

有时候,弹幕比剧情还精彩,那些脑洞大开、观点鲜明的弹幕,可以让千万用户参与到“剧情创作”中,因此很多人都喜欢边看剧边发弹幕。在 AI 算法的加持下,弹幕的呈现形式也花样翻新。优酷的很多剧都上线了基于 AI 人脸识别的跟随弹幕,与剧情更贴合,可玩性也更高。这类弹幕是如何实现的?有哪些核心技术?
在 GMIC 智慧文娱技术专场上,阿里文娱高级无线开发专家少廷分享了在优酷播放场景中,如何让互动结合算法的识别能力,实现新的 AI 弹幕形态。同时也介绍了优酷在互动游戏化领域的探索,以及让互动与内容相结合的应用实践。

播放中的互动场景
为什么要在播放场景中加入互动环节?归纳起来有四个价值:一是让用户更好地融入剧情,参与到剧情之中;二是互动能够对用户做实时反馈,体感非常好;三是很多用户在看剧时,精力不是那么集中,我们通过互动去抓住用户的剩余注意力;四是增加社区属性,让用户尽情表达,产生归属感。

上图是优酷重要播放互动的场景,包括在画面中弹出提示,对相关情节信息做科普介绍;双流播放形态,通过子母屏为播放场景提供第三人称视角;在剧中加入猜剧情、投票、小游戏等,弹幕是最核心的形态。
无论从用户规模还是用户效率看,弹幕都是效率最高的互动形式,是互动最头部的场景。AI 互动弹幕的出发点很简单,就是希望用户的互动与内容能更紧密地结合,让互动的展示形态更年轻和二次元。之前我们在弹幕中做过角色扮演的弹幕,指的是用户可以选择剧中角色,以他的口吻和头像来发弹幕。

角色扮演弹幕的转化率非常高。我们进一步思考,用户能不能直接在角色上,通过类似漫画配图的方式发弹幕,与内容融合到一起。这就是 AI 互动弹幕的由来。
基于机器视觉的互动弹幕的技术挑战
1、技术面临的问题:识别放到端侧还是云端?
一是识别剧中人物,人像识别本身已经有成熟的算法,既可以放到端侧,也可以放到云端,那么应该把识别能力放在哪?
核心的识别能力如果放到客户端上,识别的功耗和性能开销是很大的。如果是针对某些垂类场景,仅需在短时间内识别,放在客户端完全没有问题;但如果是长视频,从头到尾都有一个客户端的识别引擎在跑,端侧设备的性能、耗电就难以接受了。
二是客户端识别的精准度,因为算法识别直接输出结果,很难达到产品化的要求。在这一过程中,还要对识别结果进行二次加工和处理,包括平滑处理、降噪。这些处理都需要更多的工作时长,如果都放到客户端,难以保证实时性。所以我们将整个识别引擎都放到云端,通过云端识别输出数据,经过优化处理再将这些数据打包下发到端侧,实现投放和互动。
2、算法和工程如何对接?
工程和算法如何对接、工程如何解决算法输出后的各类问题?包括识别精度、数据抖动、视频文件变更之后导致的数据不一致的问题;另外,端侧要解决核心的体验问题。在播放过程中,镜头频繁切换时,这些人像在镜头中变化的问题,手机界面横竖屏的适应;还有气泡样式的弹幕,在不同剧中和内容的氛围如何融合等。
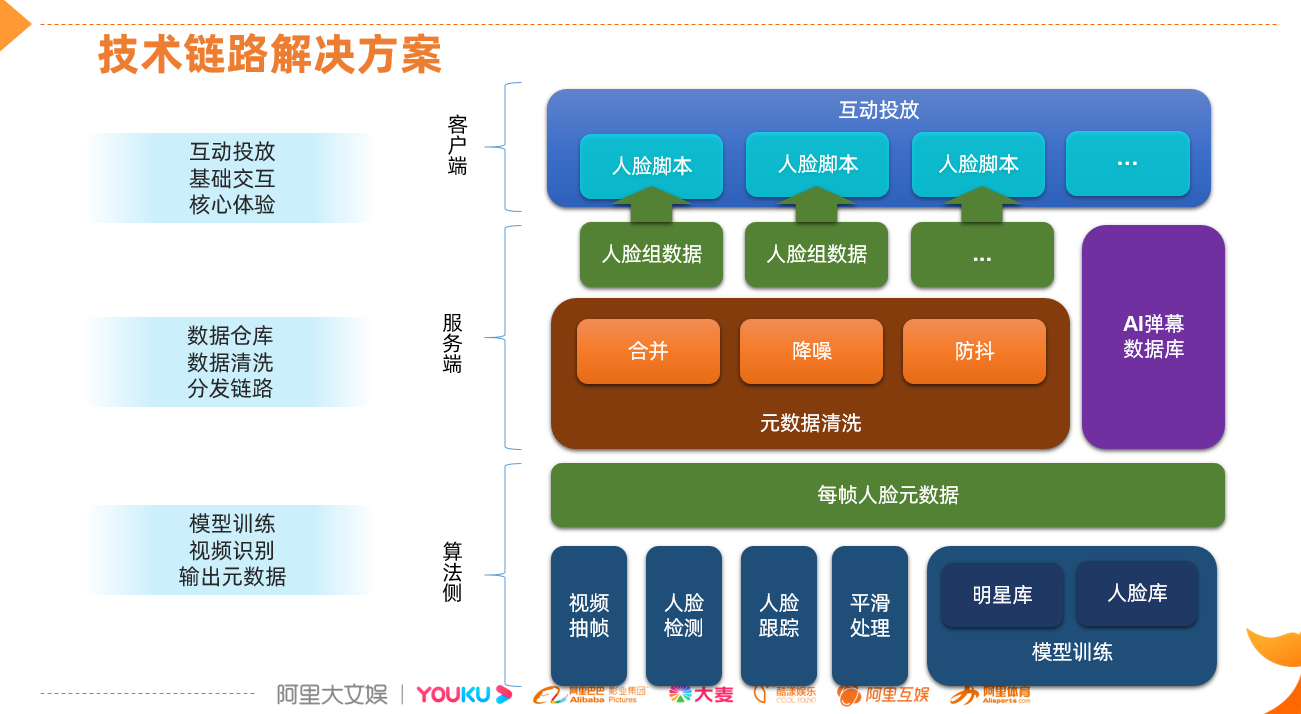
上图是我们的技术链路,由下到上,依次是算法层、服务端、客户端。在算法层,我们通过模型训练进行抽帧,对每一帧的画面进行识别,通过人脸检测和跟踪来抓取每一帧的人脸数据,再传输到服务端进行预加工,包括数据合并和降噪,最后将人脸数据打包,通过互动投放引擎投放到端侧,实现核心交互和基础体验。
1. 算法侧具体的技术细节如下:

1)视频抽帧与识别
抽帧现在按每秒 25 帧来抽取,这也是一个视频的基础帧率,对于高帧率的视频当然可以抽更多,但这与机器开销和耗时是成正比的。另外在算法侧,人脸的识别引擎有几部分,一是标准的人脸识别,能够识别大多数人脸的场景;二是优酷还针对明星和人物角色做了单独优化,我们会抽取一些剧中的明星和角色数据,作为数据集去训练,提升剧中主角和明星的识别率。
2)人脸跟踪
算法会识别出视频中每一帧的人脸和对应坐标,坐标用来标注人脸对应的位置,每个人脸帧也对应有人脸的特征值,相同特征值能够识别为同一个人。这样通过坐标和特征值,我们就能识别出一个镜头从入场到出场的序列帧里同一个人的人脸运动轨迹。
3)平滑处理,防抖动
我们知道算法是基于单帧对人脸做识别的,人脸的位置和大小的识别结果是有像素级的误差的,同一个人脸哪怕运动很轻微,上一帧和下一帧的识别结果的方框是不会严丝合缝对齐的。这样把连续的每一帧的识别结果像放动画片一样串起来,这种像方框一样的识别结果在播放场景中就会看到明显的抖动。
我们在工程侧对抖动做了检测和计算,将抖动限定在一个范围之内,让整个人脸的轨迹更平滑。

视频 2

视频 3
视频 2 是算法直接输出的人脸轨迹的识别结果,大家可以看到人脸的识别结果是伴随人物运动在抖动的,既有位置的抖动,也有大小的抖动。视频 3 是经过平滑处理后的结果,人物在整个镜头中走动,我们的识别结果输出是稳定平滑的,抖动效果已经被平滑消除掉。
2. 服务端对算法层输出的人脸原数据要做一系列的处理:

1)降噪,过滤掉镜头中不重要的人脸杂音。所谓不重要,是因为镜头中有大量的路人镜头,很多是一闪而过的,这些镜头的人脸对于用户交互来说不具备太大价值。所以我们要把路人、一晃而过的镜头中的人脸都过滤掉;
2)防抖。我们会对原数据进行平滑处理;
3)合并,就是合并一组连续帧中相同一个人脸的位置,打包输出。比如一个镜头中,一个人从左边走到右边,我们通过特征值识别出来这是相同一个人的连续镜头,那就把这一个镜头的人脸数据打包。这种包含了相同人脸和对应轨迹的数据,合并到一起之后,就成了一个数据包。然后将用户发的弹幕数据跟人脸的轨迹数据包绑定,投放到端侧,端侧负责展示。
3. 在端侧的技术细节

借助优酷互动投放引擎,将人脸识别结果的轨迹数据包和弹幕一起投放,在端侧完成数据解析和展示。端侧有一个轮训引擎来轮训互动投放的数据,当播放进度到某个位置时有人脸轨迹的数据和弹幕数据时,端侧会把人脸位置的弹幕气泡显示到播放场景中。
另外,客户端还要解决技术体验问题,包括镜头切换,虽然是细节问题,但是其实费了很多功夫。 例如,用户想发弹幕,在发送的一瞬间,镜头切换了。在用户侧看到的是弹幕闪一下就消失了,这个体感是非常不好的。
所以,在技术上我们要保证人脸弹幕发送后,会在同一个位置显示一定的时长。现在是 1 秒左右;投放弹幕的时候同样如此,如果用户在镜头的最后几百毫秒发送气泡弹幕,我们会把它做时间前置偏移,让弹幕稍微往前,在镜头中完整展示出来。
另外,在氛围方面,我们有古装剧、有现代剧、有悬疑、有综艺,剧的类型差异比较大。气泡弹幕与播放结合比较紧密,我们还是希望它的效果、样式、氛围能够跟剧本身贴合。我们在端侧实现这类样式的动态配置能力,对于不同的剧集能够展示不同的风格。刚才大家在案例中也看到了,有红的、有蓝的、有灰的,然后古装剧会带一些纹理小花之类。
另一个严重问题是,当视频剪辑变更之后,数据如何快速更新?
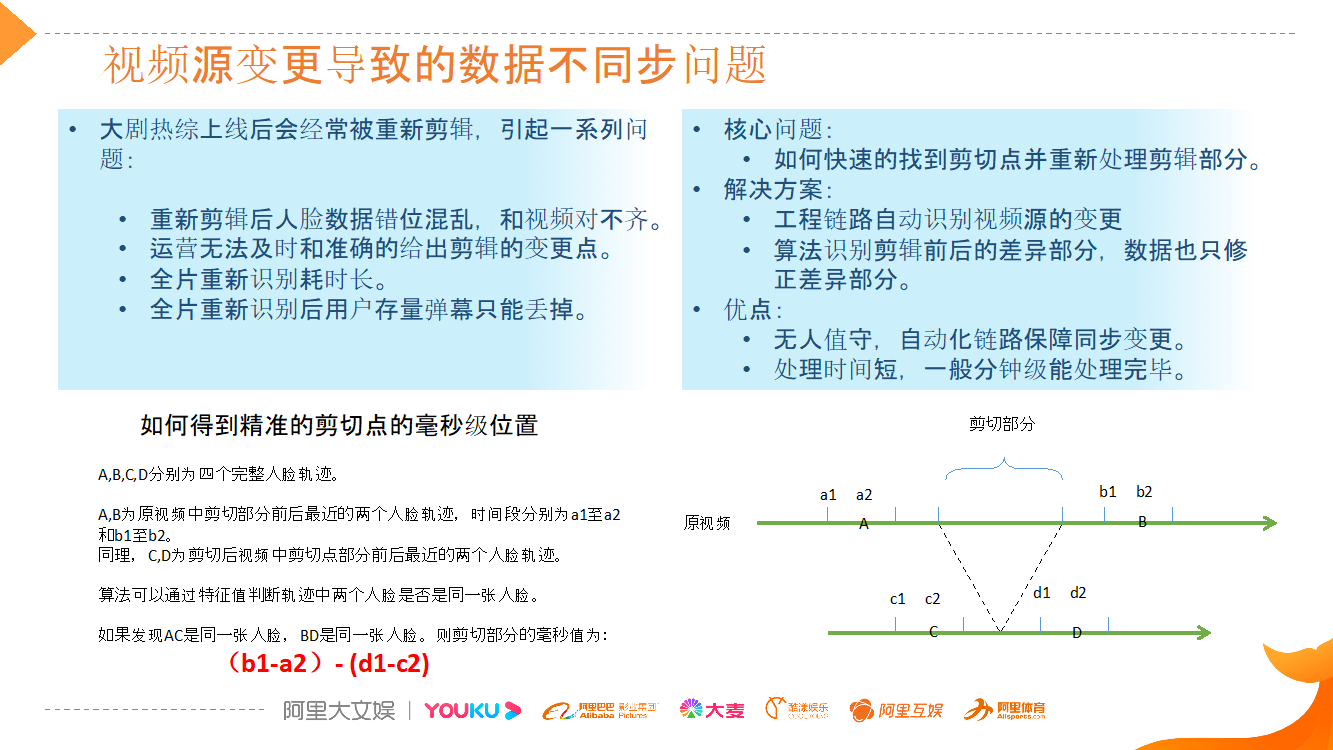
首先为什么会有视频变更?这是视频行业中的普遍现象。例如一个大剧,一个热综,在整个播放周期内,会经常因为一些原因被重新剪辑。重剪后就会引发一系列问题,比如,可能有一个桥段被剪掉了,原来识别出来的人脸数据结果和现在新的视频对不齐。另外,运营同学或者剪辑同学,其实无法准确的告知在什么时间点剪了什么内容,这无法依靠人力来保障同步。
另外,假设我们知道视频被剪辑了,全部重新识别一遍行不行?答案是不行,第一是耗时长,额外开销高;第二,如果重新识别,相当于镜头中的人脸的数据全部都更新了一遍,用户发送的存量弹幕和人脸相结合的部分无法还原。
所以我们的核心问题,就是要解决如何快速找到剪切点,并且只处理剪辑掉的部分。 技术解法如下:
首先工程侧要自动识别变更,一旦视频源变更,服务端就能收到相应的通知,并启动去做重新识别。算法要识别剪辑之后出现差异的部分,找到中间差异的时间段。这样处理的优势是:1)可以实现无人值守;2)识别时间短,分钟级处理完毕。
具体是如何实现的?我们会通过算法识别特征值。例如,原视频中 a 和 b 是两个人脸,中间的时长是 n 秒,剪辑后算法再去识别新视频源时,发现 c 和 d 对应的人脸特征值和 a 和 b 不一致、时长对不上。通过取两者(a 和 b,c 和 d)的差值,就知道那部分是被剪掉了,然后去处理差值的部分,一两分钟重新识别完,保证数据重新上线。

回到用户体验上,用户对 AI 弹幕是评价是怎么样的?
左边是用户用 AI 互动弹幕发布的内容,很多都是优秀的段子手,大家能够玩起来。
右边是用户反馈,有表达不理解、不清楚是做什么的,或者认为弹幕干扰正常观影。所以目前 AI 弹幕还是小范围投放,并没有全面铺开,因为我们也在思考用户的接受度。 在长视频中,并不是所有用户都能接受。更好的方向是将这种互动性强、更有意思的模式,与短视频和直播结合起来,因为在短内容和碎片化内容中,用户的接受度会更高,娱乐性会更强。
播放互动的相关尝试和展望
1. 互动交互能够和内容更紧密结合,交互方式更游戏化

通过对视频内容的识别,能够识别到或者理解到剧中的人物或者剧中的演员,甚至剧中的物体。这样我们对内容本身的场景和角色是能做到理解的。这样就可以将互动投放跟内容做的更紧密,比如说能够跟明星结合的更紧密,甚至能够跟商业化结合的更紧密,让商业化和内容本身结合,这也是一个方向。

2. 互动的效果更炫酷和惊艳
让交互结果和交互的视觉更年轻化,更让人有意外,让用户能有更进一步互动的欲望。

3. 用户参与的数据沉淀能够反过来指导内容的制作和生产
将用户参与互动的数据沉淀下来,通过对数据的理解和二次加工,抽象出一些结论。包括用户在互动上的高潮节点和用户高反馈的点。另外,希望指导内容制作和生产。
4. 短视频、直播这类碎片化的内容能够发挥互动的新价值
在更碎片化的短视频和直播内容中,探索一些新形态和新价值。
作者介绍:阿里文娱高级无线开发专家 少廷
公众号推荐:
2024 年 1 月,InfoQ 研究中心重磅发布《大语言模型综合能力测评报告 2024》,揭示了 10 个大模型在语义理解、文学创作、知识问答等领域的卓越表现。ChatGPT-4、文心一言等领先模型在编程、逻辑推理等方面展现出惊人的进步,预示着大模型将在 2024 年迎来更广泛的应用和创新。关注公众号「AI 前线」,回复「大模型报告」免费获取电子版研究报告。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论