

一、前言
互联网软件本身具有快速迭代、持续交付等特点,加上数据库的表结构(DDL)发布无法做到灰度发布,且回退困难、试错成本高,一个稳定可靠的数据库发布系统对于互联网公司显得尤其重要。本文将介绍携程 MySQL 数据库发布系统从无到有,版本不断迭代的演进之路,希望对读者有所参考和帮助。
我们先后设计了三个版本,最新的版本具有以下功能和特点:
发布期间只有一次表锁,锁定时间极短,锁定时间不受表容量影响;
Master-Slave 复制延迟可控,这点对有读写分离架构且数据实时性要求高的业务尤其重要;
自动避开业务高峰,自动识别热表,确保发布期间业务基本无影响;
将数据库规范加入发布前校验,对不符合规范的发布进行拦截;
介绍整个系统之前,首先对携程数据库环境和发布流程做一个简单的介绍。系统的数据库环境主要分成 Dev、测试环境(含三个子环境,功能性测试(FAT)/压力测试(LPT)/UAT 三个环境)、Product:
1)数据库表设计在 Dev 环境完成,期间包含数据库规范检测
2)然后发布到其它测试环境(FAT→LPT→UAT)
3)测试环境都验证通过后,最后发布到生产环境
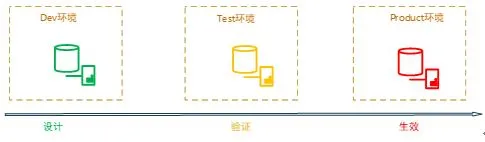
表发布流程图
二、初期(1.0 时代)
携程成立以来一直使用 SQL Server 数据库,2014 年左右开始使用 MySQL 数据库,为后面转型 MySQL 做准备。这时期接入 MySQL 的业务量很小,数据量不大,都是非核心业务,所以整个发布过程可以概括为“简单粗暴”:
1)开发人员通过直连 DEV 环境数据库,直接对数据库表进行修改
2)DBA 通过自动化工具捕捉到表的变化,将变更同步到测试环境
3)开发测试完后,将变化同步到生产环境
这个阶段只是简单把表的变更传递到其他环境,对发布期间业务和性能方面的影响没有考虑太多。
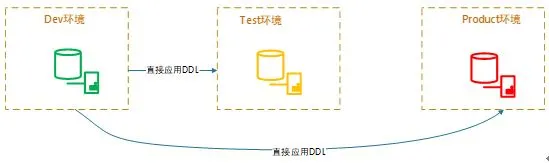
1.0 版本发布流程
三、转型期(2.0 时代)
随着业务接入 MySQL 不断增加,MySQL 数据库越来越多,到 2016 年下半年为止,MySQL 数据库数量已经有 800+,很多核心业务也转到 MySQL,包含很多读写分离架构。此时原生的 DDL 发布已经无法满足业务需求,这时引入了业界流行的 pt-online-schema-change(pt-osc)。
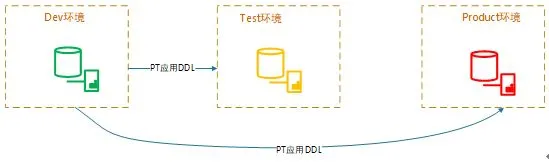
2.0 版本发布流程
pt-osc 是 percona 开发的一款比较成熟的产品,业界使用也较多。其采用触发器的方式将所有的增量 DML 应用到了影子表,这种实现方式会加大对语句的开销,并发过高时甚至会影响数据库正常提供服务,因此往往会出现发布一半最后还是不得不终止发布的现象,线上遇到核心的表或者大表往往需要晚上留守来进行发布,这极大的提高了 DBA 的运维负担。
四、引入 gh-ost(3.0 时代)
为了进一步提升发布稳定性,我们在 2017 年调研了当时刚开源不久的 gh-ost,由于产品非常新,因此做了大量的调研和测试工作,也发现提交了多个高优先级 Bug(包括 GBK 字符集支持、bad connection 以及 column case-sensitive issue 导致数据丢失等),都已得到作者的修复。
那么 gh-ost 对比 pt-osc 具体有哪些优势呢?下面先简单介绍下它的两个最核心的特性。
4.1 Triggerless
在 gh-ost 出现之前第三方 MySQL DDL 工具均采用触发器的方式进行实现,包括前面 percona 的 pt-osc,Facebook 的 OSC 等等。而 gh-ost 采用的机制和他们完全不同:它通过 MySQL binlog 来同步数据,gh-ost 本身注册为一个 fake slave,可以从集群中的 master 或者 slave 上拉取 binlog,并实时解析,将变更表的所有 DML 操作都重新 apply 到影子表上面。因此对于发布期间变更表上发生的 DML 操作,可以完全避免由于触发器而产生的性能开销,以及锁的争抢。
除此之外,一般我们选择目标发布机器通常会选择集群中 slave 节点,而 slave 一般不会承载业务,这样 binlog 解析的开销也不会落在提供业务的 master 上面,而仅仅是一次异步的 DML 语句重放。
4.2 Dynamically controllable
另一个最重要的特性是动态调控,这是此前其他第三方开源工具所不具备的。
之前通过 pt-osc 发布时,命令执行后参数就没法修改,除非停止重来。假设发布进行到 90%,突然由于其他各种原因导致服务器负载上升,为不影响业务,只能选择将发布停掉,等性能恢复再重来。
通过 pt-osc 发布的表都是很大的表,耗时较长,所以遇到这类场景很尴尬。因此发布中参数如果可动态调控将变得非常重要。gh-ost 另外实现了一个 socket server,我们可以在发布过程中,通过 socket 和发布进程进行实时交互,它可以支持实时的暂停,恢复,以及很多参数的动态调整,来适应外界变化。
4.3 gh-ost 如何工作?
在了解完其重要特性后,简单介绍下其实现原理。
其原理很好理解,首先建两张表,一张_gho 的影子表,gh-ost 会将原表数据以及增量数据都应用到这个表,最后会将这个表和原表做次表名切换,另一张是_ghc 表,这个表是存放 changelog 的数据,包括信号标记,心跳等。
其次,gh-ost 会开两个 goroutine,一个用于拷贝原表数据,一个用于 apply 增量的 binlog 到_gho 表,并且两个 goroutine 的并行在跑的,也就是不用关心数据是先拷贝过去还是先 apply binlog 过去。
因为这里会对 insert 语句做调整,首先我们拷贝的 insert into 会改写成 insert ignore into,而 binlog 内 insert into 会改写成 replace into,这样可以很好的支持两个 goroutine 的并行。但这样的调整能适用所有的 DDL 吗?答案是否定的,大家可以思考下,下面案例部分会给出详细解释。
最后,当原表数据全部拷贝完成后,gh-ost 会进入到表交换阶段,采用更加安全的原子交换。
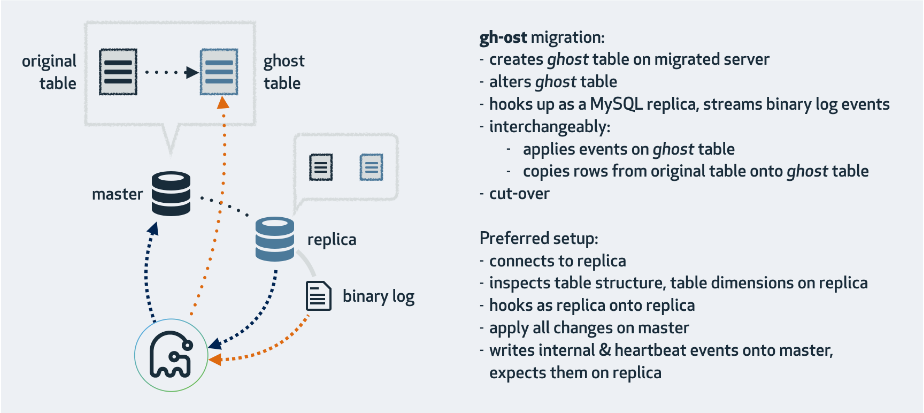
Gh-ost 架构图
五、如何做到安全发布?
为了确保每次发布符合数据库规范,确保发布可以顺利完成,发布前我们做了很多检查工作,发布过程中会有线程实时侦听发布状态。通过 producer,consumer,listener 如下三个组件来协同完成发布的顺利进行。
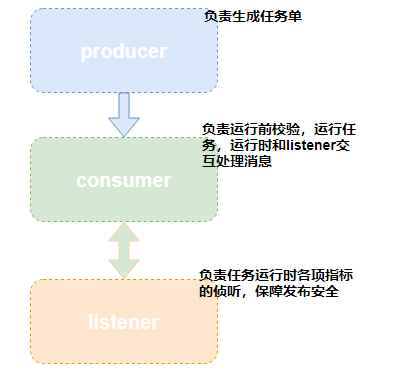
任务运行架构图
5.1 运行前——是否能做发布?
我们消费线程(consumer)会在发布前做满足发布的前置校验,选择合适的目标主机进行发布。
1)MySQL 环境变量的校验:检查当前实例变量配置是否满足发布要求。
2)冲突表校验:检查集群中是否存在已发布相冲突的表,存在的话自动进行清理。
3)冲突标记文件校验:检查发布机器上是否存在冲突的标记文件,存在的话自动进行清理。
4)磁盘容量校验:预估集群所有节点的磁盘空间是否足够
5)任务并行校验:检查集群是否存在其他发布,多实例会检查所有实例所属集群是否存在发布,为避免并行发布导致的性能影响,以及磁盘容量难以预估,我们会限制单个集群只能有串行发布。
6)DRC 成员状态校验:对于已接入 DRC 的 DB,会在发布前先初始化所有成员状态,并随机选择一个成员成为 leader,仅当所有成员所属集群均已满足前置校验,才会进入真正发布阶段。
注:DRC(Data Replicate Center),想了解更多 DRC 相关的技术戳这里。这里主要负责支持多数据中心同时发起以及结束发布流程。
5.2 运行时——进展是否正常?
整个发布过程采用的是生产消费模型,当每个消费线程运行任务时,同时会生成一个其对应的监听线程(listener),用于监听该任务的运行状态。
1)磁盘容量监听:当低于某阈值时将终止发布,并会清理发布产生的残留表来释放空间。
2)服务器性能监听:当服务器负载过高,将会自动触发 throttle,等性能恢复再重新解除 throttle。
3)副本延迟监听:延迟阈值默认初始 1.5s,后续在一个阈值上限内会动态增减,避免延迟一直波动时影响发布效率,但最终交换前会回置到默认 1.5s。
4)时间监听:当前时间若处于业务高峰期,会通过自动加大 nice-ratio 的值来进行“限流”,等业务低峰期后再做置回。
5)DRC 成员状态监听:对于接入 DRC 的 DB,会侦听 partner 的运行状态,等所有成员均已进入 postponing 状态后,再由 drc 选举出来的 leader 统一触发表名交换。
6)集群拓扑监听:线上我们往往会碰到正在发布的 DB 进行了变更维护,包括主从切换,DB 拆分到其他集群上等等。这时我们发现 gh-ost 会 hang 在那,也不会报错,往往会等到提交发布的人员反馈才会发现,因此我们这里加了对集群拓扑的监听,来及时发现拓扑的变更并终止发布。
六、碰到了哪些问题,如何解决?
目前 gh-ost 接入发布系统已接近两年,运行非常稳定。但慢慢的我们会发现原生 gh-ost 没办法满足我们所有需求,所以做了一些二次开发。
下面通过几个典型案例来简要介绍下。
案例 1、发布后自增列值保留
默认 gh-ost 发布时新表并没有保留原表自增值,部分业务是依赖自增列的值,这种场景会出现较大的问题。
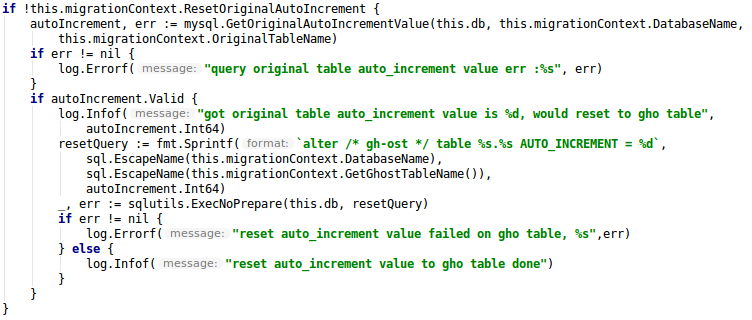
要解决这个问题其实不难,只需要在建_gho 表后设置一把 AUTO_INCREMENT 值即可。我们添加了一个- reset-original-auto-increment 参数开关,默认 false,即保留原始自增值。
代码示例如下,先查找原表的有效自增值,并应用给新的_gho 表即可。
案例 2、含唯一键表发布
我们知道唯一键发布有两大前提,首先,表中已有的存量数据必须满足新增的唯一键约束;其次,发布过程中出现的 DML 增量数据也需保证满足新增的唯一键约束。
默认 gh-ost 对表添加唯一键是无法保证数据的完整性的。为什么呢?前面我们简单提过 gh-ost 发布会做语句转换,并且 rowCopy 中 insert into 会转为 insert ignore into,而 binlogApply 中 insert into 会转为 replace into。当表结构变更中包含新增唯一键的话,这种转换就显然不够了,它会将冲突数据全部自然抹掉,而这显然是不合理的,是很严重的 data integrity 问题。
工具的预期应该是出现数据冲突即退出,说明这个发布并没有发布条件。而官方并没有做唯一索引发布的特殊支持,那我们是否可以实现这一部分逻辑?问题的关键在于我们要对原主键继续支持 insert ignore into/ replace into 的逻辑保证数据一致且不失败,另外新增唯一键部分又不能通过这种逻辑处理,保证冲突数据要及时发现。
后面通过分析我们想了一种方案,首先通过如下一条正则解析命令是否包含新增唯一键。

其次对写入逻辑进行如下改写:
1)原数据拷贝(rowCopy)从 insert ignore into 调整为 insert into … andnot exists PK 的方式,如下示例。
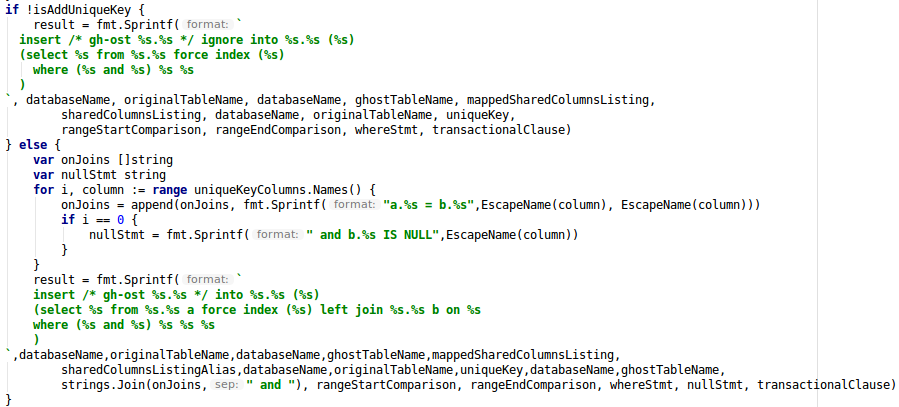
2)DML 增量应用(binlogApply)从 replace into 调整为 delete from + insert into 的方式,如下示例。

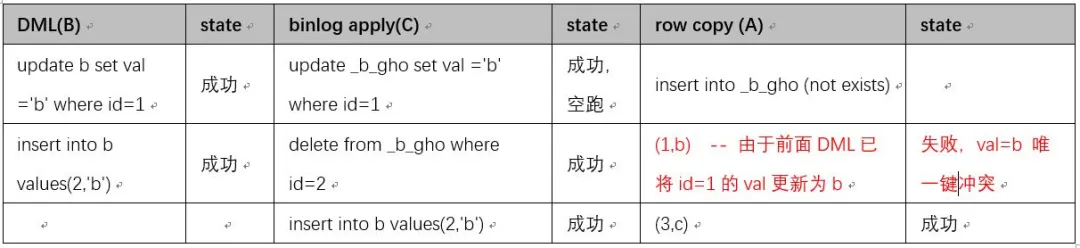
下面对原数据拷贝(A),原表 DML(B),Binlog 应用到新表© 三个过程先后顺序不固定时做下推演。首先 C 肯定在 B 后面,因此可能的顺序是 ABC,BCA,BAC 三种可能情况。
原表 b, 2 个列,col1 PK,col2 计划新增 Uniquekey,原表数据是(1,a), (3,c)。
ABC:先完成拷贝,再对原表 DML,最后应用 binlog
BCA:先原表 DML,再应用 binlog,最后拷贝
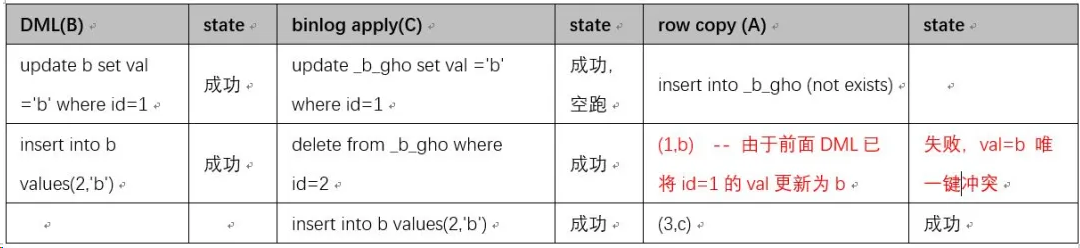
BAC:先原表 DML,再拷贝,最后应用 binlog
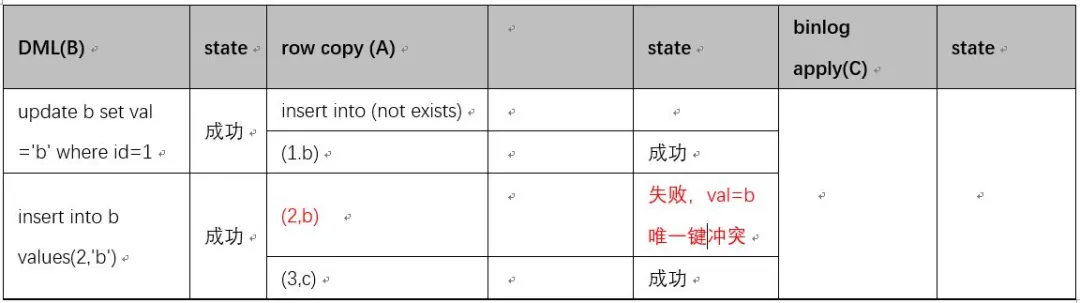
经过过程推演,我们发现这个方案可以解决新增唯一键时可能存在的问题。
案例 3、活学活用,大表发布+数据清理
我们经常会碰到一些大表的发布,发布系统一般会对超大表做拦截,建议清理些无效数据。那这里分为两个过程,即先清理无效数据,再进行发布。那我们是否可以将这两个过程合并发布呢?答案是可行的,而且可以极大的提升发布效率。
逻辑可以很容易理解,见下图,即拷贝你所需要的数据,而增量部分不做变化。我们可以加个参数-where-reserve-clause,代表你需要的数据。那这里有一个问题,拷贝范围是先去根据-where-reserve-clause 去限定,还是实际 insert 的时候去限定?有何区别?
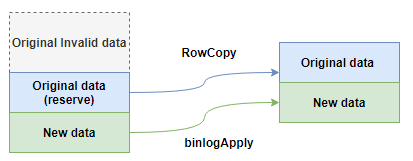
发布+清理逻辑图
区别在于如果根据-where-reserve-clause 去限定范围的性能很差,往往查主键范围需要花很久,如果主键范围又很分散,那选择先查这个范围是比较差的。而如果实际 insert 的时候去限定实际需写入的数据的话,则只是在每个 chunk 写入时附加上这个条件,可能一个 chunk 没有一条数据符合条件,那即产生一次空跑,也没有任何影响。
但如果用户明确知道要保留的主键范围,那先去限定范围可以避免大量的空跑。因此添加了-force-query-migration-range-values-on-master 来确定使用哪种方式,而具体选择需具体案例具体分析。
除此之外,我们知道数据清理表空间并不会自动瘦身,往往需要配合 optimize table 来进行表收缩。而添加的这个功能本身既支持数据清理,又支持表结构变更,而支持了表结构变更也就支持了表收缩。因此对-alter 做了下扩展,允许 noop,来支持不变更结构仅数据清理或者表收缩等场景。
下面有个线上数据清理的测试数据对比(表大小在 300GB 左右,需清理 80%左右的数据):
通过对比,我们可以看到效率提升了 10 倍以上,其中还不算 optimize 的开销。
七、结语
以上是携程数据库发布系统的整个演进过程,希望对读者有所参考和帮助,新的 3.0MySQL 数据库发布系统从 2018 年开始研发上线并持续改进,功能上已经较为完善,适应了业务快速迭代的要求,规避了发布可能造成的业务故障,覆盖了携程绝大多数类型的 DDL。
面向未来,我们的发布系统会持续改进:更加友好的交互、更加智能的 throttle,我们已经在路上。
作者介绍:
天浩,携程数据库专家,专注数据库自动化运维研发工作。
晓军,携程数据库专家,主要负责运维及分布式数据库研究。
本文转载自公众号携程技术(ID:ctriptech)。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论