

赛题分析
赛题要求一个无状态的计算节点和一个存储节点,并要求保证程序崩溃时的数据完整性,所以当计算节点写入时必须等待存储节点的 ack,而存储节点需快速确保数据写入到 page cache。
赛题说明 16 个线程,每个线程写入 4 百万条记录,按写入顺序读取及热点区间读取,所以数据按写入线程分离存储。此外 Key 大小固定 8B,value 大小固定 4KB,所以需要批量写入才能打满带宽,并且索引只需要保存位置序号就可以,减小了索引的大小。
整体架构
针对赛题的要求,可以把问题分解成三个模块来看,分别是计算节点,存储节点和网络通信,因此我们设计了如下图所示的总体结构。
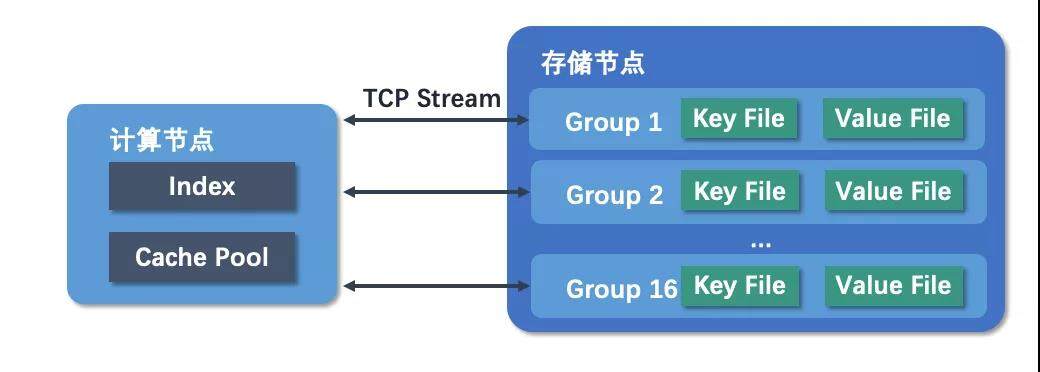
在存储节点上,数据分为 16 组存储,按照写入线程分组,保证同一线程的数据写入到同一分组,这样在读取阶段无论是按写入顺序读取还是热点区间读取都可以一次从一个分组中读取一整块 cache,降低网络开销,另外这样并发管理也比较简单,因为一个线程只会对应到一个文件,所以读写的时候是不需要对分组加锁的。具体到到每个分组内部,key 和 value 是分离存储的,因为 key 和 value 都是定长的,kv 分离以后恢复索引时只需要读取 key 文件就够了。最后存储节点会保证一旦写入成功数据就不会再丢失,也就是可以容忍 kill -9 退出。
我们把索引放在计算节点,并且使用 TCP 进行节点间通信。由于并发数目不高,所以计算节点初始化时创建 16 条 tcp 连接,每个前台线程对应一条连接,在存储节点为每个 tcp 连接创建一个新线程。数据在写入时首先由计算节点发送写请求到存储节点,存储节点收到请求并确认数据成功写入不会丢失后,会把存储的位置回复给计算节点,然后计算节点把位置插入内存索引后返回。读取时计算节点首先根据内存索引判断数据在不在 cache pool 里,如果不在就去向存储节点读取一块新的 cache,然后从 cache 中读数据。
存储节点
之前我们也提到存储节点按写入线程分组,每个分组里包含四类文件,value data 文件保存 value,key data 文件保存 key,两者各有一个 mmap buffer 文件,用来将写入 batch 到一起再刷盘。然后有一个全局的 mmap meta file,记录各个分组当前的数据长度,也就是各分组分别有多少个 kv 对,主要用于数据恢复和重建索引。
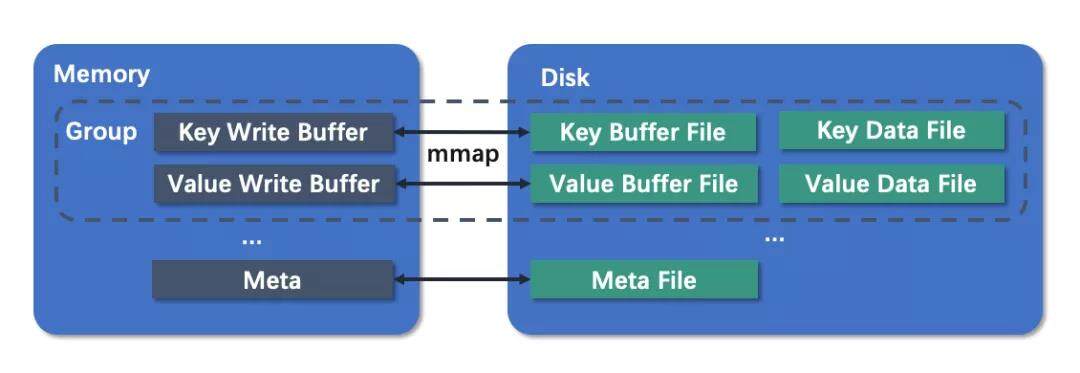
数据写入时直接将 key 和 value 写入对应分组的 mmap buffer,两者都写入成功后更新 meta file。只有当 mmap buffer 写满了以后才会 flush 到磁盘中,并且 flush 操作都是用 directIO 进行的。采用这种设计使得写入均是内存操作,将数据写入到 mmap 管理的 page cache 中即可返回,并且我们对 mmap 使用了 mmap_lock 标记使其一直锁定在内存中,只有当程序退出时才会刷盘。每次向 data 文件刷盘都是以一个 buffer 为单位,这样可以最大化利用 nvme 磁盘带宽,采用 directIO 的方式刷盘可以跳过 page cache,一方面减少了一次内存复制,另一方面降低了阶段切换时清空 page cache 的时间。而 mmap 的机制保障了即使进程意外退出,操作系统也会让 mmap buffer 中的数据安全落盘,不会引起数据丢失。
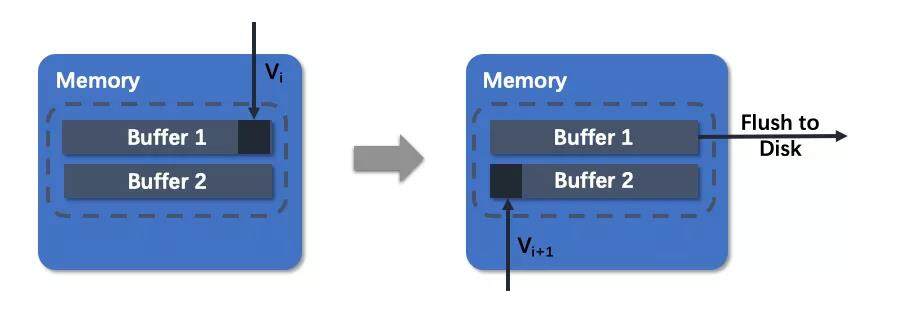
我们实际为每个 key 和 data 文件维护了多个 mmap buffer,当一个 buffer 写满时转入后台 flush,接下来的写入会写进另一个 buffer。这是因为写入操作的开销是由网络传输开销和磁盘 IO 开销两部分组成的,单个 buffer 的情况下两者完全串行执行,在发生刷盘时写入操作需要消耗网络传输加上磁盘 IO 的时间。采用多个 buffer 以后相当于将磁盘 IO 与网络开销并行化了,产生的阻塞会减少很多。
对于数据读取操作,读请求会将 offset 对齐到 cache 长度,也就是 10MB,然后存储节点直接以 directIO 方式从对齐后的 offset 处读出这一块数据返回即可。
当存储节点意外关闭时,因为我们已经确保了所有数据都能安全落盘,唯一需要恢复的就是 mmap buffer 文件当前的写入位置,所以只需要从 meta file 中读取个分组的长度,对 buffer 长度取余便可以计算出各 buffer 的当前写入位置了。
计算节点
计算节点中主要包含了索引和 cache 两部分。
索引部分,索引存储在 hash 表中,每个 entry 的格式为(key, 分组编号+分组内偏移量)。因为 key 和 value 都是大小固定的,因此偏移量只需要保存它是分组内的第几个 kv 对,所以只需要 4 字节。因此每个 entry 的空间占用为 key 8 字节加分组编号 4 字节加偏移量 4 字节,总共 16 字节,那么 6400 万个 entry 一共需要大约 1G 左右空间,因此可以完全保存在内存里。
我们实现了一个原子的 hash 表。hash 表底层是一个大小为 8000 万左右的数组,以线性探测法处理 hash 冲突。说 hash 表的每一个 entry 由两个 64 位无符号整数组成,分别代表 key 与索引,并初始化为 0。因为 key 本身可能是 0,所以我们让分组编号从 1 开始,然后对索引部分的原子变量做 cas 操作来实现原子插入。代码如下:

因为计算节点本身是无状态的,所以重启时需要恢复索引。我们把索引恢复的时机放在第一次 get 操作的时候,这样可以避免写入阶段计算节点请求恢复索引。索引恢复由 16 个线程并行执行,每一个线程向存储节点请求一整个 key 文件,因为 key 在 key 文件中的位置与 value 在 value 文件中的位置是一样的,所以遍历 key 文件就可以重建索引了。
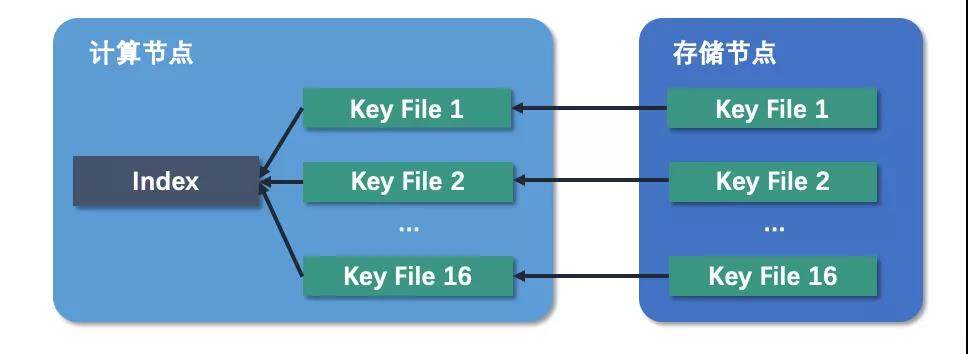
如果每次 get 都去存储节点读取,那么网络延迟开销太大,无法打满带宽。所以我们每次向存储节点请求数据时都读取一整块数据保存在内存 cache 里,大小为 10MB。由于我们不确定是不是完全按照 10MB 对齐的,因此我们为每个分组准备了两个 cache,这样当 cache miss 时,可以保证前一块 cache 的数据一定已经被读完了,可以被新的 cache 置换掉。
此外我们还实现了 cache 预取机制。由于赛题要求顺序读取及热点区间读取,热点区间读取是按照数据的写入顺序以 10MB 数据粒度分区,分区逆序推进,在每个 10MB 数据分区内随机读取,所以当向存储节点请求一个新 cache 完成时,另一个线程会根据当前两个 cache 的 offset 之差向存储节点预取下一块 cache。在顺序读取阶段差为整数,因此会顺序预取,在热点区间读取阶段差为负数,因此会逆序预取。

总结
我们的最好成绩是 786 秒,其中写用了 505 秒,顺序读取用了 134 秒,热点读取用了 147 秒,最终排名第 5 名。此外各阶段分别跑出的最佳成绩为 505/132/142 秒,在热点读阶段实际消耗在读取上的时间为 133 秒,但是恢复索引使用了 9 秒,这里还有很大的改进空间。考虑到评测系统的带宽大约 15Gbps,我们的读取性能已经基本跑满网络带宽了。
第一次参加这种类型的比赛,我们学习和积累了很多经验,很感谢华为云数据库提供的这次机会,希望来年还有机会参加,取得更好的成绩。
本文转载自 HW 云数据库公众号。
原文链接:
https://mp.weixin.qq.com/s/6SdSye7Bzkg-kK5CfPZ4vA

中国开源发展研究分析 2022
本次报告为开发者,技术管理者,开源社区运营、市场,开源办公室工作人员带来信息上的增量以及对开源趋势、...










评论