Elassandra 是一个基于 Apache Cassandra 的 Elasticsearch 实现,有效结合了两者的优势,弥补了 Elasticsearch 的一些使用限制(单点故障、在线升级等)。结合Fluent-Bit以及 Kibana,Elassandra 为 kubernetes 集群日志分析提供了一个高效独特的方案。
Elasticsearch 升级
Elasticsearch 采用主从分片架构设计:主节点管理映射修改;只有主分片支持写操作,副本分片只能进行读操作;当主分片故障时,主节点可以把副本分片升级为主分片。Cassandra 的引入增强了 Elassandra 的可用性,弱化了主节点的单点控制作用,并且实现了多点写操作。所有的节点都可以搜索请求,请求映射更新,并根据 Cassandra 的复制因子进行写操作。
因此,Elassandra 也可以更容易地通过 kubernetes 来管理,而且可以实现无宕机维护(滚动重启升级)。除此以外,对集群进行水平扩容或收缩也很容易了,因为 Elassandra 完全兼容现有的 Elasticsearch 索引,我们只需要移动那些已经被重建的索引(重新索引)。Elassandra 同时原生支持 kubernetes 集群的跨数据中心副本服务。
EFK 部署
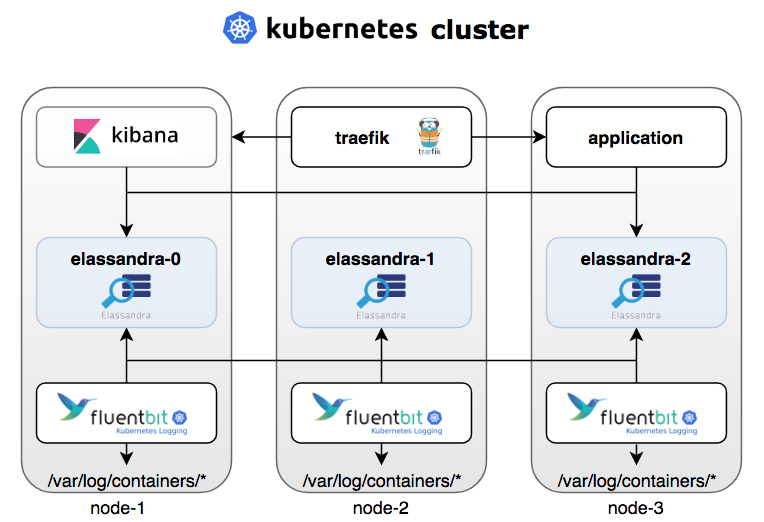
为了更好地让 Elassandra 在 Kubernetes 中发挥作用,我们同样搭配了一个 EFK 数据栈:在日志处理和转发上,我们使用了Fluent-Bit,一个支持 Elasticsearch 后端的轻量日志处理引擎(当然也可以使用传统的Fluentd或Filebeat);可视化面板方面则使用了普遍的 Kibana。
基于 EFK 的 Kubernetes 集群结构图
为使部署方便高效,我们使用了 Helm 的 chart 安装包的方式,安装源为Strapdata的Helm仓库。
首先,我们建立了一个三节点集群,硬件上使用了 SSD 存储,而软件则使用了 Azure 的 Kubenetes 服务。集群搭建完成后,我们使用 helm 把 Elassandra 安装到所有节点中,命令如下:
helm install --name "elassandra" --namespace default \ --set image.repo=strapdata/elassandra \ --set image.tag=6.2.3.10 \ --set config.cluster_size=3 \ --set persistence.storageClass=managed-premium \ strapdata/elassandra
复制代码
安装完成后,我们可以发现 Elasticsearch 服务和 Cassandra 服务已经暴露在 kubernetes 中了。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/cassandra ClusterIP 10.0.193.114 <none> 9042/TCP,9160/TCP 14h
service/elassandra ClusterIP None <none> 7199/TCP,7000/TCP,7001/TCP,9300/TCP,9042/TCP,9160/TCP,9200/TCP 14h
service/elasticsearch ClusterIP 10.0.75.121 <none>
复制代码
其次,部署 Kibana。为保持兼容性,我们需要一个同 Elasticsearch 相同版本的安装包,例如本文都使用了版本 6.2.3。
helm install --namespace default --name my-kibana \ --set image.tag=6.2.3 \ --set service.externalPort=5601 \ stable/kibana
复制代码
如果希望把 Kibana 服务暴露在公共 IP 上,我们在这里可以安装一个kubernetes的入口代理—Traefik:
helm install --name traefik --namespace kube-system --set dashboard.domain=traefik-dashboard.aks1.strapdata.com stable/traefik
helm install --namespace $NAMESAPCE --name my-kibana --set image.tag=6.2.3 \ --set service.externalPort=5601 \ --set env.ELASTICSEARCH_URL="http://elassandra-elasticsearch:9200" \ --set ingress.enabled=true,ingress.hosts[0]="kibana.${1:-aks1.strapdata.com}",ingress.annotations."kubernetes\.io/ingress\.class"="traefik" \ stable/kibana
复制代码
最后,我们需要使用一个特定的 Elasticsearch 索引模板来安装 Fluent-Bit,该模板加载了 Elassandra 相关的设置,从而可以优化日志存储和搜索的性能。
helm install --name my-fluentbit --set trackOffsets="true" \--set backend.type="es",backend.es.host="elassandra-elasticsearch.default.svc.cluster.local",backend.es.time_key="es_time",backend.es.pipeline="fluentbit" \--set parsers.enabled=true,parsers.json[0].name="docker",parsers.json[0].timeKey="time",parsers.json[0].timeFormat="%Y-%m-%dT%H:%M:%S.%L",parsers.json[0].timeKeep="Off" strapdata/fluent-bit
复制代码
到这里,我们就完成了对 Elassandra、Fluent-Bit 和 Kibana 的部署,Fluent-Bit 开始源源不断地把 pod 中的日志输送到 Elassandra 集群。
接下来,我们再看一些针对 Elassandra 的优化设置:
Elassandra 索引优化
Helm中Fluent-Bit的chart包为 Elassandra 提供了一个 Elasticsearch 索引模板,模板设置如下:
"settings": { "index": { "replication": "DC1:2", "table_options": "compaction = {'compaction_window_size': '4', 'compaction_window_unit': 'HOURS', 'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy'}", "mapping": { "total_fields": { "limit": "10000" } }, "refresh_interval": "15s", "drop_on_delete_index": true, "index_insert_only": true, "index_static_columns": true, "search_strategy_class": "RandomSearchStrategy" }
复制代码
Insert-Only 模式
Elassandra 中,Elasticsearc 文档的字段_source作为列项被存储在 Cassandra 表中。在通过 Elasticsearch 索引 API 向 Cassandra 存储层插入数据时,空字段会被默认赋值为 null,从而避免覆盖已有文档。该插入操作同时产生了一些 Cassandra 墓碑,这些墓碑其实对很多不变日志记录是没有用处的,这时设置 index.index_insert_only 字段将会避免产生墓碑,从而达到优化 Cassandra 存储的目的。
Drop on Delete Index 设置
Elassandra 采用 Cassandra 作为数据存储层。一般情况下,Elassandra 删除一个索引并不会真正删除底层 Cassandra 中的表和键空间。我们可以通过更改对 index.drop_on_delete_index 的设置,从而在删除表中索引的同时也能自动删除 Cassandra 中的表。
副本管理
Elassandra 中,Cassandra 取代 Elasticsearch 实现了数据副本管理。底层 Cassandra 的键空间副本映射保存了位置和副本数量。Elasticsearch 模板中的 index.replication 字段定义了 Cassandra 的副本映射。本例中,我们在数据中心 DC1 中保存了两个副本。
table_options 字段
table_options 字段定义 Cassandra 使用创建时间的表选项。因为日志记录是不变的,我们在这里选择使用Time Window Compactio策略来设计时间序列数据,当然我们也可以使用默认的 TTL 策略或压缩策略(默认为 LZ4)。
搜索策略类
在 Elassandra 中,调度节点会根据 search_strategy_class 定义的搜索策略将子请求分发到其他可用的节点中。默认的 PrimaryFirstSearchStrategy 策略会将子请求发送到所有的节点。我们在这里使用了 RandomSearchStrategy,在数据中心能够获得一个结果的最小节点集。比如在我们采用六节点两个副本要求的集群时,这种策略将只请求三个节点而不是六个,从而极大地减轻了集群的全局负载。
Elassandra 映射优化
由于 Elasticsearch 使用了多值字段,Elassandra 将所有类型为 X 的字段都保存到了一个 Cassandra 的列表 X 中。如果我们使用工具sstabledump查看产生的 SSTables 表,将得到如下由 filebeat 产生的 Cassandra 列:
{ "partition" : { "key" : [ "RL5Bp2cBWzCxo-DQnARL" ], "position" : 160123 }, "rows" : [ { "type" : "row", "position" : 160691, "liveness_info" : { "tstamp" : "2018-12-13T11:09:14.378005Z" }, "cells" : [ { "name" : "es_time", "deletion_info" : { "marked_deleted" : "2018-12-13T11:09:14.378004Z", "local_delete_time" : "2018-12-13T11:09:14Z" } }, { "name" : "es_time", "path" : [ "868796ae-fec7-11e8-aa29-7b1a7ab32955" ], "value" : "2018-12-13 11:08:42.265Z" }, { "name" : "kubernetes", "deletion_info" : { "marked_deleted" : "2018-12-13T11:09:14.378004Z", "local_delete_time" : "2018-12-13T11:09:14Z" } }, { "name" : "kubernetes", "path" : [ "868796aa-fec7-11e8-aa29-7b1a7ab32955" ], "value" : {"container_name": ["logs-generator"], "host": ["aks-nodepool1-36080323-0"], "annotations": null, "docker_id": ["e38071228edf79584ef4eafdfb67c0144605a31730e71b02b3f6e1c8f27e0ea3"], "pod_id": ["721a6540-fca4-11e8-8d8b-f6dcc5e73f85"], "pod_name": ["logs-generator"], "namespace_name": ["default"], "labels": [{"app": null, "controller-revision-hash": null, "release": null, "pod-template-generation": null, "statefulset_kubernetes_io/pod-name": null, "kubernetes_io/cluster-service": null, "k8s-app": null, "name": null}]} }, { "name" : "log", "deletion_info" : { "marked_deleted" : "2018-12-13T11:09:14.378004Z", "local_delete_time" : "2018-12-13T11:09:14Z" } }, { "name" : "log", "path" : [ "868796ab-fec7-11e8-aa29-7b1a7ab32955" ], "value" : "I1213 11:08:42.265287 6 logs_generator.go:67] 362287 PUT /api/v1/namespaces/ns/pods/s2qj 215\n" }, { "name" : "stream", "deletion_info" : { "marked_deleted" : "2018-12-13T11:09:14.378004Z", "local_delete_time" : "2018-12-13T11:09:14Z" } }, { "name" : "stream", "path" : [ "868796ac-fec7-11e8-aa29-7b1a7ab32955" ], "value" : "stderr" }, { "name" : "time", "deletion_info" : { "marked_deleted" : "2018-12-13T11:09:14.378004Z", "local_delete_time" : "2018-12-13T11:09:14Z" } }, { "name" : "time", "path" : [ "868796ad-fec7-11e8-aa29-7b1a7ab32955" ], "value" : "2018-12-13 11:08:42.265Z" } ] } ] }
复制代码
我们可以看到, Cassandra的集合类型(链表,集合,映射),产生了很多没有用的负载。对此,Elassandra 使用了新的属性来扩展 Elasticsearch 映射,而这些属性"cql_collection":"singtelon"可以将 Cassandra 类型显式地映射到单值字段。由于 Fluent-Bit 索引模板使用了这种单值字段映射属性,Cassandra 列存储也变得更加轻量:
root@elassandra-0:/usr/share/cassandra# tools/bin/sstabledump /var/lib/cassandra/data/logstash_2018_12_17/flb_type-751e28a0022f11e9a83bbd84c8d6464a/mc-9-big-Data.db{ "partition" : { "key" : [ "nmWfvWcBHsJPeHipoGsM" ], "position" : 402735 }, "rows" : [ { "type" : "row", "position" : 403179, "liveness_info" : { "tstamp" : "2018-12-17T19:23:34.412Z" }, "cells" : [ { "name" : "es_time", "value" : "2018-12-17 19:23:33.603Z" }, { "name" : "kubernetes", "value" : {"container_name": "logs-generator", "host": "aks-nodepool1-36080323-0", "docker_id": "e33b2cda2ed7ac3bc5a6504cd79b6ea999137a11791d67fbb8b497fe06d8d700", "pod_id": "8ecacdcd-0229-11e9-8d8b-f6dcc5e73f85", "pod_name": "logs-generator", "namespace_name": "default", "labels": [{"app": null, "component": null, "controller-revision-hash": null, "tier": null, "pod-template-generation": null, "name": null, "pod-template-hash": null, "version": null, "k8s-app": null, "kubernetes_io/cluster-service": null, "release": null, "statefulset_kubernetes_io/pod-name": null, "run": ["logs-generator"]}], "annotations": null} }, { "name" : "log", "value" : "I1217 19:23:33.600235 6 logs_generator.go:67] 2850 POST /api/v1/namespaces/ns/pods/65w 207\n" }, { "name" : "stream", "value" : "stderr" }, { "name" : "time", "value" : "2018-12-17 19:23:33.603Z" } ] } ] }
复制代码
Elassandra 存储优化
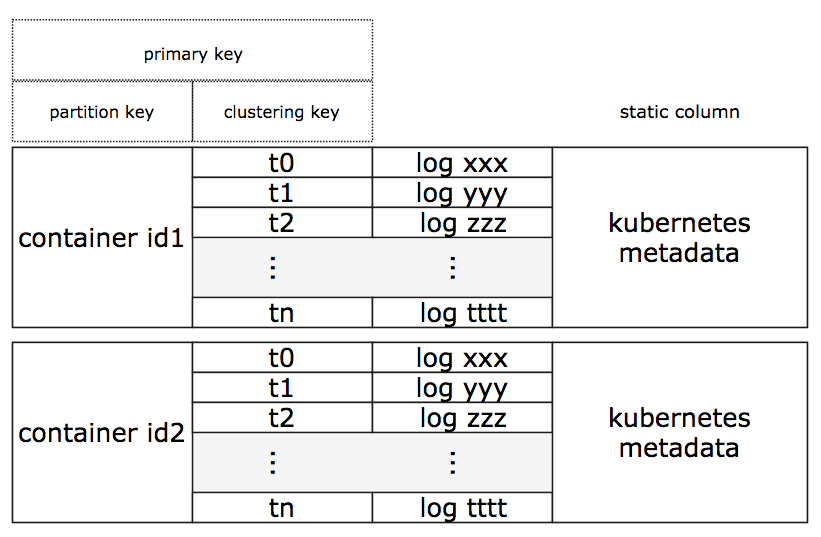
Fluent-Bit 为每一条日志记录都添加了一些相关的 kubernetes 元数据,对于某一个容器来的日志记录来说,所有的元数据都是相同的。对于这些日志记录的元数据,由于 Cassandra 采用了宽列存储,我们可以只存储一次,这样大大减小了 SSTables 的容量。下图展示了 Cassandra 存储中的 Elasticsearch documents 结构:
为实现上述结构,我们使用Elasticsearch管道改变了原始的 JSON 文档,增加了一个时间戳(唯一的)来作为 timeuuid(类型 1UUID),并使用 Cassandra 复合主键构建了一个 document_id 字段,复合键包括使用 Docker 容器 ID 的分区键 ,以及使用新 timeuuid 的集群键。
curl -H "Content-Type: application/json" -XPUT "http://elassandra-0:9200/_ingest/pipeline/fluentbit" -d'{ "description" : "fluentbit elassandra pipeline", "processors" : [ { "timeuuid" : { "field": "es_time", "target_field": "ts", "formats" : ["ISO8601"], "timezone" : "Europe/Amsterdam" } }, { "set" : { "field": "_id", "value": "[\"{{kubernetes.docker_id}}\",\"{{ts}}\"]" } } ]}'
复制代码
这样,我们可以将下面的映射属性添加到我们的Fluent-bit Elasticsearch模板中:
分区键列中字段赋值:cql_partition_key:true, cql_primary_key_order:0
集群键列中字段赋值:cql_primary_key_order:1,cql_type:timeuuid
Kubernetes 元数据列中字段赋值: cql_static_column:true
我们同时添加了索引设置:index.index_static_columns:true ,用来索引 Cassandra 静态列和所有的行。
在清除现存的索引、重新部署新的 Elasticsearch 管道和模板之后,SSTables 只需要每天为每个容器保存一个宽列日志存储。这样,我们大大优化了存储性能,并且 Kubernetes 元数据只需要每天保存一个 Docker 容器即可。同时由于 timeuuid 列可以被 Elasticsearch 当作日期使用,Cassandra 集群键清除了一些时间字段,设置是时间戳字段,例如 es_time 和 time 等。
{ "partition" : { "key" : [ "f9f237c2d64dd8b92130fd34f567b162f0ae1972e7afabee9151539ba31ccadd" ], "position" : 2800 }, "rows" : [ { "type" : "static_block", "position" : 3326, "cells" : [ { "name" : "kubernetes", "value" : {"container_name": "put-template", "host": "aks-nodepool1-36080323-0", "pod_id": "e24f2521-1256-11e9-8fe6-de1ce27ac649", "pod_name": "fluent-bit-sc6m6", "namespace_name": "default", "labels": [{"app": "my-fluentbit-fluent-bit", "component": null, "controller-revision-hash": "3156758786", "tier": null, "pod-template-generation": "1", "name": null, "pod-template-hash": null, "version": null, "k8s-app": null, "kubernetes_io/cluster-service": null, "release": ["my-fluentbit"], "statefulset_kubernetes_io/pod-name": null}], "annotations": [{"checksum/config": ["3375211361605629fc5a1f970e1fce0ce2fabbcb08ef4631acdc4bd2ac41fd7b"], "scheduler_alpha_kubernetes_io/critical-pod": null, "prometheus_io/port": null, "prometheus_io/scrape": null}]}, "tstamp" : "2019-01-07T08:33:35.968Z" } ] }, { "type" : "row", "position" : 3326, "clustering" : [ "e4375630-1256-11e9-a990-c3ec4d724241" ], "liveness_info" : { "tstamp" : "2019-01-07T08:33:35.954Z" }, "cells" : [ { "name" : "log", "value" : " % Total % Received % Xferd Average Speed Time Time Time Current\n" }, { "name" : "stream", "value" : "stderr" } ] }, { "type" : "row", "position" : 3326, "clustering" : [ "e4375630-1256-11e9-0566-b0312df0dcfc" ], "liveness_info" : { "tstamp" : "2019-01-07T08:33:35.964Z" }, "cells" : [ { "name" : "log", "value" : " Dload Upload Total Spent Left Speed\n" }, { "name" : "stream", "value" : "stderr" } ] }
复制代码
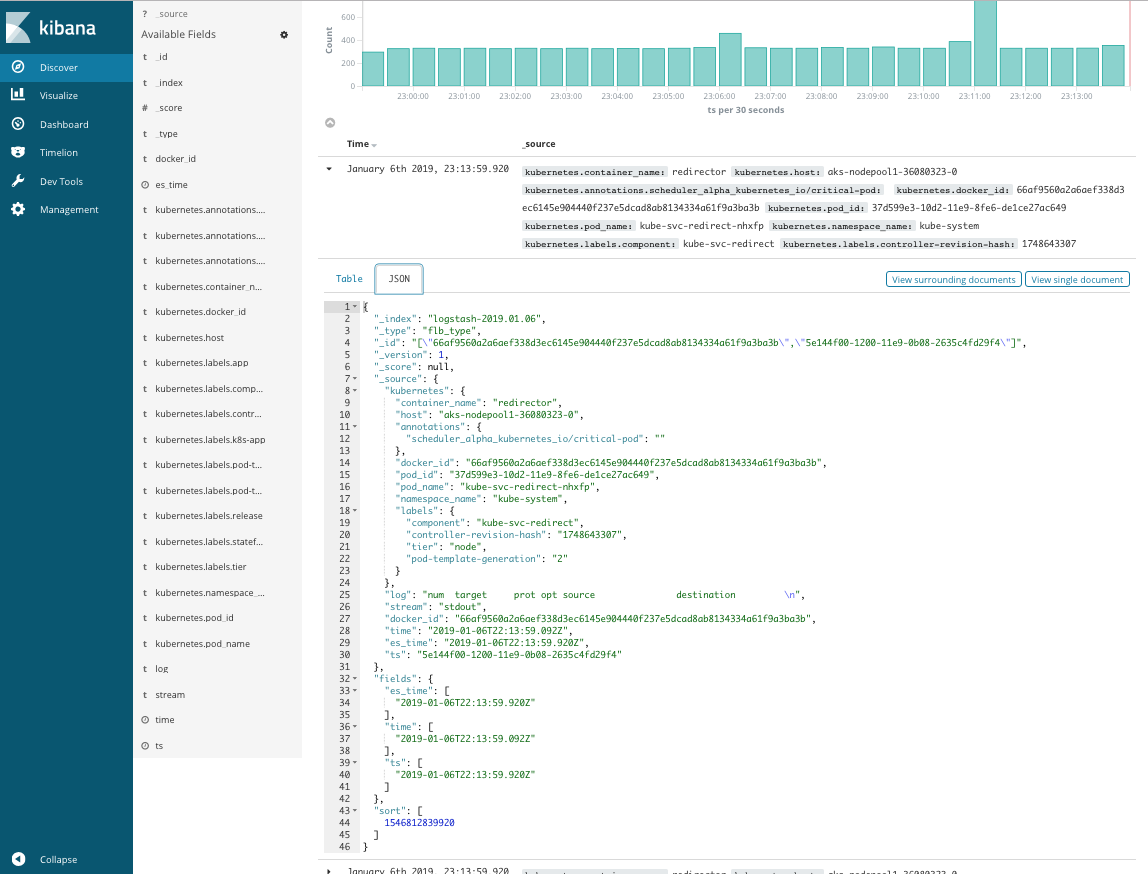
我们可以在这里使用 Kibana 来创建面板,分析日志。
可用性测试
最后,我们通过实例来验证一下 Elassandra 的可用性。
首先,创建一个日志产生器,输出实验所需要的日志记录。
for i in {1..20}; do kubectl run logs-generator${i} --generator=run-pod/v1 --image=k8s.gcr.io/logs-generator:v0.1.1 \--restart=Never --env "LOGS_GENERATOR_LINES_TOTAL=50000" --env "LOGS_GENERATOR_DURATION=3m"; done
复制代码
其次,我们强制关闭一个 Elassandra pod,人为制造一个单点故障,然后由 Kubernetes 控制器自动重启。
$kubectl delete pod/elassandra-1 pod "elassandra-1" deleted
复制代码
这种情况下,如果 Cassandra 只有一个副本,关闭主节点将会产生写错误。
[2019/01/10 16:46:09] [ warn] [out_es] Elasticsearch error{"took":3,"ingest_took":2,"errors":true,"items":[{"index":{"_index":"logstash-2019.01.10","_type":"flb_type","_id":"[\"c0e45980637031ed19386d8a2b3fa736597057eea46917b8c28b73ba640e3cc3\",\"25c13480-14f6-11e9-2b53-a734ca6c6447\"]","status":500,"error":{"type":"write_failure_exception","reason":"Operation failed - received 0 responses and 1 failures"}}},{"index":{"_index":"logstash-2019.01.10","_type":"flb_type","_id":"[\"c0e45980637031ed19386d8a2b3fa736597057eea46917b8c28b73ba640e3cc3\",\"372b3680-14f6-11e9-d3d8-e1397bcf3034\"]","status":500,"error":{"type":"write_failure_exception","reason":"Operation failed - received 0 responses and 1 failures"}}},{"index":{"_index":"logstash-2019.01.10","_type":"flb_type","_id":"[\"c0e45980637031ed19386d8a2b3fa736597057eea46917b8c28b73ba640e3cc3\",\"41a8c280-14f6-11e9-bc51-b90088b4aa65\"]","status":500,"error":{"type":"write_failure_exception","reason":"Operation failed - received 0 responses and 1 failur
复制代码
然后,我们为 Logstash 索引创建两个 Cassandra 副本,并重复上述测试。
kubectl exec -it elassandra-0 -- cqlshConnected to elassandra at 127.0.0.1:9042.[cqlsh 5.0.1 | Cassandra 3.11.3.5 | CQL spec 3.4.4 | Native protocol v4]Use HELP for help.cqlsh> ALTER KEYSPACE logstash_2019_01_10 WITH replication = {'class': 'NetworkTopologyStrategy','DC1':'2'};
复制代码
虽然在测试中 Fluent-Bit 提示器显示有一些连接中断错误,但它仍然将数据保存到了 Elassandra。
[2019/01/10 16:57:39] [error] [http_client] broken connection to elassandra-elasticsearch.default.svc.cluster.local:9200 ?[2019/01/10 16:57:39] [ warn] [out_es] http_do=-1[2019/01/10 16:57:39] [error] [http_client] broken connection to elassandra-elasticsearch.default.svc.cluster.local:9200 ?[2019/01/10 16:57:39] [ warn] [out_es] http_do=-1
复制代码
Cassandra 使用了多主节点架构,即便重启一个节点,我们仍然可以通过 Elasticsearch 的 API 在其他节点上进行写操作。如果丢失了一个节点,Elasticsearch 指示器将变为黄色,但搜索功能仍能继续使用。
health status index uuid pri rep docs.count docs.deleted store.size pri.store.sizeyellow open logstash-2019.01.10 p01ngidBRDSVsi99NupG5g 3 1 227478 0 88.3mb 88.3mbyellow open .kibana 68N_Dsk0SoOG9jHElafDUw 3 1 3 0 15.8kb 15.8kb
复制代码
节点重启后,Elasticsearch 指示器将重新变为绿色,Cassandra 节点 2 和节点 3 会将hint handoff发送到节点 1,以便恢复丢失的日志记录。
结语
Elassandra 的出现为 Kubernetes 中的日志处理增加了很多使用场景,如上文所示:通过相应的设置,你可以使用 Elasticsearch 的管道处理器来更改或优化 Cassandra 存储,即便我们不使用 Elasticsearch 的索引功能(在 Elasticsearch 映射中设置 index=no,如此将只获得底层 Cassandra 表中的数据);在维护 Elassandra 集群时,我们也可以在不关机的情况下实现滚动升级;亦或者在不用重新索引的情况下轻松实现水平扩展。
当然,Elassandra 也终于开始为混合云中的跨 Kubernetes 集群提供副本支持,详情将在其他文章中展开。
英文原文地址:https://dzone.com/articles/kubernetes-logs-with-elassandra?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed:%20dzone










评论