


大家好,我是 Johann Schleier-Smith,今天我非常期待向你们分享 Serverless 计算以及我关于 Serverless 对云计算未来影响的看法 —— 它的影响将非常深远。

首先,我将从一个简短的自我介绍开始,包括我的背景、我的经验以及 Serverless 计算相关的工作。然后,我将深入讲解,Serverless 计算从何而来,其中体现了哪些核心概念和理念?我将会从有点学术的角度来讲,但我真的希望你能从中学到一些东西。随后,我将讨论当前的一些研究趋势,最后是总结。
首先,简单介绍一下我自己。在相当长的时间里我都是一名企业家,我曾在硅谷的社交网络行业工作。我从 2003 年开始,就在想办法解决注册用户的使用产品的各种问题,以及在非常竞争激烈的环境中,保持高可用性,保持快速创新步伐。我曾经是 Tagged 的创始人兼 CTO。后来,我们收购了一家名为 hi5 的公司,合并成了一家公司。最后,公司被一家上市公司 Meet 集团收购。在我多年从业经历中面临如此多的挑战,让我真的很想从更根本的层面深入探究。
于是,我转向了学术领域,目前我在加州大学伯克利分校从事机器学习博士项目的研究。
在 riselib 从事研究,是一个非常棒的机会,可以和很多非常棒的人一起工作,向他们学习。

所以,我今天要讲述的内容,很大程度上受到了很多的合作伙伴的影响。我们已经发表了一些论文,我推荐大家去看看这里展示的作品,你可以读到更多的信息。有很多人对此领域做出贡献,例如 Ion Stoica、Joseph Hellerstein、Joseph Gonzalez、Rocha Popa (音译)等优秀的教员。
我想说,今天我将代表我自己的立场来分享。也就是说,我可能会说一些有争议的话题,我将会为自己的观点负责。我也要感谢 riselib 的赞助商,riselib 的研究是通过政府和企业资助实现的。
Now Serverless .
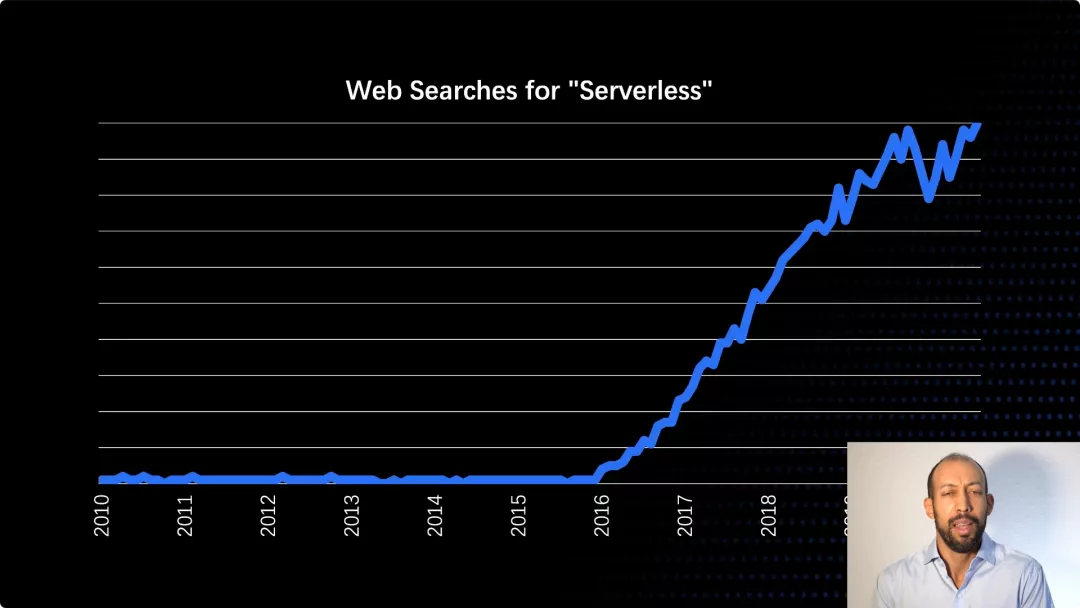
Serverless 广受关注,这张图表展示了人们对它的兴趣有多大,增长的速度有多快 —— 这是人们在 Google 上搜索 Serverless 次数的变化趋势。你可以看到,自从 AWS lambda 在 2015 年面世以来,出现了飞快的增长。当你看到这些图表时,可能你会说,这里一定发生了一些非常有趣的事情,让我更多地了解一下为什么会这样。

在 Serverless 产品方面,我想你可能有了一些了解。比如腾讯云已经提供的 FaaS 产品服务,Serverless 云函数(SCF)。这些产品允许你在云中运行代码和计算任务,而不需要考虑基础架构,也不需要考虑运维,这确实是促使人们对 Serverless 感兴趣的原因。稍后我会详细介绍这一点,但我想强调一下, Serverless 不仅仅与计算有关,还有 Serverless 存储,例如腾讯的云对象存储(COS),还有 Serverless 数据库服务,比如 TcaplusDB。

Serverless 的共性,是你使用它的方式 —— 这正是我喜欢它的地方。
你编写代码时,你可以选择任何你喜欢的编程语言。然后你将代码上传到云,接下来你会说:“云服务商,请去运行这个代码”。在这之后,一切都正常运行了。
运维方面的事情也为你安排好了。如果需要更多的底层基础设施容量,那么它将自动为你扩容,反之也会自动缩容。假如发生任何故障,也会很快得到解决。
你唯一需要关心的问题,是实际使用了多少资源,云服务商为你分配了多少计算和存储,以满足您的服务和产品 —— 而这就是你的付费方式,超级简单、实用的按用量计费方式。

这简直不要太美好 —— 所以我们认为,Serverless Land 是个神奇的地方,到处都是你能吃到的糖果,到处都是彩虹和独角兽,可真棒啊!

但是我想你一定要问的是:这么美好的东西可能是真的吗?

事实上,会存在一些捣蛋的“怪兽”,Serverless 也会遇到各种各样的挑战。这些是对 Serverless 计算的一些常见反对观点:
有一些人说,你所运行云函数它们实际上是无状态的,所以当你的程序运行结束时,数据就会被清除;还有一些人抱怨它有点贵;还有反对的观点说这可能造成效率降低,因为你正在将计算和状态分开;另一个挑战的点是,有时会被认为缺乏对 GPU 等硬件加速器的支持;还有人会说,我搞的这些应用程序,他们都无法使用 Serverless 的方式运行;还有人说,也许 Serverless 听起来很简单,但实际落地起来却很困难。
如果从学术界的角度,我可以给你们一些成果的展示,几乎所有这些反对观点描述的问题,都取得了重大进展。但仍有一个还在坚持 ... Serverless 这个名字不好。

对于这个名字有一些普遍的反对意见。
“服务器还在那里,你怎么能称它为无服务器呢?”
“另一个问题是,如果没有服务器,那有什么呢?”
这听起来不像是用词不当吗?既然如此,人们为什么还要这么命名它呢。但我要告诉你,这实际上非常重要。

还有人可能会说,为什么不给它起个别的名字?
比如就叫它云函数吧?我想说,它不仅仅是云函数;或者称之为托管服务?这概念已经有很长一段时间了;云原生?是另外一个很好的新名词,也许我们应该称之为超级自动伸缩。
随便叫什么,你可以给 serverless 想出各种各样的其他名字来。

现在我的观点是,Serverless 其实是一个很有意义的名字,最关键的点是你没有服务器。
它描述了云计算目前正在发生的最关键的事情,这一巨大的变迁即将到来。如果我们理解为什么这是一个好名字,我们就会理解趋势,也会理解云计算的发展方向。

我们开始下一节,Why Serverless?

我要带你们回到大概 2,400 年前,这是伟大的哲学家亚里士多德所在的希腊时代,哲学家们倾向于深入思考事物,一些观念在归纳总结后仍与当今社会十分相关。

让我来问你这是什么?
你可以说它是一把椅子,或一把红色椅子。如果请你稍微描述一下?你会说它是圆的,你会看到一个圆圈有四条腿,也许是用木头做的。好的,你已经告诉了我很多关于那个东西的属性。现在我可以问:关于你的描述的物体,它的本质属性是什么呢?
所以在这个问题下,我们可以说:它们的表面是平坦的,适合坐着。这就是它真正成为凳子的原因。当然它还有很多偶然属性——它是红色的、它有座椅、椅腿、它的材质等等,这些都不是本质属性。

一把凳子可能有不同的属性。我们可以看到我这里有很多例子,很多不同类型的凳子,有些有三条腿,有些只有一条腿。但它们都是凳子,它们有相同的用途和功能,但它们的工作机制各不相同。所以你可以看到每个凳子,本质属性都被保留了下来,而那些偶然属性则有所不同。

现在,请允许我再讲解得深入些 —— 我保证这些都跟计算机领域相关。
请看这是什么,这是一座桥梁。它是一座横跨溪流的桥梁,它有相当多的属性。这是架在水上的干燥路面,它连接着两岸上面铺装了原木,它有四根支撑,两端都有斜坡,中间的部分很平整。这些是用来创造桥梁的技术,你明白它的作用是什么,连接河岸两端的能力也有很多属性。

我们再看一座桥的不同案例,可能是一套不同的造桥技术,我们会发现有一套不同的属性来实现这座桥。

继续下一个案例,这个是悬挂绳子的桥梁。它不是平坦的,它有点下沉,它由岸上的四根柱子支撑着。

再看看这座桥。这个桥在中间稍高了一些,有这十根柱子连接上下导轨。这个可能是金属做的,所以它采用了不同的技术,但归根结底都是一样的,它们都提供的了桥的功能。

如果我们仔细研究每个问题,就需要研究哪些属性是本质的,哪些属性是偶然的,我们可以继续探究一下。

我们把它们都列出来,可以看到在屏幕上所有属性放在一起:哇,这是多么难懂的一团乱七八糟的东西!接下来,我们把所有偶然属性都拿走,把重点放在提供一座桥梁的本质属性上。就像你现在看到的,一切都变得简单得多。记住,这是理解 Serverless 计算的关键,这要求我们要排除大量的偶然复杂度。

云计算工作方式的实质,让我们专注于应用程序中最本质的部分——核心业务逻辑,这是每个应用中必不可少的、差异化的部分。所以你看着那台服务器,你可能会问:服务器是云计算的本质属性,还是偶然属性?

为了让大家更好的理解,我将再次倒转时光,不是回到几千年前,而是回到 1967 年。这是 IBM System 360 大型计算机,它是一台非常令人印象深刻的机器。当时为这些机器写的代码,如今仍在很多公司运行。

它是一个大型计算机,意味着是一个支持许多用户的集中式资源。在 1960 年代,这是一项巨大的进步,能够真正有效地将公司一台大型计算机的资源和时间进行共享,分配给各个团队使用。现在你看到这个大型计算机,实际上会意识到,在 20 世纪 60 年代,在这些大型计算机上正在实现的许多东西,与我们今天在云计算和 Serverless 计算中追求的价值非常相似。

Fred Brooks 是 System 360 的主要领导者之一,他领导了操作系统和许多硬件团队,后来他成为一位非常杰出的教授和图灵奖获得者。1980 年代后期,他撰写了开创性的文章,在其中他区分了计算机程序的复杂度,并且提出了与你的应用业务有关的是本质复杂度。也许业务本质复杂度是很有限的,但是计算机带来了复杂度,这就是业务功能的技术实现细节。就像那座桥,取决于我们用的是绳子、钢材还是木头,我们会有很多不同的技术实现细节。这些技术细节实际上非常重要,正是因为这些技术让事情变得可行,但它们与你应用程序的业务逻辑并没有关系,与解决方案的最终结果也无关。
在我所目睹的技术里,使用汇编语言编写程序的过程中,就有太多的偶然复杂度。而现在的高级编程语言已经变得如此之好,以至于可以使用它们做任何的事情。这样对于我们可以用计算机做什么来说,这是一次巨大的变革。
本质复杂度和偶然复杂度的理论,真的是一种伟大的见解,是我们从几千年前哲学家得到的启发,最近几十年里确实是具有非凡的意义。

为了更深入地了解这一点,再了解几种通常与 System 360 一起使用的编程语言。Fortran 用于数值计算,Cobol 用于商业应用程序,PL/1 作为一种通用的编程语言。而对于那些真正需要高性能的应用程序,需要通过 System 360 汇编语言实现。

我想,任何一个曾经使用过各种不同语言和系统的人都会很熟悉这种权衡,一方面是编程的体验,另一方面是性能和开销。

在此我想展开讲一下,给你们一个具体的例子,以便对 System 360 有更清晰的认识。这是校验信用卡号码的 Luhn 算法,一个简单但古老的算法。如果想要查看该信用卡号码是否有效,可以采用一个简单的方法 —— 实际就是一种校验和。从卡号的末尾开始偶数位都乘以 2,如果结果是大于 10 的数字,则将个位和十位相加即得到一位数字,把所有数字相加得到总和。如果可以被 10 整除,就是一张有效的信用卡。超级简单的算法,对吧?

事实上,如果我们使用像 PL/1 这样的编程语言。这代码看起来可能你们大多数人都不认识,当你看到它,可能你会说这可能是 2020 年最新最伟大的新语言,就这么简单。右读一些输入,得到该数字,颠倒它,然后对奇数位和求和,然后对一些偶数和求和,并根据需要执行判断逻辑,看看它是否被 10 整除,如果是则通过测试,否则就不通过。这个很十分简单。

现在让我们来看一下汇编语言实现。代码去掉了注释 —— 即使注释在其中,也真的很难分析。我花了一些时间来分析,了解这段程序在做什么。我会省去大部分的细节,会给你们一个高度概括的介绍。
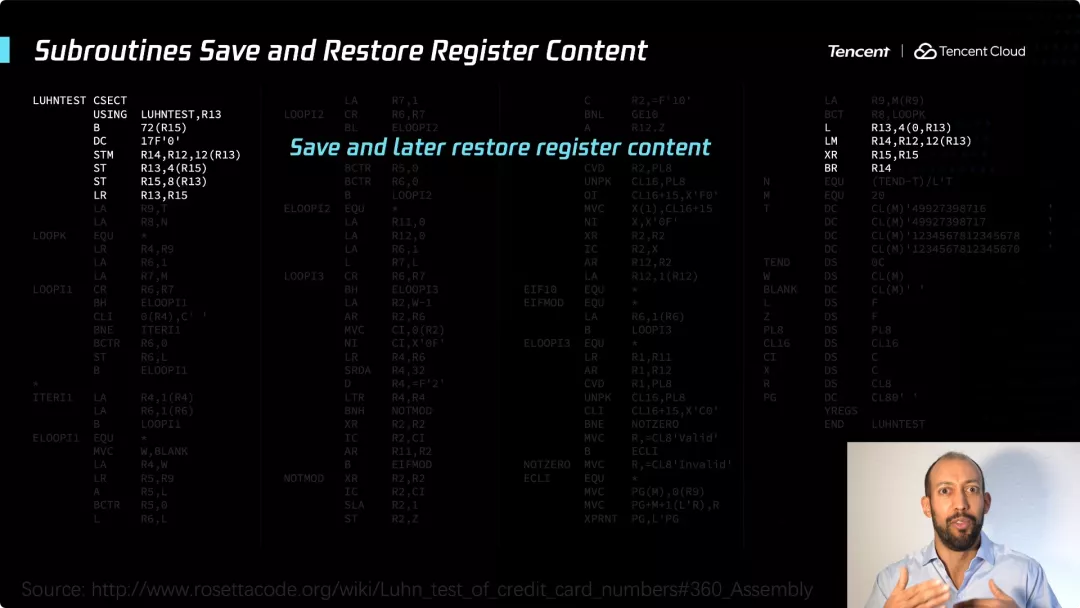
此处从寄存器的操作开始。什么是寄存器呢?我们知道在 CPU 内部有固定数量的存储单元,这些存储单元用于基本操作、算术运算、访问内存单元、加载和存储等。如果你准备编程,必须弄清楚你要如何使用这些寄存器。这只是复杂度的一部分,你还必须在编程时考虑,如何确保你空间足够使用。这些操作与计算信用卡号码的校验和无关,这只是当你用汇编语言编程时,必须要发生的一些工作。

这是字符串长度。你会注意到,上面没有名字,没有卡号,以及诸如此类的东西。它只是一堆寄存器,你必须跟踪你的程序中交叉引用,你还必须做出决定将使用哪个寄存器来计算字符串的内存地址,并将字符串所有内容存储在那个内存地址。

反转字符串也是类似操作。

我不会再深入讨论了,这是一堆详细的指令、逻辑和判断,和你要做的事情没有任何关系。

通过这个高度概述的介绍,不难发现用汇编语言的代码要比 PL/ 1 长得多,寄存器名称也不含什么信息,直接暴露了这台机器的很多工作原理。
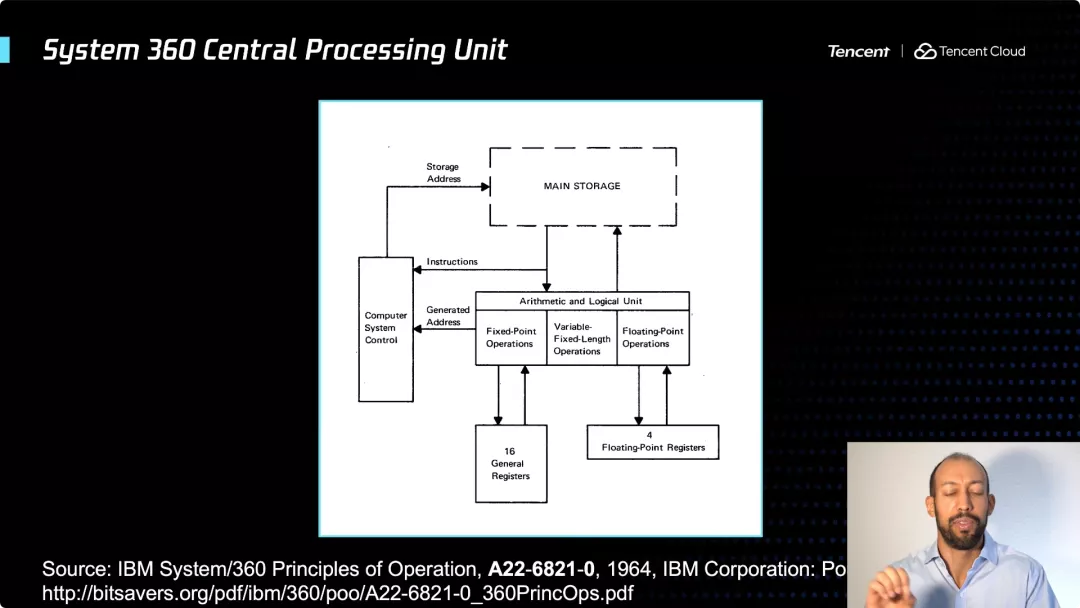
这是那台机器的示意图,有浮点寄存器、定点寄存器、16 位通用寄存器,需要对特定内存单元、特定存储地址进行读写操作。我并不是对汇编持完全否定的态度,汇编语言编程的好处是,你可以用很少的资源获得非常好的性能。

这是 Margaret Hamilton 的照片,还有一堆阿波罗制导计算机的汇编语言代码的打印件,我认为这真的是个很酷的东西。她是该项目的首席软件开发人员,在 1969 年编写了火箭载着宇航员导航到月球的程序,使用的技术比我们今天要原始得多。

这是一张阿波罗制导计算机的照片,它的运行频率是 2MHz,可能比你今天拥有的最慢的计算机或手机慢一千倍。不仅如此,这里还有一件非常有意思的事——资源是如此的有限!真的,这导致用汇编语言编程的人们需要详细地思考,如何去使用这 2,048 个字节的内存,这就是你能使用的全部内存,需要以非常谨慎地使用内存的每一个字节。记住,我们要去月球的时候,火箭上有一百五十种不同的装置需要去控制,而我们只需要使用这么一点点内存就可以做到。

汇编语言编程需要考虑的事情,包括如何使用每个寄存器?如何安排内存中的数据?如果我要切换程序,我该怎么做?等等。

现在我们来到 2020 年,当你想到云计算的时候,您会遇到很多类似的问题!
那么,我应该如何使用每一个服务器呢? 我需要多大的一个服务器实例?如何知道何时需要分配更多服务器?其中一个服务器是否出现故障时,我该如何应对这种情况?即便我知道需要备份我的数据,但是我应该备份多少次?如何保证数据的一致性?
所以这些都是挑战,真正的挑战,艰难的挑战,它们与你正在交付的应用程序没有任何关系。

那么汇编语言的复杂度,是如何解决的呢?解决办法其实很简单,编译器会做生成机器代码的工作。编译器是如此出色,以至基本没人再需要使用汇编语言进行编程,除非是非常特殊应用程序。我认为依赖服务器的编程,就是当今的汇编语言编程。

为了说的更加具体,我就像这样对比一下。用汇编语言编程,要处理寄存器的名称,要处理特定的内存单元和地址。当你使用高级编程语言时,这些东西就消失了对吗?你永远也看不到寄存器,编译器会完全处理它,将其隐藏起来,包括内存地址。在一些不那么高级的语言 (如 C 语言) 中你还会看到这些。但可以肯定的是,一旦你使用了像 Java 这样的语言,内存地址就完全消失了。如果谈及云服务,也会有服务器地址,我的观点是这不属于云,它将消失!

所以我的观点是,Serverless 是一个精确的命名,它表明了当今基于云编程的问题所在,暴露在编程模型中的服务器,就像暴露寄存器或特定内存单元一样有问题。
现在最关键的是将过去对我们有效控制编程复杂度的方法,应用到云服务中,将它们应用于消除服务器、固定地点、固定资源、固定地址,改变我们基于云编程的方式。

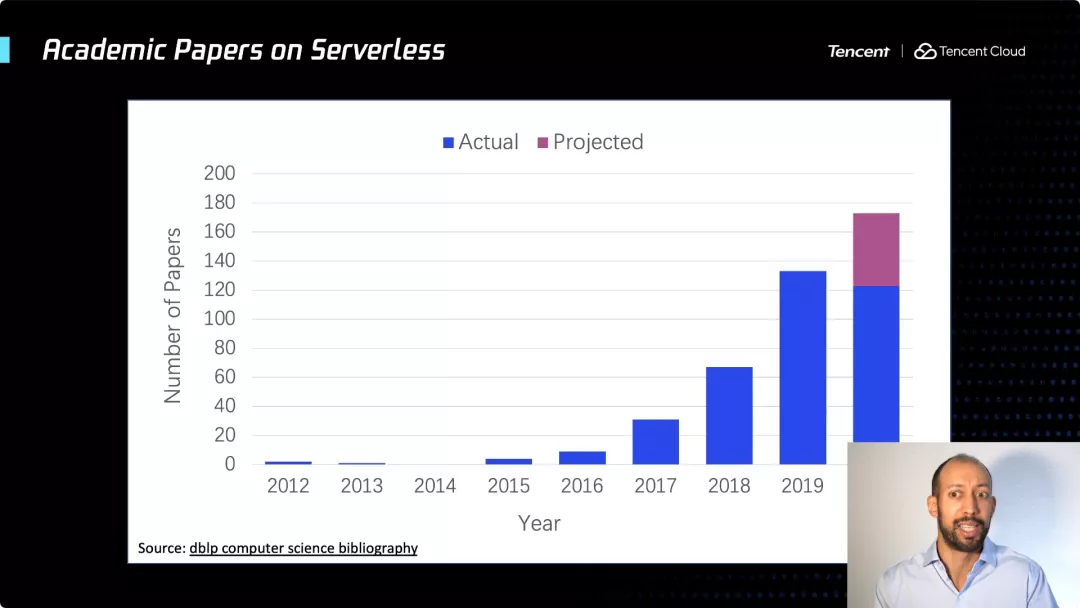
接下来,我想对目前的一些研究做一个简要的概述。我会偏向伯克利分校的视角,目前整个学术界都在进行 Serverless 研究,并且一直在加速发展。

让我们来逐一过一下已经完成的一些工作吧, 来针对性的解决这些对 Serverless 的反对观点。至于名字不好这件事,我们已经聊过了,不再多说。
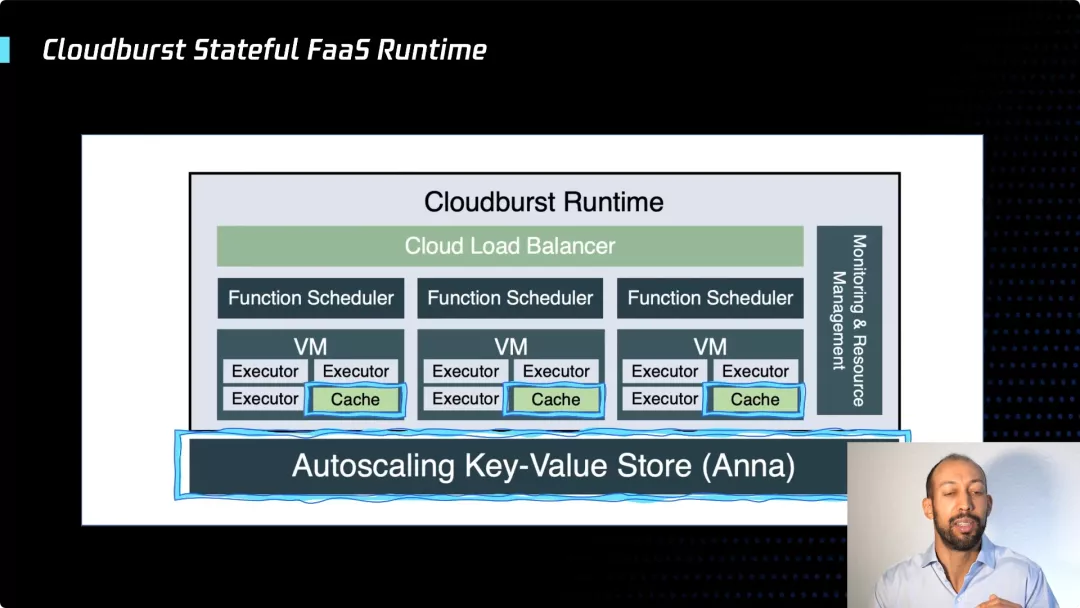
第一个是无状态计算的限制。在伯克利我们开发了一个名为 cloudburst 的系统,它将高性能 K-V 存储与 FaaS 运行时集成在一起,允许数据缓存与主机放在一起,在 Serverless 的环境中实现了高性能计算。

还有其他的反对意见认为, Serverless 太贵,或效率低下。
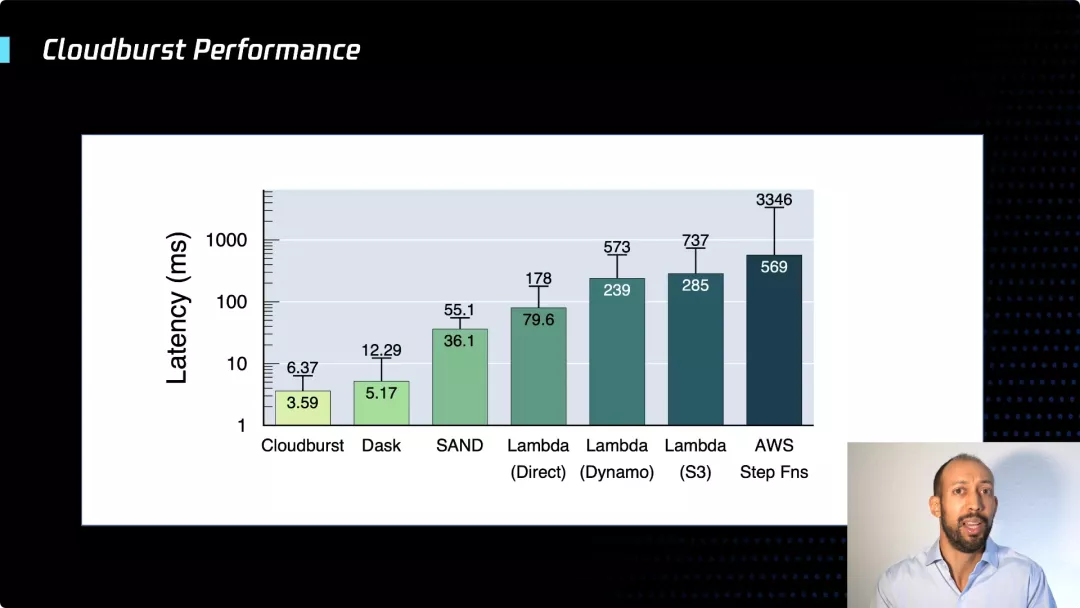
如你所见,CloudBurst 解决了延迟,这里我们对比了一个函数调用另一个函数的场景,只是进行一系列简单的操作。我们看到与目前公共云的相比,这里的延迟大大减少了。

我们还在努力将 GPU 等硬件加速集成到 Serverless 计算中,这实际上非常有意思,因为可以想出不同的方法来做到这一点。
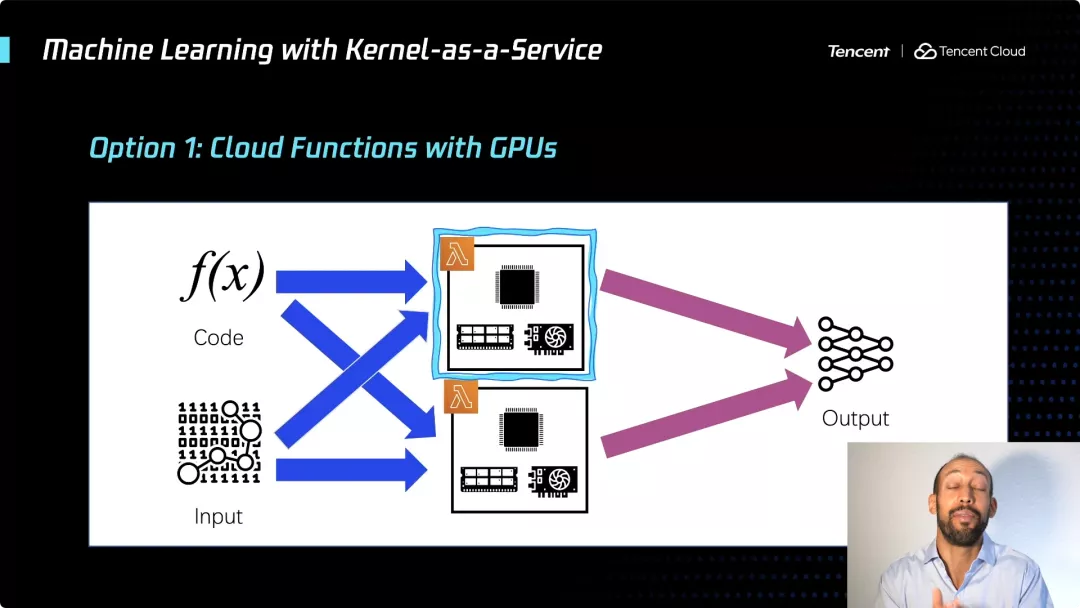
例如,一种选择是让每个云函数都附带一个 GPU。所以如果你有很多云函数在运行,你会得到很多的 GPU 和 CPU。

另一种选择是将计算单元进行拆分,这样你就可以有一个 GPU-only 的函数(或许也用到一点 CPU),这样在扩展该资源方面会获得更大的灵活性。你可以独立于 CPU 资源和内存资源,来扩展 GPU 资源,这也是我们一直在研究的。另外,在传输数据等方面也存在一些挑战,但这是一个非常令人兴奋的研究领域。

对 Serverless 的另一个反对意见是:人们会说,它不支持我现有的一些应用程序,比如一些遗留应用程序。

例如,直到最近还没有共享文件系统的支持,没有 FaaSFS 这样的文件系统可以与云函数一起使用。AWS 已在几个月前发布了一款产品,但与传统本地文件系统相比,在性能方面还存在一些瓶颈。
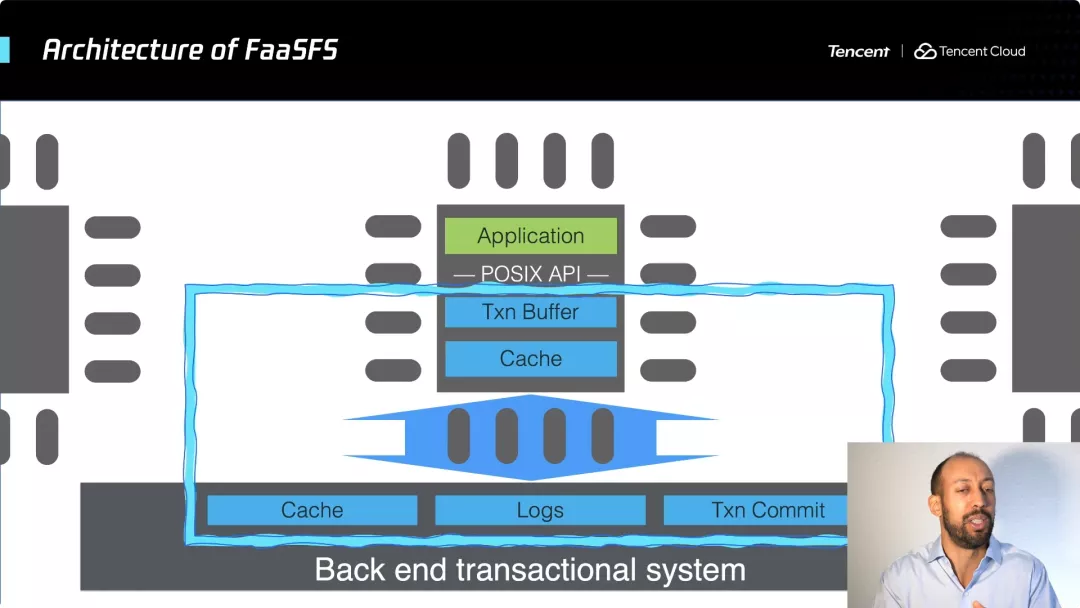
为了解决这个问题,我们构建了一个共享文件系统,称之为 FaaSFS 。提供了集成事务机制的缓存,能够确保数据非常靠近算力,可以非常快地访问,并且保持了数据的全局一致性。

最后,人们有时会有的另一种抱怨:Serverless 听起来很简单,但实践起来却很难。

我只想回到我之前提出的论点,也就是说,在过去的五六十年里,我们有大量的复杂度计算。可以看到在语言领域已经发生了很多事情,产生了巨大的变化,例如一些编译工具。对于云计算来讲,现在还为时尚早,伯克利的人们已经在此领域开展了很多基础性的工作,我非常兴奋能在我们前进的过程中与他们一起工作。


虽然对 Serverless 计算仍有不少反对声音。我不会说我今天在这里已经解决了所有这些问题,但我要说的是,这些问题正在一个接一个的被解决。学术界和人力资源行业的研究人员,都在非常积极地攻克几乎所有的障碍。所以我们对 Serverless 计算很有信心,这个梦想真的可以应用于广泛的应用程序中。我们所有人很快就能真正享受到这一点。

Serverless 计算的本质是:云计算的 Serverless 阶段,驯服了基于云编程的偶然复杂度,让您专注于本质复杂度(业务本身)—— 那些你的业务应用中真正有价值的部分。

就像一开始在那个桥的例子中,把所有其他让你分心的东西拿走,摆脱它们,然后专注于最最重要的事情。

总结一下,服务器是造成云应用程序偶然复杂度的根本原因,不接受反驳。
思考一下,只需想想一下今天我们编程模型所不存在的那些东西,寄存器名称、内存单元、以及服务器地址,这些也很快就会消失不见。要使 Serverless 应用于每一个应用场景,仍然面临着各种各样的挑战,同时研究人员正在积极地向前迈进,解决所有这些挑战。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论