

点击流分析工具可以很好地处理数据,有些工具甚至具有令人印象深刻的 BI 界面。但是,孤立地分析点击流数据存在很多限制。例如,客户对您网站上的产品或服务感兴趣,却在您的实体店购买。点击流分析师会问:“他们浏览产品之后发生了什么?”,而商业分析师会问:“他们购买之前发生了什么?”
点击流数据可以增强您的其他数据源,这并不足为奇。如果结合购买数据使用,它有助于您确定要放弃购买的产品或优化营销支出。同样,它还可以帮助您分析线上和线下行为,甚至是客户在注册帐户之前的行为。但是,一旦点击流数据馈送的好处显现,您必须快速适应新的请求。
这篇文章介绍了我们在 Equinox Fitness Clubs 如何将数据从 Amazon Redshift 迁移到 Amazon S3,以便对点击流数据使用后期绑定视图策略。我们将在这篇文章中广泛讨论 Apache Spark、Apache Parquet、数据湖、hive 分区和外部表等有趣的内容!
当我们开始将点击流数据从其自有工具传送到我们的 Amazon Redshift 数据仓库时,速度是主要考虑事项。我们的初始用例是将 Salesforce 数据与 Adobe Analytics 数据合并在一起,以便深入了解我们的潜在客户开发流程。Adobe Analytics 可以告诉我们潜在客户来自哪些渠道和宣传活动、访问期间浏览了哪些网页以及是否在我们的网站上提交了潜在客户表单。Salesforce 可以告诉我们潜在客户是否符合条件、是否咨询过顾问以及最终是否注册会员。将这两个数据集合并在一起有助于我们更好地理解和优化我们的营销策略。
首先,我们来了解将 Salesforce 和 Adobe Analytics 数据集中到 Amazon Redshift 所涉及的步骤。但即使在 Redshift 中合并在一起,也需要一个通用标识符才能进行交互。第一步是在我们的网站上提交潜在客户表单时,生成 GUID 并将相同的 GUID 发送到 Salesforce 和 Adobe Analytics。

接下来,我们要将 Salesforce 数据传送到 Redshift。幸运的是,这些馈送已存在,因此我们可以在馈送中添加新的 GUID 属性并在 Redshift 中对其进行描述。
同样,我们必须生成从 Adobe Analytics 到 Amazon Redshift 的数据馈送。Adobe Analytics 提供了 Amazon S3 作为我们数据的目标选项,因此我们将数据传送给 S3,然后创建作业将其发送到 Redshift。此作业涉及到获取每日 Adobe Analytics 馈送,并附有一个含有数百列和数十万行的数据文件、一系列查找文件(如数据标题)和一个描述已发送文件的清单文件 – 然后以其原始状态全部传送至 Amazon S3。接着,我们使用 Amazon EMR 和 Apache Spark 将数据馈送文件处理为单个 CSV 文件,然后将其保存到 S3,以便我们执行 COPY 命令将数据发送到 Amazon Redshift。
此作业持续了几周时间,在我们开始频繁使用数据之前运行良好。虽然作业效率很高,但新列数据发生了日期回溯的情况(模式演变)。因此我们确定需要更大的灵活性,这是由数据的性质决定的。
数据湖补救
当我们决定重构作业时,我们做了两项准备工作。首先,我们逐渐开始采用更多的数据湖策略。其次,近期发布Redshift Spectrum。它使我们能在数据湖中查询点击流数据的平面文件,而无需运行 COPY 命令并将其存储在 Redshift 中。此外,我们可以更有效地将点击流数据合并到存储在 Redshift 中的其他数据源。
我们想利用自描述数据,该数据将数据模式与数据本身相结合。将数据转换为自描述数据有助于我们管理广泛的点击流数据集,并防止模式演变相关的挑战。我们可以将所需的每一列都放入数据湖文件中,然后只使用查询中重要的列以加快处理。为实现这种灵活性,我们使用的是 Apache Parquet 文件格式,因为其列式存储技术,该格式不仅具有自描述性,而且速度很快。我们在 Amazon EMR 上使用 Apache Spark 将 CSV 转换为 Parquet 格式,并对数据分区以获区扫描性能,如以下代码所示。
借助 AWS Glue Data Catalog,我们可以在 Amazon Redshift 和其他查询工具(如 Amazon Athena 和 Apache Spark)中查询可用的点击流数据。这是通过将 Parquet 文件映射到关系模式来实现的。AWS Glue 允许在几秒钟内查询其他数据。这是因为模式会实时发生更改。这意味着您可以同时完成列删除/添加、列索引重新排序和列类型更改。然后,就可以在保存模式后立即查询数据。此外,Parquet 格式可防止数据形状发生变化时出现故障,或者放弃和删除数据集中的某些列。
我们使用以下查询为 Adobe Analytics 网站数据创建了第一个 AWS Glue 表。我们在 SQL Workbench 的 Amazon Redshift 中运行了此查询。
运行此查询后,我们通过 AWS Glue 界面根据请求对 schema 添加了其他列。我们还使用分区来加快查询和降低成本。
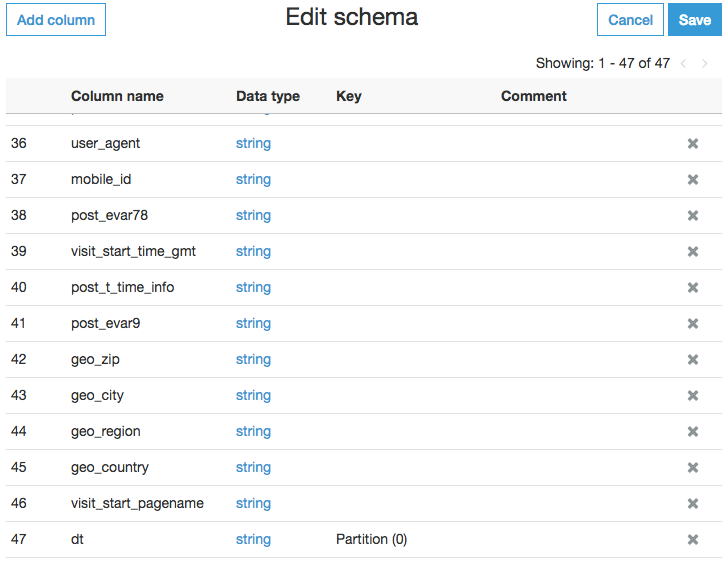
此时,我们的数据库中有个新的 schema 文件夹。它包含可以查询的外部表,但我们希望更进一步。我们需要增加一些数据转换,例如:
将 ID 重命名为字符串
连接值
操作字符串,不包括我们从 AWS 发送的用来测试网站的 bot 流量
更改列名称以方便使用。
为此,我们创建了如下所示的外部表视图:
现在,我们可以从 Amazon Redshift 执行查询,将我们的结构化 Salesforce 数据与半结构化动态 Adobe Analytics 数据相结合。通过这些更改,我们的数据变得极其灵活、对存储大小非常友好、查询特别高效。从那时起,我们开始将 Redshift Spectrum 用于很多用例,包括数据质量检查、机器数据、历史数据存档,使我们的数据分析师和科学家能够更轻松地混合和加载数据。
小结
通过将 Amazon S3 数据湖与 Amazon Redshift 合并,我们能为点击流数据构建高效灵活的分析平台。从而无需始终将点击流数据加载到数据仓库中,并且使平台适应传入数据中 schema 更改。请阅读 Redshift Spectrum 入门文档,还可以在下面观看我们在 AWS Chicago Summit 2018 上的演讲。
相关文章:
如果觉得这篇文章有用,请务必阅读从数据湖到数据仓库:利用 Amazon Redshift Spectrum 增强 Customer 360 和 Narrativ 通过 Amazon Redshift 帮助创建者将其数字内容货币化。
作者介绍:
Ryan Kelly 是 Equinox 的数据架构师,帮助草拟和实施数据计划框架。他还负责点击流跟踪,帮助团队深入了解他们的数字计划。Ryan 热衷于让人们更方便地访问和提取他们的数据,以获取商业智能、执行分析和丰富产品/服务。他还喜欢探索和审查新技术,了解是如何改善他们在 Equinox 的工作。
本文转载自 AWS 技术博客。
原文链接:


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论