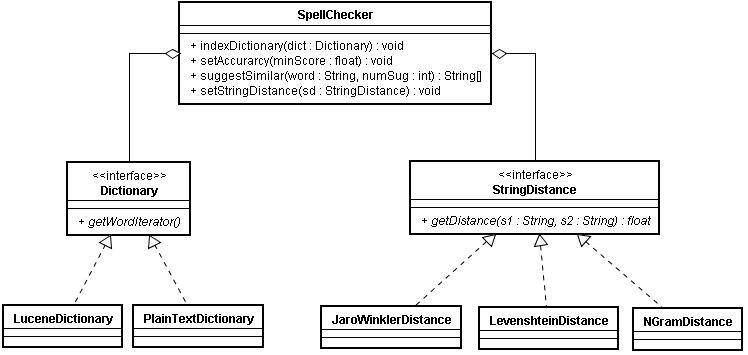
简单来说,Lucene SpellChecker 实现包括主类 SpellChecker,主类 SpellChecker 用到了 Directory、Dictionary、以及三个 StringDistance 算法之一。SpellChecker 类使用策略模式(GoF)选择 StringDistance 算法,内置的 StringDistance 算法实现有 JaroWinklerDistance、 LevenshteinDistance、NGramDistance,缺省为 LevenshteinDistance。你还可以调整精度,精度的取值范围在 0 到 1 之间,缺省为 0.5。精度的设置对结果有很大影响,也许你会觉得精度应当设置得比缺省值要高一些,但也许你会发现设置得过高时算法却不会返回任何结果。拿我的词典来说,精度取 0.749 时得到的结果最好。Dictionary 接口有两个直接实现,你也可以编写自己的实现。
对我们的“您是不是要找”实现来说,我们在词典中搜索关键字的子集,根据选定的字符串距离算法查找“相近”的关键字,而且距离要与预先设置的精度相匹配。图 1 是 Lucene SpellChecker 的类图概览。
示例
下面是一个简单的代码示例。运行这个例子需要 Java 5 或更新版本、lucene-core-3.0.0.jar、lucene-spellchecker-3.0.0.jar,以及一个名为 dictionary.txt 的平面文件(一行一个关键字的简单文本文件,后面有一个例子)。
// 创建词典 // 实例化拼写检查器 final SpellChecker sp = new SpellChecker(directory); // 对词典进行索引 sp.indexDictionary(new PlainTextDictionary(new File("dictionary.txt"))); //“错误”的搜索 String search = "Arnold Swuazeneger"; // 建议个数 final int suggestionNumber = 5; // 获取建议的关键字 String[] suggestions = sp.suggestSimilar(search, suggestionNumber); // 显示结果 System.out.println("Your Term:" + search); for (String word : suggestions) { System.out.println("Did you mean:" + word); } // 再创建一个拼写错误的搜索 search = "bava"; suggestions = sp.suggestSimilar(search, suggestionNumber); System.out.println("Your Term:" + search); for (String word : suggestions) { System.out.println("Did you mean:" + word); }
给定的 dictionary.txt 文件如下所示:
Seth MacFarlane
Arnold Schwarzenegger
Scarlett Johansson
Rodrigo Santoro
java
lava
bullet
程序的输出为: Your Term: arnold swuazeneger
Did you mean: Arnold Schwarzenegger
Your Term: bava
Did you mean: java
Did you mean: lava
Did you mean: bullet
Benchmarking 测试
为了对性能有所了解,我们在具备以下配置的机器上将示例运行了十五次,取其平均值:
操作系统:Windows XP Professional SP3
处理器:Intel Core 2 Duo E6550 @2.33GHz
内存:1.96GB
测试
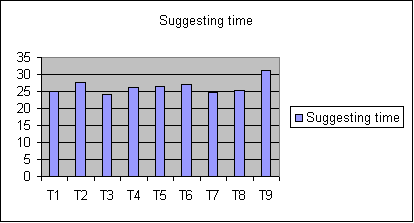
测试编号 关键字长度 词典大小 精度 算法 索引时间 获得建议的时间 T1 17 5 0,5 Levenshtein 73,0136214 25,036049 T2 17 81000 0,5 Levenshtein 3402,293693 27,7293112 T3 17 5 0,5 JaroWinkler 69,53269 24,232477 T4 17 81000 0,5 JaroWinkler 3356,016059 26,287849 T5 17 81000 0,5 NGram 3353,633583 26,580123 T6 17 81000 0,9 Levenshtein 3325,310027 26,96378 T7 17 81000 0,3 Levenshtein 3408,072786 24,723142 T8 4 81000 0,67 Levenshtein 3328,584784 25,363586 T9 28 81000 0,67 Levenshtein 3354,5943 31,284672图表
其中:
关键字长度是关键字包含的字母个数。
词典大小是文件行数。
精度由 setAccuracy 方法设置。
根据测试结果,我们可以得出这样的结论:精度对时间的影响不大,关键字长度对时间却有很大影响——包含四个字符的关键字大约 2ms 就能获得结果。测试的三种算法中,NGramDistance 略快于另外两个。在测试中我还发现,JaroWinkler 距离算法所得到的准确结果最少。
结论
正如你看到的,利用已有的算法使得“您是不是要找”的实现细节出奇的简单。但在现实场景中,要创建支持应用、适用于领域特定关键字的词典则需要花费更多的力气。
参考文献
- http://lucene.apache.org/java/docs/
- http://today.java.net/pub/a/today/2005/08/09/didyoumean.html
- http://archsofty.blogspot.com/2009/12/adicione-o-recurso-voce-quis-dizer-nas.html
- http://lucene.apache.org/java/3_0_0/api/contrib-spellchecker/index.html
- http://en.wikipedia.org/wiki/Edit_distance
- http://en.wikipedia.org/wiki/Levenshtein_distance
- http://en.wikipedia.org/wiki/Jaro-Winkler_distance
关于作者
Leandro R. Moreira 从 2002 年开始参与软件开发,目前是巴西政府机构的一名软件开发人员。他参与很多开源项目的开发,包括 Jpcsp。在 Mudno Java 第 30 期上,他发表了文章《面向对象的世界:实现内部DSL》,此外,他还有一个用母语葡萄牙语维护的博客。
查看英文原文: Implementing Google’s “Did you mean” Feature In Java 。
感谢沙晓兰对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论