

本文提出了一种高效的 LVS 流量异常检测算法,帮助 ops 同事更加精准的判断业务流量突增突减等非正常状态。希望该文章能给大家对异常检测的理解有所启发,后续会有作者对机器学习落地运维创新的系列文章,敬请期待。
前言
双十一刚过,阿里还有京东就在疯狂地 show(秀)他们的技术有多牛逼。无可厚非,两家公司在应对 guagngu 节的时候都有自己的一套针对不同场景的策略。试想一下,假如双十一那天天猫的主页访问不了,那马爸爸不得损失好多个亿。为了防止这样的情况出现,除了疯狂扩容以外,一套理想的异常检测机制也是非常非常重要的。
异常检测的场景很多,例如硬件的故障检测、流量的异常点的检测等场景。这篇博客我们针对的是时间序列的异常检测。时间序列异常的检测算法有很多,业界比较流行的比如普通的统计学习方法–3σ原则,它利用检测点偏移量来检测出异常。比如普通的回归方法,用曲线拟合方法来检测新的节点和拟合曲线的偏离程度,甚至有人讲 CNN 和 RNN 技术应用到异常点的检测。
通过普通的阈值来检测 lvs 流量异常的方法效果比较差,本篇文章提出了一种新的检测算法,下面将重点介绍我们在实践过程中的经验。
1 数据分析
获取过去 7 天的 lvs 流量的数据,我们可以大致将趋势分为两种:
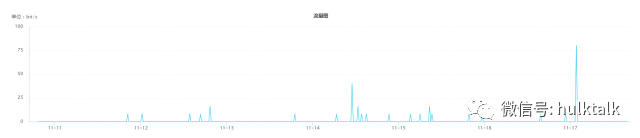
一种是如下图的具有周期性的数据,这种情况更多需要考虑周期性给数据带来的影响。
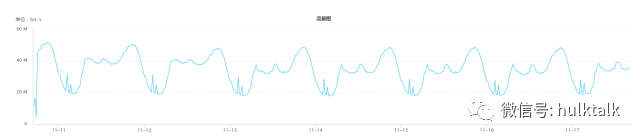
而另一种如下图的随机的数据,不具有周期性,这种情况需要采用和周期性不一样的策略来检测。
2 检测机制的研究
由于曲线就有周期性和非周期性的两种趋势,所以我们的检测机制需要能够处理两种方式。
下面我们将详细介绍每个算法。
算法
短期环比(SS)
对于时间序列(是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列)来说,T 时刻的数值对于 T-1 时刻有很强的依赖性。比如流量在 8:00 很多,在 8:01 时刻的概率是很大的,但是如果 07:01 时刻对于 8:01 时刻影响不是很大。
首先,我们可以使用最近时间窗口(T)内的数据遵循某种趋势的现象来做文章。比如我们将 T 设置为 7,则我们取检测值(now_value)和过去 7 个(记为 i)点进行比较,如果大于阈值我们将 count 加 1,如果 count 超过我们设置的 count_num,则认为该点是异常点。
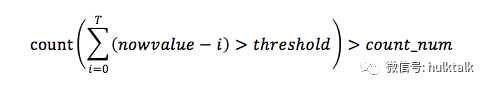
上面的公式涉及到 threshold 和 count_num 两个参数,threshold 如何获取我们将在下节进行介绍,而 count_num 可以根据的需求进行设置,比如对异常敏感,可以设置 count_num 小一些,而如果对异常不敏感,可以将 count_num 设置的大一些。
动态阈值
业界关于动态阈值设置的方法有很多,今天介绍一种针对我们 lvs 流量异常检测的阈值设置方法。通常阈值设置方法会参考过去一段时间内的均值、最大值以及最小值,我们也同样应用此方法。取过去一段时间(比如 T 窗口)的平均值、最大值以及最小值,然后取 max-avg 和 avg-min 的最小值。之所以取最小值的原因是让筛选条件设置的宽松一些,让更多的值通过此条件,减少一些漏报的事件。
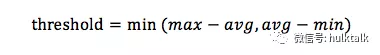
长期环比(LS)
上面短期环比参考的是短期内的数据,而仅仅有短期内的数据是不够的,我们还需要参考更长时间内数据的总体走势。
通常使用一条曲线对该趋势进行拟合来反应曲线的走势,如果新的数据打破了这种趋势,使曲线变得不平滑,则该点就出现了异常。曲线拟合的方法有很多,比如回归、moving average 等等。在这篇文章中,我们使用 EWMA,即指数权重移动平均方法来拟合曲线。在 EWMA 种,下一点的平均值是由上一点的平均值,加上当前点的实际值修正而来。对于每一个 EWMA 值,每个数据的权重是不一样的,最近的数据将拥有越高的权重。
有了平均值之后,我们就可以使用 3-sigma 理论来判断新的 input 是否超过了容忍范围。比较实际的值是否超出了这个范围就可以知道是否可以告警了。
同比(chain)
很多监控项都具有一定的周期性,其中以一天为周期的情况比较常见,比如 lvs 流量在早上 4 点最低,而在晚上 11 点最高。为了将监控项的周期性考虑进去,我们选取了某个监控项过去 14 天的数据。对于某个时刻,将得到 14 个点可以作为参考值,我们记为 xi,其中 i=1,…,14。
我们先考虑静态阈值的方法来判断 input 是否异常(突增和突减)。如果 input 比过去 14 天同一时刻的最小值乘以一个阈值还小,就会认为该输入为异常点(突减);而如果 input 比过去 14 天同一时刻的最大值乘以一个阈值还大,就会认为该输入为异常点(突增)。
静态阈值的方法是根据历史经验得出的值,实际中如何给 max_threshold 和 min_threshold 是一个需要讨论的话题。根据目前动态阈值的经验规则来说,取平均值是一个比较好的思路。
同比振幅(CA)
同比的方法遇到下图的现象就不能检测出异常。比如今天是 11.18 日,过去 14 天的历史曲线必然会比今天的曲线低很多。那么今天出了一个小故障,曲线下跌了,相对于过去 14 天的曲线仍然是高很多的。这样的故障使用方法二就检测不出来,那么我们将如何改进我们的方法呢?一个直觉的说法是,两个曲线虽然不一样高,但是“长得差不多”。那么怎么利用这种“长得差不多”呢?那就是振幅了。
怎么计算 t 时刻的振幅呢? 我们使用 x(t) – x(t-1) 再除以 x(t-1)来表示振幅。举个例子,例如 t 时刻的流量为 900bit,t-1 时刻的是 1000bit,那么可以计算出掉线人数是 10%。如果参考过去 14 天的数据,我们会得到 14 个振幅值。使用 14 个振幅的绝对值作为标准,如果 m 时刻的振幅[m(t) – m(t-1)]/m(t-1)大于 amplitudethreshold 并且 m 时刻的振幅大于 0,则我们认为该时刻发生突增,而如果 m 时刻的振幅大于 amplitudethreshold 并且 m 时刻的振幅小于 0,则认为该时刻发生突减。
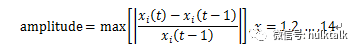
算法组合
上面介绍了四种方法,这四种方法里面,SS 和 LS 是针对非周期性数据的验证方法,而 chain 和 CA 是针对周期性数据的验证方法。那这四种方法应该如何选择和使用呢?下面我们介绍两种使用方法:
一、根据周期性的不同来选择合适的方法。这种方法需要首先验证序列是否具有周期性,如果具有周期性则进入左边分支的检测方法,如果没有周期性,则选择进入右分支的检测方法。
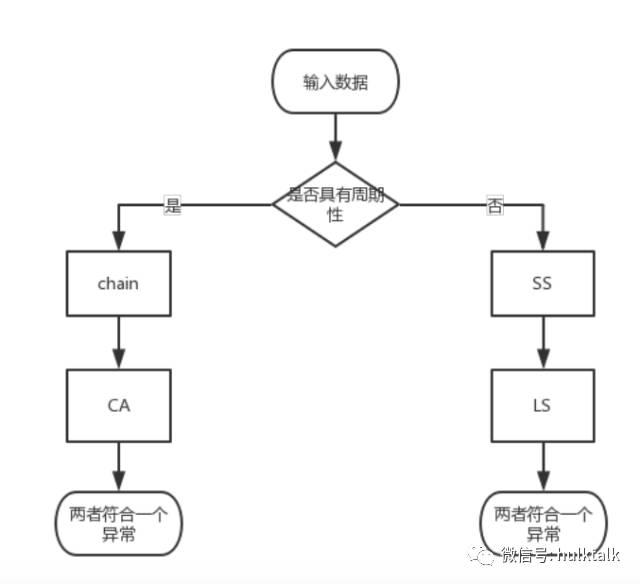
上面涉及到了如何检测数据周期的问题,可以使用差分的方法来检测数据是否具有周期性。比如取最近两天的数据来做差分,如果是周期数据,差分后就可以消除波动,然后结合方差阈值判断的判断方法来确定数据的周期性。当然,如果数据波动范围比较大,可以在差分之前先对数据进行归一化(比如 z-score)。
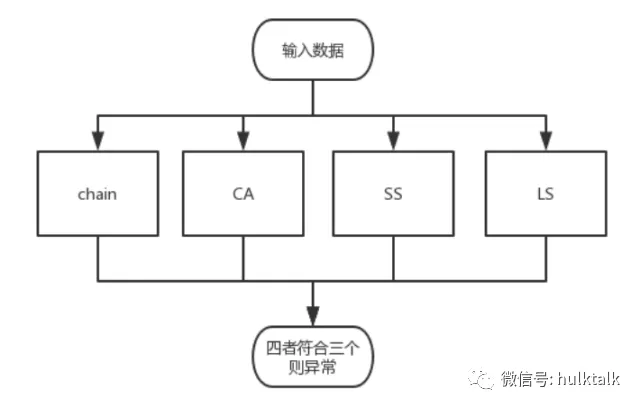
二、不区分周期性,直接根据“少数服从多数”的方法来去检测,这种方法比较好理解,在此就不说明了。
3 总结
这篇文章介绍了我们在 lvs 异常检测中使用的方法,也许这些方法还不够解决所有的场景,你还需要在此基础上去不断丰富算法,才能达到比较好的效果。所谓,理论结合实际,具体的问题需要具体的分析,才能将理论应用于实践。
本文转载自公众号 360 云计算(ID:hulktalk)。
原文链接:
https://mp.weixin.qq.com/s/3KNekJqDmIMsvh1wpDtBxg

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论