

作者|小米数据智能部开发工程师 汤佳树
编辑|SelectDB
小米用户行为分析统一平台是基于海量数据的一站式、全场景、多模型、多维度、自助式大数据智能洞察分析服务平台,对接各类数据源,进行加工处理、分析挖掘和可视化展现,满足各类用户在用户洞察场景下的数据分析应用需求,提供高效极致的分析体验。
业务需求
平台可以基于数据进行时间分析,留存分析,分布分析,漏斗分析等,业务方主要基于事件进行分析,事件是追踪或记录的用户行为或业务过程,可以是单个事件也可以是多个事件组合的虚拟事件。
数据来源于各业务的打点数据,且基于事件模型进行建模,用户在产品中的各种操作都可以抽象成 Event 实体,并且里面都会包含五要素:
Who:即参与这个事件的用户是谁,例如用户的唯一 ID
When:即这个事件发生的实际时间,例如
time字段,记录精确到毫秒的事件发生时间Where:即事件发生的地点,例如根据 IP 解析出的省份和城市
How:即用户从事这个事件的方式,例如用户的设备,使用的浏览器,使用的 App 版本等等
What:描述用户所做的这件事件的具体内容,例如点击类型的事件,需要记录的字段有点击 URL,点击 Title,点击位置等
数据基于 OLAP 引擎 Doris 进行存储,随着接入业务不断增多,且接入的业务量不断膨胀,Top 级应用可以达到 100 亿条/天,查询压力和时间相继增大,用户对查询时延的吐槽愈来愈多,我们急切的需要提升查询性能来提升用户的体验。
痛点问题
针对于业务需求,我们总结了以下痛点问题:
为了实现复杂的业务需求,OLAP 分析引擎需要留存、漏斗等分析函数支撑。
增量数据 100 亿/天,导入压力大,部分业务要求数据导入不丢不重。
业务接入不断增多,数据量膨胀,需要 PB 级的数据下的交互式分析查询达到秒级响应。
为了解决以上的痛点问题,我们对比了多款 OLAP 分析引擎,最终选择了 Apache Doris。Doris 提供了留存、漏斗分析等函数,极大程度的简化了开发的成本。在数据导入的过程中,我们尝试 Doris 刚推出的 Merge On Write Unique Key 导入模型,可以抗住 100 亿/天的增量数据压力。针对于向量化查询引擎的改造也是的性能较之前的版本有 3-5 倍的提升。
架构演进
一个优秀的系统离不开持续迭代与演进。为了更好的满足业务需求,我们在存储架构与查询引擎两个层面上不断进行尝试,小米用户行为分析系统在上线后,目前已完成 3 次改造,以下将为大家介绍改造历程。
数据存储结构:数据架构的演进
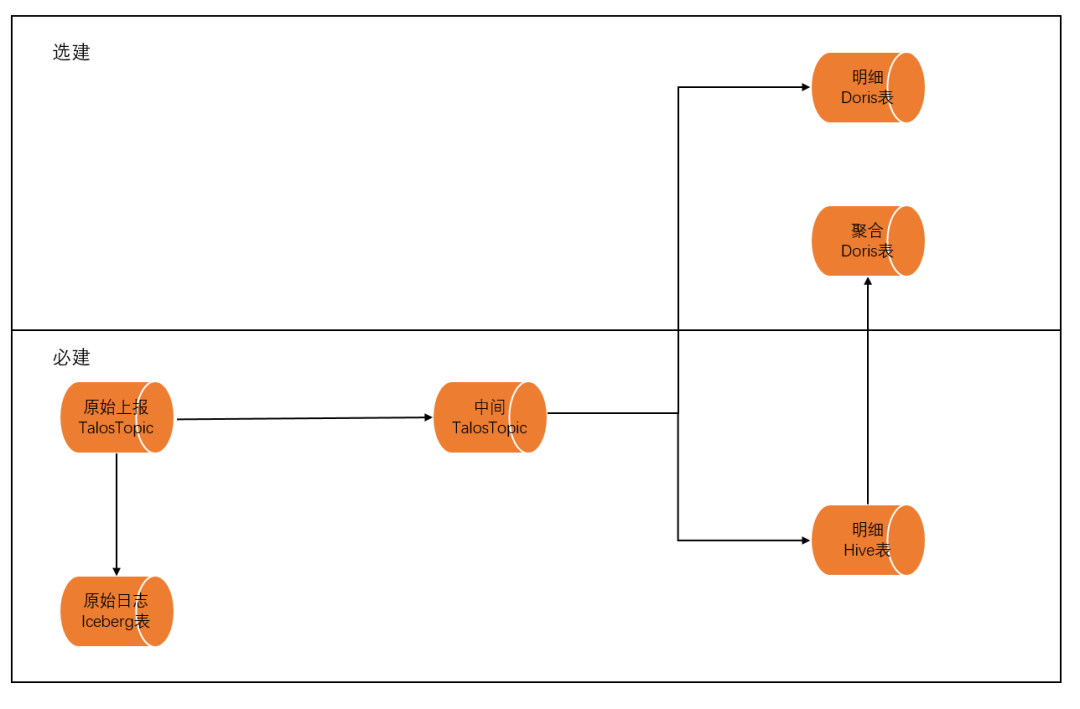
在小米的用户行为分析平台中,原始数据通过小米自研的消息队列 Talos,在 Flink 中清洗与建模后,被下游的 Doris 与 Hive 消费。全量的数据会存储在 Hive 中,进行批量 ETL 或历史数据召回的查询。实时增量数据被存储在 Doris 中,用来做热数据的查询操作。基于冷热数据分离的架构,我们进行了 3 次架构的演进。
第一阶段:基于明细宽表的查询
在最初的阶段我们使用了基于明细的宽表查询模式。为了处理灵活多样的分析请求,在系统中,我们配合统一埋点平台处理数据,接入的 OLAP 的数据是直接埋点的全字段展平。在入库之前,我们在 Flink 中将数据打平,以宽表的模式存储在 Doris 明细表中。根据查询的需求,我们将经常使用的列作为建表的维度列,利用前缀索引的特性进行查询加速。但某些头部大数据量业务容易查询多天数据,一个大查询可能就会将集群资源占满甚至导致集群不可用,且查询耗时相当之久。
第二阶段:基于聚合模型的查询加速
在改造的第二阶段,我们使用了聚合模型对业务查询进行加速。 我们对接入行为分析的应用进行统计分析,绝大多数接入行为分析的应用数据量在 1 亿/天数据量以内。对于部分使用频率较高的表,我们采用聚合表完成查询加速,对单天数据量超 10 亿且高频的头部应用做聚合表加速。具体流程为根据数据量挑选出头部应用,对其进行字段解析,并挑选出常用指标及维度,由 Hive 表数据进行聚合 T-1 产出数据,最后写入到 Doris 中,进行查询加速。该阶段的改造解决了集群头部业务大查询的问题,此时虽然独立集群存储没问题,但由于其他业务接入后还会持续增加数据量和埋点字段 ,这样会导致元数据最先进入瓶颈。
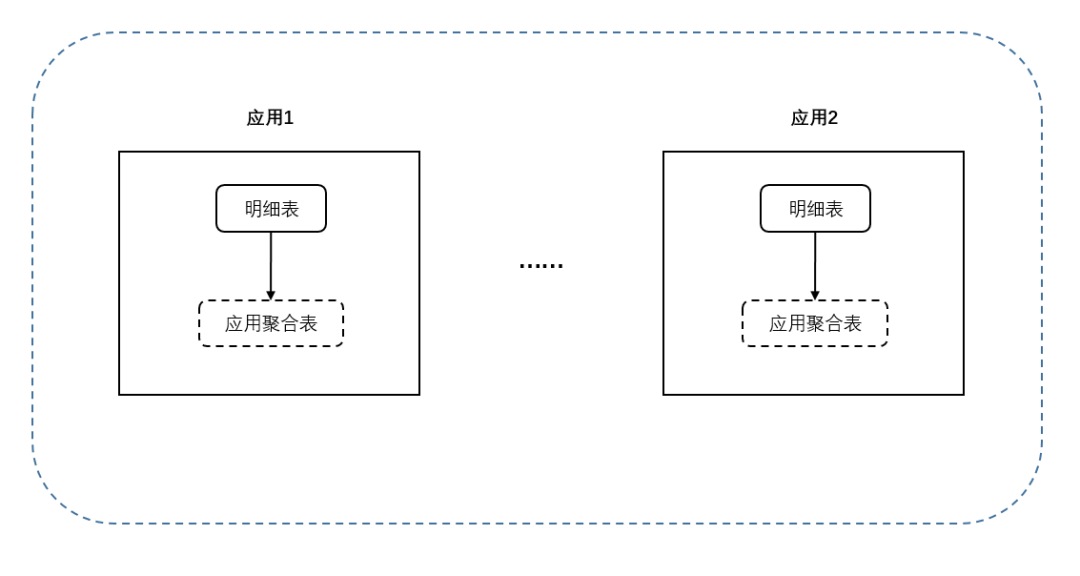
第三阶段(当前阶段):业务适配的建表改造
当前阶段,我们对业务需求进行深度解析后重新规划了建表结构。我们对某些应用的埋点字段进行分析,发现有些用户埋点字段多达 500+,但在行为分析里实际用到的可能只有 100+,这显然有所浪费。所以我们与用户沟通调研需求,配合行为分析平台侧的能力,用户可在平台对有用事件和属性进行筛选,同时设置字段映射和过滤逻辑,然后再进行建表。
查询服务架构:查询引擎的改造与演进
我们基于业务深度改造了查询的服务架构,构建了新的查询引擎架构,实现 SQL 的权重、路由、缓存和资源调度操作。根据查询条件,路由引擎会将 SQL 拆分成多条子查询,在 Doris 或 Hive 中执行后,将子查询的结果汇总,得到最终的结果。针对查询引擎,我们也进行了 3 次技术架构的改造。
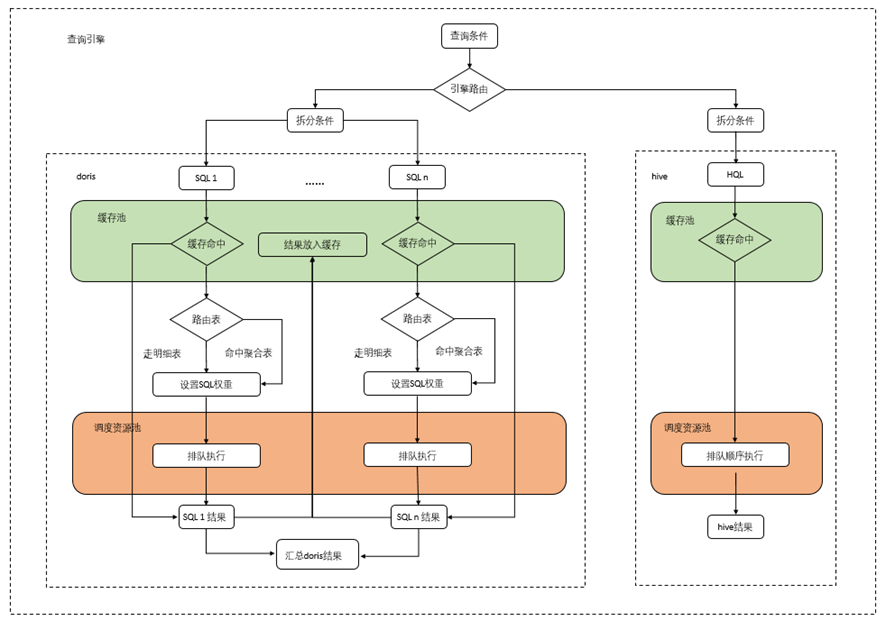
第一阶段:基于集群粒度的查询资源管理
我们对集群粒度进行查询资源管理,在资源调度中,我们会给每一个 Doris 集群设置一个总的资源池大小(根据集群能力和测试进行量化),根据数据量大小和查询天数对每个 SQL 进行加权,并对资源池的最大最小并行 SQL 数进行限制,如果计算的 SQL 超过限制则进行排队。其次,还会利用 Redis 对数据进行 SQL 级别缓存。
第二阶段:基于 SQL 路由的改造
为适配聚合表加速做了路由层,提升缓存命中率和利用率,此阶段拆分原始提交 SQL,基于指标进行缓存,粒度更细,服务端可根据指标进行适当计算更易于缓存命中。值得一提的是排队时间往往会比较长,有些场景下可能会进行重复提交或拆分成同样的 SQL,为了提高效率会在 SQL 排队前和排队后各进行一次缓存校验。
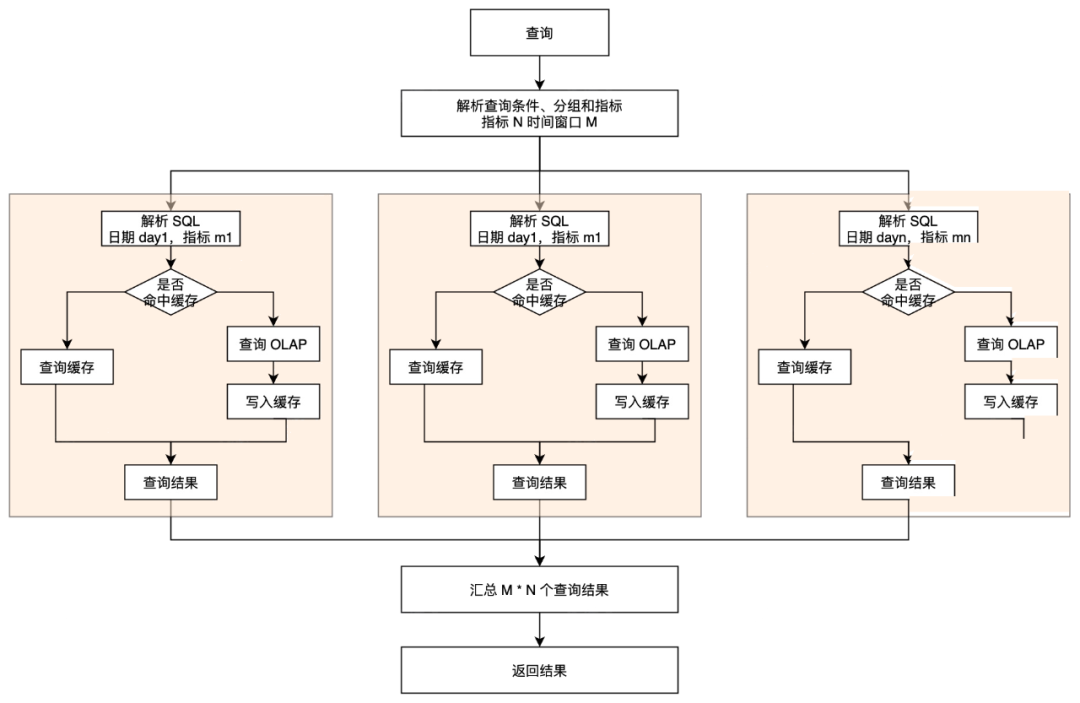
第三阶段(当前阶段):基于 SQL 权重的改造
整体架构方面,由于采取了筛选埋点字段而非全量字段导入 Doris,针对头部问题用户,我们会基于查询历史统计指标及维度,根据指定的某些规则进行默认初始化操作,并以此沟通用户并进行引导升级。此外为了更精细的控制资源调度,本阶段对对 SQL 内容进行加权,如含有DISTINCT,LIKE,VARIANCE_SAMP等字样再加权。对于资源消耗较大的操作,如 DISTINCT,会给予更高的权重,调度引擎在执行时会分配更多的资源。
实践应用
数据建模
对业务来讲,分析查询需要较高的灵活度,且是对用户粒度进行分析,所以需要保留较多的维度和指标,我们选用 Doris 作为存储查询引擎,且采用明细表建模,这样可以保证用户能够根据分析需求查出数据。另一方面,由于查询分析是一个延时要求较高的产品,对于数据量大、查询天数多、语句复杂的情况,查询延时会很高,所以对于头部应用,我们根据高频指标维度进行了聚合表模型建模。
数据导入
明细表部分,我们接入 Json 格式 TalosTopic,动态获取 Doris 表的 Schema 信息,通过双缓冲区循环攒批的方式,利用 StreamLoad 向 Doris 中写数据,如果在导入 Doris 时有出现失败的批次,重试 10 次仍然失败,会将数据按照应用粒度存入 HDFS,并在凌晨定时调度任务重新写入 T-1 未写入的数据。聚合表部分,我们由 Talos 落盘的 Iceberg 表,每日进行 T-1 数据的聚合,根据服务端选取的维度和指标,以及聚合类型(count ,count distinct , sum ,max ,min ),进行聚合存入中间 Hive 表,再由统一导入 Doris 程序进行导入。
数据管理
明细数据和应用聚合表分库存储,TTL 均为 33 天。数据表会有数据质量监控,如果总行数或者设置指标环比波动太大,会进行告警人工介入确认数据是否有误,视紧急程度进行回补处理。
数据查询及应用
绝大多数用户会锚定事件,进行含指标聚合,去重用户数(几乎占总查询的 50%)的事件行为分析,同时还会有留存分析,漏斗分析,分布分析等分析类型。
建表模型的维护
为了适配业务的变更,上游的埋点信息会周期性的更新。原有的表结构需要进行变更以适配埋点的增加。在过去的 Doris 版本中,Schema Change 是一项相对消耗较大的工作,需要对文件进行修改。在新版本中开启 Light Schema Change 功能后 , 对于增减列的操作不需要修改文件,只需要修改 FE 中的元数据,从而实现毫秒级的 Schame Change 操作。
应用现状
小米目前在 300 多个业务线上线了 Doris 集群,超过 1.5PB 的业务数据。在初期我们选择了两个使用较为频繁的集群进行向量化升级。
现迁移 Doris 向量化集群的行为分析业务有 2 个,7 天增量数据的平均值在百亿左右,存储空间占用 7T/天左右。在升级到向量化的版本后,存储资源有较大的节省,只需要原有集群约 2/3 的存储空间。


性能提升
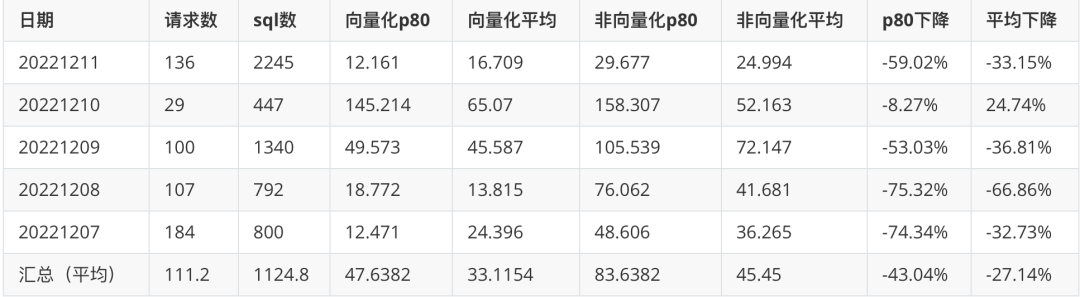
请求粒度
升级 Doris 向量化版本后,行为分析平台以请求粒度统计查询耗时 P80 和均值,P80 耗时下降 43% ,平均耗时下降 27% ;统计口径:汇总 12.07-12.11 期间,行为分析请求粒度查询执行时间。
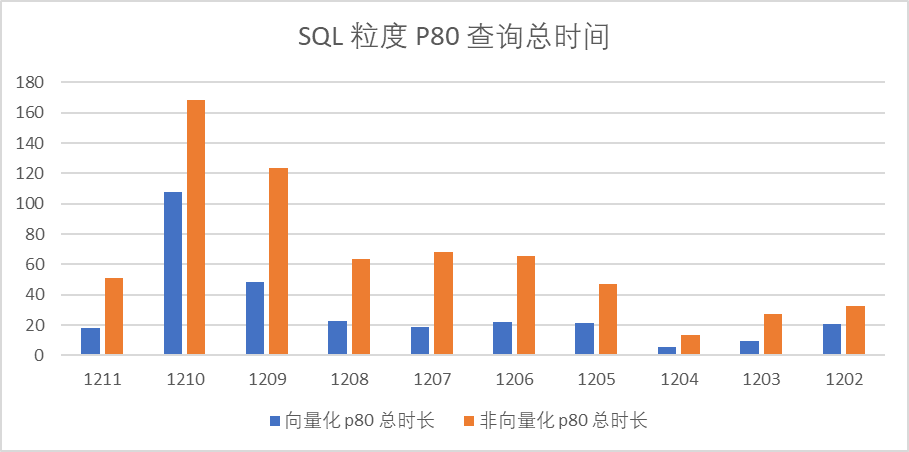
SQL 粒度
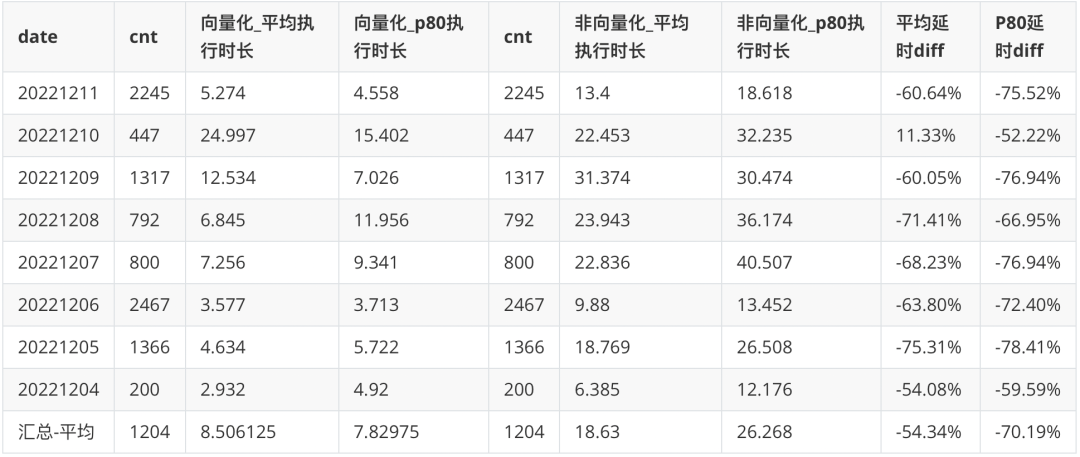
升级 Doris 向量化版本后,行为分析平台以 SQL 粒度来统计查询耗时 P80 和均值,耗时 P80 下降 70% ,平均耗时下降 54% 。统计口径:汇总 12.04-12.11 期间,行为分析 SQL 粒度查询执行时间(未含排队)
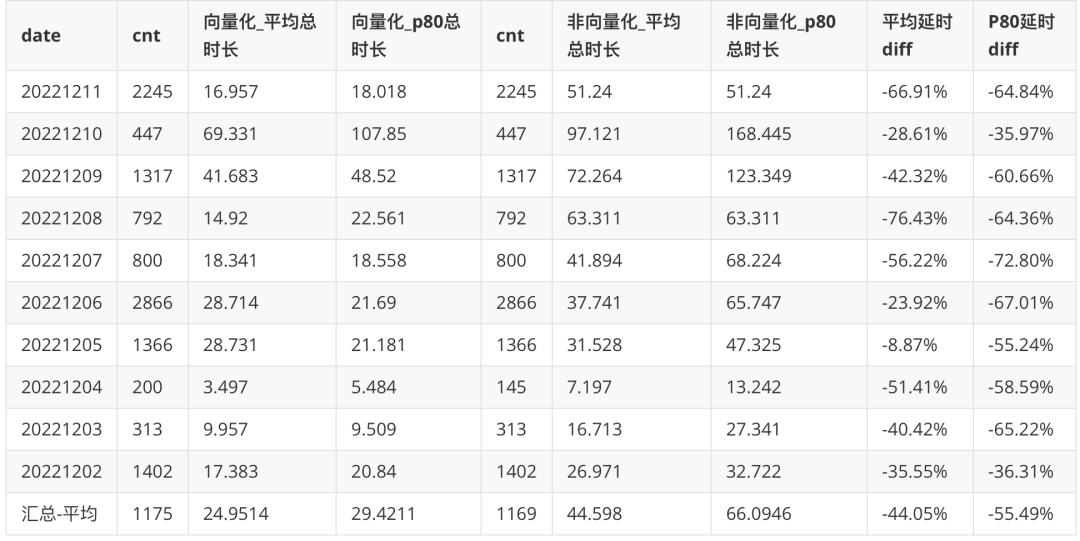
升级 Doris 向量化版本后,行为分析平台以 SQL 粒度统计查询耗时 P80 和均值,耗时 P80 下降 56% ,平均耗时下降 44% ;
统计口径:汇总 12.02-12.11,行为分析 SQL 粒度查询总时间 (含排队)
去重优化
在 ID-Mapping 的时候,通常需要针对 ID 进行去重操作。在最初我们使用了COUNT DISTINCT来完成去重。
在经过优化后,我们使用子查询+ GROUP BY来替代COUNT DISTINCT的功能
相较于原有的COUNT DISTINCT,使用子查询+ GROUP BY 的模式性能有 1/3 的提升。
未来规划
在过去的三年时间里,Apache Doris 已经在小米内部得到了广泛的应用,支持了集团数据看板、广告投放/广告 BI、新零售、用户行为分析、A/B 实验平台、天星数科、小米有品、用户画像、小米造车等小米内部数十个业务,并且在小米内部形成了一套以 Apache Doris 为核心的数据生态 。随着业务的持续增长,未来我们会进一步推动小米的其他业务上线向量化版本。
非常感谢 Apache Doris 社区与 SelectDB 公司的鼎力支持,小米集团作为 Apache Doris 最早期的用户之一,一直深度参与社区建设,参与 Apache Doris 的稳定性打磨,未来我们也会密切联系社区,为社区贡献更多的力量。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论