
几个月前,我接到一个任务,要拿出一个 _ 集中式的事件系统 _,可以让我们的各种后端组件相互通信。我们讨论了后端活动流、渲染、数据转换、建筑信息模型(BIM)、个性身份(identity)、日志报表、分析等等。找寻其中是否有真正通用的可变负载、使用模式和扩展性配置。或许是其他的某样东西,能使我们的开发团队轻松接口。当然,系统的每个部分都应该具备 _ 自我扩展 _ 的能力。
由于我没有时间写太多的代码,所以我选择了 Kafka 作为我们的存储核心,因为它稳定且被广泛使用,而且表现良好(请注意,我没有说非得用它不可,可以用其他东西替代)。当然,现在我还不能直接将 Kafka 暴露出去,得在前端用一些 API 去实现这些。没想太多,我就放弃了在我的后端管理偏移量的想法,因为这在为实例处理失败时,会给人带来太多的约束。
所以我的结论就是,将系统分为独立的两层:第一层是 API 层,负责处理请求流(incoming traffic);第二层是后端层,负责处理长期的、有状态的、与 Kafka 交互的流处理进程(比如,实现生产者和消费者)。这两层都可以独立扩展,只要求它们之间保持一致的路由,以保证客户端可以与相同的后端流处理进程,保持通信。
两层代码均 100% 使用Scala实现,并使用 Play! 框架。同时,它们重度依赖Akka actor 系统(每个节点通常跑数百个 actor)。后端层实现了一组自定义的 Kafka 生产者和消费者,并使用一组专用的 actor 来管理预读与写缓冲区。一切都被实现为嵌套的有限状态机(我超爱这个概念)。分析数据存储到Splunk,同时,度量数据存储到Librato(collectd 是在容器中运行的)。
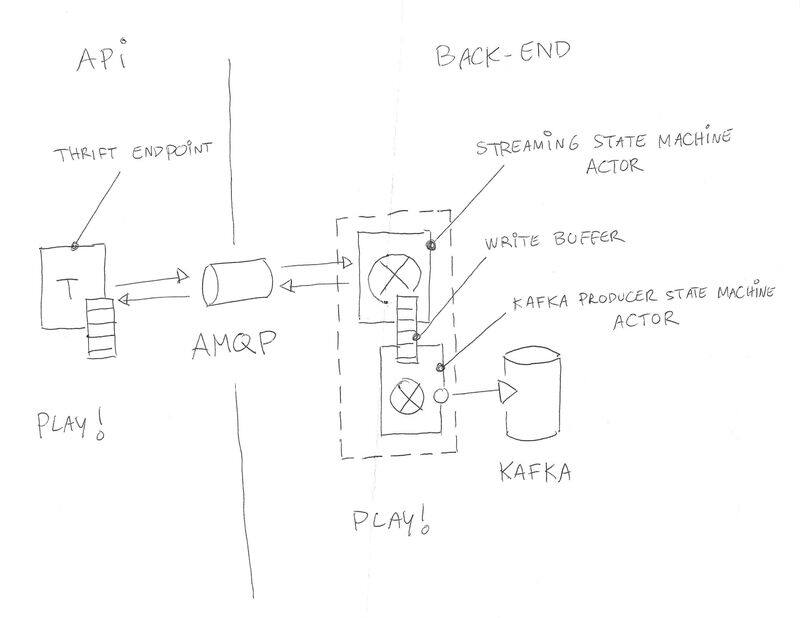
在此,哥文艺地展示下系统发布后的模样
如何实现两层之间的路由呢?只需使用 RabbitMQ 即可,它有很好的持久性和弹性,甚至没什么趣味可言。AMQP 队列是实现这一简单的“电话交换机”模式的伟大方法。通过使用一些逻辑分片技术(比如对一些存在于每个事务中的 cookie 值进行散列或者类似的技术)将一组固定的后端节点关联到某个 RabbitMQ broker,就能够让路由支持扩展,这简直是小事一桩。
为什么我没有对 RabbitMQ 的 broker 做集群?哇哦,我能说我懒吗,关键是我真心觉得没啥必要。在每个 broker 之间分流实际上是为了高效,而在我看来,更重要的是以更轻松的方式去控制。为此付出的额外工作相比收成毫无意义。
所以,总之,给定容器拓扑,我们的请求会保持一条特定路径,这条路径依赖于后端节点所处理的流会话。我们所需的每一层可独立扩展远比整体可扩展重要。唯一的实际限制将是虚拟网络适配器和带宽。
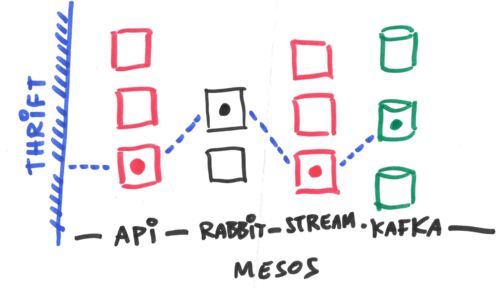
虚线表示给定的会话将保持的特定路径。
现在,我们开始有意思的部分吧:如何确保可靠的通信,避免拜占庭式的失败呢?我要说,这非常简单,只需使用简单的两阶段提交协议,在客户端和后端同时建立状态机镜像模型(例如,他们总是同步的)。读写操作需要显式的确认请求。当你尝试读取并且失败的时候,你只需重新尝试,直到获得确认,然后这个确认将改变后端的状态(比如,向前移动 Kafka 的偏移量或者下发定时任务将事件发布)。所以我的客户端和后端之间的传输流实际上是这样的:“allocate session”、“read”、“ack”、“read”、“ack”…“dispose”。
这一系统的巨大优势是有效地实现了操作幂等,而且没有任何烦人的声明语句,就可以编码状态机中的所有逻辑(我告诫自己:我要提供一个纯粹的功能实现,没别的,只为了炫技)。应对任何网络故障,当然是优雅地重新尝试。通过这种方式,还可以得到自由的控制流和背压技术。
这个系统的 API 会暴露为 Apache Thrift (当前通过 HTTPS 协议使用压缩技术工作,计划在某个时间点迁移到普通的 TCP 层)。我提供了 Python、Scala、.NET 和 Ruby 语言的客户端 SDK,以应对我们在 Autodesk 所使用的、花样百出的技术)。请注意,Kafka 偏移量是由客户端管理的(虽然这样不透明),这使得后端控制更简单。
稍等,我听见你说,如何处理后端节点宕掉的情况?哇哦,因为我们有两阶段协议,所以我们在读取数据的时候并不会真的获取:如果客户端不断地失败,将使用当前的偏移量,重新分配一个新的流会话。当向 Kafka 写入数据时,麻烦来了,因为这个过程是异步并且潜在地受下行流背压(比如你的节点失败了并且 Kafka broker 也出现问题了)。我会将后端节点配置为正常关机,在等待任何写挂起时,传入的任何请求都会快速失败。最后一招,我们甚至可以将任何待处理的数据刷新到磁盘上(之后,重新将数据注入)。
稍等,我听见你又说,如果基础设施的一部分挂掉会怎样?同样的。与流会话处理的实际后端节点之间的通信中断,当然会慢下来,但不会再有什么讨厌的影响,这又要归功于两阶段协议喽。
哦,我忘了说,在将数据写入 Kafka 日志前是自动加密的(使用 AES 256)。Kafka 的生产者和消费者使用同一套密钥共享。在涉密的主题上,我可以让流会话通过 OAUTH2 来验证,对每个请求验证 MD5-HMAC,走 TLS 到后端集群。
现在你又问,那么,我们如何完整地部署这个时尚最时尚的系统呢?嗯,我们将整套系统 100% 地运行在一个普通的 Mesos/Marathon 集群上(现在用的不是 DCOS 哦,但我们可以切过去,因为这样可以用上他们超赞的仪表盘)。集群托管在 AWS EC2 上,我们基本上整体复用了一些 c3.2xlarge 实例(在给定的区域内,10 到 20 个小型部署足够了)。请注意,我们可以在 Kubernetes 上(无论是 EC2 还是 GCE)做同样的事情。
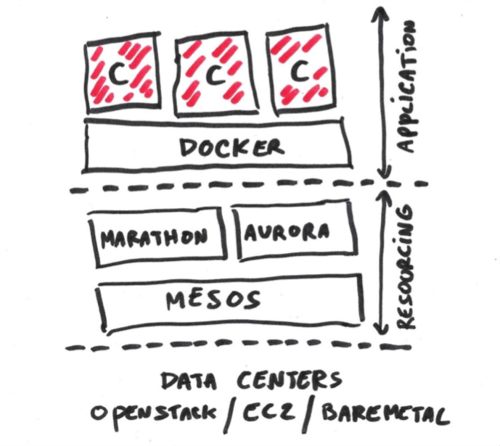
小秀一下我们技术栈的结构
每处部署都使用了我们的开源技术 Ochopod (自集群容器)。操作被降低到绝对最小值。例如,我们要做一次优雅的构建推送,就拿 API 层来说,无非是分配一些新的容器,等待他们启动好,然后逐步替换旧部署,这样就可以了。所有这一切都是通过集群中的一个专用的 Jenkins slave(它本身也是一个 Ochopod 容器)完成的!
实际上,我开发了一个叫 Ochothon 的迷你 PaaS 系统,只是为了能够快速开发 / 运维所有的容器。
(点击放大图像)

Ochothon CLI 显示了我的一个预发布集群的情况
为了能让你感受 Ocho-* 平台是多么好用,我这样说吧,一个人(比如我)就能够管理跨 2 个区域的 5 个部署系统,包括所有的基础设施副本……此外,还能有时间写写博客、码码程序!
所以,总体来说,此间的设计和编码,整件事情都充满乐趣,再加上它现在已经在生产运行,是我们云基础架构任务的关键部分(这是一个还不错的打赏)。如果你想对这个奇葩的流系统有更多的了解,告诉我们哦!
相关文章
- Deploying our eventing infrastructure over Mesos/Marathon & Ochothon !
- Ochopod + Kubernetes = Ochonetes
- Return of the finite state machine!
查看英文原文: How Autodesk Implemented Scalable Eventing Over Mesos
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论