

本文由 dbaplus 社群授权转载。
前言
在云平台的日常运维工作中,有很多故障排查和数据核对的场景,为了给全线运维人员(含部分开发和运营分析人员)提供现网数据的实时查询,我们使用 MySQL 和开源工具 otter 搭建了一套数据查询和管理系统,可以查询平台各资源池现网当前的数据。并与现网保持准实时同步(秒级延时)。
查询模块的主要组件是 MySQL,纳管线上业务系统的核心数据库,用户使用频次极高,此台 MySQL 中的部分核心数据还作为其他资源池的源数据,实时同步给异地机房。负责数据实时同步的 otter 管理节点与 MySQL 部署在同一物理机上,是云平台所有资源池中查询模块的中枢节点。
首先,介绍一下开源工具 Otter(内容引自 GitHub)
Otter 是由阿里提供的基于数据库增量日志解析,准实时同步到本机房或异地机房 MySQL 数据库的一个分布式数据库同步系统,工作原理如下:
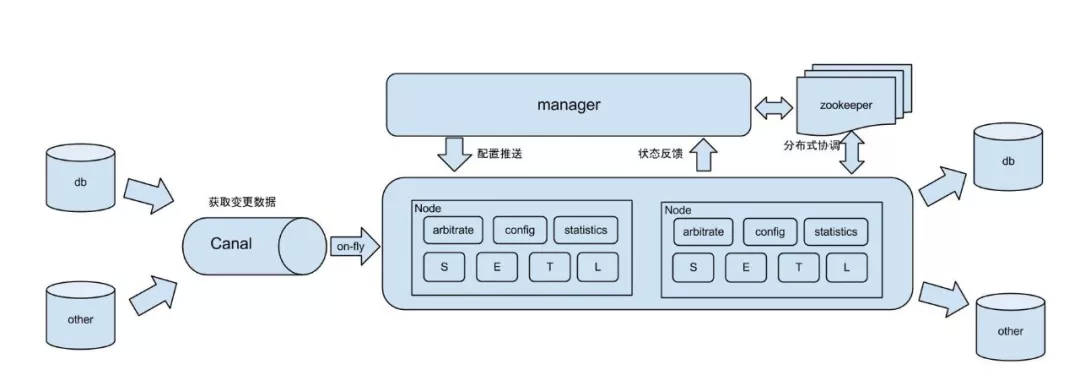
db:数据源以及需要同步到的库;
Canal:用户获取数据库增量日志;
manager:配置同步规则设置数据源同步源等;
zookeeper:协调 node 进行协调工作;
node:负责任务处理处理接受到的部分同步工作。
一、Otter 的特性
1、纯 JAVA 开发,占时资源比较高
2、基于 Canal 获取数据库增量日志数据,Canal 是阿里另一款开源产品
下面是 Canal 的原理图:
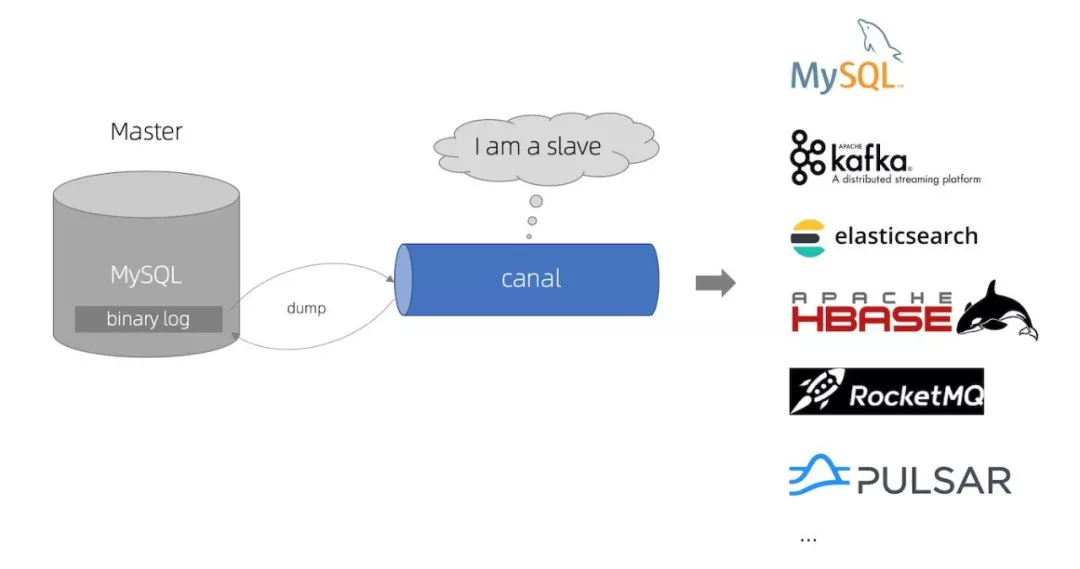
基于 MySQL 主备复制原理:

MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件 binary log events,可以通过 show binlog events 进行查看);
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log);
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据。
Canal 工作原理:
Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议;
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal );
Canal 解析 binary log 对象(原始为 byte 流)。
3、典型管理系统架构,manager(web 管理)+node(工作节点)
1)manager 运行时推送同步配置到 node 节点,负责配置监控
2)node 节点将同步状态反馈到 manager 上,负责处理任务
4、基于 zookeeper,解决分布式状态调度的,允许多 node 节点之间协同工作
5、使用 aria2 多线程传输技术,对网络依赖带宽依赖较低
二、Otter 能解决什么问题
1、异构库同步
MySQL -> MySQL/Oracle。(目前开源版本只支持 MySQL 增量,目标库可以是 MySQL 或者 Oracle,取决于 Canal 的功能)
2、单机房同步 (数据库之间 RTT < 1ms)
数据库版本升级;
数据表迁移;
异步二级索引。
3、异地机房同步(是 Otter 最大的亮点之一,可以解决国际化问题把数据从国内同步到国外提供用户使用,在国内场景可以做到数据多机房容灾)
机房容灾
4、双向同步(双向同步是在数据同步中最难搞的一种场景,Otter 可以很好的应对这种场景,Otter 有避免回环算法和数据一致性算法两种特性,保证双 A 机房模式下,数据保证最终一致性)
1)避免回环算法 (通用的解决方案,支持大部分关系型数据库)
2)数据一致性算法 (保证双 A 机房模式下,数据保证最终一致性,亮点)
5、文件同步
站点镜像 (进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片)
单机房复制示意图:
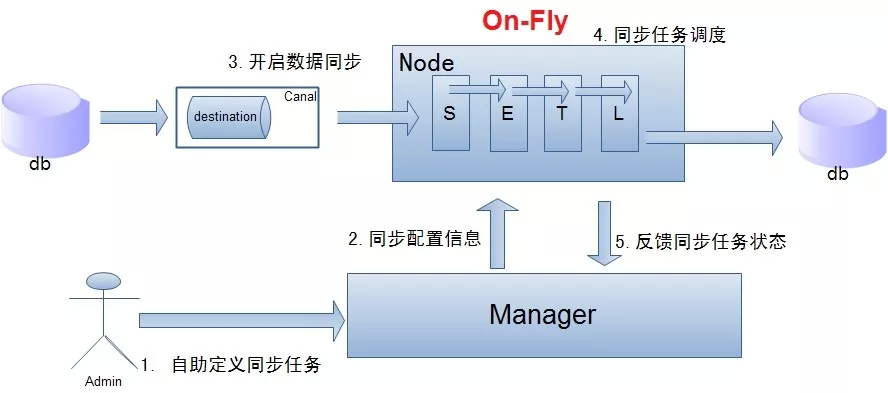
说明:
数据 on-Fly,尽可能不落地,更快的进行数据同步. (开启 node loadBalancer 算法,如果 Node 节点 S+ETL 落在不同的 Node 上,数据会有个网络传输过程);
node 节点可以有 failover / loadBalancer。
异地机房复制示意图:
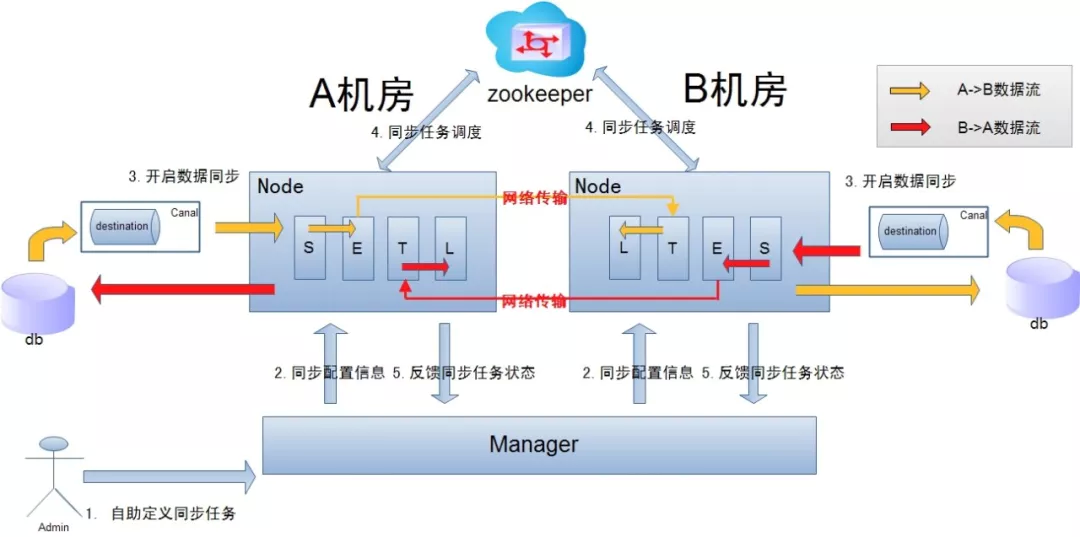
说明:
数据涉及网络传输,S/E/T/L 几个阶段会分散在 2 个或者更多 Node 节点上,多个 Node 之间通过 zookeeper 进行协同工作 (一般是 Select 和 Extract 在一个机房的 Node,Transform/Load 落在另一个机房的 Node);
node 节点可以有 failover / loadBalancer. (每个机房的 Node 节点,都可以是集群,一台或者多台机器)。
关于 Otter 的调度模型、数据入库算法、一致性、高可用性和扩展性等内容,可以登录 GitHub 了解。
「Otter」相关链接:https://github.com/alibaba/otter/wiki/Introduction
里面有详细的介绍,本文不再赘述,下面重点说明一下 otter 的安装和使用。
三、安装部署
移动云业务需要数据汇总,需将多个主数据库同步汇总到一个从数据库中,方便数据统计分析。Otter 中间件则满足了此需求,相对比多源复制,更加灵活和可塑性。
前面简单介绍了 Otter 的基本信息,下面开始搭建一个 Otter 环境,因为一个 Otter 需要 Manage+node+数据库还有很多的依赖,这里我们先来搭建 Otter 的管理服务器 Manager。
1、环境准备
1)阿里软件
Otter(manager、node)软件:https://github.com/alibaba/otter/releases
Manager 数据库初始化脚本:https://raw.githubusercontent.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
2)集群
Zookeeper:http://download.csdn.net/download/jxplus/9451794
3)JAVA
JDK:测试环境使用 yum 安装 1.6 以上版本
4)数据库
Mysql5.7:http://dev.mysql.com/downloads/mysql/
5)操作系统
CentOS 7.1.1503 (Core):https://www.centos.org/download/
版本信息

2、软件安装
1)操作系统安装
2)java jdk1.6
安装完成操作系统后,使用 yum 安装 jdk1.6 以上版本(含 1.6)
3)安装 MySQL 数据库
4)安装集群软件 ZooKeeper
下载安装包后解压即可,不需要编译安装。然后进行配置:
① 修改 tickTime、clientPort、dataDir 参数
tickTime:时长单位为毫秒,为 zk 使用的基本时间度量单位。例如,1 * tickTime 是客户端与 zk 服务端的心跳时间,2 * tickTime 是客户端会话的超时时间。
tickTime 的默认值为 2000 毫秒,更低的 tickTime 值可以更快地发现超时问题,但也会导致更高的网络流量(心跳消息)和更高的 CPU 使用率(会话的跟踪处理)。
clientPort:zk 服务进程监听的 TCP 端口,默认情况下,服务端会监听 2181 端口。
dataDir:无默认配置,必须配置,用于配置存储快照文件的目录。
② 执行下面命令启动 server
③ 查看是否启动成功
5)安装阿里 otter(manager、node)
① 初始化 manager 的 otter 数据库
连接安装好的 mysql 数据库,在数据库软件中创建 otter 数据库,在操作系统命令行执行:
② 解压 manager 安装包到指定目录,并做如下修改
③ cd /otter/bin 执行 shstartup.sh,查看 vim /otter/logs/manager.log,出现以下信息说明 manager 启动成功

④ 访问本机 ip+port,可以看到 manager 管理平台,使用匿名用户只能查看,使用 admin 用户可以操作配置
⑤ 安装 node,在 manager 页面为 node 定义配置信息,并生一个唯一 id,首先访问 manager 页面的机器管理页面,点击添加机器按钮并配置 node 的一些参数
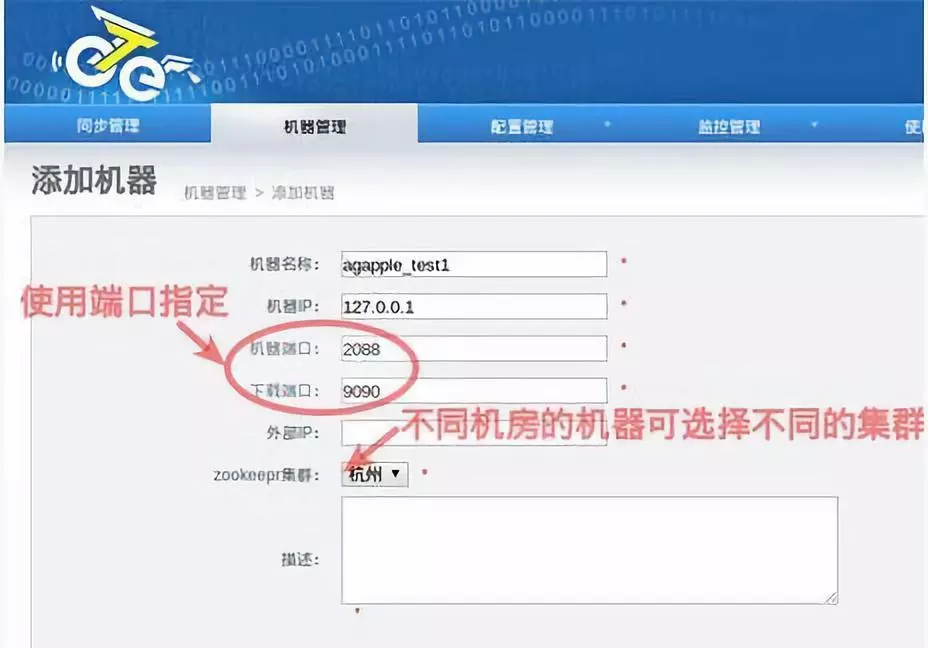
机器名称:自定义,方便记忆即可
机器 IP :对应 node 节点将要部署的机器 ip,如果有多 ip 时,可选择其中一个 ip 进行暴露(此 ip 是整个集群通讯的入口,实际情况千万别使用 127.0.0.1,否则多个机器的 node 节点会无法识别)
机器端口:node 数据通信端口,建议默认 2088
下载端口:node 数据下载端口,建议默认 9090
外部地址:node 部署的物理机外网 IP,存在一个外部 ip 允许通讯的时候走公网处理,没有可以不写。
Zookeeper 集群:zookeper server ip
⑥ 机器添加完成后,跳转到机器列表页面,获取对应的机器序号 nid
⑦ 解压 node 安装包到指定目录,将第五步生成的 nid 写入 conf 目录下的 nid 文件
⑧ 修改 /node/conf/otter.properties 文件
otter.manager.address = manager 安装部署机器的 IP+PORT
例如:
⑨ 启动 node
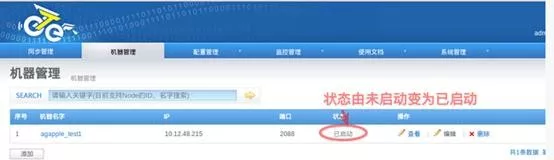
⑩ 验证 node
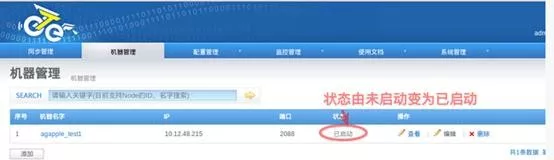
访问 http://managerip:port/node_list.htm,查看对应节点状态,如果变为已启动,说明 node 已经正常启动。
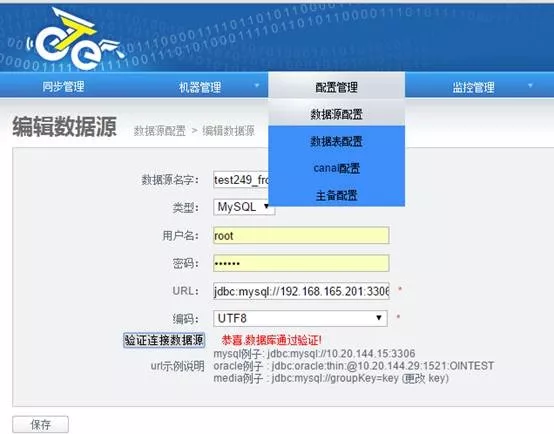
3、同步配置
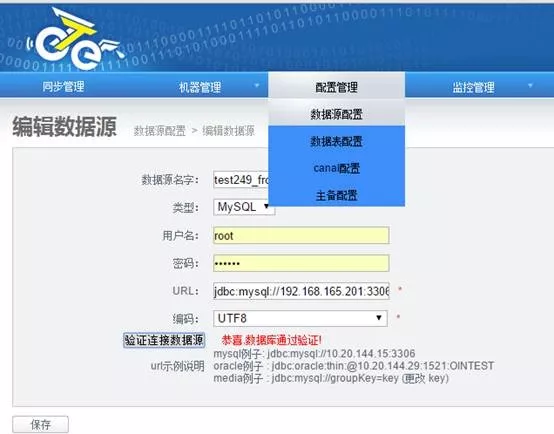
1)添加数据源-数据来源端
2)添加数据源-数据落地端
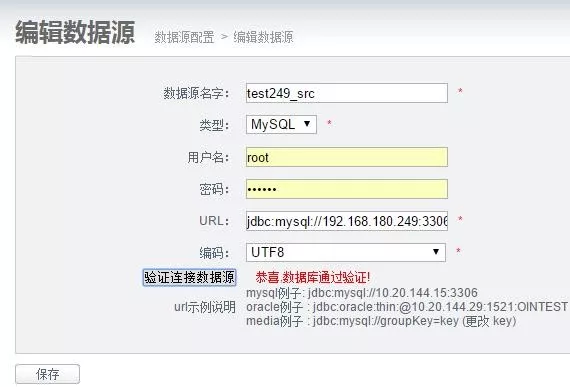
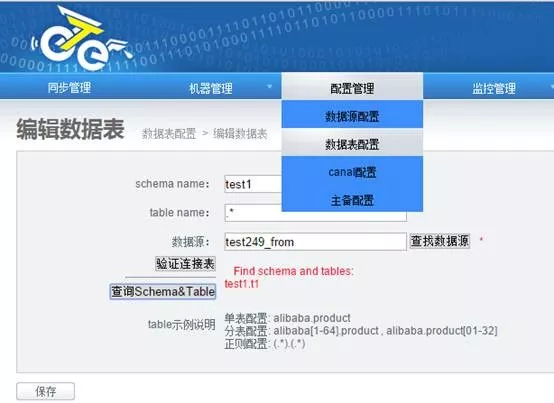
3)添加需要同步的数据表-数据来源端
4)添加需要同步的数据表-数据落地端

5)添加 canal
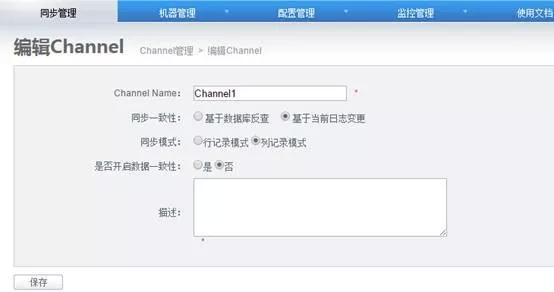
6)添加 channel
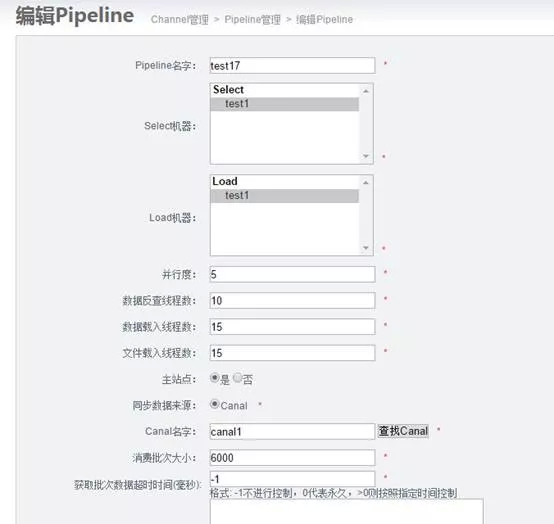
7)添加 Pipeline

点击上一步添加的 channel1,添加 pipeline。
8)添加表映射关系

点击上一步添加的 pipeline test17,添加表映射关系。
9)启动 channel
添加完成表映射关系后,回到 channel 页面,启动刚刚添加 channel1。
10)测试同步
11)构建 kerberos 安全域
由于查询涉及到现网数据的异地传输,数据安全保障工作十分重要,因此构建了 Kerberos 安全域。域内的组件互通,以及外部客户端访问域内组件,均需要经过 kerberos 的认证。
通过上述操作 otter 环境基本配置好了,并且搭建了 zookeeper+manager 环境,成功运行了 otter-manager 管理界面,并完成了数据同步测试。这样我们初步完成了数据同步和查询平台的搭建。
四、数据查询平台的使用
1、访问方法
推荐使用 Navicat 等工具,IP、端口、账号、密码等和原魔数台相同。
可以将访问频次比较高的数据保存为视图。
不建议使用 select * 或没有任何条件的全表查询,查询数据前先查找对象表的主键,并使用主键过滤。
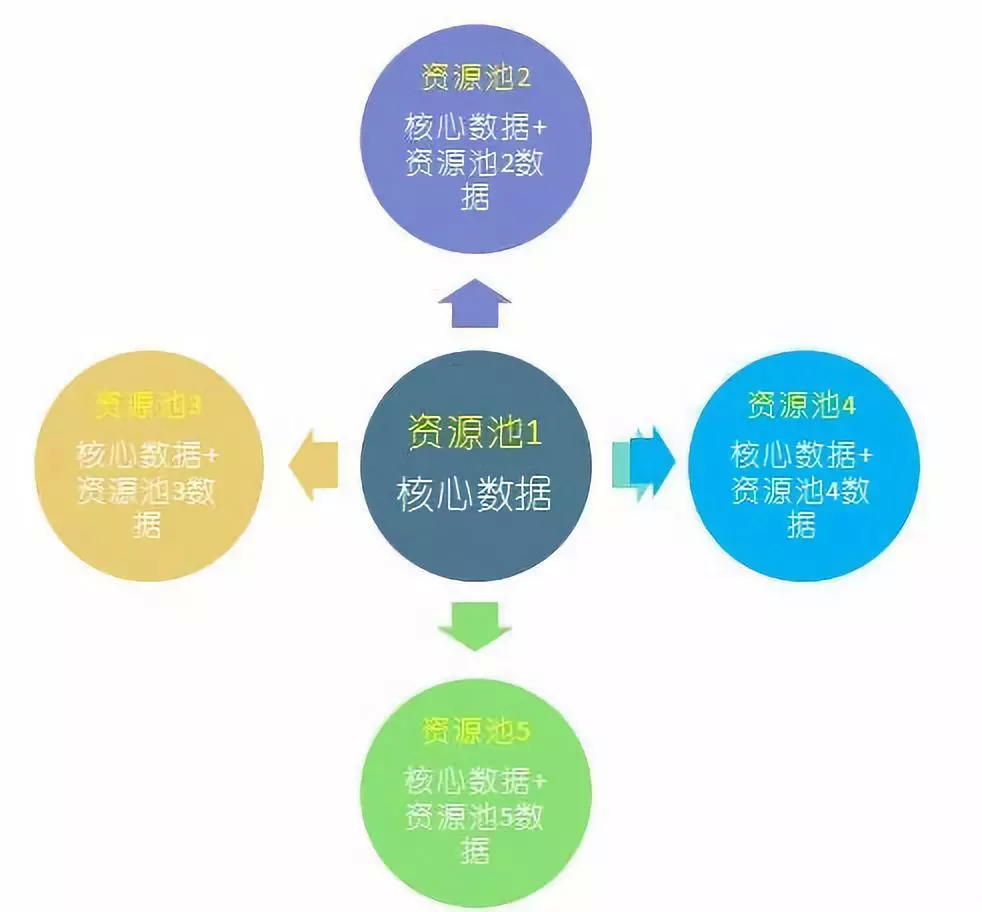
2、查询模块架构设计
查询模块的逻辑架可以设计为星型结构,MySQL 除作为核心数据主节点,将核心数据分发到各资源池之外,其他资源池的数据不互通。
3、数据一致性整治
为兼容数据表外键(外键关联的表数据变更不能被同步),保证数据一致性,对出现不一致的表数据,采用点对点 trigger 触发变更的方式,逐个建立关联触发器。

总结
通过以上方式,我们就初步搭建了一套生产环境数据同步和查询系统,可以满足日常运维中大多数故障排查和数据核对的场景,为运维人员提供一种安全、实时和有效的数据查询平台。
作者介绍:
刘书浩,“移动云”DBA,负责“移动云”业务系统的数据库运维、标准化等工作;擅长 MySQL 技术领域,熟悉 MySQL 复制结构、Cluster 架构及运维优化;具有自动化运维经验,负责“移动云”数据库管理平台的搭建。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论