在看到最近新推出的 GitHub Actions 后,我的第一个想法是创建一个简单的示例项目,在这个项目中,我们“部署”一个使用了这个新特性的机器学习模型。当然,这不是一个“真正的部署”,但是可用此模型在存储库中测试你的模型,而不需要任何额外的编码。
GitHub Actions 是一个用于构建、测试和部署的自动化工具。举个例子快速了解下它是什么:每次你创建一个 Pull Request(带有某个标签)时,都会触发新的应用程序构建,然后它可以向高级开发人员发送消息,让他们快速查看代码。
项目地址:
https://github.com/gaborvecsei/Machine-Learning-Inference-With-GitHub-Actions
我们将创建什么?
在存储库上创建一个自定义操作和自动化工作流,你可以在其中使用经过训练的模型,并在某个问题有了新评论时触发它。你还可以找到模型训练和推理代码。我想要超级硬核,所以我选择了 Iris 数据集和随机森林分类器。这个树集成模型经过训练,可以根据萼片和花瓣的长度和宽度来识别花朵。
这个模型的训练是在 Jupyter Notebook 上完成的。这些代码训练并序列化我们将用于预测的模型。当问题收到评论时,GitHub Actions 工作流将被触发。如果评论包含前缀/predict,那么我们就开始解析评论,然后我们做一个预测并构造一个回复。最后一步,该消息由机器人在相同的问题下发回给用户。为了把事情做得更好,整个自定义操作将在 Docker 容器中运行。
我们将找出工作流中的步骤,并为某些步骤创建单独的操作。一个工作流可以包含多个操作,但是在这个项目中,我们将使用单个操作。
创建一个操作
第一步,我们应该在名为 action.yaml 的根文件夹中创建操作。在这里,我们可以描述 inputs、outputs 和运行环境。
name: 'Prediction GitHub Action Test'description: 'This is a sample with which you can run inference on a ML model with a toy dataset'inputs: issue_comment_body: required: true description: 'This is the Github issue comment message' issue_number: required: true description: 'Number of the Github issue' issue_user: required: true description: 'This user send the comment'outputs: issue_comment_reply: description: 'Reply to the request'runs: using: 'docker' image: 'Dockerfile' args: - ${{ inputs.issue_comment_body }} - ${{ inputs.issue_number }} - ${{ inputs.issue_user }}
复制代码
从上到下,你可以看到定义好的 3 个输入和 1 个输出。最后,runs 键描述了我们的代码将要在其中运行的环境。这是一个 Docker 容器,其输入将作为参数传入。因此,容器的入口点应该按照定义的顺序接受这 3 个参数。
容器
如果我们仔细查看 Dockerfile,就可以看到我们的运行环境是如何构建的。首先,我们安装所有 Python 需要的东西。然后复制 entrypoint.sh 并使其可执行,这样它就可以在容器内运行了。最后,序列化的 sklearn 模型文件被复制到容器中,这样,我们就可以使用它来进行预测。(在真实的场景中,不应该将模型文件存储在存储库中。这只是为了可以快速演示。)
FROM python:3.6
# Install python requirementsCOPY requirements.txt /requirements.txtRUN pip install -r /requirements.txt
# Setup Docker entrypoint scriptCOPY entrypoint.sh /entrypoint.shRUN chmod +x /entrypoint.sh
# Copy the trained modelCOPY random_forest_model.pkl /random_forest_model.pkl
ENTRYPOINT ["/entrypoint.sh"]
复制代码
定义工作流
没有工作流就不能使用操作。它定义了你希望在管道中采取的不同步骤。
name: Demoon: [issue_comment]
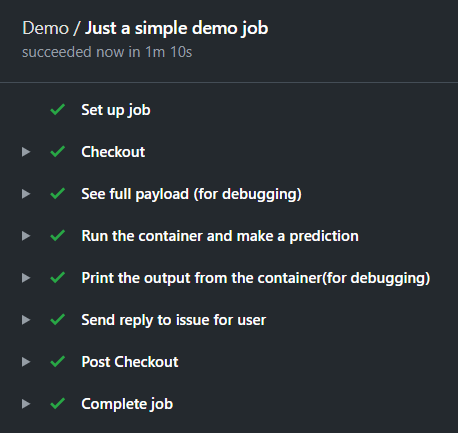
jobs: my_first_job: runs-on: ubuntu-latest name: Just a simple demo job steps: - name: Checkout uses: actions/checkout@master - name: See full payload (for debugging) env: PAYLOAD: ${{ toJSON(github.event) }} run: echo "FULL PAYLOAD:\n${PAYLOAD}\n" - name: Run the container and make a prediction if: startsWith(github.event.comment.body, '/predict') uses: ./ id: make_prediction with: issue_comment_body: ${{ github.event.comment.body }} issue_number: ${{ github.event.issue.number }} issue_user: ${{ github.event.comment.user.login }} - name: Print the output from the container(for debugging) run: echo "The reply message is ${{steps.make_prediction.outputs.issue_comment_reply}}" - name: Send reply to issue for user env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} run: bash issue_comment.sh "steps.makeprediction.outputs.issuecommentreply""{{ github.event.issue.number }}"
复制代码
首先,on: [issue_comment]定义了我希望在接收到某个问题的评论(任何人提出的任何问题)时触发这个流。然后,我通过 runs-on: ubuntu-latest 定义了运行的 VM 类型(它可以是自托管的,也可以是由 GitHub 提供的)。接下来是有趣的部分,我之前提到的步骤。
签出步骤:在这个步骤中,我们将移到存储库中所需的分支上(这也是一个 github 操作)。
查看有效负载:我在这里把它用于调试。在问题下收到评论后,它显示整个有效负载,包括这个容器、评论、问题编号、留下评论的用户等等。
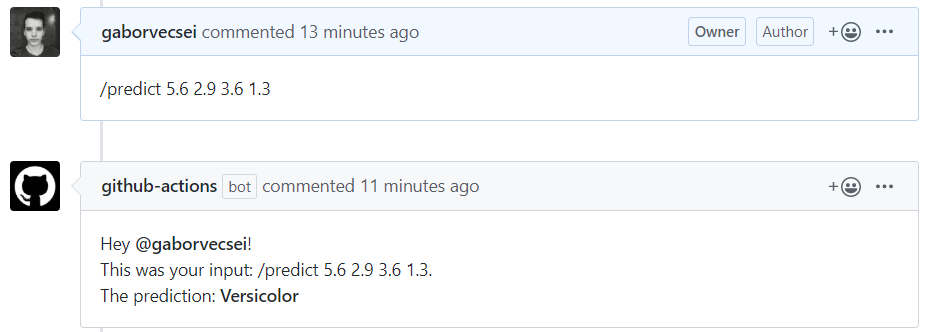
做出预测:这是我们的自定义动作。代码行 if: startsWith(github.event.comment.body,’/predict’)确保只有在出现有效的预测请求时才运行这个步骤(包含前缀/predict)。你可以看到,输入是在 with 关键字下定义的,而值是通过它们的键(如 github.event.comment.body)从负载中添加的。
打印应答:构造的应答被回显到日志。它使用前面的步骤中定义的输出:steps.make_prediction.output .issue_comment_reply。
发送应答:创建的应答中包含预测,将使用脚本 issue_comments .sh 作为应答发送。
每个步骤都在指定的运行器 ubuntu-latest 上运行,但是我们的操作在创建的容器中运行。此容器是在工作流被触发时构建的。(我本来可以缓存它,这样每次流运行时就可以使用以前构建的映像,但是我还是懒得将它添加到这个示例中)。
做出预测
有一件事我没有谈到:预测是如何做出的?你可以通过查看 main.py 脚本轻松地解决这个问题。
model = load_model("/random_forest_model.pkl")
try: sepal_length, sepal_width, petal_length, petal_width = parse_comment_input(args.issue_comment_body) predicted_class_id = make_prediction(model, sepal_length, sepal_width, petal_length, petal_width) predicted_class_name = map_class_id_to_name(predicted_class_id) reply_message = f"Hey @{args.issue_user}!<br>This was your input: {args.issue_comment_body}.<br>The prediction: **{predicted_class_name}**"except Exception as e: reply_message = f"Hey @{args.issue_user}! There was a problem with your input. The error: {e}"
print(f"::set-output name=issue_comment_reply::{reply_message}")
复制代码
看到上面的内容,可能你就会觉得这太简单了:输入、数据集、模型、模式存储、如何处理请求等等。例如,对于图像输入,你可以从一个 base64 字符串解码,然后通过存储在 GitLFS 中的深度学习模型运行它。那么,就动手实际操作下吧。
原文链接:
https://www.gaborvecsei.com/Machine-Learning-Inference-with-GitHub-Actions/














评论