
下面介绍如何开始一个 AI 业务,这是一次比较科普的演讲,希望通过计算机视觉的一些案例,能带给在座的各位 EGO 会员及各行业的老板一个关于 AI 和自己的业务结合的直观的认识。
这里我先简单介绍一下计算机视觉做的事情是什么,然后再给大家引申一下,在一些业务里应用这些技术的可能性。
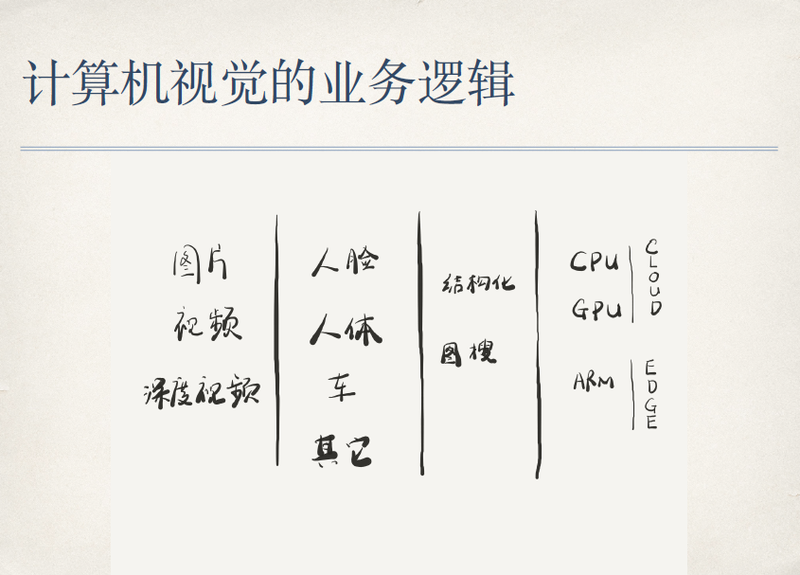
这个图是我今天早上临时加上的,我觉得这样画应该更容易理解一些。计算机视觉的任务就是要对几种和视觉相关的媒体做一些信息处理,包括图片、视频以及深度视频。
通过这些媒体我们得到的对象包括人脸、人体、车以及其他,这里其他对象的范围比较广泛,比如说宠物、食品、普通物体分类等等,但是它的应用范围应该远不如前三者。
得到了这些对象的图像信息之后,我们要做什么任务呢?总结一下,比较广泛应用的有两种任务,一是结构化,二是图搜。
结构化是指这个对象确切可描述的信息。比如一张人脸图片的结构化信息包括人的性别、年龄、表情类别,以及戴不戴眼镜、口罩、帽子等信息;人体的结构化包括人的上身下身的衣着特点等;车辆的结构化信息就比较多了,基本的有车牌、车型、年款、颜色等,另外有一些可以描述的特征信息,比如车窗内挂件、摆件,甚至是否有划痕等等,这些特征描述对于区分一些很像的车是非常有用的。
然后是图搜,图搜的信息基础是没有结构化描述的,计算得到的是一个特征。我们常谈到的人脸识别就是典型的图搜应用,最典型的 1:N 人脸搜索就是以一张脸搜图库里的脸,得到和它距离很近的一些脸。人体和车也是一样,只不过人体和车辆的特征维度相对于人脸来讲少一些,这决定了人脸搜索可以在一个更大的库中发生,人体和车辆只能在相对小的库中搜索。
对于结构化和图搜这两种任务来讲,图搜具有更广泛的应用场景,为什么呢?得到结构化信息之后,通常是作为数据库索引进行搜索,但是具体应用中很难单纯依赖结构化信息得到想找的对象。比如要找一个人,很难通过具体描述这个人是长头发、有胡须、戴眼镜或者其他可描述的细节直接找到这个人,但是如果提供一张这个人的照片,就可以在人脸库里很好地搜索到。车也是一样,我们通常通过车牌来搜索一个车,但是在真正的应用场景里,这是不一定生效的。比如一些犯罪分子在办案时往往会把车牌隐藏掉,或者干脆用一个假车牌,这时候就需要用车的特征来搜索,这样的场景下技术带来了真正可用的价值。
这张图再往后,是计算的平台或载体。
首先是云服务的应用,这在公安这类机密客户那里是远远落后于商业及个人用户的。我们去年经常做这样的事情,就是把一堆服务器搬到用户的机房里,比如警方或者交管局,我们留下专人运维这个机房里的服务器,我们连接客户的视频流,利用 CPU 和 GPU 去计算前面所所说的东西,然后把结果在它的客户端体现出来,或者是推送到客户的平台中。
但从今年开始我们有一些新的东西受到了老客户的青睐,对于类似于公安或交通这样的传统用户,他们竟然也或多或少的接受云端的方案,这在以往是不可想象的,因为他们的技术和数据是非常机密的。但是现在一些云服务提供商针对公安、银行这些具体的业务做了大量专用网络和安全上的优化工作,使得这个事可以发生。
另一方面就是越来越多地使用了 EDGE 端的计算,端到端(EDGE 端到 CLOUD 端)已经不再是什么秘密,一个很直接的结果就是降低了成本、提高了密度、以及广泛的智能化。举个例子,原来的 IPC(网络摄像机)都是传视频到后端去处理,现在很多专门的车辆及人脸抓拍摄像机可以在终端设备上把我们关注的对象抓拍成图片,再把图片传到后端去处理,一方面是节省带宽,原来一个 Gb 的带宽只能传输几十路视频,现在只传输抓拍图片可以做到万路,更令人激动的是,假如抓拍设备部署在普通的超市、饭店这样的街头小店里,使用非常便宜和普通的家用带宽就可以满足要求。另外一个好处是后端服务器的计算成本极大降低,可能降低两个数量级这样的程度。两个数量级大家可以想象是什么样的情况,我们可以把一个应用做到非常便宜,可以从原来 2G 的业务逐渐做到 2B 的业务,再逐渐做到 2C 的业务。目前零售行业以及一些智能办公行业已经在尝试这样的业务方式,总结一下,就是我经常在公司和客户那里说的三个词:低成本、高密度、智能化。这是从业务上来分析计算机视觉的一些情况。
这里边有几个事情我需要说明一下。第一个是深度视频,深度视频相关的产品我们在四年前就开始做,我不否认它的科技范儿,以及在一些场景里它不可替代的作用,但是到现在为止还是一个成本比较高的产品,所以它大都应用在类似于银行加钞、金库、监狱等支付能力非常强的客户。深度视频的作用显而易见,通过深度数据,它很容易能够计算出人的肢体行为、行动、人和环境关系等信息,而普通二维数据很难做到。这个产品目前还不具备广泛场景的扩展性,但是随着传感器技术的提高,事实上我们已经看到一些这方面的成果,它也会满足前边提到的低成本、高密度、智能化的原则。
另一个要说明的是视频,这就是刚才讲的,逐渐会把后端视频的处理转移为前端抓拍之后在后端对图片的处理,这样降低了两个数量级的成本之后,最大范围地进行业务的推广。大家可能很奇怪,之前 GPU 的势头很猛,NVidia 的股价在一年时间里飙升了三倍不止。但是我想说的是 NVidia 工业级别的显卡价格和 CPU 这样的市场相比是小众和暴利的。CPU 是个 2C 的市场,GPU 也有 2C 的市场,但是工业级别的 GPU 显卡,它的市场价格是普通显卡的几倍。之所以能维持高价,是因为之前少有替代品,然而我们今天看来它的优势越来越小。
一方面,现在有很多算法上的进展告诉我们,同样的算法在 CPU 上也可以高度的优化,它的成本和在 GPU 上可以媲美。而结合 CPU 服务器的稳定性和灵活性,比如分钟级别的弹性调度,它的实际成本还有一个数量级的优化空间。
另一方面,它的竞争对手还包括 ARM、FPGA、 Google 的 TPU 芯片等这些日益成熟的专有计算芯片。这样的结果告诉我们,我们以前好像做错了,我们建立了大量的 GPU 集群,某个友商甚至利用它上一轮融资的千万美金建立了一个几千块 GPU 的私有计算集群。但是大家往后看,这可能不是特别值得,我感觉一两年内就会发生的是,首先 GPU 的价格会降低到非常亲民,专有计算芯片无论在服务器端还是在轻量级设备端都普及。
(点击放大图像)

这个图是一个人脸系统的业务模型,左边是终端设备,是我们系统的数据源,基本都是抓拍设备,包括我们自己造的人脸抓拍机,以及我们自己造的人眼相机。人眼相机是可以应用于大广场、大范围的人脸抓拍机。另外还有抓拍服务器,对接普通的 IPC,通过这个抓拍服务器可以把普通的 IPC 变成抓拍机一样的形态来对接系统。中间系统上下两个蓝色的数据流,下面的数据流是实时业务流,上面是像黑白名单入库之类的离线业务流。视频数据由抓拍设备转换成图片之后会经过人脸引擎进行处理,这个大规模的引擎包括人脸检测、特征提取和结构化,对于车的数据也类似地会有相应的车辆检测和结构化,然后经过存储、比对引擎和消息队列,形成我们的一套系统,后面对接应用的 API 池。上面还有一个从数据库对接出的离线数据分析和实时数据分析系统,它结合其他平台的业务数据,对结构化数据和比对结果进行大数据分析,并汇集到一个多维查询系统。
每个行业都有它自己不好做的地方,AI 这个细分行业里最大的特点就是数据依赖。大家可能都知道 AI 算法基本上都是以基于学习的算法为主,简单的讲就是通过大量的数据标注之后(Data),对一个网络(Network)的参数进行迭代优化得到一个模型(Model),业务层通过这个 Model 进行推理计算。我这个题目叫“如何开始一个 AI 业务”,当你在自己的业务上考虑这个问题的时候,你要用 AI 解决什么问题,首先要问自己数据够不够,第一是量够不够,第二是质量够不够,第三是数据的多样性够不够,量和质量比较好理解,下面讲一下多样性的问题,也就是跨域数据的难题。
多样性

以人脸识别这个业务为例,有一些公共的人脸平台,可以输入一张照片和一个库,它会给出识别结果。但是据我了解,这些通用的人脸平台在具体业务上表现并令人满意。我是非常理解他们的,为什么几个友商都说自己是人脸识别第一的平台,但是在具体应用时表现不好呢,答案是它的数据并没有符合你使用的域。
举个例子,一个做婚恋网站,它数据库里的照片都是经过化装打扮的;一个社交网站,它的人脸头像数据都是个性搞怪的;而我们的身份证照片,则是普通素颜的。这几个领域里的数据,领域内是非常好用的,但是它们相互之间的交叉联系,无论从数据获取、标注还是得到最终应用结果,都是非常困难的。我们之前在某个边疆省份做了一个业务,模式很简单,就是用人脸识别跑一个黑名单,黑名单里包括公安关注的危险分子,这个名单非常大,大概有几十万。在最开始实施现场测试的时候,我们发现结果非常不好,准确度并没有达到我们的期望。后来我们发现这个省的大多是少数民族,他们的脸跟汉族人特征差异很大,而跟西亚人或者是俄罗斯人种是更像的,而我们那时候的人脸模型,还是以汉族人为主要的样本训练得到的,所以带来了很大的困难,其根本原因还是样本数据量不足造成的。所以在我们把现场数据标注和重新训练作为项目本身的过程,很快就达到了我们期望的准确度。
只有深入理解应用数据的域,才能够得到期望的效果。另外一种情况是希望有跨域数据的应用,比如证件照和各种现场抓拍照的跨域,就必须专门针对跨域的问题进行交叉的标注和训练,才能得到好的结果。跨域的成本往往取决于数据的来源,比如刷身份证并抓拍人脸的门禁,就可以很好的把证件照和抓拍照联系起来。
另外一个与数据相关的就是如何在业务中结合标注。所谓标注,大家可以理解为人工智能里的“人工”。一个已经使用旧数据训练好的模型在你的领域里可能不一定适用,必须把标注的任务融入到业务里,让它成为业务的常态。做电商一定会有个呼叫中心,做 AI 也一定会有个标注中心支撑我们的业务,他们就会根据我们任务的指标去完成标注的任务。经过标注中心标注之后,AI 模型的效果会逐渐变好。所以当你考虑这样的业务一定要同时考虑相关的人工成本,如果领域不变的话,成本可能会逐渐降低,需要标注的数据会逐渐变少,但是可能不会消失,因为时过境迁,总会有些变化的东西。

ID,ID,ID,重要的事情说三遍,在 AI 业务里,我们认为能得到的最有价值的信息就是 ID。我把它分成了几种层次:
第一种就是类似于身份证这样的 ID,它不一定是身份证,但一定是长效、唯一的 ID,这是最有价值的,就像你在网上做什么事都有记录一样,如果我有这个 ID,而以后你在现实中做什么事也都有纪录,这是很可怕的事情。
第二种就是长 ID,长 ID 是跨域的,跨时间、跨地点、跨来源,长 ID 并不能知道你是张三还是李四,但是它知道这个 ID 之前所有的活动。我们把能够拼接形成长 ID 的计算过程叫 ReID,就是你很多活动我们通过算法把它们连接在一起了。
在商场里,当你进入的时候,如果获得了你得长 ID,系统虽然不知道你是谁,但是能瞬间调出你之前进入商店的行为,包括你在哪个柜台前逗留时间长,你的动线轨迹,甚至可以绑定了你的结帐信息,知道你购买的记录。对于商店的应用来讲,这些数据已经足够了,这样的一个长 ID 获取成本低而且规避了侵犯隐私风险,一个商场显然不可能对你的身份信息进行核实,但是它有这样的长 ID,就有足够的想象空间做出一些营销上的优化。短 ID,就是一个在时空上局部的 ID。ID 的价值从上到下是递减的,当然获取成本也是越来越小。ID 的密度和分布也是非常重要的,就像网站的浏览记录,得到的 ID 密度越高,对用户行为了解得更透彻,这里有很多细节。包括我是只得到你在这的活动,还是说得到你非常大范围的活动。这些就是我对 ID 的一个分类定义。
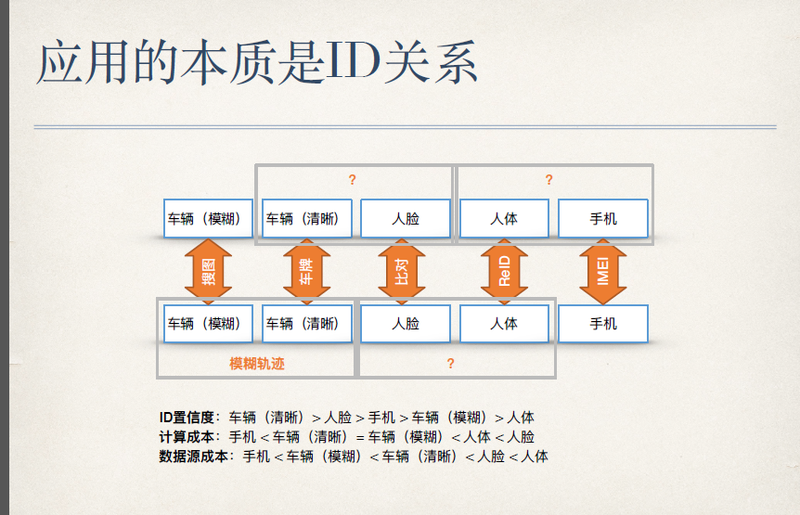
这里总结了一下以人脸识别或者车辆识别技术为基础的应用,本质上是 ID 的关系。所有我们需要得到的结果都是这几个 ID 的关系,车辆、模糊的车辆、清晰的车辆、人脸、人体、手机,或者没有写进来的其他的东西。
在应用里,我们希望它们之间都有 ID 对应,同一类对象,比如人脸和人脸之间,进行比对之后,就知道两个人脸是不是同一个人的概率,如果是同一个人,再把两个 ID 合并,其他的也是一样。但是当我关注下面这样的事的时候,就不一样了。一个人开了车,然后从这个车上下来,这个时候,我作为一个人很容易知道这个车是他的车,他是司机也好,他是副驾驶也好,这个关系我知道,但是人工智能很难处理这样的事情,它需要通过一些逻辑上的分析以及一些模糊的匹配去得到这样的关系。
比如图中横向的,车辆和人脸之间的关系,模糊车辆和清晰车辆之间的关系,模糊车辆就是看不清楚车牌,但是大概能看清这个车,清晰车辆就是车牌能看得更清楚一些。我们会通过一些模糊匹配的方式以及时空关系等方式把它们匹配起来。包括人脸和人体也是一样,能看清这张脸,但是当其他任何拍这个人拍得比较小的时候,这张脸看不清楚了,我怎么知道这个人还是你,这也是一个要打通的关系。人体和手机更是这样。当我们把横向和纵向的关系都打通, ID 全部的关系就通了。现在我的图中打问号的这几个地方,实际上是目前做得并不好的地方,这也是人工智能相关的应用在近几年要特别加强,也是最有机会的地方。
你的业务需要 AI/CV 吗?
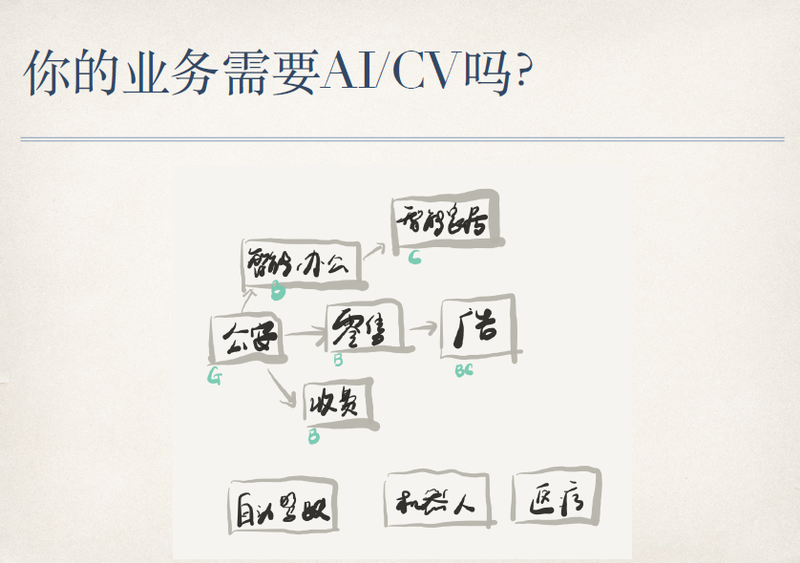
我接受过很多的公司来向我们咨询方案,想要他们的业务里获得 AI 的能力,用来帮助他们的业务进行优化和转型。在实际项目中我也接触了几个行业,我们也做了一些产品去应用于不同行业。
图中列的几个行业有这样的一些关系,首先从公安业务说起,它的特点就是 2G,主要的业务目标是公安稽查、布控,就是刚才讲的动态黑名单布控、静态图帧这样的一些业务,这个业务做了几年。说实话,这是我们的衣食父母,到现在公安业务也是整个人工智能行业最现实的一个业务方向。以公安业务的技术、产品为基础,我们发现可以做很多新的东西,比如说智能办公,楼宇和室内显然比公共场所的业务量级要大,但这是一个 2B 的业务,之前是不好做的,因为成本太高。
大家也看到很多楼宇物业已经应用了包括人脸门禁,它不是一个新鲜的事物,刷脸然后进门或者拍一个证件对脸进行验证之后就可以进去了,证明你的人和证件是同一个。但是智能办公的要求是不一样的,它的要求是不只在门口要有这样的设备,在公司的各个角落里都要有,包括休闲区、工作区,甚至车口、门口等等,这作用是什么呢?作用就是把办公区里人的行为数据化,当然能做到这点的前提就是成本降低了。包括收费业务,有些朋友应该发现广东这边已经有了,就是当你进入高速路口时,可以刷支付宝进行收费,不用去 ETC,也不用去交现金。很快它可能做到连手机的支付宝也不用刷了,它看到你的车牌,并且看到你的脸,把车牌和你的脸进行验证之后,你就直接可以开车通过了。当然之前你要通过支付宝去存一些钱,或者绑定支付宝在相应的帐户里,这样就会得到一个更快捷的通过方法。后面还有几个这样的业务目标,不扩展讲了。我觉得蛮有意思的,通过一种技术从高大上而专业(图左边)到走向非常便宜而广泛(图右边)的这一路上,有非常多的机会。实际上正是这样的转变,才能让一个技术真正落地,实现它的价值。
你的业务需要一个算法团队吗?
这个问题好多人问的,就是当你的公司想做一些 AI 相关的业务,你需不需要自己养一个算法团队。这没有直接的答案,得具体问题具体分析,需要看是哪些方面的业务。
首先你的业务从 AI 的层面上来讲,是不是一个通用的类型。比如说你希望像美图秀秀拍一个人脸之后进行美化,这个就有有可能不需要自己的 AI 团队,百度腾讯谷歌微软这样一些提供基础 AI 服务的公共资源以及像“一桶筐汤”这样的公司提供的方案,都可以是你的选择。但是当你遇到一些业务别人并没有涉及过的或者你的领域数据很独特时,可能就得养一个算法团队了。但是需要更正一下,确切的说是算法“工程”团队。算法团队是更基础的层面,但算法工程团队实际上是把现成的算法进行实践和工程化的团队,这是非常必要的。
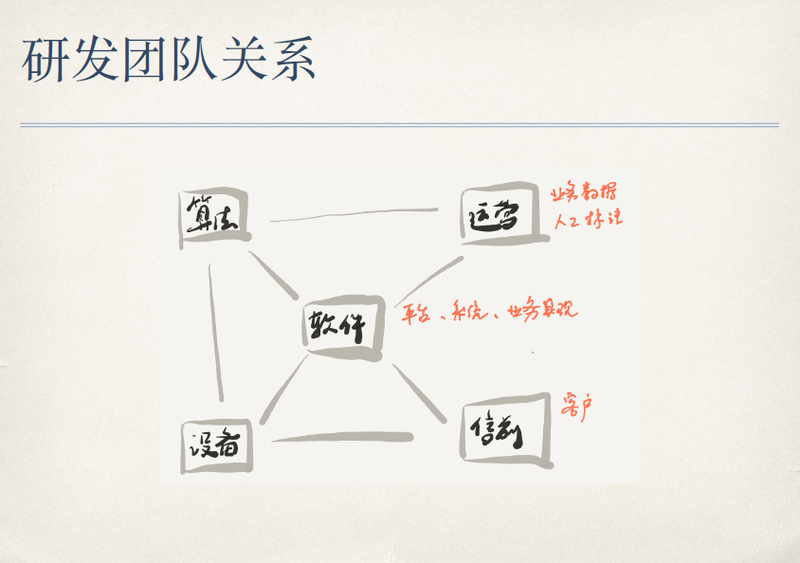
做一个 AI 的业务在研发团队里需要有这样一些角色,算法团队、软件团队、设备团队,更包括运营和售前。这些团队角色之间的关系,我简单讲一下。比如说算法团队和软件团队之间的关系,看起来很自然,算法团队提供算法,给软件团队来包装成产品。但实际上并不是这么直接,算法的结果一定是循序渐进的,开始得到的结果肯定不好。软件团队提供给用户的价值,是通过算法体现出来,但是算法还不够好的过程中,软件要当好一个背锅侠的角色,它需要通过各种手段来进行补助。算法不是万能的,软件在合适的时候巧妙的使用算法,才能实现算法最大的价值,不能美玉当砖。这些团队里,有不少故事可以讲,有机会我专门整理。
今天的分享就到这里,谢谢大家。
讲师介绍
苑维然博士于 2013 年加盟格灵深瞳,负责计算机视觉和大数据分析系统的研发工作,任格灵深瞳首席架构师,兼人脸平台产品负责人。
苑博士曾就职于法国国家信息与自动化研究院(INRIA),任专家工程师,在一项由法国研究基金会(ANR)和法国时尚产业联合的项目(SIMULVET)中从事计算机图形计算引擎的开发。苑博士 2008 年毕业于北京大学,获理学博士学位;2003 年毕业于大连理工大学,获工学学士学位;是多项专利的发明者,并在国际期刊和会议上发表了多篇关于计算机图形学和高性能计算方面的论文。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 1 条评论