

背景介绍
随着人工智能技术在爱奇艺视频业务线的广泛应用,深度学习算法在云端的部署对计算资源,尤其是 GPU 资源的需求也在飞速增长。如何提高深度学习应用部署效率,降低云平台运行成本,帮助算法及业务团队快速落地应用和服务,让 AI 发挥真正的生产力,是深度学习云平台团队努力的目标 。
从基础架构的角度,GPU 资源的紧缺和 GPU 利用率的不足是我们面临的主要挑战。由于大量的算法训练及推理服务需求,云端 GPU 资源经常处于短缺状态;而使用 CPU 进行的推理服务常常由于性能问题,无法满足服务指标。除此之外,线上服务通常有较高的实时性要求,需要独占 GPU,但由于较低的 QPS,GPU 利用率经常处于较低的状态(<20%)。
在此背景下,我们尝试进行了基于 CPU 的深度学习推理服务优化,通过提升推理服务在 CPU 上的性能,完成服务从 GPU 迁移到 CPU 上的目的,以利用集群中大量的 CPU 服务器,同时节省 GPU 计算资源 。

图 1. 深度学习服务对云平台的挑战
1. 深度学习推理服务及优化流程
1.1 什么是深度学习推理服务?
深度学习推理服务通常是指将训练好的深度学习模型部署到云端,并对外提供 gRPC/HTTP 接口请求的服务。推理服务内部实现的功能包括模型加载,模型版本管理,批处理及多路支持,以及服务接口的封装等,如图 2 所示:
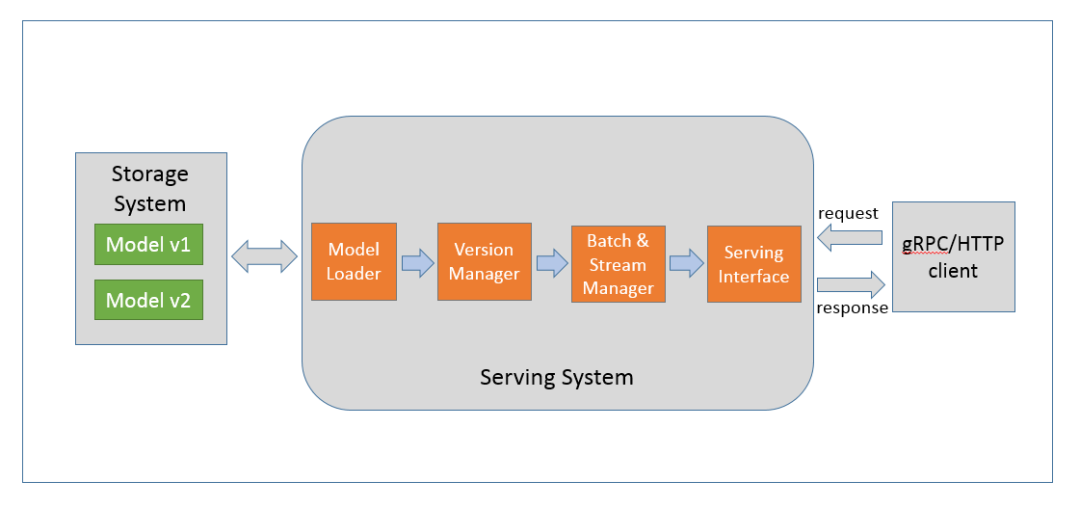
图 2. 深度学习推理服务功能模块
业界常用的深度学习推理服务框架包括 Google 的 tensorflow serving、Nvidia 的 Tensor RT inference server,Amazon 的 Elastic Inference 等。目前爱奇艺深度学习云平台(Jarvis)提供以 tensorflow serving 为框架的自动推理服务部署功能,已支持的深度学习模型包括 tensorflow,caffe,caffe2,mxnet,tensorrt 等,未来还会支持包括 openvino,pytorch。除此之外,业务团队也可以根据自身需求实现和定制特定的深度学习服务化容器,并通过 QAE 进行服务的部署和管理。
1.2 服务优化的流程是怎样的?
服务优化流程如图 3 所示,是一个不断朝优化目标迭代的过程。
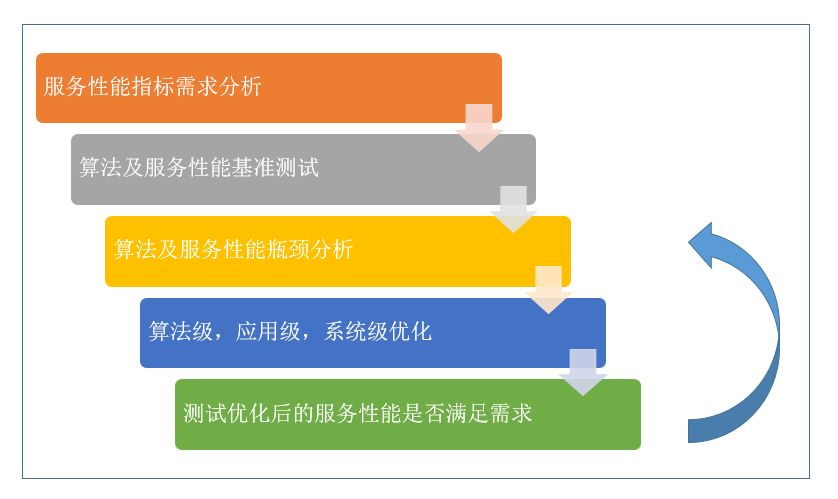
图 3. 服务优化的流程
进行深度学习推理服务的优化,首先需要明确服务的类型和主要性能指标,以确定服务优化的目标。从系统资源的角度,深度学习服务可以分为计算密集或者 I/O 密集类服务,例如基于 CNN 的图像/视频类算法通常对计算的需求比较大,属于计算密集型服务,搜索推荐类的大数据算法输入数据的特征维度较高,数据量大,通常属于 I/O 密集型服务。从服务质量的角度,又可以分为延时敏感类服务和大吞吐量类型服务,例如在线类服务通常需要更低的请求响应时间,多属于延时敏感类服务,而离线服务通常是批处理的大吞吐量类型服务。不同类型的深度学习服务优化的目标和方法也不尽相同。
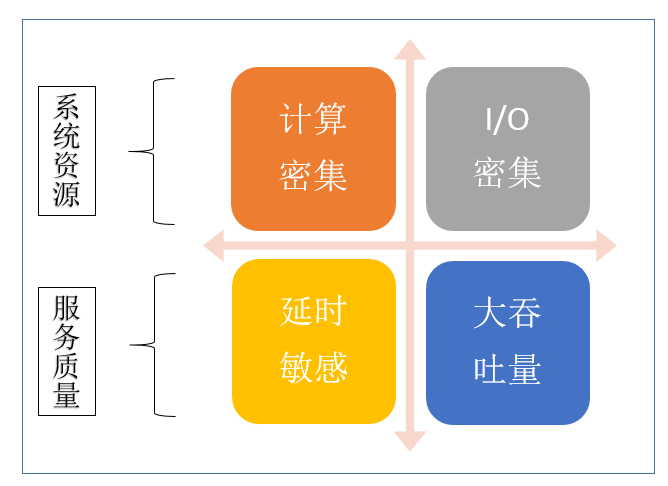
图 4. 深度学习推理服务的分类
1.3 深度学习推理服务的性能指标有哪些?
深度学习服务的性能指标主要包括响应延时(latency),吞吐量(throughput),及模型精度(accuracy)等,如图 5 所示。其中响应延时和吞吐量两个指标是进行服务化过程中关心的性能指标。明确服务性能指标后便于我们分析服务规模,计算单一服务节点需要达到的服务性能。
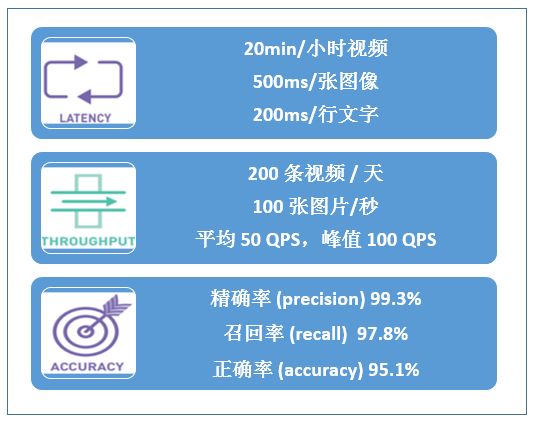
图 5. 深度学习服务性能指标
2. 基于 CPU 的深度学习推理服务优化
2.1 CPU 上进行深度学习优化的方法主要有哪些?
“工欲善其事,必先利其器”。CPU 上进行深度学习推理服务优化的方法,可以分为系统级、应用级、算法级,每一级也有对应的性能分析工具,如图 6 所示:
系统级的优化主要从硬件和平台的角度进行计算加速,方法主要包括基于 SIMD 指令集的编译器加速、基于 OMP 的数学库并行计算加速、以及硬件厂商提供的深度学习加速 SDK 等方法。
应用级的优化主要从特定应用和服务的角度进行流水和并发的优化。通常的深度学习服务不仅仅包含推理,还有数据的预处理、后处理,网络的请求响应等环节,良好的并发设计可以有效的提升服务端到端的性能。
算法级的优化主要针对深度学习模型本身,利用诸如超参数设置、网络结构裁剪、量化等方法来减小模型大小和计算量,从而加速推理过程。

图 6. 深度学习服务性能优化方法及分析工具
2.2 如何进行系统级的优化?
CPU 上系统级优化实践中我们主要采用数学库优化(基于 MKL-DNN)和深度学习推理 SDK 优化(Intel OpenVINO)两种方式。这两种方式均包含了 SIMD 指令集的加速。
数学库优化对主流的深度学习框架(tensorflow,caffe,mxnet,pytorch 等)均有官方源支持。以 tensorflow 为例,使用方法如下所示:
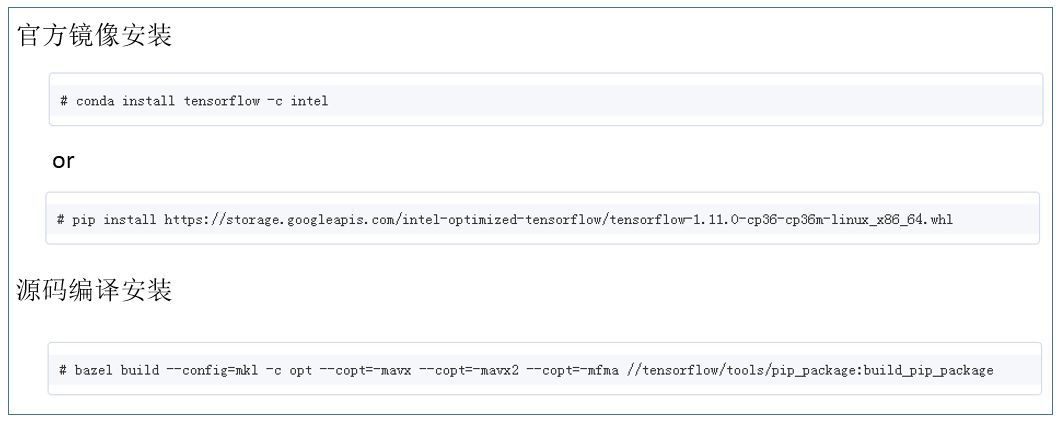
图 7. 基于 MKL-DNN 优化的 Tensorflow 使用方法
深度学习推理 SDK 优化方法,需要首先将原生深度学习模型进行转换,生成 IR 中间模型格式,之后调用 SDK 的接口进行模型加载和推理服务封装。具体流程如下所示:
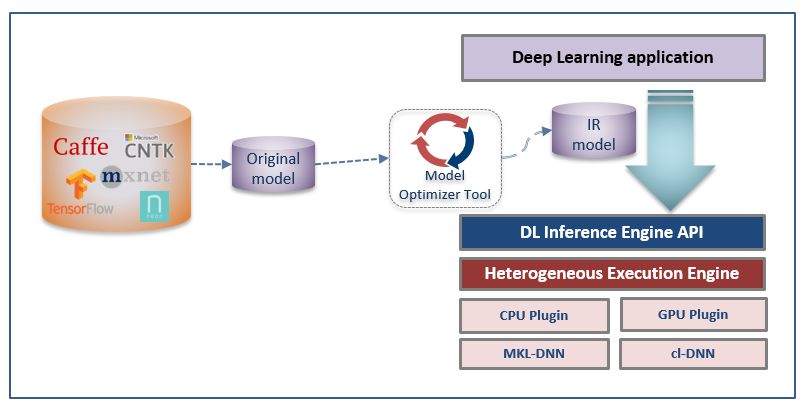
图 8. OpenVINO 优化推理服务流程
2.3 选用哪种系统级优化方式?
两种优化方式的比较如图 9 所示:

图 9. 系统级优化方式比较
基于两种优化方式的特点,实践中可首先使用基于 MKL-DNN 的优化方式进行服务性能测试,如满足服务需求,可直接部署;对于性能有更高要求的服务,可尝试进行 OpenVINO SDK 优化的方法。
2.4 系统级优化使用中有哪些影响性能的因素?
以上两种系统级优化方法,使用过程中有以下因素会影响服务性能。
(1)OpenMP 参数的设置
两种推理优化方式均使用了基于 OMP 的并行计算加速,因此 OMP 参数的配置对性能有较大的影响。主要参数的推荐配置如下所示:
• OMP_NUM_THREADS = “number of cpu cores in container”
• KMP_BLOCKTIME = 10
• KMP_AFFINITY=granularity=fine, verbose, compact,1,0
(2)部署服务的 CPU 核数对性能的影响
CPU 核数对推理服务性能的影响主要是:
• Batchsize 较小时(例如在线类服务),CPU 核数增加对推理吞吐量提升逐渐减弱,实践中根据不同模型推荐 8-16 核 CPU 进行服务部署;
• Batchsize 较大时(例如离线类服务),推理吞吐量可随 CPU 核数增加呈线性增长,实践中推荐使用大于 20 核 CPU 进行服务部署;
(3)CPU 型号对性能的影响
不同型号的 CPU 对推理服务的性能加速也不相同,主要取决于 CPU 中 SIMD 指令集。例如相同核数的 Xeon Gold 6148 的平均推理性能是 Xeon E5-2650 v4 的 2 倍左右,主要是由于 6148 SIMD 指令集由 avx2 升级为 avx-512。
目前线上集群已支持选择不同类型的 CPU 进行服务部署。
(4)输入数据格式的影响
除 Tensorflow 之外的其他常用深度学习框架,对于图像类算法的输入,通常推荐使用 NCHW 格式的数据作为输入。Tensorflow 原生框架默认在 CPU 上只支持 NHWC 格式的输入,经过 MKL-DNN 优化的 Tensorflow 可以支持两种输入数据格式。
使用以上两种优化方式,建议算法模型以 NCHW 作为输入格式,以减少推理过程中内存数据重排带来的额外开销。
(5)NUMA 配置的影响
对于 NUMA 架构的服务器,NUMA 配置在同一 node 上相比不同 node 上性能通常会有 5%-10%的提升。
2.5 如何进行应用级的优化?
进行应用级的优化,首先需要将应用端到端的各个环节进行性能分析和测试,找到应用的性能瓶颈,再进行针对性优化。性能分析和测试可以通过加入时间戳日志,或者使用时序性能分析工具,例如 Vtune,timeline 等 。优化方法主要包括并发和流水设计、数据预取和预处理、I/O 加速、特定功能加速(例如使用加速库或硬件进行编解码、抽帧、特征 embedding 等功能加速)等方式。
下面以视频质量评估服务为例,介绍如何利用 Vtune 工具进行瓶颈分析,以及如何利用多线程/进程并发进行服务的优化。
视频质量评估服务的基本流程如图 10 所示,应用读入一段视频码流,通过 OpenCV 进行解码、抽帧、预处理,之后将处理后的码流经过深度学习网络进行推理,最后通过推理结果的聚合得到视频质量的打分,来判定是何种类型视频。
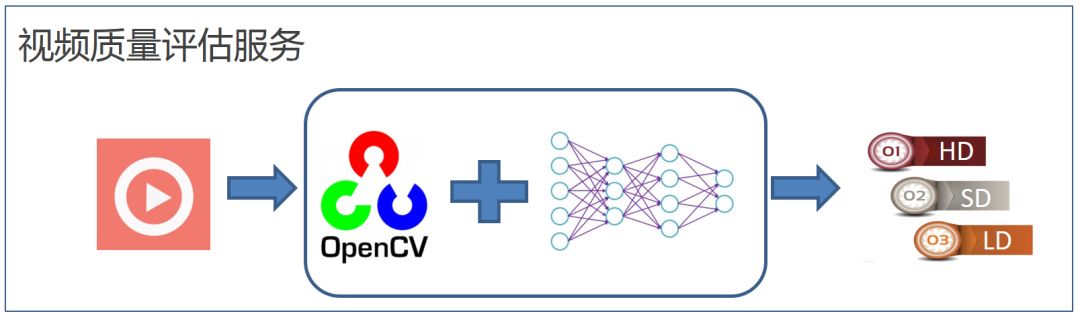
图 10. 视频质量评估服务流程
图 11 是通过 Vtune 工具抓取的原始应用线程,可以看到 OpenCV 单一解码线程一直处于繁忙状态(棕色),而 OMP 推理线程常常处于等待状态(红色)。整个应用的瓶颈位于 Opencv 的解码及预处理部分。
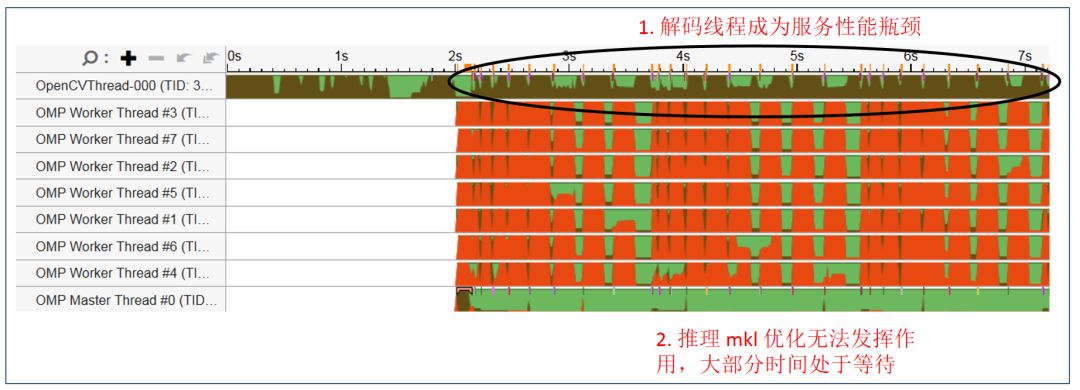
图 11. 应用优化前线程状态
图 12 显示优化后的服务线程状态,通过生成多个进程并发进行视频流解码,并以 batch 的方式进行预处理;处理后的数据以 batch 的方式传入 OMP threads 进行推理来进行服务的优化。
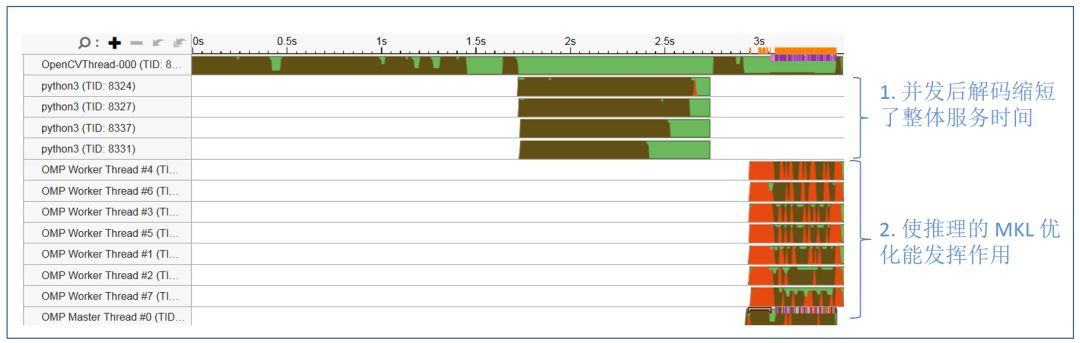
图 12. 应用并发优化后线程状态
经过上述简单的并发优化后,对 720 帧视频码流的处理时间,从 7 秒提升到了 3.5 秒,性能提升一倍。除此之外,我们还可以通过流水设计,专用解码硬件加速等方法进一步提升服务整体性能。
2.6 如何进行算法级的优化?
常见的算法级优化提升推理服务性能的方法包括 batchsize 的调整、模型剪枝、模型量化等。其中模型剪枝和量化因涉及到模型结构和参数的调整,通常需要算法同学帮助一起进行优化,以保证模型的精度能满足要求。
2.7 Batchsize 的选取在 CPU 上对服务性能的影响是怎样的?
Batchsize 选取的基本原则是延时敏感类服务选取较小的 batchsize,吞吐量敏感的服务选取较大的 batchsize。
图 13 是选取不同的 batchsize 对推理服务吞吐量及延时的影响。测试结果可以看 batchsize 较小时适当增大 batchsize(例如 bs 从 1 到 2),对延时的影响较小,但是可以迅速提升吞吐量的性能;batchsize 较大时再增加其值(例如从 8 到 32),对服务吞吐量的提升已没有帮助,但是会极大影响服务延时性能。因此实践中需根据部署服务节点 CPU 核数及服务性能需求来优化选取 batchsize。
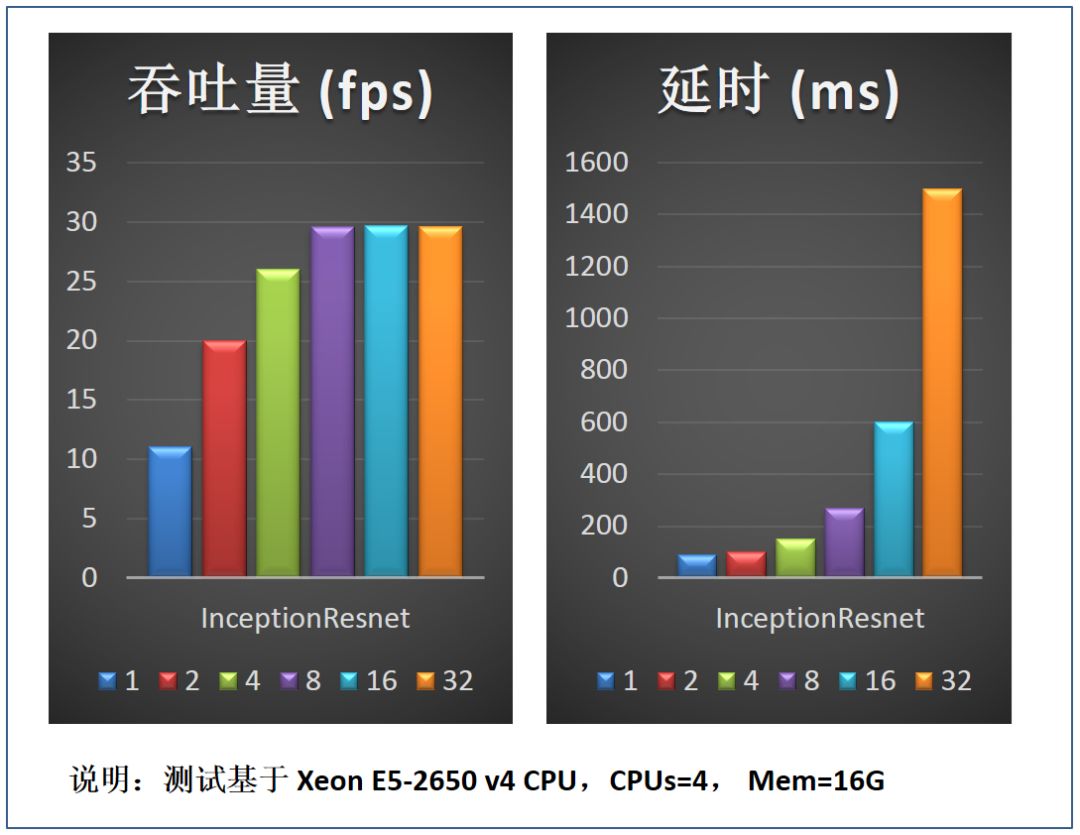
图 13. Batchsize 对服务性能影响
总结与展望
以上介绍的系统级优化方法,已在深度学习云平台落地超过 10+应用和算法,部署上千 core 的服务,平均性能提升在 1~9 倍。更详细的使用方法可以参考文末相关链接。
对于深度学习的推理服务优化,深度学习云平台还计划加入更多的异构计算资源来加速特定任务,例如 VPU、FPGA 等计算资源。同时在服务的弹性和优化调度、部署参数的自动优化选取等方面,我们也会继续深入优化,以充分发挥云平台的计算资源和能力,加速深度学习推理服务的落地。
相关链接
(1)OpenVINO:
https://software.intel.com/en-us/openvino-toolkit
(2)Vtune 性能分析工具:
https://software.intel.com/en-us/vtune

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论